
基于公交刷卡数据的城市通勤时空分析
2021-05-14 03:57刘晓柳林,2*邹健
计算机应用与软件 2021年5期
刘 晓 柳 林,2* 邹 健
1(山东科技大学测绘科学与工程学院 山东 青岛 266590) 2(国家测绘局海岛(礁)测绘技术国家测绘地理信息局重点实验室 山东 青岛 266590)
0 引 言
城市的公交车系统每天都会产生海量的时空轨迹数据,包括公交刷卡数据和GPS定位数据等。当数据无缺失时,将公交刷卡数据与GPS定位数据融合易得到乘客的上车站点。由于大部分城市采取一票制刷卡制度,刷卡信息中不包含乘客的下车站点及时间,无法获取乘客完整的出行链和空间出行信息[1],因此快速准确地从公交数据中提取出乘客的上下车站点及时间是公交数据挖掘的基础[2]。
目前已有一些有关利用公交刷卡数据进行的研究,但主要是针对下车站点及OD矩阵的推断。文献[3]提出了公交出行节的概念,根据乘客的出行节是否连续分多种情况来推断乘客的下车站点,推算模型比较复杂,处理效率较低;文献[4]提出了一个基础的基于时空邻近性的恢复算法和一个改进的基于历史的恢复算法,但需要借助于地铁刷卡信息;文献[5]对公交出行行为进行了分类,推算了有往返出行和有换乘的出行乘客的出行起止点,但未考虑到其他乘客。总体来说,现有的基于公交IC卡数据的站点推算方法还有很多的不足,因此本文对公交IC卡数据进行了深入的探讨与研究,改进了传统的上车站点推导算法,提出了下车站点推导算法,以青岛市西海岸新区的公交刷卡数据、GPS定位数据为例验证了算法的可行性,并利用公交刷卡数据识别了通勤乘客,进行了公交通勤分析。
1 研究数据
本文研究数据来源于青岛市琴岛通卡股份有限公司及真情巴士集团提供的公交刷卡数据、GPS定位关联站点数据、真情巴士集团司机档案数据、驾驶员对应车号数据(真情巴士集团车辆调度数据)等,在分析了各数据的字段后建立了数据之间的关联关系,如图1所示。
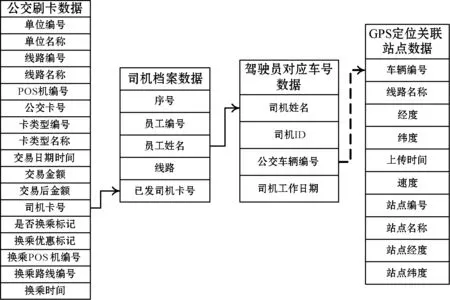
图1 数据字段及关联关系
公交刷卡数据中无车辆编号,无法直接与GPS定位关联站点数据匹配上车站点,首先可以通过司机档案数据匹配公交刷卡数据中司机卡号所对应的员工姓名,然后再通过驾驶员对应车号数据(即车辆调度数据)结合司机工作日期匹配到车辆编号,匹配完成即可与GPS定位关联站点数据融合进行处理。
2 上下车站点的识别
2.1 上车站点识别
根据公交刷卡数据的字段可以发现单纯地通过公交刷卡数据无法获得乘客的上车站点,因此结合GPS定位数据来识别。通常乘客的刷卡时间Ti与GPS定位数据中同一车辆的到离站时间区间(Tas,Tcs)满足式(1)时,可判定车辆所在的站点S即为乘客的上车站点[4]。
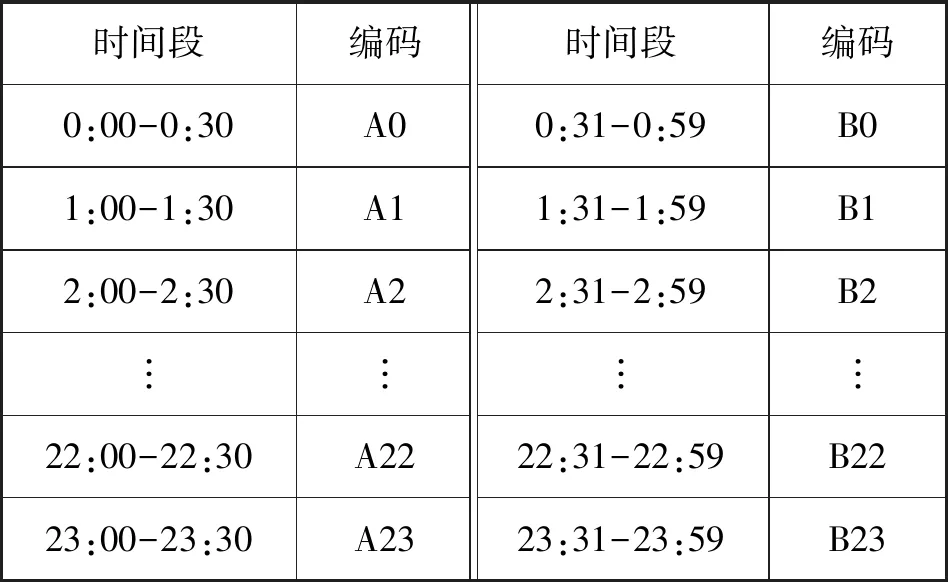
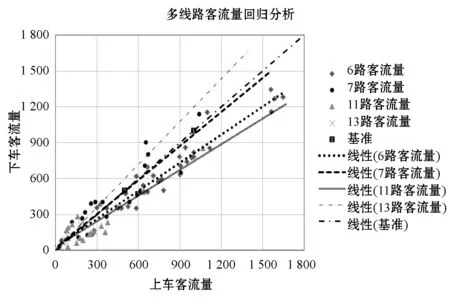
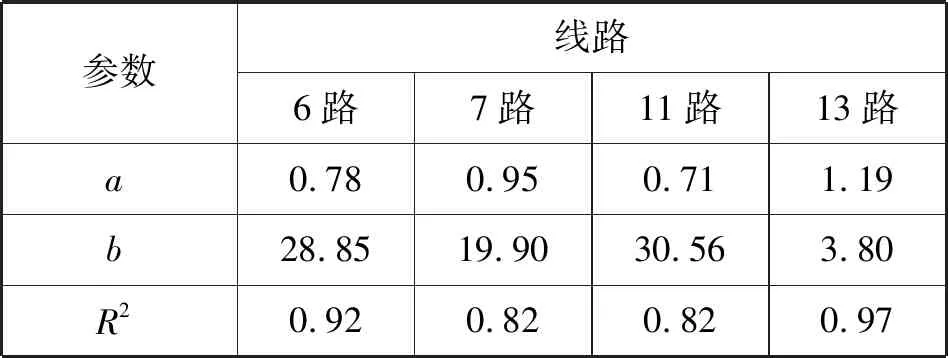
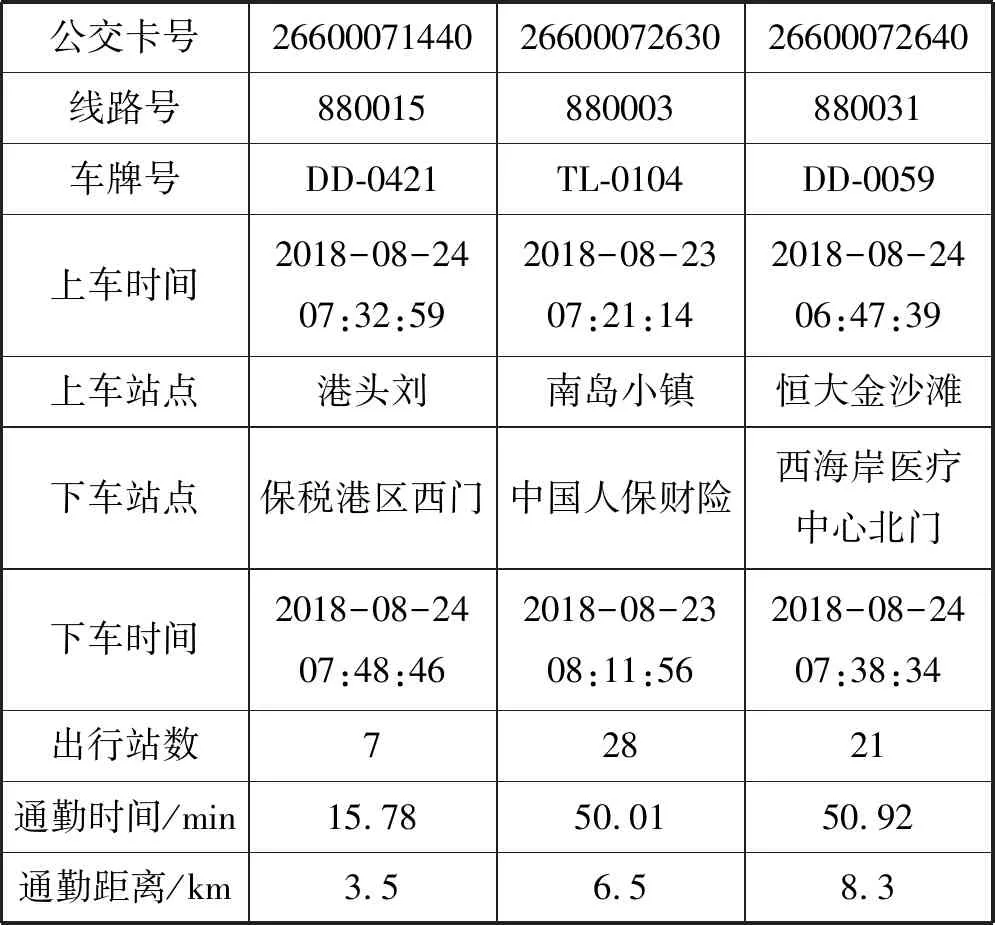
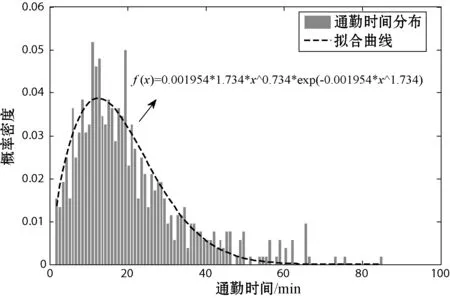
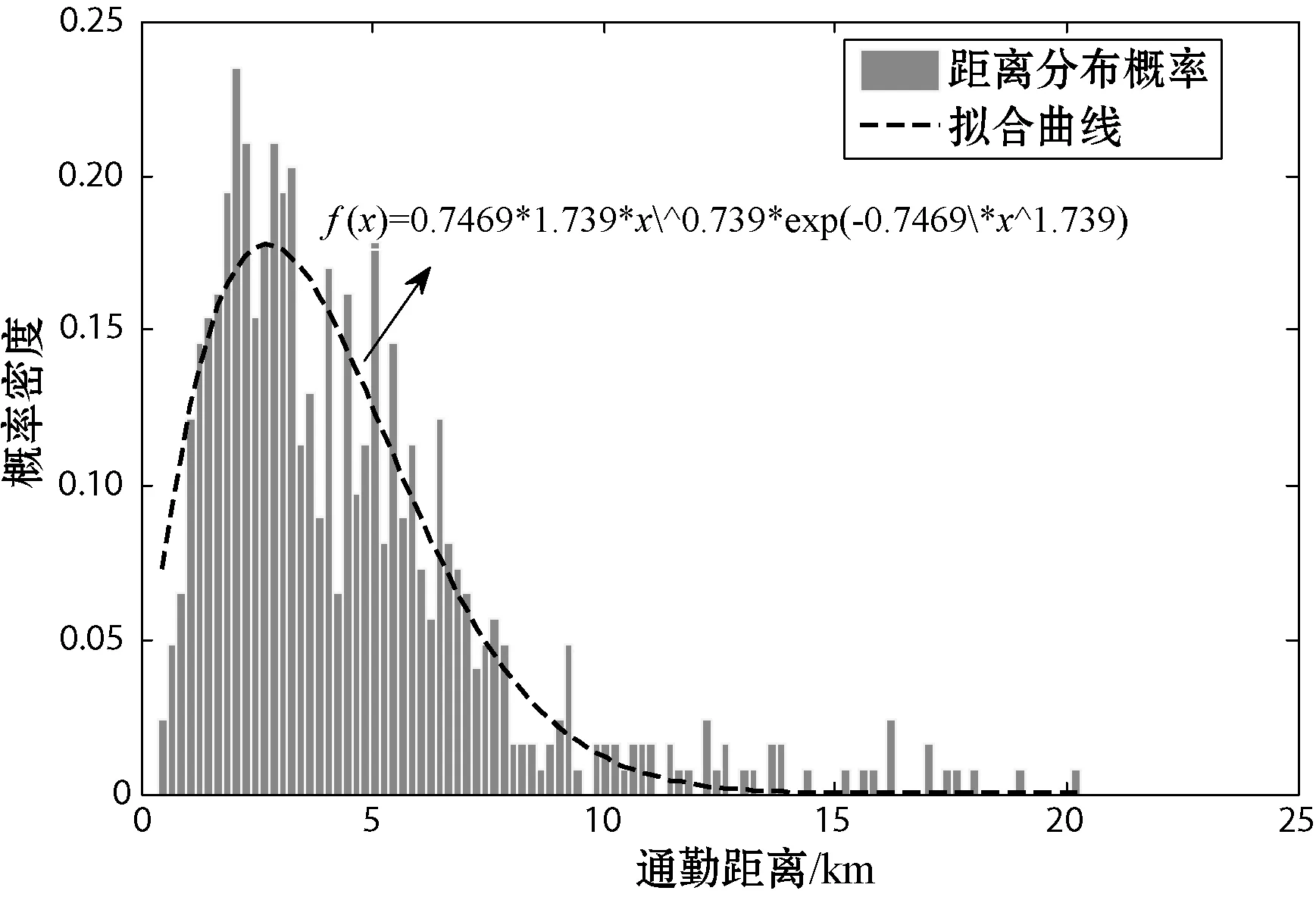
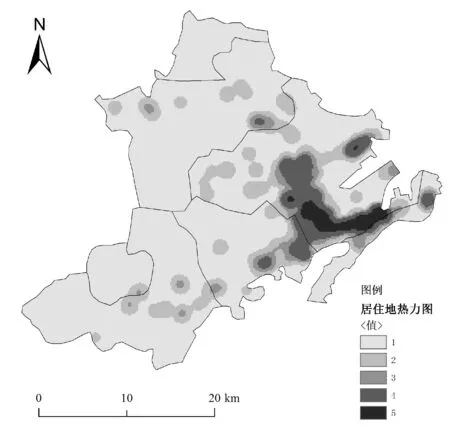
Tas (1) 但在公交运营中,有时会存在多辆公交车同时到站的情况,后续公交车为了节省时间会提前开门上客,此外在高峰时段因前门拥挤,部分乘客会选择后门上车[5],在公交离站后刷卡,因此部分乘客刷卡时间会在车辆到离站时间区间外。 为提高上车站点识别率,本文引入了弹性阈值对到离站时间区间进行了改进,若乘客刷卡时间Ti满足式(2)时,则可判定站点S为上车站点。 Tas-φ (2) 式中:φ为公交车到离站弹性阈值。 考虑到公交运行时长、候车时间等因素,在进行下车站点推算时首先以2小时为阈值,将前后两次刷卡时间差值小于2小时的出行设为连续出行,否则为非连续出行(一天内仅一次刷卡记录的出行也为非连续出行),所以对于一天内有多次刷卡记录的乘客可以有多次连续出行或非连续出行。 对任一乘客q在线路L上任一站点i上车,为推算乘客在任一站点j下车的概率提出了如下假设: 1) 对于连续出行来说,乘客上次乘车的下车站点大多接近下次乘车的上车站点[5]。 2) 对于非连续出行,乘客当次乘车的下车站点为下游高频站点[5]。 3) 对于下游无高频站点的非连续出行,乘客的出行规律服从整体公交乘客的出行规律,即乘客会选择吸引强度较大的站点下车,且出行站数服从泊松分布[6]。 2.2.1基于整体出行规律分析 根据以往的公交客流分析结果,从公交乘客整体上看,乘客的出行站数服从一定的分布规律,且各站点吸引强度不同。因此,在推算乘客下车站点时应将出行站数和站点吸引强度两个因素考虑在内。 1) 单纯考虑出行站数。 居民的公交出行距离通常处于一定范围内,而出行距离可以用乘坐的站点数量来表示。已有的研究指出,下车概率随途经站点数量服从泊松分布[6-8]。因此仅受途经站点数量一个因素影响时的下车概率Fij的公式如下: (3) 式中:λ为途经站点数量的均值,当上车站点i下游站点数量不足λ时,λ=m-i,m为单条线路站点总数。 2) 单纯考虑站点吸引强度。 站点吸引强度是用一条线路上各站点的客流量来表示的,不同站点的吸引强度不同。由于居民的出行具有往返性,各站点的上下车客流量基本相当[4]。因此可用各站点上车客流量来计算站点吸引强度Wj,公式如下: (4) 式中:Sk为站点j的上车人数;m为某一线路站点总数。 2.2.2基于个体出行规律分析 从单个乘客q来考虑,定义下游站点集Eq、高频站点集Fq和衔接站点集Gq[6],下车站点的推算分以下几种情况: 1)C1:对于乘客的连续出行,若Gq非空,则站点j的吸引权重Z1如下: (5) 2)C2:对于Gq为空集、Fq非空的乘客的连续出行或者Fq非空的非连续出行,下游站点j吸引权重Z2如下: (6) 式中:Sj为乘客q于研究期内在站点j的上车次数;p为高频站点集中的站点个数;Sp为乘客在高频站点p的近期上车总次数。 3)C3:对于Gq、Fq均为空集的乘客的连续出行和Fq为空集的乘客的非连续出行,下游站点j的吸引权重Z3如下: Z3=1/d (7) 式中:d为下游站点j与下次刷卡上车站点的标准化距离,当乘客在研究期内的上车站点数为1时,d=1。 综上所述, 本文将单个乘客的出行特征融入到整体公交乘客中,在任一线路任一站点i上车的单个乘客,在同线路上站点j下车的概率Pij的推算公式为: (8) 式中: (9) 根据上述下车站点算法即可推算公交乘客的下车站点,再将其与GPS定位数据结合即可获得乘客的下车时间。 上下车站点匹配完成后,需要对匹配结果进行验证。常规的验证方法是将匹配结果与实验调查值进行比较,但在实际生活中,跟踪调查单个乘客上下车站点难度较大。研究乘客的上下车站点本质上是为了分析乘客群体的出行特征,因此本文采用上下车客流量来对算法进行检验[9]。 根据公交乘客的出行特征,一天各站点的上下车客流量基本相当,即二者之间应该具有线性关系[9]: Si,on=aSi,of+b (10) 式中:Si,on为站点i的上车人数;Si,of为站点i的下车人数;a、b为回归系数,若上下车客流量基本相当,则a的值应接近1[6]。 通勤是造成城市早晚高峰的主要原因,早高峰主要集中于居住地附近,而晚高峰多发生于就业地附近。目前公交通勤已成为缓解城市交通压力的重要途径,掌握通勤者的空间出行特征对于科学布局公交站点、动态调整公交线路具有重要意义。 在对公交刷卡数据进行分析后,提出出行时间链的概念,即根据乘客每次刷卡时间所处的时间段对其进行编码,然后将乘客一天的刷卡时间码按时间先后连接起来即可获得乘客每天的出行时间链。 时间段的划分如表1所示,相邻的时间段级别相差1(即B0与A0相差1个级别,B0与A1也相差1个级别)。 表1 时间段编码 通勤群体有两大出行规律:(1) 出行天数较多,通勤群体几乎每个工作日都会出行,即提取出的出行时间链较多;(2) 出行时间相对固定,即出行时间链较稳定[10-11]。 城市早晚交通高峰主要是由通勤造成的,以前主要是根据乘客在高峰时段的刷卡记录数来识别通勤乘客[12],但该方法会将在高峰时刻有多条刷卡记录的乘客误判为通勤乘客,同时对于一些错时上下班的城市又会遗漏大量通勤乘客[13]。PTD(Position-Time-Duration)模型[14]的提出为通勤识别提供了新的思路,该模型将乘客每天的首次刷卡站点定义为居住地,将乘客在某站点的停留时长超过阈值的站点定为就业地[15-16]。 基于通勤出行的特点,本文结合出行时间链和PTD模型进行通勤乘客及其职住地的识别。将各卡号一周的出行记录汇总,按照日期和时间先后进行排序,获取乘客每天的出行时间链。时间链判定方法如下。时间链相同:每天的出行链编码完全相同;时间链相似:首次出行时间链编码相差1个级别,但两次出行时间差值在半小时以内,其他时间链编码相同的可认为对应的两天的时间链相似。将乘客一周的出行时间链进行对比,若5天的工作日中出行时间链相同或相似的天数大于等于3,则对这些乘客建立PTD模型。 若非居住地PTD模型中存在停留时长大于等于某一阈值的情况,则可确认这些乘客为通勤人员,同时PTD模型中所对应的站点即为乘客的就业地站[17]。 本文以2018年8月20日至8月26日的青岛市西海岸新区公交刷卡数据为例来进行通勤时空分析。青岛市西海岸新区位于山东省青岛市西岸,是我国第九个国家级新区,现新区辖12个街道,11个镇,可划分为十大功能区,目前新区内开通了96条公交线路,共有1 090个公交站点,站点分布图如图2所示。 图2 西海岸新区公交站点分布图 新区的西南部分主要发展农业、港口、军民融合产业,就业地相对较少。由图2可见,区内公交站点相当稀疏,因此本实验通勤分析研究过程中会去除西南部分的三个功能区(现代农业示范区、董家口循环经济区和古镇口军民融合创新示范区)。 上下车站点的识别利用MATLAB软件实现。2018年8月20日至8月26日的公交刷卡数据共180万条左右,其中工作日的刷卡数据1 347 928条,在匹配上车站点时取弹性阈值为站间停留时长的1/5,即φ=1/5(Tcs-Tas),共识别出了1 260 110条刷卡记录的上车站点,上车站点的识别率高达93.485%,与不添加阈值的传统算法相比多识别了77 910条,识别率提高了5.78百分点。 按照上文提出的下车站点算法,以6路、7路、11路、13路公交车为例,提取了各线路的刷卡数据来推算下车站点并进行验证。根据各站点的上下车客流量进行了回归分析,分析结果如图3所示。回归方程的各参数如表2所示,可以看出各线路回归方程的系数a均分布在1左右,说明上下车客流量的相关性较强;各线路的可决系数R2均大于0.8,接近于1,说明客流量的拟合效果较好,表明本文算法推断出来的各站点上下车客流量基本均衡,符合居民出行的基本特征,可以进一步用于通勤的分析。 图3 西海岸新区多线路公交客流量分析 表2 各线路客流回归参数表 在进行通勤分析时,对具有3天以上相同或相似出行时间链的乘客建立PTD模型,通过PTD模型来识别通勤乘客及其职住地。智联招聘最新推出的《中国职场人平衡指数调研报告》[18]指出青岛的日均工作时长为8.47 h,因此本文在识别通勤时将阈值设为8 h,共识别出了656 820条通勤乘客的刷卡记录,数据处理结果如表3所示(为保护乘客隐私对公交卡号进行了处理)。 表3 部分数据处理结果 根据处理结果,在MATLAB软件中对通勤时间和距离进行了多种函数的拟合,包括泊松分布、指数分布、对数分布和韦伯分布,结果显示韦伯分布的拟合效果最好,如图4-图5所示。 图4 西海岸新区公交通勤时间分布 图5 西海岸新区公交通勤距离分布 可以看出,公交通勤乘客的通勤时间与通勤距离基本符合韦伯分布,该分布具有明显的长尾效应。通勤时间主要介于6~21 min,通勤距离一般小于7 km。根据处理结果计算出西海岸新区的平均通勤时间为33 min,平均通勤距离为7.9 km,与百度地图公布的2018年度中国城市交通报告中青岛的行政区内平均通勤时间为37.8 min、通勤距离为8.3 km[19]的结果比较接近,说明了本文的识别结果较准确。 借助ArcGIS软件对通勤乘客的职住地站点进行了可视化分析,结果如图6-图8所示。 图6 居住地热力图 图7 就业地热力图 图8 西海岸新区公交通勤出行 可以看出,新区的通勤出行及职住地站点主要集中在青岛经济技术开发区,居住地相对就业地来说比较分散,居住地站点除了开发区之外,在中德生态园、灵山湾影视文化产业区、海洋高新区等均有分布。经济技术开发区集先进制造业、高端服务业为一体,区内遍布大型工业园,如海尔工业园、海信工业园、澳柯玛工业园、青岛光谷软件园等,产业集群效应吸引了大量的通勤出行,与本文的热力图中心相符。 本文首先提出了利用公交刷卡数据识别乘客上下车站点的算法,在此基础上提出了出行时间链的概念,结合PTD模型来识别通勤乘客及其职住地,并以青岛市西海岸新区的公交刷卡数据为例进行实验验证与通勤时空分析。在识别上车站点时,加入了弹性时间,上车站点的识别率达到93.485%,与不添加阈值的传统算法相比提高了5.78百分点。接着以多线路公交为例推算了下车站点,并将上下车客流量进行了回归分析,回归分析的结果表明本算法推断出来的各站点上下车客流量符合居民出行的基本特征,验证了算法的可行性。最后结合提出的出行时间链和PTD模型识别了西海岸新区的通勤乘客及其职住地,计算出的区内平均通勤时间为33 min,平均通勤距离为7.9 km,与百度地图发布的交通报告结果比较接近,此外本文识别出的区内职住地与通勤出行也与实际情况基本相符。2.2 下车站点推算
2.3 客流模型检验
3 城市通勤时空分析
3.1 出行时间链提取
3.2 通勤职住地识别
4 实例分析
4.1 研究区概况

4.2 站点识别
4.3 通勤时空分析


5 结 语
猜你喜欢
现代电子技术(2021年15期)2021-08-06数学大王·中高年级(2019年5期)2019-06-09儿童故事画报·智力大王(2018年1期)2018-10-30智富时代(2018年7期)2018-09-03智富时代(2018年7期)2018-09-03小学生·新读写(2016年5期)2016-05-14股市动态分析(2015年45期)2015-09-10小学生时代·综合版(2014年12期)2015-01-17奥秘(2014年8期)2014-08-30故事作文·低年级(2009年7期)2009-11-23
