
基于注意力交互机制的层次网络情感分类
2021-05-14 06:28杨春霞李欣栩吴佳君刘天宇
计算机工程与应用 2021年9期
杨春霞,李欣栩,吴佳君,刘天宇
1.南京信息工程大学 自动化学院,南京210044
2.江苏省大数据分析技术重点实验室,南京210044
3.江苏省大气环境与装备技术协同创新中心,南京210044
4.佳木斯市汤原县气象局,黑龙江 佳木斯154000
近年来随着互联网的不断发展,各大平台充斥着大量用户对商品的评论,通过阅读和分析这些评论可以发现用户对产品的情感倾向。对评论中的情感倾向进行挖掘有助于用户获得个性化服务,也有助于商家及时调整销售策略。
情感分类是推荐系统、数据挖掘等领域的一项重要任务[1-2]。本文研究内容是针对评论的文档级情感分类,即假定每个文本均表达了用户对单一产品的情感,预期目标是确定评论的情感倾向。
目前许多学者[3-5]基于深度学习的方法搭建了分类模型并针对不同场景得到了不错的效果,但是针对评论的文档级情感分类任务为了提高分类效果,需要在通用的情感分类模型的基础上考虑用户数据和产品数据。Tang等[6]结合用户信息和产品信息建模,证实相关数据的添加有助于提高模型效果。但是评论中包含词粒度、句粒度和篇章粒度的文本信息,直接使用整条评论进行建模不可避免地会丢失部分信息。文献[7-8]将用户和产品信息融入注意力层并使用多个特征提取层,通过获取不同粒度的信息来提高模型效果,实验证明层次网络具有更强大的特征提取能力,在建模过程中添加用户数据和产品数据帮助分类也是很有必要的。然而现有的大多数模型将用户信息和产品信息二者归为一类进行建模,但是在一条评论中,不同词与用户信息和产品信息的相关程度有所差异。例如,在评论“The bar is definitely good‘people watching’and i love the modern contemporary decor”中,“good”“modern”和“contemporary”主要描述产品特征,“love”主要描述用户情感。情感分类的结果与相关描述词高度相关,所以在建模过程中添加用户和产品信息来帮助提取描述词是很有必要的。除此之外可以看出这些描述词与用户和产品的相关度有所区别,所以将用户信息和产品信息二者归为一类进行建模是过于粗糙的。此外为了更好地利用用户和产品信息,考虑到目前基于深度学习的分类模型在分类过程中通过逐步抽取较为重要的文本特征来提高分类效果,相似地,本文在抽取描述词中较为重要特征的同时,尝试抽取产品和用户对分类贡献度大的特征来帮助分类。
综上本文提出一种基于注意力交互机制的层次网络(Hierarchical Network-based Attention Interaction Mechanism,HNAIM)模型。
(1)为了从词级、句级提取语义特征并生成篇章级文本表示。模型的第一部分层次网络首先由BiLSTM生成句级的语义特征,得到的特征作为下一个BiLSTM的输入最终得到篇章级的文本特征。考虑到文本中描述词与用户和产品的相关度不同,层次网络将用户和产品信息分开建模。
(2)经典的注意力机制只能抽取重要的描述词特征,本文采用注意力交互机制,在抽取重要的描述词特征的同时,抽取产品和用户对分类贡献度大的特征来帮助分类。模型的第二部分利用注意力交互机制分别在句级和篇章级上帮助原始层次模型获取更有价值的语义信息。
1 相关工作
基于深度学习的文档级情感分类旨在通过深度学习来预测文本的整体情感极性,其关键在于提取文本特征。Bengio等[9]最早利用神经网络将词表示在向量空间中。Mikolov 等[10]和Pennington 等[11]分别提出Word2vec和Glove词向量模型,这些词嵌入模型在情感分类任务上均取得不错的效果。为了进一步挖掘文本的特征,一些学者将词嵌入和其他深度学习模型进行结合,LSTM因其可以解决文本语义上的长期依赖问题受到学者的青睐。然而语义的联系是双向的,BiLSTM模型在保留LSTM优点的基础上能够保留文本的上下文信息,在情感分类任务上可以取得更好的效果。
注意力机制在NLP中表现为信息加权,它的引入提高了网络对文本特征的提取能力。Bahdanau 等[12]首次将注意力机制应用到机器翻译任务中,取得较好的效果。Luong 等[13]将注意力分为局部和全局两种形式,促进了注意力机制在NLP 的推广。Yang等[14]在情感分类任务中通过注意力机制和神经网络的结合提取文本特征并取得了不错的效果。胡荣磊等[15]利用LSTM 和前馈注意力构建情感分类模型。Huang等[16]通过改进的注意力机制将句子和方面词联合建模,较传统的情感分类模型取得了更好的效果。
Tang等[17]利用层次网络的概念构建情感分类模型,即基于词粒度的文本表示使用CNN/LSTM来构建句粒度的文本表示,然后基于句子和它们的内在关系构建篇章级的文本表示。在针对评论的情感分析任务中,文献[7-8]结合用户和产品信息构建层次网络模型并取得了很好的效果。
本文针对评论文本的特性在相关工作的基础上进行一定的改进。本文利用BiLSTM 构建层次网络来提取文本特征,但用户和产品分开建模;本文使用注意力交互机制,在挖掘文本特征的同时也挖掘用户和产品中的重要特征来辅助分类。
2 HNAIM模型
2.1 任务定义
本文主要针对评论文本的特性,结合用户和产品信息构建分类模型。为了便于后续对比分析,本文使用Tang等[6]数据预处理后的评论数据集(详见3.1节)。数据集中每条文本仅有一个用户和一个产品。文本t(t ∈T)结构为{u,p,d} ,含义为文本t(t ∈T)中用户u(u ∈U)发表了关于产品p(p ∈P)的评论d(d ∈D),其中T 是文本集,U 和P 表示用户集和产品集,D 为评论集,t、u、p、d 为单一样本。最终目标是确定评论的情感倾向。
2.2 算法模型
本文利用BiLSTM 构建层次网络来提取不同粒度的语义信息,由于文本中描述词与用户和产品的相关度不同,将用户和产品信息分开建模。在层次网络中通过注意力交互机制逐步提取文本、用户、产品中的重要特征。HNAIM模型图(主要模块见2.2.1~2.2.5小节)如图1所示,分类流程如下:
(1)通过词嵌入模块将文本t(t ∈T)中{u,p,d }转化成词向量{u,p,d}。
(2)将d 中作为层次网络的输入,首先使用BiLSTM来学习词向量的句级表示,然后通过BiLSTM处理句级表示,最终生成篇章级文本特征。
(3)通过注意力交互机制分别计算文本特征与用户和产品的相关度,将文本中重要的句子进行加权突出。在词粒度生成含用户观点的句子表示su和含产品观点的句子表示sp,在句粒度得到含用户观点的篇章级文本表示du和含产品观点的篇章级文本表示dp。
(4)将du和dp简单连接得到文本向量dt,通过softmax 层得到dt、du、dp在不同类别上的概率sxt、sxu、sxp,最终根据sxt的概率来进行情感分类。
(5)通过损失函数模块优化模型。针对评论文本特点,损失函数加入sxu、sxp作为辅助分类信息。
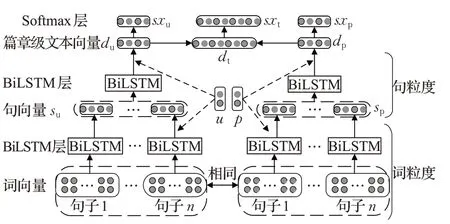
图1 HNAIM算法模型结构
2.2.1 词嵌入
情感分类的基础是将文本中的单词转换成词向量。文本t(t ∈T) 呈{u,p,d} 的结构,将u(u ∈U) 和p(p ∈P)转化为词向量u 和p。如公式(1)所示:
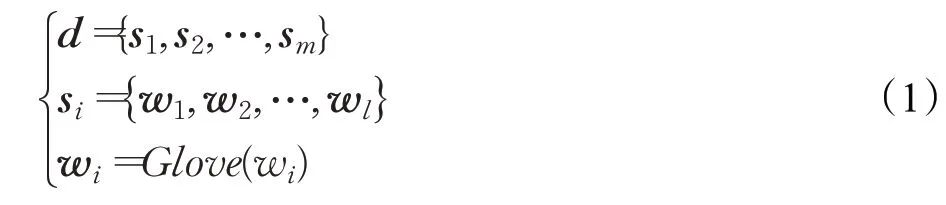
将评论d(d ∈D)按符号分成m 个句子,即d={s1,s2,…,sm},每个句子含n 个词,即si={w1,w2,…,wn},将si的长度用零补成定长l ,l(n ≤l) 是D 中最长句子单词数。将wi转化为词向量wi,最后将si表示成l×v 的词向量矩阵si的形式,其中v 是词向量的维数。文本t(t ∈T)呈{u,p,d}结构的向量形式。
2.2.2 BiLSTM层
LSTM 每个单元如公式(2)至(7)所示。公式中σ代表sigmoid 函数,ft、it、ot分别对应遗忘门、输入门以及输出门,wt是t 时刻的输入,ct是t 时刻单元的状态,ht表示t 时刻LSTM 的输出,ht-1是t-1 时刻LSTM 的输出。然而LSTM 只能捕捉一个方向上的信息流动,但文本信息的语义关联是双向的。BiLSTM可以从两个方向来获取信息,这样不但可以从网络上获取更多的文本信息,而且更加符合文本的语义特性。BiLSTM 由一个前向LSTM 和一个后向LSTM 组成,最后合并两个方向上LSTM 的结果得到所需的文本特征。如公式(8)至(10)所示,其中LSTM1和LSTM2表示两个方向上的LSTM,ht1和ht2表示t 时刻两个方向上LSTM 的输出,ht表示t 时刻BiLSTM 的输出,ht-1是t-1 时刻BiLSTM的输出。[…;…]是简单的连接操作符。
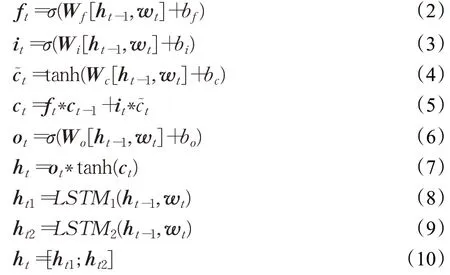
2.2.3 注意力交互机制
本文在抽取文本中较为重要的特征的同时,尝试抽取产品和用户对分类贡献度大的特征来帮助分类。由于引入用户信息和引入产品信息的处理流程相似,故以引入用户信息u 为例来介绍注意力交互机制的构造。原始的注意力机制如公式(11)、公式(12)所示:其中I是用户信息u 和文本向量ht的信息交互矩阵,αij是句子对用户的注意力,最后通过计算αij和ht的乘积来筛选文本中的重要特征。注意力交互机制在原始注意力机制的基础上,逐步提取用户u 中的重要特征来帮助分类。如公式(13)至公式(15)所示,其中βij是用户对句子的注意力,-βj是用户级注意力,即筛选出的用户的重要特征,最终注意力权重γ 由每个用户级注意力和文本注意的加权和得到。如公式(16)所示,最后的文本表示是原始文本特征和注意力权重的乘积。

2.2.4 softmax层
层次网络最终输出含用户信息的篇章级文本向量du和含产品信息的篇章级文本向量dp。如公式(17)所示,将二者简单连接生成文本向量dt,[…;…]是连接操作符。如公式(18)所示,使用softmax 计算dt、du、dp在不同类别上的概率sxt、sxu、sxp。本文根据sxt的分布情况来预测文本的情感倾向。
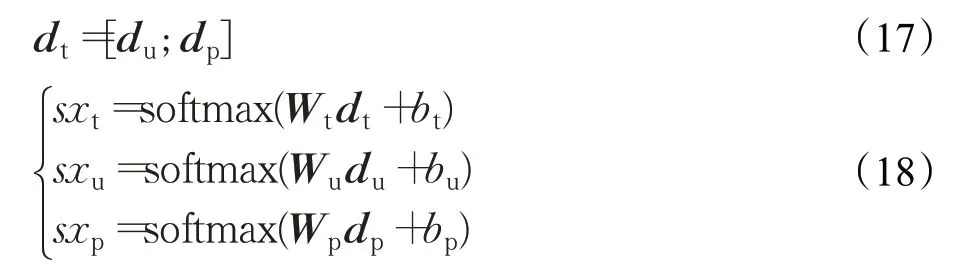
2.2.5 损失函数

3 实验结果与分析
3.1 实验数据与实验环境
Yelp2013、Yelp2014 是点评网站2013 年、2014 年的餐厅数据,IMDB 是影评数据,类别反映情感极性,数值越大表示评价越正面。训练集、验证集、测试集比例为8∶1∶1,数据集相关信息如表1所示。
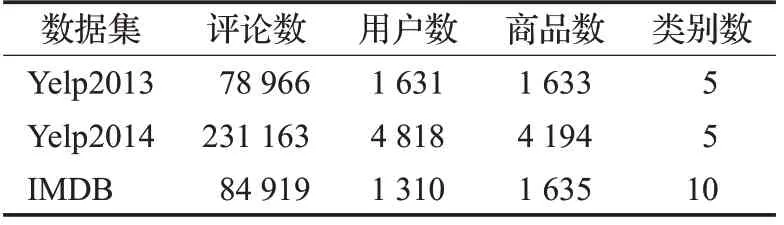
表1 Yelp2013、Yelp2014、IMDB数据集信息
本文实验环境如表2所示。
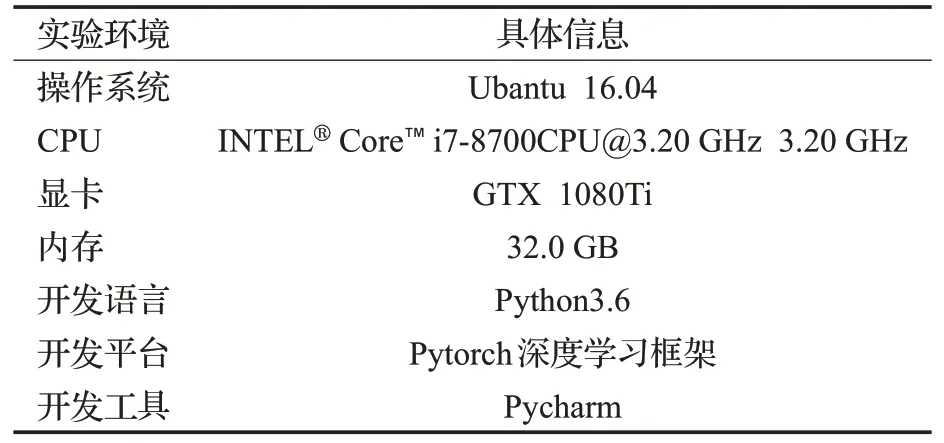
表2 实验环境
3.2 实验参数与评价指标
为了便于后续研究分析,本文采用固定参数法。相关超参数如表3所示,本文选用Glove[11]预训练的词向量来初始化文本向量,向量维数为300,BiLSTM每层单元数为200,用户和产品数据维数为200,训练过程采用Adam 来更新参数,使用随机失活和早期停止来预防过拟合,使用梯度裁剪来预防梯度爆炸。
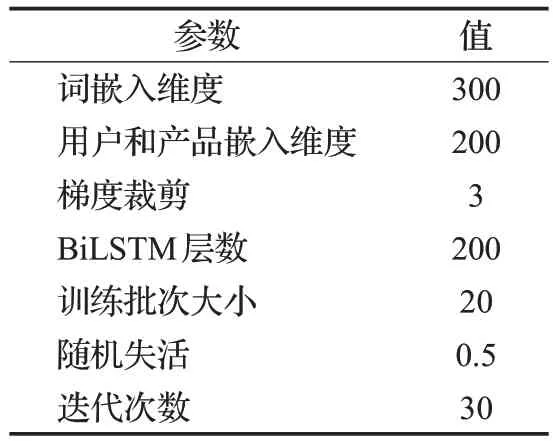
表3 实验参数设置
本文采用2个评价指标作为判定标准。如公式(23)所示,Accuracy(精确率)中N是数据集总文本数,T是模型分类正确的文本数。如公式(24)所示,RMSE(均方误差)中N是数据集总文本数,gdi是实际文本类别,pri是预测文本类别。
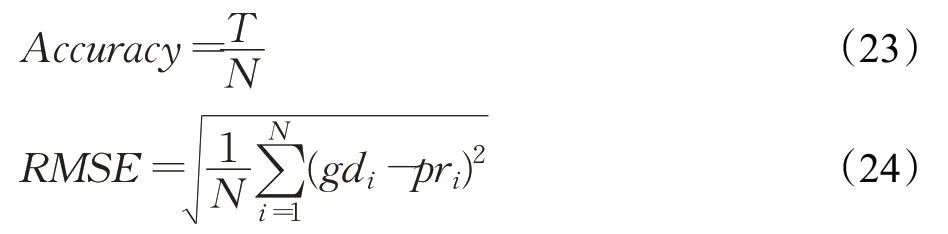
3.3 对比实验与结果分析
本文采用相同数据集下现有模型的实验结果与HNAIN进行对比,对比结果如表4所示。
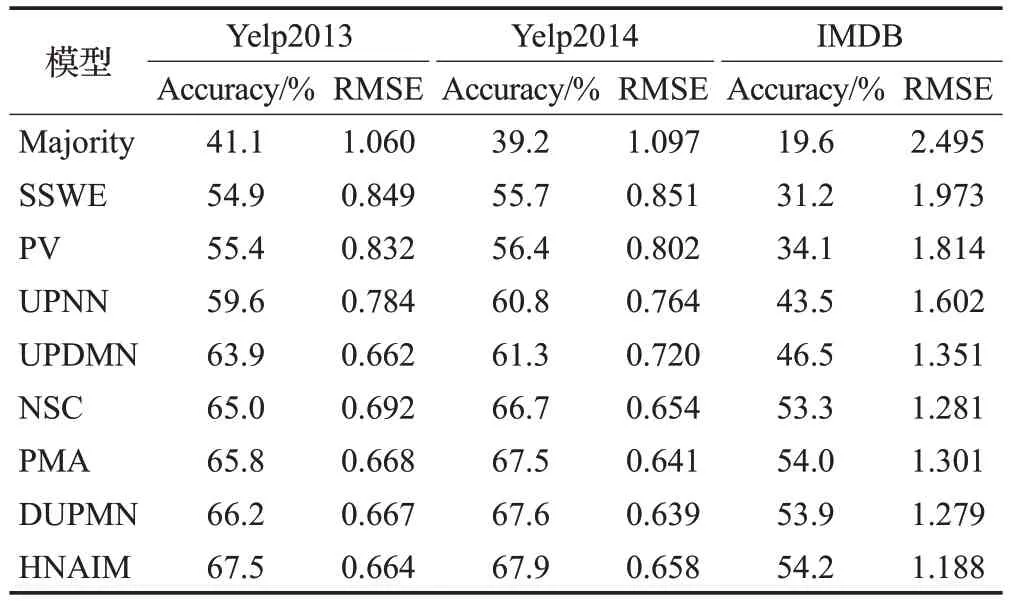
表4 不同分类模型比较
(1)Majority:将统计到的训练集中概率最大的分类类别当做测试集的分类类别。
(2)SSWE[1]:特殊训练词向量作为SVM 分类器的输入特性进行情感分类。
(3)PV:利用PVDM算法进行情感分类。
(4)UPNN[6]:通过CNN 提取词向量中的信息,在建模过程中融入用户信息和产品信息来进行情感分类。
(5)UPDMN[18]:通过注意力机制考虑用户或产品相关的其他文本类别并利用LSTM对当前情感分类。
(6)NSC[7]:利用层次网络对文本特征进行编码,在建模过程中利用注意力机制来提取文本中的重要特征,最后通过softmax进行情感分类。
(7)DUPMN[19]:利用双记忆网络提取用户和产品的重要特征,利用双层LSTM结合提取到的用户和产品特征对文本进行分类。
(8)PMA[20]:与NSC 类似,但利用如用户排名偏好法等外部方法来提高分类效果。
由表4 可以看出,在三个数据集上Majority 效果最差,这是由于该模型无法获得任何文本信息。SSWE和PV的效果优于Majority,但是模型效果仍低于其他深度学习分类模型,这反映了深度学习模型在情感分类方面的良好性能。UPNN 和UPDMN 则是分别利用CNN 和LSTM进行分类,并在过程中引入用户和产品信息后模型效果得到提升,证实了该信息的添加对情感分类任务有正面影响。NSC模型使用层次结构进行情感分类,在UPNN 和UPDMN 基础上进一步提高了分类性能,初步验证了考虑文本不同粒度的层次网络具有更强大的特征提取能力,PMA 在NSC 的基础上利用用户偏好排名法提高了分类性能。DUPMN 结合用户和产品信息利用层次网络进行分类,取得了当前对比模型中的最好效果。本文HNAIM模型最终分类准确率优于所有相关模型,均方误差与对比模型最好效果基本持平,这说明本文的HNAIM模型在针对评论文本的情感分类任务上有一定的可行性。
3.4 模型分析
3.4.1 注意力交互机制对模型性能的影响
为了验证注意力交互机制的作用,保持HNAIM 模型其他部分不变,将注意力交互机制替换成如公式(11)和公式(12)所示的经典注意力机制计算的注意力权重,即模型HNAM。在三个数据集上的实验结果如表5 所示,通过三个数据集的结果可以看出,本文HNAIM模型在两个评价指标下的效果均优于对比模型HNAM。由此可以证明注意力交互机制在本模型中可以起到提高模型效果的作用。
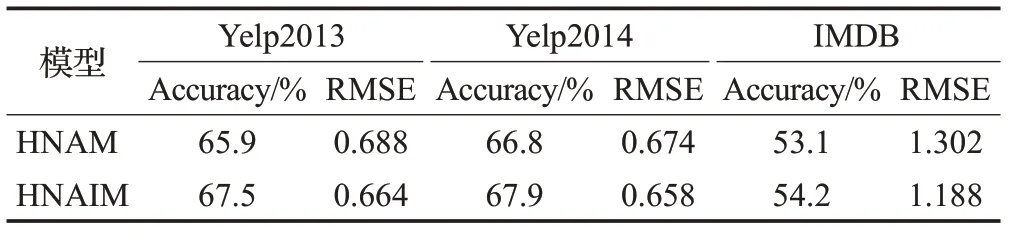
表5 注意力交互机制对模型的影响
3.4.2 语义提取层对模型性能的影响
HNAIM模型利用BiLSTM构建层次网络来提取文本中重要的语义信息。为了验证BiLSTM 提取到的上下文信息对模型性能的影响,保持模型其他部分不变,将BiLSTM 替换成LSTM,LSTM 仅从一个方向上处理文本信息。在三个数据集上的结果如表6 所示,由BiLSTM 构成的层次网络性能在两个评价指标上均优于LSTM 构成的层次网络。由此可见双向网络结构效果优于单向网络。本文利用双向网络在不同粒度提取到的语义信息更有利于情感分类。
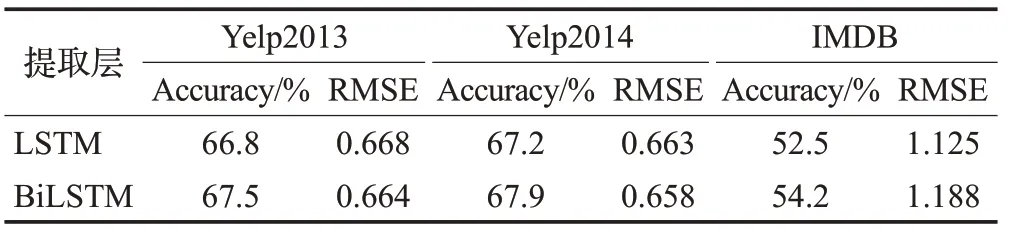
表6 语义提取层对模型的影响
3.4.3 基于用户和产品的损失值对模型性能的影响
本文通过试凑法进行权重配置,将用户视角下的损失值lossu和产品视角下的损失值lossp作为辅助分类信息来帮助分类。为了对比lossu和lossp在最终损失函数中的占比程度对实验结果的影响,选取具有代表性的四组权重,如表7 所示,λ1、λ2、λ3(λ1+λ2+λ3=1)是lossu、lossp、losst的权重系数,权重1 用于考察不含辅助分类信息对分类的影响,权重2 和权重3 用于考察只含单一辅助信息对分类的影响,权重4 是本文选用的权重配置。实验结果如图2所示。
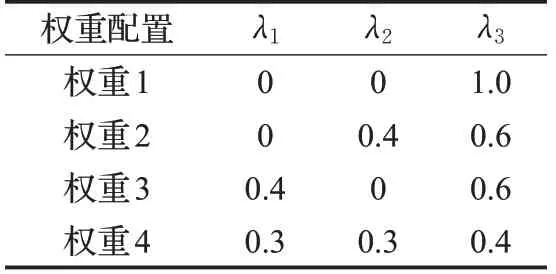
表7 不同损失权重配置
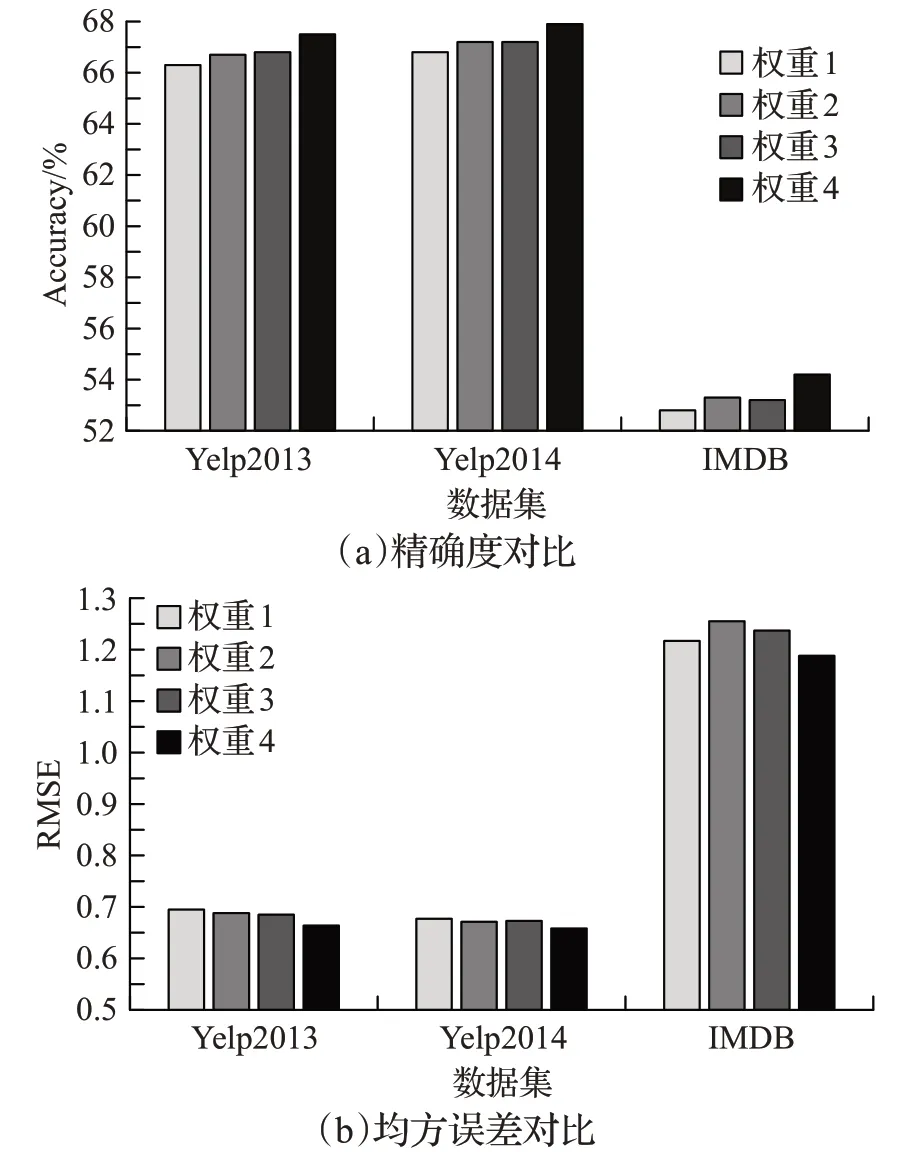
图2 不同权重值对实验的影响
由图2(a)和图2(b)可以看出,对三个数据集来讲,本文模型选用的权重4 在两个评价指标下的效果均优于其他权重配比,这说明本文的参数设置是合理的。不含lossu和lossp作为辅助分类信息的权重1在两个评价指标下均表现出最差的效果,这说明lossu和lossp可以起到帮助分类的效果。权重2和权重3在两个评价指标下的效果各有千秋,这反映出lossu和lossp对最终分类结果的影响力相仿。综上可知,lossu和lossp作为辅助分类信息能有效帮助分类,也证实本文的HNAIM 模型有一定的合理性。
4 结束语
针对评论文本提出HNAIM模型。由于文本中存在词级、句级和篇章级等不同粒度的语义信息,因此该模型选择层次网络结构。层次网络首先利用BiLSTM 处理文本的词级语义,得到的句级特征经过BiLSTM进行处理,最终生成篇章级特征用作最后的分类。由于文本中描述词与用户和产品的相关度不同,层次网络将用户和产品信息分开建模。本模型在句级和篇章级利用注意力交互机制,在抽取文本中较为重要特征的同时,也尝试抽取产品和用户对分类贡献度大的特征来帮助分类。三个公开数据集上的实验结果表明本模型可以提高分类效果,具有一定的可行性。下一步将深入研究用户和产品信息对分类效果的影响。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
