
柴达木盆地西部古近系咸化湖盆烃源岩总有机碳含量预测
2021-05-14 07:35太万雪刘成林田继先冯德浩
特种油气藏 2021年1期
太万雪,刘成林,田继先,冯德浩,曾 旭,李 培,孔 骅
(1.油气资源与探测国家重点实验室,北京 102249;2.中国石油大学(北京),北京 102249;3.中国石油勘探开发研究院,河北 廊坊 065007)
0 引言
烃源岩总有机碳含量(TOC)是识别有效烃源岩的重要依据,相关学者在TOC预测研究中通常使用的手段有多元回归法、ΔlgR法、人工神经网络法以及支持向量机和核磁共振测井等[1-4]。ΔlgR法是Passey等[5]通过大量数据拟合和实验分析提出的一种经典理论。国内外学者针对原始的ΔlgR模型进行多种改进[6-7],边雷博等[8]在 ΔlgR 法基础上增加自然伽马参数,使预测模型更加稳定。但上述ΔlgR法均未针对受盐度影响岩性变化复杂的烃源岩地层进行过研究。多元回归模型通过建立自变量与因变量的数学关系进行TOC预测,计算简便,但一般仅是根据数学关系进行模型建立,缺乏地质思维。人工神经网络模型通过模拟人脑神经元处理信息的机制,对输入样本的TOC与测井曲线的相关性进行学习,从而预测未知层位的TOC。近年来国内外大量学者在预测TOC时,均大量应用人工神经网络方法[9-12]。但在使用神经网络方法时,未针对输入测井参数进行优选,参数冗余导致模型泛化能力弱。
目前柴达木盆地西部古近系咸化湖盆仍然采用单一的方法进行TOC的预测,前人忽略了盐度对测井参数及TOC的影响。在柴西地区分别应用多元回归法、优化的ΔlgR法和BR-BP神经网络法进行TOC预测,讨论3种方法预测TOC的精度,通过对方法的优化提高TOC预测精度。解决柴西地区不同咸化条件下烃源岩预测的难题,为国内外咸化烃源岩TOC的预测提供了一种切实可行的流程及方法。
1 地质背景
柴达木盆地是中国典型的高原山间断陷盆地,位于青藏高原东北部。目的层烃源岩为古近纪下干柴沟组上段(E32)。根据郭佩[13]研究,E32层沉积期柴达木盆地主要有狮子沟超咸化中心、红沟子-油泉子地区2个咸化中心(图1)。E32层烃源岩关键井测井参数齐全,TOC整体上不高,但富烃凹陷面积较大,有效烃源岩规模较大,具有较高的勘探开发价值。

图1 柴达木盆地西部构造划分及地层柱状图Fig.1 Structural division and stratigraphic column of western Qaidam Basin
由图1可知,柴达木盆地狮子沟地区E32层受高盐度影响,石盐段及灰质泥岩段测井曲线变化异常,石盐段测井曲线呈异常高声波时差、高电阻率等特征,而碳酸盐岩与泥岩混积段测井曲线易震荡。因此,针对测井曲线的异常表现,高盐度与中—低盐度地区需要分别建立TOC预测模型,选取狮子沟井位建立高咸化TOC预测模型,选取小梁山井位建立中—低咸化TOC预测模型。
2 咸化湖盆烃源岩有机碳含量预测模型
2.1 测井曲线多元回归模型
根据E32层烃源岩的单一测井参数与TOC的相关性对比(图2),选取自然伽马(GR)、声波时差(AC)、井径(CAL)、电阻率(Rt)以及中子孔隙度(CNL)参数进行多元回归拟合,舍弃电导率(σ)参数。使用SAS软件求解多元回归未知系数。具体回归模型见表1。

图2 下干柴沟组上段测井参数与TOC响应关系Fig.2 Relationship between well logging parameters and TOC response in upper member of Lower Ganchaigou Formation

表1 下干柴沟组上段多元回归预测模型Table 1 Multiple regression forecast model of upper member of Lower Ganchaigou Formation
使用多元回归方法建立的下干柴沟组上段烃源岩有机碳预测模型(表1)相关系数一般为0.500 0~0.700 0,预测结果较差,在此基础上使用图2优选出的测井参数进行有机碳ΔlgR预测与神经网络模型预测。
2.2 优化的ΔlgR预测模型
该文在边雷博[8]的研究基础上,应用归一化原理,采取一一映射法将不同范围的声波时差与260~460 μs/m声波时差一一映射,将不同范围的电阻率与声波时差为260~460 μs/m时对应的电阻率一一映射,并建立预测模型。
首先将电阻率和声波时差归一化:


式中:Rt为电阻率,Ω·m;Rtmax、Rtmin为电阻率曲线叠合段最大值、最小值,Ω·m,Rt基值为电阻率基线值,Ω·m;Δt为声波时差,μs/m;Δt基值为声波时差基线值,μs/m;Δtmax、Δtmin为声波曲线叠合段最大值、最小值,μs/m。
根据声波时差的应用范围,Δtmax为460 μs/m,Δtmin为 260 μs/m,式(1)变为:

该公式与原始ΔlgR法相比,在处理深层低声波时差段烃源岩的有机碳预测方面,具有较高的准确性。
高咸化模型(狮 20井)Rt基值为 8.64 Ω·m,Δt基值为207.83 μs/m;中—低咸化模型(梁 3 井)Rt基值为 7.41 Ω·m,Δt基值为 200.85 μs/m。利用SAS软件确定待定系数,代入式(3)得到ΔlgR预测模型。
高咸化ΔlgR模型:

中—低咸化ΔlgR模型:
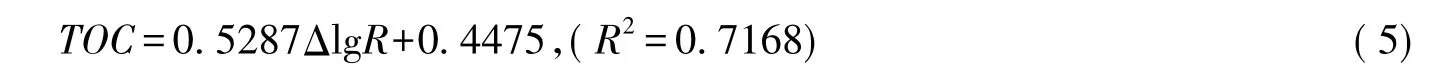
2.3 BR-BP神经网络模型
影响TOC表达的测井参数较多,为了避免参数冗余降低神经网络模型泛化能力,首先进行测井参数的主成分分析[14]。根据计算的高咸化模型主成分累计贡献率(表2),给出主成分个数,当前a个主成分的累计贡献率达到85.00%时,满足预测需要,停止主成分引入。
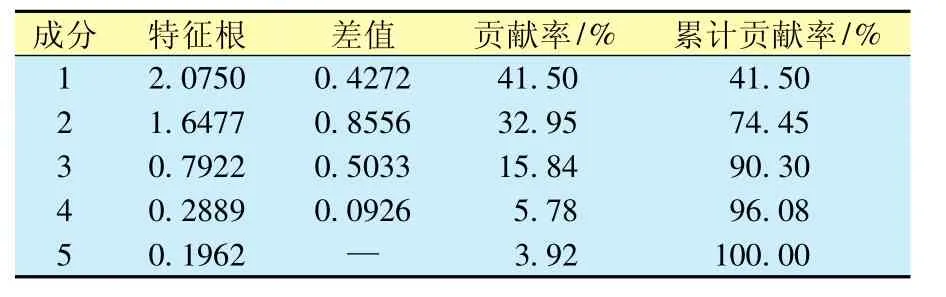
表2 测井参数主成分分析Table 2 Principal component analysis of loging parameters
使用SAS软件得到的主成分Y1、Y2、Y3的计算公式为:
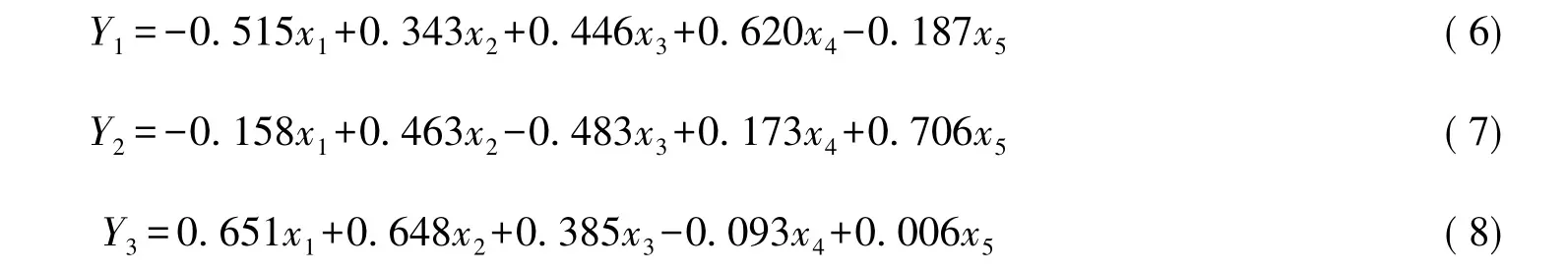
式中:Y1、Y2、Y3代表引入的3个主成分;x1为自然电位;x2为自然伽马;x3为声波时差;x4为电阻率;x5为井径。
引入主成分Y3时累计贡献率达到90.30%(表2),超过预测TOC要求的85.00%,引入结束。同理,可以进行中—低咸化BP模型主成分分析。
在进行BP神经网络训练时,部分输入参数受盐度影响,局部测井曲线出现极值,曲线波动大,训练系统为了使这部分样本与训练集完全匹配,导致训练过程过度严格,出现过拟合现象。过拟合得到的模型在训练集表现良好,但验证集表现很差,模型泛化能力弱,不能应用到其他井位。因此,此次模型选取的是贝叶斯正则化算法[12],算法在损失函数中添加一个L2正则项,用来抑制过大的模型参数,缓解过拟合现象,具体如式(9)所示:等式右侧第1项代表原始损失函数,称为C0项;等式右侧第2项是引入的L2正则项。
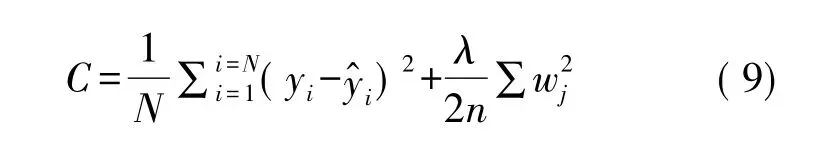
式中:N为样本总数;yi和为第i个样本的真实值和预测值;n为训练集样本数;wj为网络权值;λ为正则项系数,通过λ权衡正则项与C0项的比重。
式(9)提高了算法的收敛速率和泛化能力。针对研究区将测井数据按75%、15%、15%的比例分配训练集、测试集以及验证集,拓扑关系如图3所示。

图3 BP神经网络拓扑关系图Fig.3 Topological graph of BP neural network
3 结果与讨论
3.1 模型应用结果
综合建立的模型,针对3种方法进行应用,选取高咸化地区狮20井、低咸化地区梁3井绘制了实测TOC与预测TOC的拟合图(图4),使用相关系数(R2)作为评价标准。
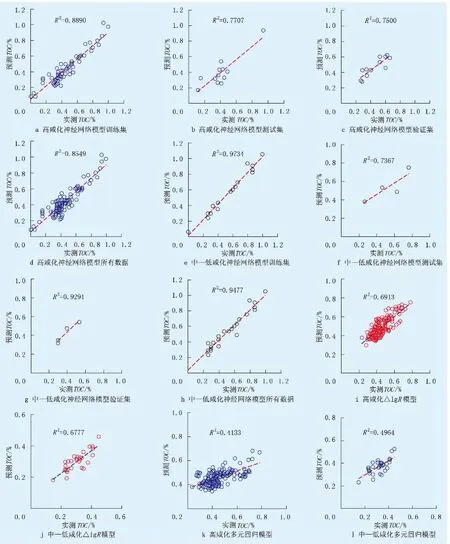
图4 下干柴沟组上段实测TOC与预测TOC对比Fig.4 Comparison of measured TOC and predicted TOC in upper member of Lower Ganchaigou Formation
回归模型R2均小于0.500 0,总体表现最差,离散度也最大。高咸化的ΔlgR模型R2为0.691 3;中—低咸化ΔlgR模型R2为0.677 7,ΔlgR模型在高咸化地区预测结果更好,ΔlgR模型整体上优于回归模型。高咸化神经网络模型训练集 R2为0.889 0;中—低咸化训练集R2为0.973 4,其中,高咸化模型的验证集(图4b、c)R2低于训练集较多,说明盐度在一定程度上影响了模型稳定性。
3.2 讨论
图5为不同盐度地区3种预测模型的实际应用,针对图5的应用结果进行模型预测结果讨论。

图5 下干柴沟组上段烃源岩TOC预测模型单井对比Fig.5 Single well correlation diagram of TOC prediction models for high salinity and medium-low salinity source rocks
神经网络模型由于方法的优越性,整体上表现最优,通过大量的机器学习,达到90%以上的准确率。由图5可知,神经网络模型在高咸化地区的预测效果没有低咸化地区效果明显,中—低咸化模型数据收敛性最好。通过贝叶斯算法虽然提高了模型的泛化能力,但在实际预测中,输入测井参数的品质、网络参数(权值、迭代次数、训练速率等)都会影响模型预测结果。且高咸化模型的输入参数较复杂,测井参数与TOC之间的对应关系也没有中低咸化模型简单,这些原因都会提高机器学习难度,降低预测准确度。此外,机器学习需要大量数据支撑,在测井数据较少的地区不能使用神经网络预测。
优化的ΔlgR仅需要声波和电阻率2条曲线,对测井要求较低。图5中优化的ΔlgR曲线明显具有声波曲线与电阻率曲线的变化特征,在沉积过程中,高盐度地区受盐度变化影响,碳酸盐岩与泥岩大量互层的烃源岩段声波曲线超出公式应用范围,但应用归一化原理,降低了盐度影响,使得高盐度模型表现优于低盐度地区模型。同时在应用过程中发现,由于烃源岩层在纵向上跨越深度较大,在基值的选取中不能应用于整个层位,需要分层位、甚至在同一层分段拟合ΔlgR公式,工作量较大。
图5回归模型预测趋于将曲线中心化,曲线左右幅度变化较小,整体预测TOC变化程度较小。在高盐度和中—低盐度地区应用模型预测差异小,模型对盐度不敏感,回归模型仅根据数学方法预测,TOC与拟合值结果偏差较大。
4 结论
(1)根据测井曲线参数,采用优化的ΔlgR和BR-BP神经网络对柴西地区下干柴沟组上段烃源岩的TOC进行预测,根据咸化程度不同分别建立预测模型。
(2)多元回归模型拟合效果趋近中心值,表现平庸,准确率一般;优化的ΔlgR模型应用归一化原理,有效减小盐度影响,但基值选取繁琐,曲线普适性不好;BR-BP神经网络模型的预测效果总体上最好,贝叶斯算法有效提高了模型泛化能力。高咸化地区受复杂地质条件影响,预测效果较低咸化模型表现差,在处理高咸化模型时应注意网络参数的设定。
(3)在柴达木西部地区下干柴沟组上段(E32)具体应用时,优先选取BR-BP人工神经网络预测,针对盐度对岩性和测井曲线的变化,分别建立了高盐度神经网络模型和中—低盐度神经网络模型,可在全柴西范围内应用。当部分井测井数据较少而不足以支撑机器学习以及高盐度神经网络模型响应不好时,选用优化后的ΔlgR模型进行辅助研究,建立的模型可以覆盖柴西全区,有效指导盆地内高精度烃源岩评价。
猜你喜欢
测井技术(2022年3期)2022-11-25
河北渔业(2022年10期)2022-10-15
中国海洋大学学报(自然科学版)(2022年9期)2022-09-05
重庆科技学院学报(自然科学版)(2022年3期)2022-07-08
文萃报·周二版(2022年10期)2022-03-19
中国石油大学学报(自然科学版)(2022年1期)2022-02-28
科学与生活(2021年18期)2021-11-24
科技创新导报(2020年19期)2020-09-26
石油研究(2020年3期)2020-07-10
地球(2015年8期)2015-10-21
