
基于新词发现与特征融合的电力设备缺陷文本挖掘
2021-05-13 05:44陈超吴迪唐昕冯斌张又文郭创新
电气自动化 2021年2期
陈超,吴迪,唐昕,冯斌,张又文,郭创新
(1.国网浙江平湖市供电有限公司,浙江 平湖 314200;2.国网嘉兴供电公司,浙江 嘉兴 314033;3.浙江大学 电气工程学院,浙江 杭州 310027)
0 引 言
随着电网在线监测装置的普及,状态评价和故障诊断的自动化程度不断提升。然而受限于在线监测装置的覆盖率、可靠性与故障研判类型局限性问题,在目前设备运维实践中,仍有大量设备巡检记录依赖人工完成,且这部分信息常以文本形式进行记录[1]。近年来,学者开始将自然语言处理应用于电力设备文本分析。邱剑博士[2]利用K近邻方法实现故障文本分类,将文本挖掘技术应用于断路器全寿命状态评价。文献[3]与文献[4]在此基础上深入研究,提出了卷积神经网络与双向长短期记忆网络,提升了分类效果。
上述研究对模型结构进行了多种探索,但在文本预处理与特征融合方面并未开展较多研究。为提升电力缺陷文本挖掘效果,本文在文本数据预处理与特征融合方面开展研究。首先采用新词发现算法,扩充电力专业词汇;其次在特征融合方面,融合字与词级别特征;最终通过注意力机制优化的卷积神经网络对电力设备缺陷文本进行训练,并开展对比试验。
1 基于新词发现的文本数据预处理
1.1 基于凝固度-自由度的新词发现
为全面覆盖具体的训练语料中所有的专业词汇,除了通过导则规范梳理出专业词汇外,还需对训练语料基于新词发现算法进行数据挖掘,再经由人工审核作为词典的补充。本文采用基于NGRAM凝固度的新词发现方法,对于一个字符串序列,用凝固度表征几个字符之间联系的紧密程度。以三个字符构成的字符串为例,其凝固度定义如下:
(1)
式中:P为在语料中该字符串出现的概率;N为字符串的凝固度;abc为由三个字符a、b、c构成的字符串。通过限定不同GRAM的凝固度阈值,筛选出所有高于阈值要求的NGRAM字符串集合,并保留这些字符串的左右邻居字符,再将这些候选字符串通过自由度进行一定的筛选。某字符串的自由度为所有左邻居字符和所有右邻居字符的信息熵中较小的一个,如式(2)所示。
R=min{-∑P(cleft)log2P(cleft),
-∑P(cright)log2P(cright)}
(2)
式中:P为在语料中该字符串出现的概率;Plog2P为该字符的信息熵;cleft和cright为该字符的左邻居字符和右邻居字符。对不同GRAM词语进行自由度的阈值设置,进一步筛选出自由度高于阈值标准的词语,即可获得最终的新词。
1.2 停用词表构建
在电力设备缺陷记录文本中,有部分无用信息,需要在分词阶段识别出这些无用特征并加以剔除。停用词包括:各种中文标点符号;一些无实义的错误记录,如“其他”“1号”和“Ⅱ回”等表征设备编号的词语。
2 融合字词特征的文本向量化表示
2.1 文本特征表示
本文采用word2vec模型[5]作为特征提取方法。它是一种常用的文本特征表示方法,利用局部上下文窗口的方式进行滚动训练,然后利用神经网络训练结束后的模型参数作为向量化依据,生成向量蕴含丰富的上下文信息。
2.2 字词特征融合
利用字、词两种层次对输入文本进行划分,能够更好地保留不同级别的信息供模型分析组合,流程如图1所示。
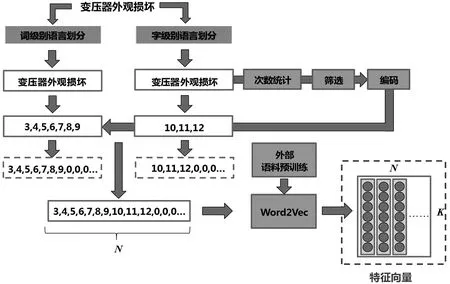
图1 NLP任务中自注意力机制示意图
3 深度学习模型构建
3.1 文本卷积网络
文本卷积神经网络[6]输入为尺寸为N×K的二维空间向量。卷积部分使用三种卷积核尺寸,分别为3×K、4×K和5×K,利用三种不同尺寸卷积核进行特征提取,并利用池化均值池化或最大值池化,进一步缩减特征维度。基于卷积操作的特征提取是模型的关键。
3.2 自注意力机制
注意力机制(attention)[7]是模仿人类注意力所设计的一种学习机制,利用可学习的注意力权重作为输入的不同部分,分配不同的注意力,以保证模型能够在大量的输入特征中快速地获取有效信息。
注意力机制可以抽象结构为求取Query、Key和Value之间的关系。
自注意力机制(self attention)当中,Query、Key和Value本质上都采用相同内容,从而获取输入不同文本特征单元之间的依赖关系,如图2所示。具体计算公式如式(3)所示。

图2 NLP任务中自注意力机制示意图
(3)
式中:Q、K、V分别为输入问询Query、键Key和Value值;dk为字/词向量维度;Attention为注意力值;Softmax为归一化指数函数。
3.3 注意力优化的卷积网络文本分类模型
传统的文本卷积网络虽能够实现高维特征的抽取,但未对关键性的元素加强“注意”,对特征的关键程度判别能力不足。自注意力机制,通过对文本向量进行注意力计算获得加权后的向量特征,再基于文本卷积网络提取特征,以实现分类模型效果的优化,如图3所示。

图3 注意力机制优化文本卷积网络结构
4 算例分析
4.1 数据划分与评价指标说明
利用随机抽样将某地区电网缺陷单数据按8∶2划分为训练集及测试集。
测试评价指标为测试集、测试集的准确率(accuracy)和Ma-cro-F1值。二分类问题中常用的判别指标为准确率(accuracy)、F1-measure等。准确率为分类正确的样本数除以总样本数,F1-measure为精确率与召回率的调和平均值,其中精准率是预测和真实类别均为正的样本数除以预测类别为正的样本总数,召回率是预测和真实类别均为正的样本数除以真实类别为正的样本总数。
对于N分类问题,可以将每一类数据轮流作为正类,其他类别均作为负类,计算N次F1-measure,记作F11,F12,……,F1N。Macro-F1可表示为:
(4)
式中:N为分类数目;F1i为第i类数据作为正类时的F1-measure值。
4.2 数据预处理及特征融合效果校验
为验证所提出数据预处理与特征融合方法的有效性,开展如下对比试验:第一组为只采用字级别特征;第二组为采用仅基于jieba默认分词后的词级别特征;第三组为基于新词发现扩充词典后的词级别特征;第四组获取一、三组特征,实现字词级别特征融合。四组模型均为本文所提出的注意力机制优化卷积神经网络(ATT+CNN),结果如表1所示。
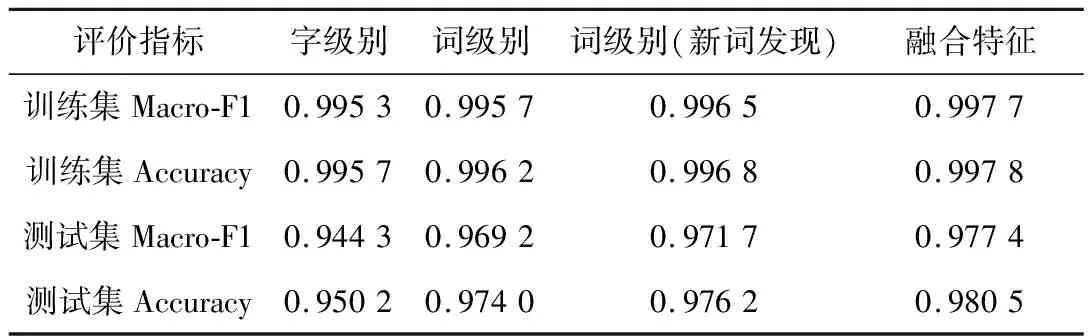
表1 不同输入特征分类结果对比
通过表1对比试验显示,采用词级别特征比字级别特征能够获得更好的分类效果,而基于新词发现预处理能够使效果获得进一步提升。基于新词发现以及融合字、词级别特征的方法,在测试集和训练的Macro-F1和准确率上均取得了一般效果。通过融合字和词级别特征,使模型能够获得更丰富的特征输入,可获得更好的缺陷分类效果。
4.3 多模型对比试验
本文主要对比所提出模型与其他深度学习模型分类效果,结果如表2所示。

表2 三种深度学习模型分类效果对比
对比试验显示,基于注意力机制优化的卷积神经网络,在四项指标上均取得了三种模型中的最佳效果,验证了本文所提出方法的有效性。
5 结束语
本文考虑了电力领域专用语料特点,针对电力设备缺陷语料库提出了基于注意力机制优化的卷积神经网络文本信息挖掘方法。新词发现和字词特征融合有效地提升了模型对文本的信息挖掘能力。基于注意力机制优化的卷积神经网络文本信息挖掘方法相比于其他传统的深度学习方法(CNN、BiLSTM)对电力缺陷文本的信息获取能力更优。该方法使电网缺陷文本分类由传统的人工分类转变为自动分类,以促进智能化运维。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
音乐天地(音乐创作版)(2019年12期)2019-02-09
燕山大学学报(2014年1期)2014-03-11
语文知识(2014年12期)2014-02-28
通信学报(2014年12期)2014-01-01
