
基于LSTM 的风机故障检测研究
2021-05-13 07:16胡翔殷锋袁平
现代计算机 2021年8期
胡翔,殷锋,袁平
(1.四川大学计算机学院,成都610065;2.西南民族大学计算机科学与技术学院,成都610041;3.重庆第二师范学院数学与信息工程学院,重庆400067)
0 引言
伴随着全球化石燃料短缺问题愈发严重,能源的开发重心逐渐转向可再生能源。风能如今作为被广泛开发与利用的清洁能源之一,在电网系统总容量中占有很大比例[1]。然而,由于风力发电处于复杂且恶劣的环境,风力涡轮机经常发生故障,从而导致非计划停机时间,这给风电场运营商带来高运行维护成本,因此研究先进的风力涡轮机故障检测方法是非常必要的,它可以尽早检测到那些可能存在的故障,最终帮助风电场的运营商及时采取适当的措施,避免造成继发性损害甚至灾难性事故,从而实现更好的维护计划。
目前,研究风力涡轮机故障检测的方法可以分为两类,一种是基于数学模型的方法,另一种是基于数据驱动的方法。基于数学模型的方法主要是基于风力发电机系统中的物理机制和严格的数学模型进行系统建模,但它们很难实践且不易更改。基于数据驱动的方法不需要严格的数学建模,并且可以从风电涡轮机测量的高维传感数据中提取有用的特征或表示,然后通过进一步的分类决策来识别不同的故障类型。通过提升风机故障检测精确度,可以帮助风电场维护人员提前获知风机运行状态,及时准确地诊断风机的故障,以提高维护速度并最大限度地提高风力发电效率。Shin等人[2]利用支持向量机来实现端到端的风机故障诊断,并添加了两个外部数据作为输入。Yan 等人[3]提出首先利用PCA 从高维故障数据中提取出低维特征,消除特征之间的相关性,并作为支持向量机的输入,最后输出故障或正常。这些研究方法都基于建立好的数据标签的数据集的情况,且需要另外的特征提取工作。
针对以上问题,本文提出一种基于LSTM 的风机故障检测框架,首先利用DBSCAN 聚类算法对原始数据进行异常聚类,再作为LSTM 网络模型的输入,且不依赖前期的特征选择,并捕捉隐藏在时间序列数据的长期依赖关系,最后输出异常和正常的二分类结果。
1 算法基础
1.1 LSTM网络
LSTM(Long Short Term Memory networks)是RNN(Recurrent Neural Network)网络的一种变体,由Hochreiter 和Schmidhuber[4]开发,解决RNN 中的梯度消失问题。LSTM 利用门控机制可以学习长输入序列,从而可以处理复杂序列信息的问题,其网络结构如图1所示。
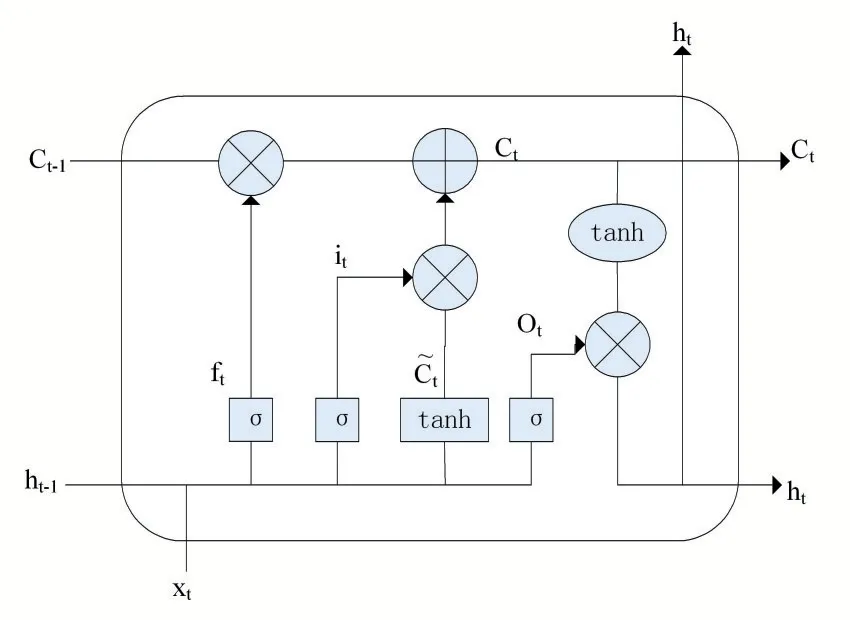
图1 LSTM网络结构图
LSTM 中的每个节点的状态如公式(1)-(6)。其中,xt表示当前输入,ht-1代表上一次迭代的隐藏状态,W 和b 表示权重和偏差,σ指的是sigmoid 函数,ft表示忘记门的输出,it表示输入门的输出,代表中间临时状态,Ct-1代表上一层的单元状态,Ct表示下一层的单元状态,Ot表示输出门的输出,ht表示下一层的隐藏状态层。
xt和ht-1进入忘记门得到ft,决定丢弃上一层的哪些信息;进入输入门得到it,决定更新哪些信息;进入输出门得到Ot,更新单元状态。
1.2 异常聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)[5]是一种基于密度的空间聚类算法,它将具有足够密度的区域划分为簇,且在具有噪声的空间中找到任意形状的簇。如图2 所示,DBSCAN 聚类算法将数据分为三类:核心点、边界点和噪音点:
核心点(Core Object),表示当数据点xi在半径为Eps 的邻域内存在至少MinPts 个样本,那么该数据点xi称为核心点;
边界点(Border Object),表示当数据点xi在半径为Eps 的邻域内存在少于MinPts 个样本,而自身在其他核心点的范围之内,则该数据点xi称为边界点;
噪音点(Noise Object),指的是既不是核心点也不是噪音点的数据点。
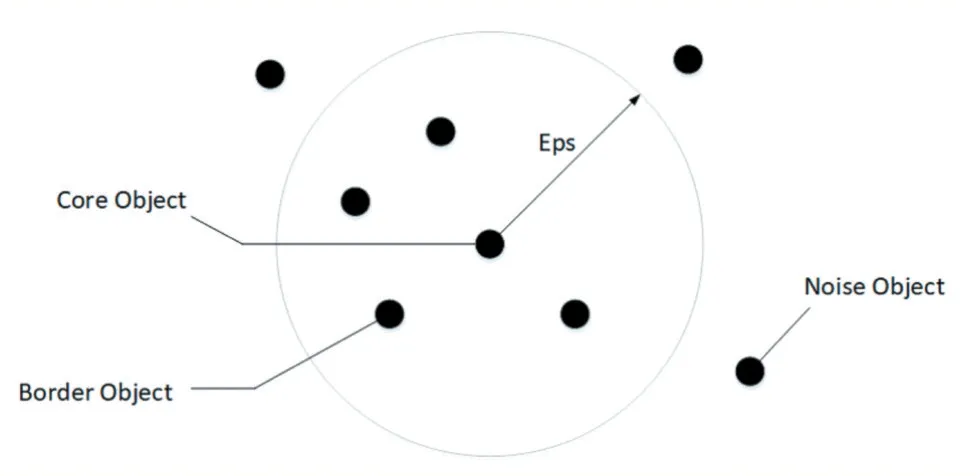
图2 DBSCAN示意图
DBSCAN 聚类算法的核心思路是随机从某个数据点p 开始,根据半径Eps 检索可达的点,再根据最小数据点个数MinPts 来判断当前数据点p 是不是核心点。若p 为核心点,则创建一个簇,并开始检索该簇中其他核心点并加入到当前簇中;若不是,则检索其他数据点,直至所有点检索完成。
相比于基于划分的聚类算法K-means,DBSCAN不需要指定具体的簇的个数,就能处理不同大小或形状的簇,且可以有效地识别噪音。
2 基于DBSCAN和LSTM的故障检测框架
本文提出的故障检测框架如图3 所示。该框架主要分为离线训练和在线检测两部分。风机SCADA 数据是由风电场控制系统监视的各种参数组成,包括电气参数(例如功率、电流和电压等)、与天气相关的参数(风速和风向等)和轴承变速箱温度等,其中离线训练包括数据清洗、数据标记和LSTM 模型训练。框架的输入为风电场SCADA 运行数据,首先对风机运行数据进行数据清洗,将那些存在属性缺失和严重偏离正常值的样本过滤;由于SCADA 数据存在多维数据,且这些变量的值的范围相差过大,因此需要将它们转换为相同范围,即进行归一化;其次需要对SCADA 数据进行标签,本文利用DBSCAN 聚类算法对数据聚类得出正常点和异常点,并在此基础上对数据进行标记。最后将标记后的数据输入到基于LSTM 的神经网络模型,不需要依赖前期的特征提取,捕获标记数据中隐藏的长期依赖关系。该框架的在线检测部分主要是将风电场中的新SCADA 数据经过数据预处理之后,输入到训练好的LSTM 模型中,最终得到风机故障的二分类结果。
该框架很好地利用DBSCAN 聚类算法对风机运行数据进行异常聚类,同时对实验数据标记成为正常运行和故障两种状态,不需要风电场的故障日志报告,这也就弥补了风电涡轮机存在缺失故障报告的不足。LSTM 已在序列数据中的机器学习问题中证明了其有效性,它使用存储单元将信息从过去的输出传递到当前的输出,通过历史数据的长期序列中学习隐藏的依赖关系,而在风机故障检测领域中,风机运行数据正好符合时间序列的类型,且不需要进行特征提取,可以实现端到端的故障检测。
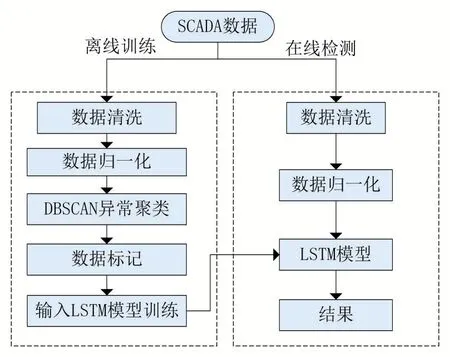
图3 框架流程图
3 实验结果与分析
3.1 数据集描述
本文的实验数据来自位于爱尔兰风电场中的涡轮机[6],其中涵盖了2014 年1 月至2015 年9 月,包含将近50000 个分辨率为10 分钟的数据样本,每个数据样本具有60 个属性。表1 列出了数据集的部分样例,运行参数包括风速、转速、功率和产出等。
3.2 评价指标
为了衡量方法的性能,本文选取精度、召回率和F1 分数[7]作为实验的评估标准,它们之间相关联的是混淆矩阵。
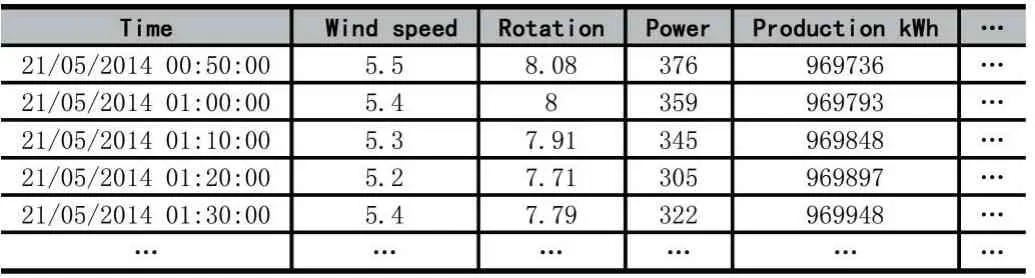
表1 数据集的部分样例

表2 二分类混淆矩阵
二分类混淆矩阵如表2 所示,TP(真阳例)表示将正类样本预测为正类,FP(假阳例)表示将负类样本预测为正类,FN(假阴例)表示将正类样本预测为负类,TN(真阴例)表示将负类样本预测为负类。由混淆矩阵可以引出以下评价指标:
查准率,代表模型预测正确率,即正确预测样例数量和总样例数的比值,如公式(7)所示:

召回率,表示被预测为正例的数量与真阳例数量的比值,如公式(8)所示:

F1-score,表示查准率和召回率的调和平均值。由于可能存在数据集中正负样例严重不平衡问题,导致出现precision 过高但recall 过低或者precision 太小但recall 太大的情况,而F1-score 正好综合考虑两者,如公式(9)所示:
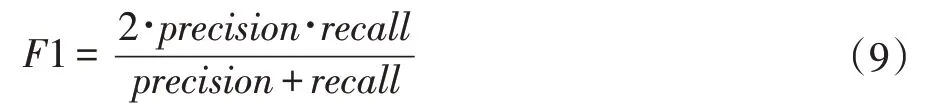
3.3 实验结果
本文选取SCADA 运行数据中的功率数据和风电涡轮机转速数据组合成二维数据,并使用DBSCAN 聚类算法对生成的数据进行聚类,其中的参数MinPts 设置为5,参数eps 设置为2.1。基于实验数据的聚类结果,将DBSCAN 聚类出的噪声点作为异常点,并对实验数据进行标签。聚类结果如图4 所示,正常点和异常点分别用不同半径大小的圆圈表示。

图4 DBSCAN聚类结果图
神经网络模型中LSTM 中输入维度设置为50,隐藏神经元的维度设置为100。模型的最后一层的激活函数为Sigmoid 用作二分类。
基于LSTM 的神经网络模型与SVM 的实验对比结果如表3 所示。本文的模型在F1 分数和Precision略高于基线SVM,这是由于LSTM 能捕获到SCADA 数据的时间序列相关性。

表3 实验对比结果
4 结语
在风电涡轮机故障检测领域中,需要进行数据标签和特征提取。但由于在风电场系统中的SCADA 运行数据并不能直接标签,此时就需要将正常数据点和故障数据点标记出来。本文提出使用DBSCAN 聚类算法对原始数据聚类,得出正常数据点和异常数据点,最后将实验数据成功标签为“正常”和“故障”。另外,本文使用LSTM 模型对实验数据进行训练,无需进行特征提取,LSTM 可以利用自身的门控机制捕获时间序列中长期依赖关系,实现端到端的风机故障检测。通过实验结果可以得出,该框架在准确率和召回率上有较好的效果。未来将考虑利用好风电场的警报日志和故障日志,共同作用于对SCADA 数据的标签。
猜你喜欢
环球时报(2022-07-27)2022-07-27
中国应急管理科学(2022年2期)2022-05-23
机电信息(2022年9期)2022-05-07
中国水运(2022年4期)2022-04-27
当代化工(2020年5期)2020-08-25
中国化工贸易·中旬刊(2018年6期)2018-10-21
海峡摄影时报(2017年7期)2017-07-14
科技与企业(2015年20期)2015-10-21
城市建设理论研究(2014年37期)2014-12-25
