
基于文本的高速铁路信号设备故障知识抽取方法研究
2021-05-13 03:00李新琴史天运代明睿张晓栋
铁道学报 2021年3期
李新琴,史天运,李 平,代明睿,张晓栋
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所, 北京 100081;2. 中国铁道科学研究院集团有限公司, 北京 100081)
高速铁路信号设备是铁路安全运营的基础保障设备[1-2]。随着中国高速铁路的飞速发展,高速铁路信号设备也不断升级改造。基于高速铁路运营里程的积累,产生了大量的信号设备故障数据,这些数据以文本的形式记载了故障的详细信息,蕴含着丰富的故障诊断与处理经验知识。但由于其以非结构化文本的形式存储,不利于计算机处理和理解,长期由人员查阅分析,存在着严重的故障知识无法高效复用的问题。因此,在铁路大数据与智能铁路的建设下,有必要基于铁路数据与人工智能服务平台,研究机器学习算法,实现故障知识的自动抽取,为高速铁路故障诊断及智能铁路建设应用中的智能问题、智能推荐等智能服务的落地提供知识库。
知识抽取主要包括命名实体识别和实体关系抽取两个方面。命名实体通常指人名、地名、机构名等以名称为标识的实体[3]。命名实体识别主要是将故障文本数据中的关注信息作为命名实体抽取出来。实体关系抽取是将抽取出来的命名实体进行关联,形成〈实体,关系,实体〉三元组数据,并通过知识融合和知识加工方法,将三元组数据组织成知识。命名实体识别与实体关系抽取,可以作为两个独立的任务进行,也可以基于一个模型同时抽取。相互独立抽取时,命名实体识别[4]目前主流的方法包括:长短时记忆网络(Bidirection Long Short Term Memory,BiLSTM)与条件随机场(Conditional Random Fields,CRF)结合的命名实体识别模型[5-6],以及卷积神经网络(Convolutional Neural Network,CNN)与BiLSTM+CRF结合的模型,以实现中文命名实体识别[4]。高速铁路信号设备故障关系抽取是一个文本分类问题。文本分类机器学习模型包括:单分类器,例如决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)、朴素贝叶斯 (Naive Bayes Classifier,NBC)等,以及集成学习分类器[7],深度学习模型[8-11]。同时抽取是将命名实体与实体关系在一个模型中学习,最后直接输出实体与关系的三元组数据。命名实体与实体关系联合抽取模型主要包括:BiLSTM与编码-解码过程(Encoder-Decoder,ED)、CNN相结合的混合神经网络实现的实体与关系联合抽取模型[12],以及BERT(Bidirectional Encoder Representations from Transformers)与注意力机制相结合的联合抽取模型[13]。
在铁路文本数据分析领域,许多学者开展了研究。在命名实体识别方面,杨连报[5]采用Word2Vec对铁路事故故障进行特征表示,并采用BiLSTM+CRF实现铁路电务的事故故障命名实体识别。在文本分类方面,文献[14]采用TF-IDF特征提取与基于遗传算法改进的Bagging集成分类器,实现铁路安全隐患文本数据智能分类;张磊等[15]采用卡方检验和朴素贝叶斯方法对安全管理文本进行降维和分类;上官伟等[16]通过改进文档主题生成模型(Latent Dirichlet Allocation,Labeled-LDA),采用基于粒子群优化的支持向量机算法对车载日志进行分类。
高速铁路信号设备故障知识抽取方法,借鉴学者们对命名实体与实体关系抽取的研究方法,针对信号设备故障数据特点,提出命名实体与实体关系的抽取模型,实现信号设备故障知识的抽取。根据故障数据的信息价值,定义故障命名实体与实体关系类型,构建故障知识结构;统一标注命名实体与实体关系抽取样本数据,提出多维字符特征表示的命名实体特征表示方法和多维分词特征表示的实体关系特征表示方法,采用BiLSTM+CRF实现命名实体抽取;基于多维分词实体关系特征表示,设计基于Transformer[17-18]网络,实现实体关系的抽取。为验证模型的有效性与正确性,应用高速铁路2009—2018年信号转辙机设备故障数据进行实验分析。
1 高速铁路信号故障知识抽取模型总体框架
高速铁路信号设备故障数据,来源于铁路电务相关系统以及人员整理的故障信息,并以Excel形式存储,较为全面地记载了电务信号设备故障发生的详细信息。其中,故障原因分析数据,以非结构化文本的形式描述了故障设备的型号、故障发生的原因、整改措施等有价值的信息。
高速铁路信号设备故障知识抽取模型总体框架见图1。该模型自底向上分为三层:最底层为文本预处理层,实现对原始文本数据去除设备型号、停顿词等预处理操作;中间层为故障知识抽取模型层,通过对故障知识的定义,统一标注文本数据,并对标注文本进行特征表示,将文本数据转换为向量,通过命名实体识别模型与实体关系抽取模型,先后实现实体抽取与关系抽取,形成三元组的知识数据;最上层为故障知识层,采用图数据库对知识进行存储,为基于知识图谱的各类应用提供数据支撑。

图1 高速铁路信号设备故障知识抽取模型总体框架
2 高速铁路信号设备故障知识定义
故障知识的宝贵价值在于能够有效辅助现场人员分析故障致因,并能够给出故障处理意见。高速铁路信号设备故障知识以抽取故障致因和处理方法为目的,根据对故障原因分析文本数据的特征总结,定义故障知识结构。高速铁路信号设备故障知识结构见图2。从图2中可以看出,通过设备现象引起设备现象这种闭环结构,能够有效抽取引起事故的致因链,其余知识结构能够有效表达故障的处理措施。
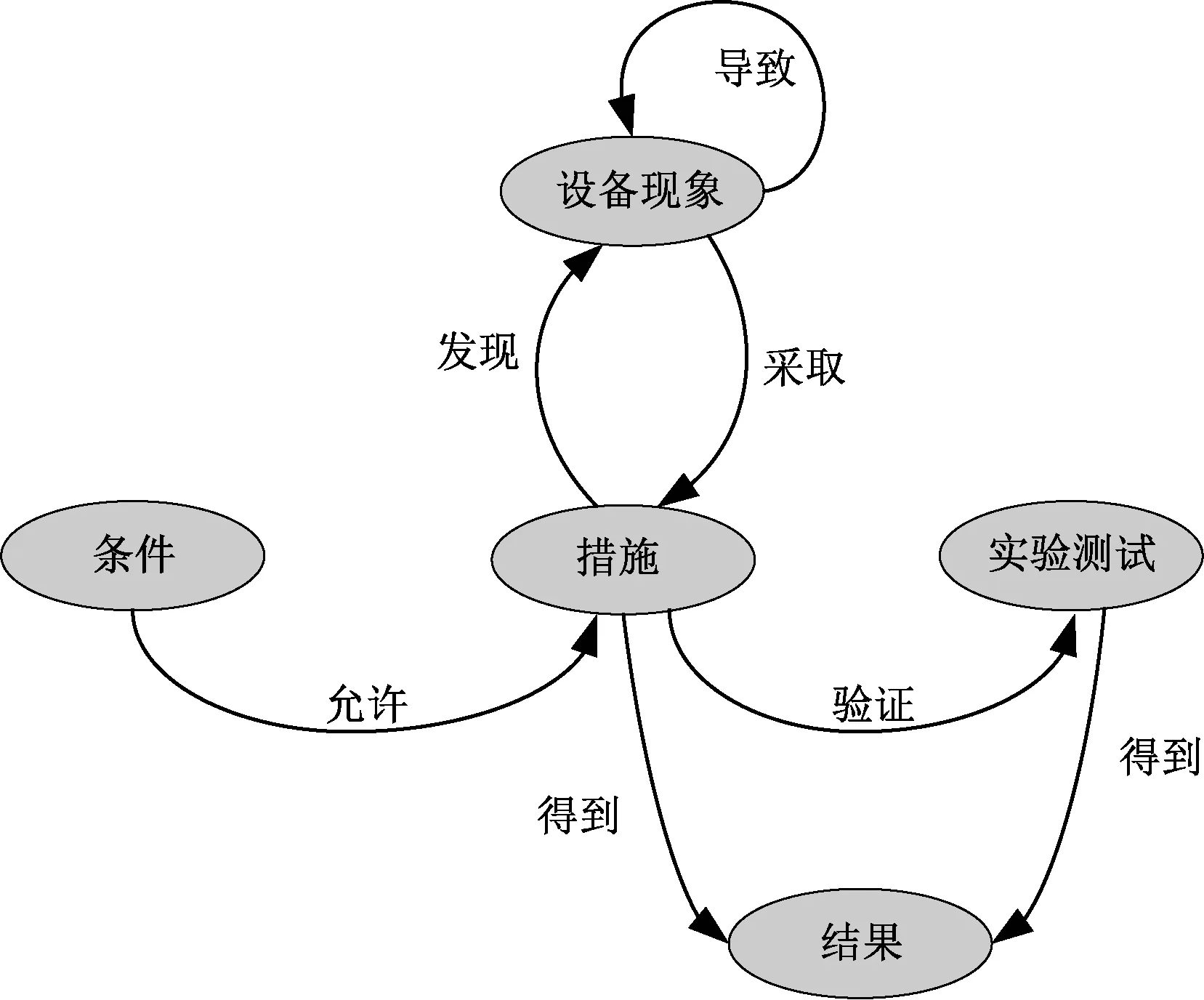
图2 高速铁路信号设备故障知识结构
根据故障知识结构,共定义5类命名实体和7类关系类型。命名实体和实体关系定义见表1。

表1 命名实体和实体关系定义
3 高速铁路信号设备故障知识标注
高速铁路信号设备故障知识抽取方法,基于有监督学习的深度学习方法实现,需要大量标注样本数据进行训练。信号故障知识标注方法将命名实体学习与实体关系学习样本统一标注。每一条信号设备故障文本标注为原文序列、索引序列、命名实体序列、关系序列、关系索引序列,组成一个序列集合,分别对应图3中的{seq0,seq1,seq2,seq3,seq4}。高速铁路信号设备故障文本标注序列集合见图3。

图3 高速铁路信号设备故障文本标注序列集合
命名实体识别序列标注采用BIOE表示,其中B(Begin)表示实体的起始位置,I(Internal)表示实体的中间部分,E(End)表示实体的末尾字符,O(Other)表示非实体字符,用“-”与表1中定义的实体标注类型连接。实体关系在每个实体末尾字符用关系标注类型表示,并在关系索引序列中标记与之有关系的实体,如对图1最底层原文部分数据的标注如图3所示。
4 高速铁路信号设备故障知识特征表示
经过标注的信号设备故障数据需要表示为计算机能够识别和处理的数据类型,并能够保留数据本身的特点。信号设备故障知识特征表示方法将标注数据转换为多维字符特征与多维分词特征,并输入到信号设备故障知识抽取模型中。
4.1 基于多维字符特征的命名实体特征表示
命名实体特征表示不仅要表示样本数据中标注的命名实体特征,也要表示文本上下文内部相关信息,所以多维字符特征表示方法包含了样本中每一个字符特征、标注样本的命名实体特征、能够表达样本内容的分词特征等三维特征。
(1)字符特征:即表示所有标注样本的seq0的汉字的特征。将样本去重后的所有字符按顺序编码得到字符编码集合Dc。
(2)命名实体特征:即将样本的seq2信息完整表示出来。获取seq2所有的不重复的命名实体标记,并将所有标记按顺序编码,映射为命名实体字典集合Tc。
(3)分词特征:样本的seq0通过加载专业语料的jieba分词工具进行分词。得到的样本分词集合不仅能够表达字符在词语中的位置,而且可以判断词语的字符数量。设一个文本的总长度为L,包含n个分词{w1,w2,w3,…,wn},则每个分词的表示子集合为
f(wi)={l-(l-1),…,l-1,l}
(1)
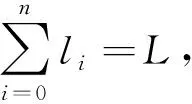
以上编码完成后,设有n个样本数据集,输入一个样本i的seq0及seq2标注数据,得到相应的编码向量Dci、Sci、Tci,并且具有相同的维度,长度为样本字符的长度,每个样本采用三维不同的特征向量组成向量VNERi(i=1,2,…,n),所有样本向量表示为VNER,并且在最后加一维向量Ln用于表示每个样本的长度。
4.2 基于多维分词表示的实体关系特征表示
实体关系特征表示应用知识标注全部序列seq0~seq4,表达实体以及实体之间的关系。设seq3中有n个实体关系,将标注数据分解为n个实体关系学习样本,每个样本采用基于多维分词的实体关系特征方法表示。
实体关系主要包括:分词特征,首部命名实体特征,尾部命名实体特征,掩码特征。其中首部和尾部命名实体基于实体位置特征表示方法表示。
(1)分词特征表示:实体关系分词将样本中的命名实体作为语料加载到jieba分词工具进行分词,这样能够将命名实体作为一个分词整体进行处理。输入seq0实现样本数据的分词,并将所有标注样本的分词集合去重后按顺序编码形成分词集合Sc。
(2)首部和尾部命名实体特征表示:x表示输入的当前命名实体的位置索引;y表示命名实体的字符长度;z表示整个样本的索引长度;δ表示索引值大小的上限。首部和尾部命名实体的特征集合为
f(x,y,z)={{-x,0}+{0}·y+
{1,z-y-x+1}}+δ
(2)
(3)掩码特征表示:表示首部实体和尾部实体以及其他非实体的位置信息。x表示首部索引的起始位置,y表示尾部实体的索引位置,z表示整个样本的索引长度,过公式(3)计算掩码特征集合,并且f(x,y,z)与g(x,y,z)的输出集合大小相等。
g(x,y,z)={1}·(x+1)+{2}·
(y-x-1)+{3}·(z-y)
(3)
根据以上3种实体关系特征表示计算方法,输入第i个样本数据集seq0~seq4,通过Sc的分词编码映射,得到分词特征向量Sci,通过f(x,y,z)分别得到样本的首部命名实体特征向量Hi和尾部特征向量Ti,通过g(x,y,z)得到样本的掩码特征向量Mi,最终得出该样本的多维特征向量VREAi(i=1,2,…,n),以及所有样本的向量表示。
5 高速铁路信号设备故障知识抽取模型原理
信号设备故障知识抽取模型将知识特征表示的多维字符向量与多维分词向量,分别输入到BiLSTM+CRF命名实体识别模型和Transformer关系抽取模型中,BiLSTM+CRF与Transformer两个深度学习网络模型,对输入的特征数据经过网络嵌入层转换后进行特征学习,经过训练的网络模型能够自动识别输入样本的实体,以及实体之间的关系,最终输出三元组的知识数据。命名实体与实体关系抽取模型见图4。
5.1 基于BiLSTM+CRF命名实体抽取
命名实体识别是自然语言中典型的序列标注问题,输入一个线性序列x={x1,x2,x3,…,xn},输出给线性序列中的每一个元素打上标签集合中的某个标签的序列y={y1,y2,y3,…,yn}。BiLSTM与CRF结合是一种能够有效学习自然语言的上下文关系并能够保证输出序列前后依赖关系的模型,图4中左半部分即为BiLSTM+CRF-NER部分。
BiLSTM由前向LSTM和后向LSTM组合而成。LSTM是一种特殊的循环神经网络,其神经元有3个门结构,分别是遗忘门、输入门和输出门,各门的输入输出计算公式为
(4)

CRF通过对BiLSTM的输出进行学习,能够保证输出序列的条件概率满足马尔科夫性,例如B-P后面的输出字符应该是I-P,而不是其他,这样可以增强输出序列的正确性。当输入序列x时,输出序列取值为y的条件概率为
(5)
式中:Z(x)为归一化因子;tk为转移特征函数;λk为转移特征的权值系数;sl为结构特征函数;μl为结构特征的权值。
5.2 基于Transformer网络的实体关系抽取
Transformer是一种基于注意力机制(Attention)建立全局输入(Encoder)和输出(Decoder)依赖关系的神经网络,相比其他神经网络具有较强的并行性,主要包括编码过程和生成式的解码过程。信号设备故障实体关系抽取是一个分类问题,基于Transformer Encoder编码过程实现。图4中右半部分即为Transformer-RE部分,其为应用Transformer思想设计的信号设备故障实体关系抽取网络结构。
基于Transformer的关系抽取网络结构中,将多维分词表示的特征向量经过Embedding层的转化后,输入到Encoder网络单元中。Encoder网络单元由多头注意力机制和基于位置的全连接前馈网络2个子层组成,每一层的输出都经过一个归一化计算。
多头注意力机制由多个注意力机制单元组成。注意力机制将输入向量转换为query(Q)和一组key-value(K,V)向量,并根据注意力机制单元个数h进行h次线性变换,将每个注意力机制单元的计算结果进行拼接,然后再将每个注意力机制单元对输入的Q,K,V进行Attention函数计算,计算公式为
(6)
式中:headi=Attention(QWiQ,KWiK,VWiV);WiQ∈Rdl×dq,Wik∈Rdl×dk,Wiv∈Rdl×dv,WiO∈Rhdv×dl,都是模型学习的映射参数。
全连接前馈网络层主要包括两层全连接前馈神经网络,以及中间的一次ReLu函数激活和Dropout防止过拟合计算。对于不同的注意力机制单元使用相同的参数。其中W和b表示网络连接权重和偏置。最后对多头注意力机制层与全连接前馈网络层的输出结果求和并进行归一化输出。
FFN(x)=max(0,xW1+b1)W2+b2
(7)
6 实验验证与结果分析
以高速铁路信号设备2009—2018年产生的故障数据验证知识抽取模型,其中,70%作为训练集样本,20%作为验证集样本,10%作为测试集样本。采用准确度Precision和召回率Recall作为算法评价和对比的指标,F1值为综合评价模型。
(8)
式中:C为所有样本的总数;c为所有类别总数;TPi为被正确分到此类的样本个数;TNi为被正确识别不在此类的样本个数;FPi为被误分到此类的样本个数;FNi为属于此类但被误分到其他类的样本个数。
6.1 基于多维字符特征表示的BiLSTM+CRF命名实体识别模型验证
高速铁路信号转辙机设备10年的故障数据中共包含1 362个不同汉字和21个实体标签类型,BiLSTM为1层神经网络结构,LSTM神经网络神经元个数为100,最大字符长度为100,Embedding字符特征维度为100,分词特征维度为20,批处理大小为20,Dropout损失率为0.5。经过50轮训练得到的训练结果见表2。

表2 基于多维字符特征的BiLSTM+CRF命名实体识别训练结果
从训练结果可以看出,故障维修条件、维修测试、维修结果、故障现象都有较高的评价指标,只有维修采取的措施评价指标较低,分析原因是由于各样本中故障维修措施多样化,并且相似的维修措施描述方式和标注边界不同造成的。
6.2 基于多维分词表示的Transformer关系抽取模型验证
高速铁路信号设备故障样本数据中共有6 260个实体关系学习样本。基于多维分词表示的Transformer网络关系抽取模型采用3层网络结构,每层中的多头注意力机制包含4个注意力机制单元,分词维度为50,Embedding层中位置向量大小为2×50+2=102,位置维度为5,线性转换特征维度为60,隐藏层维度为100,Dropout损失率为0.3,网络输出为一维向量,大小为关系类别个数。
Transformer实体关系网络经过40轮的训练,每轮将训练样本分为8次批处理训练,训练过程中,第10轮、20轮、30轮、40轮的损失函数loss函数值见图5。
从图5中可以看出,随着训练轮数及每轮训练样本的增加,loss值不断下降,最后趋于稳定并接近于0,说明以上参数值使得Transformer网络训练达到最佳状态。最终模型训练结果见表3。
由表3可以看出:基于多维分词特征表示的Transformer实体关系抽取模型,在高速铁路信号设备故障实体关系分类中具有较好的表现,各关系类别评价指标都在90%以上;由于MEP(采取维修措施发现设备故障现象)类实体关系在样本中极少,所以其评价指标较低。
6.3 实体和关系抽取模型对比试验
为了进一步说明本文研究方法的有效性,针对已标注的高速铁路信号转辙机设备10年的故障数据,采用不同的特征表示方法,以及不同的命名实体抽取模型和实体关系抽取模型进行实验。其中命名实体识别分别采用Word2Vec和多维字符特征进行特征表示,采用预训练模型ALBERT_base和BiLSTM+CRF模型实现设备故障命名实体识别;实体关系抽取分别采用字符+位置特征以及多维分词特征进行特征表示,采用Transformer、RNN和CNN作为实体关系抽取模型实现设备故障实体关系抽取。多种实体和实体关系抽取模型实验结果见表4。
从表4可以看出,多维字符特征+BiLSTM+CRF在设备故障命名实体识别中各项评价指标最高,而目前主流的预训练模型Word2Vec和ALBERT_base由于设备故障样本数量不足,未体现出较高的性能;在设备故障实体关系抽取中,多维分词特征+Transformer模型各评价指标最高,字符+位置特征与Transformer模型,以及多维分词特征与RNN和CNN的组合模型,实体分类性能都不及多维分词特征+Transformer模型,说明多维分词特征+Transformer是最佳的设备故障实体关系抽取模型。

表4 多种实体和实体关系抽取模型实验结果
6.4 实验总结
根据以上实验结果可以得到,针对高速铁路信号设备故障文本数据,采用统一标注,命名实体识别与实体关系识别任务相互独立训练的方式具有优势,并且基于多维字符表示的BiLSTM+CRF命名实体识别模型与基于多维分词表示设计的Tramsformer关系识别模型,在高速铁路信号设备故障命名识别与关系分类中具有较好的表现。实验证明,高速铁路信号设备故障实体与关系抽取模型在故障知识抽取问题中具有应用价值。
7 结束语
“十四五”铁路网络安全和信息化规划中明确提出建设铁路数据服务和人工智能平台。基于知识图谱的自然语言处理人工智能服务是平台的重要组成部分。高速铁路信号设备故障命名实体与实体关系管道式抽取模型,将文本的故障原因分析数据转化为可以为故障诊断服务的知识。该模型也可以应用到铁路其他专业,如果统一存储知识,随着应用的深入,将形成庞大而丰富的铁路知识库,该知识库能够解决铁路诸多方面智能化服务无法实现的瓶颈。高速铁路信号设备故障知识抽取之后,如何应用机器学习算法去除冗余知识以及基于已有知识挖掘未知知识都是下一步的研究方向。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年22期)2020-01-14
建材发展导向(2019年5期)2019-09-09
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
山东工业技术(2016年15期)2016-12-01
