
深度神经网络在多场景车辆属性识别中的研究
2021-05-14 06:28柴江云
计算机工程与应用 2021年9期
王 林,柴江云
西安理工大学 自动化与信息工程学院,西安710048
随着社会经济的飞速发展,国民的生活水平稳步上升,目前,人们的代步工具已经逐步从自己的双脚转换为各种机动车辆,随之而引发的各类交通问题也越来越复杂。智能交通系统(Intelligent Transportation System,ITS)[1-2]是专门针对目前经济发展所造成交通问题的理想解决方案。各类机动车辆作为交通的重要组成成员,其属性的有效识别在智能交通系统中的位置举足轻重。在一般监控视频画面中,普遍存在图像像素不够清楚,车牌被阻挡、涂抹、腐蚀等情况,无法准确对车牌号码做出定位与识别,这时快速准确地识别出车辆的其他属性信息就显得尤为重要。比如车辆其他的外观特征,车辆类型和颜色的准确识别可以弥补车牌识别的不足,并且可以对车牌识别结果进行补充,更全面地增加车辆信息,也可以提高ITS 的可靠性和安全性,大幅度提高车辆交通管理的智能性。快速准确地识别出车辆的类型和颜色并根据识别结果做出准确的分析,可以有效地服务于ITS,并且还可以建立起一个车辆信息数据库提供车辆的信息检索,将其应用到交通安全和相关部门中将大幅度提高相关部门的工作效率。因此,车辆属性的有效识别在交通拥堵、车辆检索跟踪和实时检测管理车辆中具有极其重要的作用,它将成为ITS的重要辅助手段之一。
车辆的颜色识别是计算机视觉研究的一个子领域,它的主要工作是确定一幅图像中车辆的主要颜色,传统的颜色识别由于天气、光照等复杂的外界环境因素还存在许多问题,无法正确识别出各车辆的颜色,此外,还有一些车辆的颜色非常接近,无法准确做出分类,这也是颜色识别的一大挑战。自然场景中的车辆颜色识别可以在车辆检测、车辆跟踪和自动驾驶等系统中提供有用的信息。车辆的类型由于其特定的边缘特征,相比车辆颜色的识别较为容易,只要样本足够多,图像质量足够高,就可以准确地识别出车辆类型,并且获得较高的精度。传统的车辆属性识别中,往往是针对单一的属性进行识别,Zhang 等人[3]提出了一种基于胶囊网络(Capsule Network)的车辆类型识别模型,该模型包括对不同角度和光照条件的五种不同类型的车辆进行识别,并对胶囊网络的动态路由算法进行了重新设计,以节省训练时间和加快收敛速度,最后取得了91.27%的准确度。Chen等人[4]根据纹理特征,将每个汽车面部图像分为多个子图像,在不同层中使用卷积神经网络(Convolutional Neural Network,CNN)提取全局和局部特征,对车型进行识别,取得了较高的准确率,但仅能识别包含车辆前景的图片,对车辆其他角度的图片无法做到正确识别。Damitha 等人[5]利用支持向量机(Support Vector Machine,SVM)的方法对车辆的颜色进行了分类识别,他们提取相同的感兴趣区域(Region of Interest,ROI),以便从车辆中提取颜色特征,并且使用了几种不同的特征组合,并根据这些特征组合进行了测试,最后取得了87.52%的平均准确率。Xue等人[6]为了减弱照明因素对颜色识别的影响,对于不同照明条件下的图像使用不同的处理方法,以提高色彩识别的准确性,但是他们在处理图像时需要花费大量时间来对图像进行手动分类。阮航等人[7]首先利用Faster R-CNN 网络对车辆进行检测,然后对GoogLeNet 网络结构进行改进,在全连接层后面连接多个损失层以实现车辆的标识、姿态和颜色属性的识别,其取得了85%的准确率。
综上可知,车辆属性识别领域的研究有很多,也取得了不少成果,但大多数学习任务是基于单个属性的单任务学习,关于具有多个属性的复杂学习任务的研究却很少。仅通过车辆的某一个属性来定位一个特定车辆往往很难实现,识别过程耗时普遍较长,无法切实应用于现实应用,而且车辆的外在属性可以确定的信息越多,对定位特定车辆帮助则越大。对于车辆,它也具有多个属性描述,例如根据汽车类型,它可以描述为car、suv、van 等;根据车辆的颜色,可以将其描述为红色、白色、黑色等。基于以上分析,本文针对车辆的多属性特征,通过网络搜索和实拍数据来构造车辆多属性数据集,并提出一种基于深度神经网络的现实场景中车辆属性识别方法,利用YOLO(You Only Look Once)神经网络的升级版YOLOv3网路,通过图像全局区域对车辆数据集进行训练,同时将车辆类型和颜色两个属性任务进行分级训练,二者之间互不影响,实现车辆类型和颜色属性的检测识别工作,从而提高了模型的适用性。
1 车辆属性识别框架
1.1 YOLOv3网络
目前深度学习(Deep Learning,DL)[8-9]在目标检测识别领域应用及其广泛[10]。近年来,基于DL 的算法在图像分类[11]、物体检测[12-13]等方面取得了突破性的成果。在处理视觉任务时,与采用人工特征的传统方法相比,深度学习架构能够从原始图像上学习到更有效的表示,并且比传统方法的性能更好。其中CNN 在数字识别[14]的工作中首次显现出其实用性,Krizhevsky 等人[11]是第一个将CNN 应用于大规模图像分类问题的,并且在ImageNet数据集[15]上获得较高性能的应用实例,这是迄今为止最大和最具挑战性的图像数据集。
本文以YOLOv3 网络为原型,通过采用残差网络(Residual Network,ResNet)[16]的跳层连接方式,在增加网络深度的同时,使得网络仍然可以收敛,能够实现端到端的目标检测和识别。YOLOv3 神经网络意在只需要看一次图像即可预测出图像中存在的目标对象及其位置信息,该网络直接从图像中提取检测框,并通过整个图像特征检测目标对象[17]。在该过程中,首先将输入图像划分成S×S 个网格,然后对每个网格都预测出B个检测框,每个检测框都包含5个预测值,分别是x、y、w、h 和confidence。其中x、y 为检测框的中心坐标,w和h 分别为检测框的宽和高,confidence 是这个检测框所属类别的置信度。每个检测框的损失函数包含四部分,如式(1)所示:
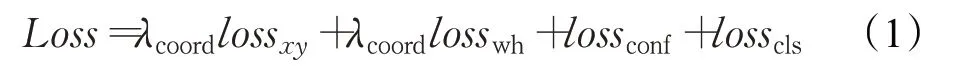
其中,lossxy是检测框的中心坐标误差,losswh是检测框的高度坐标误差,lossconf是检测框的置信度误差,losscls是检测框的分类误差。损失函数分为两部分:有物体部分和没有物体部分,其中没有物体的部分损失增加了权重系数。一幅图像中大部分内容不包含待检测物体,这样会导致没有物体部分的计算量大于有物体部分的计算量,这会导致网络倾向于检测单元网格不含有物体,因此在没有物体的部分添加权重系数,减少没有物体部分计算的贡献权重,本文取值为0.5。
中心坐标损失lossxy定义为式(2):


式(5)表示只有当第i个网格的第j个检测框负责某一个真实目标时,该检测框所产生的边界框才会计算分类损失函数。
1.2 车辆属性识别网络
网络深度越深,目标检测识别的准确率越高,但相应的检测时间就会越长,在普通静态图片识别中,时间因素的影响还不是很突出,但在视频应用中,需要考虑到视频的实时性条件,在一帧视频的目标检测识别过程中,时间因素是一个重要的考量标准。在本实验中,包括车辆类型和车辆颜色两个属性类别,考虑到不同类型车辆的颜色分布区域不同,比如卡车的颜色主要分布于车窗周围,而轿车和越野车的颜色主要分布在车头的引擎盖上,因此本文将车辆的整个图像区域作为车辆颜色的ROI,最大限度地使用车辆信息进行颜色训练,这样就会和车辆类型的ROI发生冲突。在本实验中,采取将车辆类型和车辆颜色属性进行分级训练,这样不仅可以使用不同的网络结构,还可以避免车型和车辆颜色ROI冲突的问题。在训练时两个模块间采用不同的网络结构,然后对模型进行整合调用,可以大幅度提高车辆属性识别的准确率和检测时间。
图1是本实验的车辆属性识别算法,在图1中,首先将输入图像调整为416×416 大小,然后在图像上运行CNN 进行特征提取,最后通过模型的置信度对检测结果设置阈值进行检测框的筛选。

图1 车辆属性识别算法
在本实验中使用YOLOv3 神经网络来建立车辆属性识别的模型。图2为车辆类型识别网络的结构图。
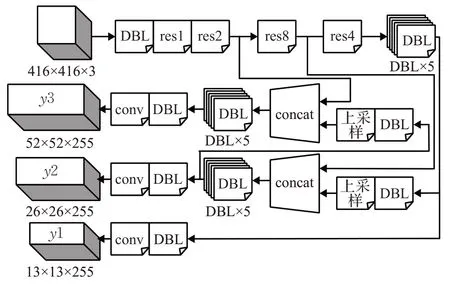
图2 车辆类型识别网络结构图
图2中DBL、resn、concat具体内容如下:
DBL:是该网络结构的基本组件。即为卷积+Batch Normalization+Leaky relu的组合。
resn:n代表数字,有res1,res2,…,res8 等,表示一个res_block里包含n个res_unit。
concat:张量拼接,将中间层和后面某一层的上采样进行拼接,让网络同时学习深层和浅层特征,使得表达效果更好。
该网络通过若干个DBL 组件和res 残差单元进行特征提取,然后通过concat对中间层和后面某一层的上采样进行张量拼接融合学习各层特征,最后创建3个尺度的输出,即图2 中的[y1,y2,y3],其中底层信息含有全局特征,中间层信息含有局部特征,这样拼接,可以使得两者兼顾。此外,还借鉴了特征金字塔网络(Feature Pyramid Networks,FPN)[18]的思想,采用多尺度来对不同尺寸的目标进行检测,越精细的网格单元可以检测出越精细的物体。
在车辆类型识别模块中,因需要采集的特征点较多,特征采样网络越深,采集到的车型特征点越多,分类准确度越高,在车辆颜色识别模块中,车辆颜色分布比较均匀,其特征点较少,只需计算出每个ROI 中的颜色像素值,特征采样网络仅需简单的一些层就可实现。在YOLOv3神经网络的基础上进行改进,保留其部分的卷积层,在每个卷积层后加入一个池化层,然后进行张量拼接,重新组合成一个23层的新的网络结构,对车辆颜色样本进行训练,以提高车辆属性识别的整体时间。图3为改进后的车辆颜色识别网络结构图。其中,DP为卷积层和池化层的组合。在该网络中,通过多个DP 组件和若干个卷积层进行特征提取,然后同样通过concat进行张量拼接融合学习属性特征,最后创建2个尺度的输出,即图3中的[y1,y2]。
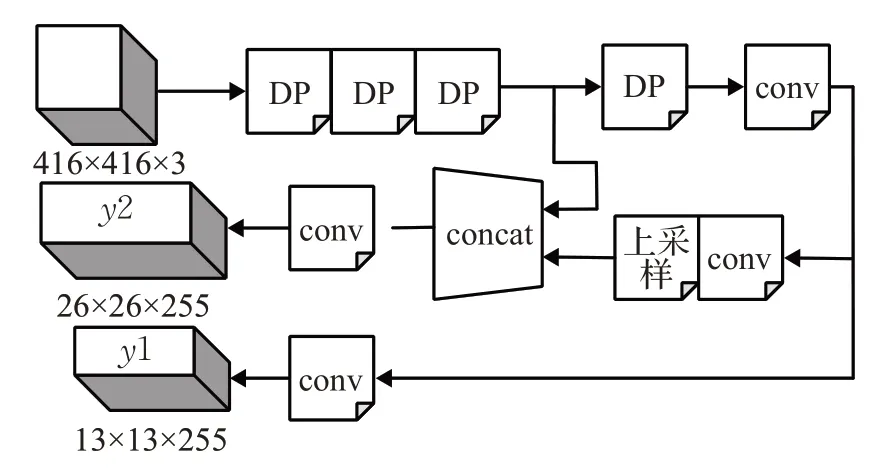
图3 车辆颜色识别网络结构图
采用DP 组合的方式在不影响识别准确率的前提下,精简了网络结构,降低了网络深度,大幅度缩短了模型检测识别所占用的时间,与车型识别模型相结合,在网络检测出车型的同时调用车辆颜色模型进行颜色识别,可以提高车辆属性识别的准确率,并且缩短车辆整体识别时间。
1.3 模型训练
在进行模型训练前,需要准备好模型训练所需的车辆图片样本数据集,以便网络进行特征学习。除原始的图片样本数据集外,还需准备好网络训练所需的样本感兴趣区域,即样本的标签数据集。该标签数据集需要将训练用的数据进行手动标记好感兴趣区域和类别名称,这样不仅可以提高感兴趣区域的准确性,还可以减弱噪声的干扰,提高特征提取的有效性。在本文中,将车辆按照类型分为bus、car、coach、truck、suv、van 6 种类型;按照颜色分为黑色、蓝色、灰色、绿色、橙色、紫色、红色、白色、香槟色、黄色以及银灰色11种颜色。
本实验在GTX 1080Ti GPU 上进行训练,在训练前,还需对部分参数进行调整,将训练数据集分为64批,每批的数量设置为4,这样可以减轻GPU 负担的同时最快速度的进行迭代,迭代次数设置为500 000 次,充分学习车辆各属性的特征。训练过程中学习率(learning_rate)参数值设置得越高则所得模型的识别准确率越高,但该参数不能随意设置,过高的learning_rate会导致网络仅学习数据集而发生学习偏差,因此在本实验中将learning_rate设置为0.001。在训练过程中,模型的训练损失和模型学习率的曲线变化如图4 所示。其中图4(a)是模型训练过程中平均损失的曲线图,在训练过程中平均损失降得越低则模型的学习效果越好,图4(b)是模型训练过程中学习率的曲线图,该曲线反映了训练过程中模型学习到各属性特征的能力大小,期望值趋于训练前的设定值,即0.001。由图4 可以看出,模型的训练损失值最后降低在0.02附近,已经可以满足训练要求,但是learning_rate 在400 000 次迭代之后发生锐减,说明训练模型在此时出现了过拟合现象,故而结合平均损失曲线图,最佳迭代次数应截止在400 000 次之前,此时平均损失仍然在最低处,同时学习率达到最高。适时的停止训练,降低训练过程中过拟合带来的影响,可以提高模型的识别准确率。
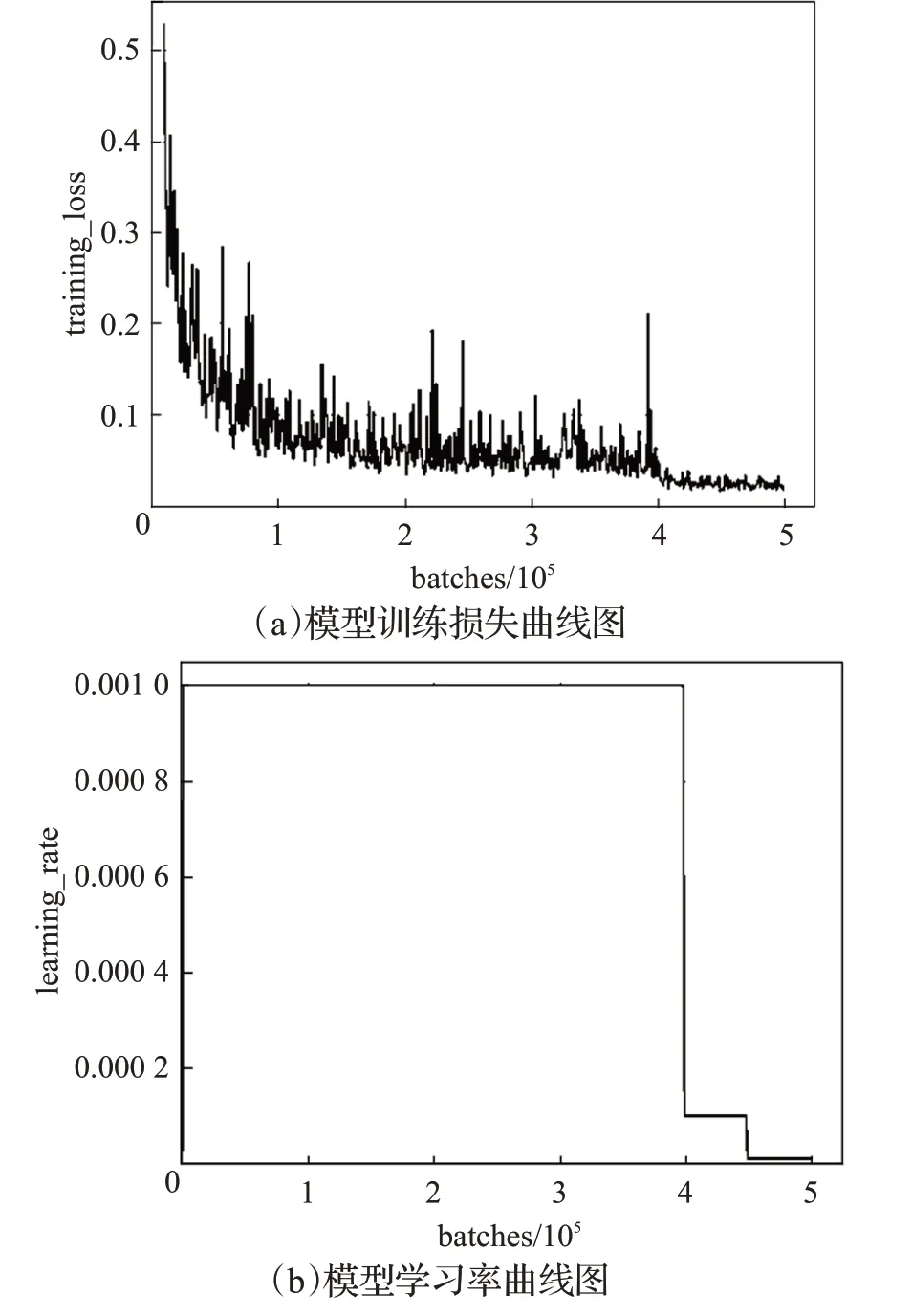
图4 训练损失与学习率结果
2 实验分析
2.1 数据集
由于要实现车辆的类型和颜色两类属性的识别问题,因此需要数据集有充足的训练数据和丰富的种类。为满足实验需求,其中应包括不同环境、不同角度、不同类型和不同颜色的车辆。但是目前公开的车辆数据集中,车辆类型普遍比较陈旧,颜色和现在的车辆颜色相差较大,无法满足本实验的数据要求。因此,为满足本实验的数据要求,自建了一个包含车辆多种属性的AttributesCars数据集,其中包含各类型及各类颜色的车辆,共计20 000 张车辆图像,可以完成对车辆类型和颜色属性的训练准备。其中50%来自网络上公开的车辆数据集Stanford Cars,该数据集中车辆的类型和现在的车辆相差不大,但车辆的类型比较固定,以car和suv 居多,故而另外50%采集自网络上公开的各类型车辆的数据和手动采集的多种场景下的各类型车辆数据。为了扩充数据集以及增强训练模型的鲁棒性,分别对这些数据进行了缩放、模糊处理,其中80%进行逐个筛选后做标签处理,用于训练,剩下的20%用于测试。
2.2 实验结果与分析
在车辆属性识别过程中,需在满足识别准确率的前提下,最大限度地满足视频实时性的要求。在本实验中,颜色识别模块采用简化改进版的网络结构,训练所得模型大幅缩减了检测识别所用时间,并且识别准确率没有受到影响,在车型识别模块虽然识别时间较长,但结合颜色模块可以弥补车型模块识别时间较长的缺陷,使得整体车辆识别时间可以满足视频实时性的要求。
在车辆行驶中,道路场景变化多样,监控视频中的车辆图像随道路场景的变化而不同,在一个监控画面中,车辆出现位置与摄像头位置距离的远近直接影响到是否能正确有效地识别车辆属性。为了评估车辆属性识别模型的适用性,特在近景监控和交通监控两种不同场景下进行了测试与验证。在近景监控场景中,摄像头距离车辆目标位置较近,采集到的图像比较清晰,对监控画面中的车辆进行检测与识别的准确率比较高;在交通监控场景中,摄像头一般位于较高位置,距离车辆比较远,采集到的车辆图像相较近景中像素偏差较大,目标偏小,准确率相对比较低。图5是本实验训练模型的识别效果图,图中目标车辆顶部显示的是该车辆颜色和类型属性的识别结果。其中图5(a)是在近景监控场景中的部分车辆属性识别结果,图中车辆图像较大,颜色清晰,识别结果正确无误;图5(b)是在交通监控场景中部分车辆的属性识别结果,图中车辆图像较小,颜色勉强可以看清,识别结果也正确无误。从图5 可以看出,无论是在近景监控场景中还是交通监控场景中,均可以正确识别出车辆的类型和颜色,证明了本模型的可行性。
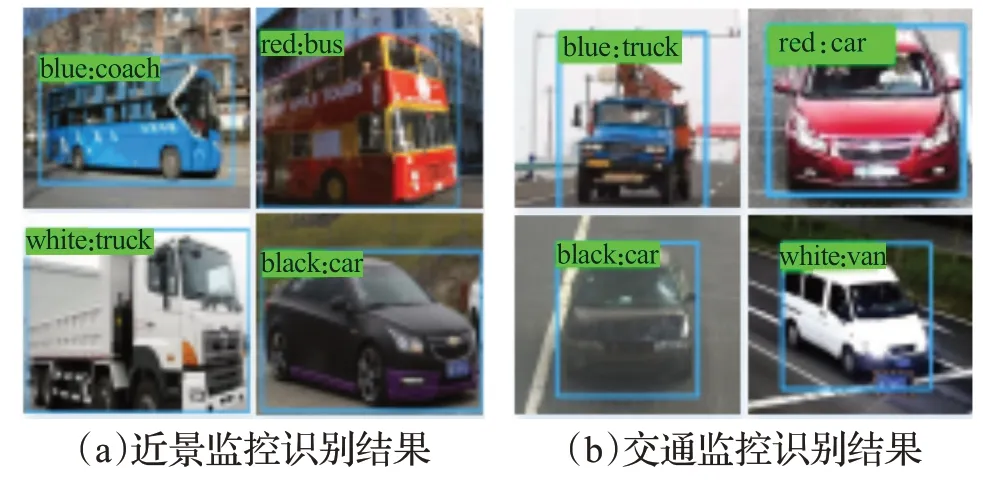
图5 模型识别结果
在实验结果中可以看出本实验的模型可以正确识别出不同场景下车辆的类型和颜色属性,为验证本文方法在车辆属性识别方面的优越性,将本文方法与其他在车型和车辆颜色识别方面的研究方法进行了比较,因本实验涉及到车辆类型和颜色两个属性,并且是分级进行训练的,特将车型和颜色属性分别进行比较。分别在识别准确率和识别所用时间方面进行对比分析,车辆类型和车辆颜色的识别结果对比分析分别如表1 和表2所示。
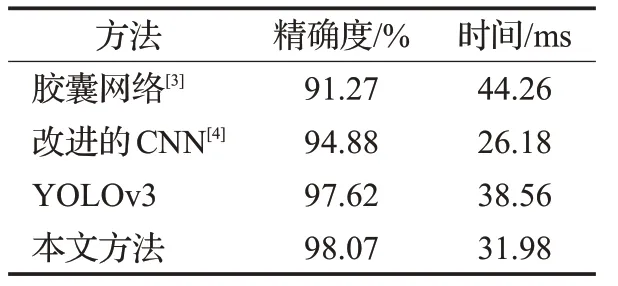
表1 车辆类型识别结果
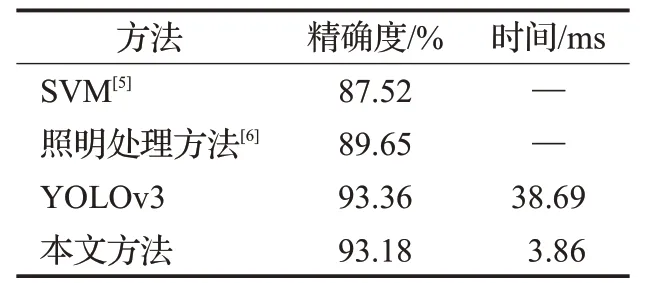
表2 车辆颜色识别结果
由表1可以看出,基于胶囊网络方法在达到91.27%准确率的前提下,车型的识别时间为44.26 ms,基于改进的CNN 方法的准确率为94.88%,其识别时间减少为26.18 ms,原始的YOLOv3 方法的准确率为97.62%,相应识别时间增加为38.56 ms,且其识别车辆类别较少,不够全面,本文所提出方法准确率达到98.07%,识别时间为31.98 ms,相较原始的YOLOv3方法在准确率提升的前提下识别时间略有降低。
由表2 可以看出,基于SVM 方法的车辆颜色识别的准确率为87.52%,基于照明处理方法的车辆颜色识别准确率为89.65%,这两种方法的识别时间未知,而YOLOv3方法可以达到93.36%的准确率,38.69 ms的识别时间,时间相较其他方法大幅缩短,本文所提出的方法准确率为93.18%,识别时间仅用3.86 ms,相较YOLOv3方法在不影响识别准确率的前提下,大大缩短了识别时间,对视频中车辆识别的应用更具实用性。
综合表1 和表2 的结果可以看出,本文提出的车辆多属性识别模型可以在识别车辆类型的同时,对车辆颜色进行有效的识别,车型识别时间为31.98 ms,结合车辆颜色的识别时间3.86 ms,整体车辆的识别时间为35.84 ms,可以满足视频实时性的要求,此外,车辆的类型和颜色的类别相结合共同识别,使得车辆识别结果更加全面,平均准确率可以达到95.63%,可以更有效地应用于现实交通中车辆属性的检测识别。
3 结束语
本文提出了一种基于深度神经网络的多场景下车辆多属性识别方法。首先针对真实道路场景下的监控图像,采集包含各类型与各类颜色的车辆数据集,并进行分类筛选和标签处理,训练经过改进后的YOLOv3神经网络得到车辆多属性识别模型,该模型可以在缩短识别时间的前提下同时达到识别准确率度高,检测效果好的要求,适用于各类真实道路场景下的监控图像。本文将车辆的类型和颜色属性的样本数据集进行分级训练,有效提升了属性分类的准确率与实时性。利用测试数据集对训练得到的车辆多属性识别模型进行了测试,实验结果表明,本文提出的方法在不同道路场景下均具有较高的检测精度,满足了现实使用要求,并且可以有效识别出车辆的类型和颜色信息,具有较高的识别准确率和良好的适用性以及鲁棒性。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
少儿科学周刊·儿童版(2015年11期)2015-12-17
汽车文摘(2015年11期)2015-12-02
