
尿液代谢组学非靶向质谱分析法两种采集模式的比较
2021-05-12 02:25肖晓莲刘晓燕朱文凤杨晔宏杨俊涛
基础医学与临床 2021年5期
肖晓莲,刘晓燕,朱文凤,杨晔宏,杨俊涛,孙 伟*
(中国医学科学院基础医学研究所 北京协和医学院基础学院 1.药理系;2.医学分子生物学国家重点实验室,北京 100005)
代谢组学(metabolomics)分析方法是研究小分子代谢物的有效工具,能够直接反映生命体终端和表型信息,在精准医学和转化医学中发挥着重要作用[1-4]。基于质谱(mass spectrum,MS)的非靶向代谢组学分析方法已广泛应用于许多领域,包括疾病生物标志物发现、代谢通路研究和寻找调节某些疾病表型的生物活性化学物质,比如脱髓鞘病, 糖尿病或肿瘤等[5-8]。
非靶向代谢组学分析方法中常用的数据采集模式有两种,即全扫描采集(full scan acquisition, FSA)模式和数据依赖采集(data dependent acquisition, DDA)模式。FSA模式对每个样本进行一级质谱图(MS)扫描以获得所有代谢特征的精确质荷比(mass-to-charge ratio, m/z)和相对丰度,再选择靶向的离子扫描二级质谱(MS/MS,MS2)图进行代谢物的鉴定。DDA模式是在进行一级质谱图扫描的同时,选择一级谱图中的高丰度离子进行二级谱图采集,一次实验同时完成代谢物的定性和定量分析。以往文献表明,不同数据采集模式会影响代谢物的鉴定和定量[9]。目前,对非靶向代谢组学分析方法的采集模式比较的研究仍很缺乏且不全面。有人使用代谢物标准品分析比较两种模式鉴定的代谢物数目,但未进行定量比较;同时,该研究缺乏真实生物样本的代谢物的定性定量比较,并且未考虑不同丰度及峰宽的代谢物的定性定量结果[10]。本研究拟分别用代谢物标准品混合物和健康人尿液代谢物进行两种采集模式的质谱分析,以从代谢物的定性及定量两个方面,全面地比较了两种数据采集模式进行质谱分析的优缺点。
1 材料与方法
1.1 材料
试剂:乙腈、甲酸(Merk公司);水(质谱级)、标准品:醋氨酚、咖啡因、磺胺脒、磺胺二价氧嘧啶、缬氨酸-酪氨酸-缬氨酸、维拉帕米、特非那定、亮氨酸脑啡肽和利血平9种代谢物(Waters公司);尿液:10名健康人的晨尿(晨起第一次尿液),每人留取50 mL,4 500×g离心10 min去细胞碎片。
1.2 方法
1.2.1 标准品:标准品的质谱分析分别采用FSA和DDA两种模式采集,进样2 μL,分别进行3次实验操作重复。
1.2.2 尿液代谢物的提取:每个尿液样本取200 μL,加入等量乙腈混合,放置-20℃冰箱30 min后,14 000×g离心10 min,取上清吹干后加入200 μL 2%乙腈溶解。
提取尿液代谢物后,每个样本取3 μL代谢物提取液混合成一份混合物上机。质谱分析分别采用FSA和DDA两种模式采集(FSA组和DDA组),设置3个进样量,包括1、2和4 μL,每个进样量进行3次实验操作重复。
1.2.3 质谱分析代谢物:标准品混合物和尿液代谢物经色谱柱(3.0 mm×100 mm,1.8 μm)进行分离,多肽的洗脱液梯度为2%~100% B液(0.1%甲酸,100%乙腈),流速为500 μL/min,洗脱时间为17 min。洗脱的代谢物用Triple TOF5600质谱仪分析(AB Sciex, 多伦多, 安大略省, 加拿大),分析模式分别采用FSA模式和DDA模式。FSA模式参数如下:一级全扫描范围为50~1 200 m/z,累积时间为0.25 s, GAS1为55 psi,GAS2为55 psi,Curtain Gas为35 psi,温度为550 ℃,电离喷雾电压为4 500 V;二级定性扫描碰撞能量使用20、35、50、35步长15 eV,每个循环选丰度top4一级质谱(LC-MS)图进行二级质谱(LC-MS/MS)采集,动态排除时间为5 s,选择动态背景排除。DDA模式参数如下:一级全扫描范围为50~1 200 m/z,一级累积时间为0.25 s,二级累积时间为0.1 s,GAS1为55 psi,GAS2为55 psi,Curtain Gas为35 psi,温度为550 ℃,电离喷雾电压为4 500 V,二级定性扫描碰撞能量为35步长15 eV,每个循环选丰度top4一级质谱图进行二级质谱采集,动态排除时间为5 s,选择动态背景排除。
1.3 统计学分析

2 结果
2.1 标准品结果的分析
FSA组的9个代谢物丰度均高于DDA组(P<0.05)(图1A)。其中,亮氨酸脑啡肽差异最明显,在FSA组的丰度(abundance)比DDA组高约3倍。全部代谢物在FAS组的丰度比DDA组平均高约2.36倍(图1)。

A.abundance of known metabolite; B.coefficient of technical variation;*P<0.05 compared with full scan acquisition图1 代谢物标准品的定量分析Fig 1 Quantitative analysis of known
有8个代谢物丰度的变异系数(coefficient of variation, CV)值在DDA组明显高于FSA组,维拉帕米的丰度CV值在两组中相近。DDA组的CV值范围在2.14%至11.20%,FSA组的CV值范围在0.81%至6.35%(图1B)。
2.2 尿液样本的分析
2.2.1 定性比较:进样量为1、2和4 μL时,FSA组的一级谱图数、二级谱图数、代谢特征数目及二级谱图匹配的代谢特征数均稍多于DDA组(表1)。
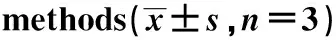
表1 两种数据采集方法的液相二级质谱(MS2)结果Table 1 LC-MS/MS(MS2) data of the two acquisition
进样量为1 μL时,FSA组鉴定的代谢物较DDA组多9.5%。进样量为2 μL时,两组鉴定的代谢物数目相近。进样量为4 μL时,FSA组鉴定的代谢物数目较DDA组多10%(图2)。
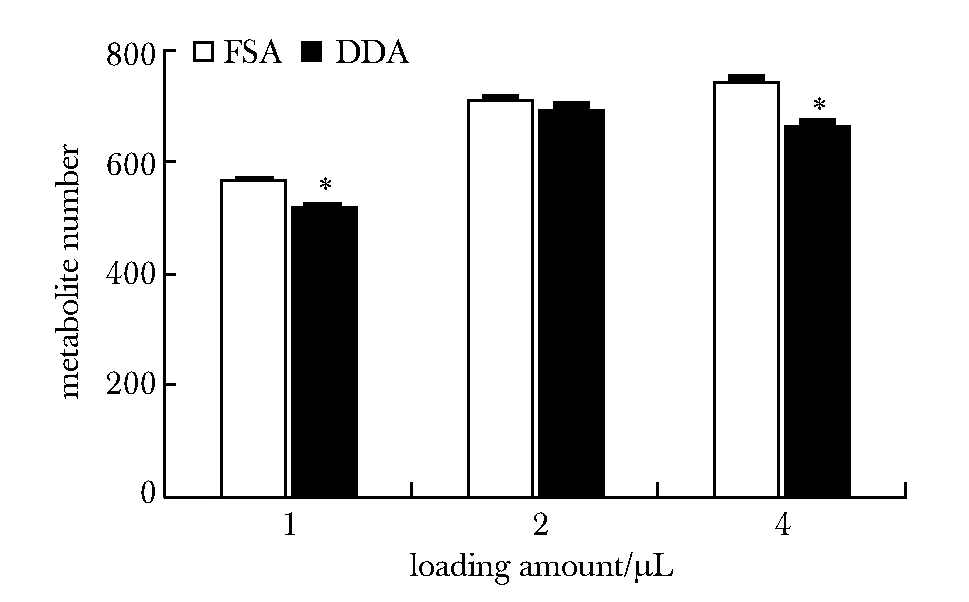
*P<0.05 compared with full scan acquisition图2 两种采集方法尿液代谢物鉴定结果比较Fig 2 Comparison of urine metabolite number in two acquisition methods
2.2.2 定量比较:进样量为1、2和4 μL时,DDA组的CV中位数为10.3%、7.0%和6.5%,FSA组的CV中位数为7.1%、3.0%和2.6%。3种进样量中,两组的丰度CV分布趋势一致,DDA组的CV分布总体高于FSA组(图3)。
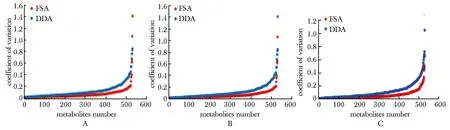
A.technical CV distribution of urinary metabolites with 1 μL loading amount; B.technical CV distributionof urinary metabolites with 2 μL loading amount; C. technical CV distribution of urinary metabolites with 4 μL loading amount图3 两种采集方式不同上样量尿液代谢物实验操作CV重复性比较Fig 3 Distribution of repeatitive technical CV comparison of urinary metabolites in two acquisition methods
低丰度代谢物(质谱信号强度10~100)中,进样量为1、2和4 μL时,DDA组代谢物的丰度CV均数分别较FSA组高1.3、1.7和1.9倍(P<0.05)。中(信号强度100~1 000)、高(信号强度为>1 000)丰度代谢物中,进样量为1 μL时,两组的CV均数相近;进样量为2和4 μL时,DDA组代谢物的丰度CV均数分别较FSA组高1.7、1.8和1.9、1.4倍(P<0.05)(图4A)。
在峰宽时间<5 s的代谢物中,进样量为1、2和4 μL时,DDA组的CV均数分别较FSA组高1.8、1.7和2.2倍(P<0.05)。峰宽时间为5~10 s的代谢物中,进样量为1、2和4 μL时,DDA组的CV均数分别较FSA组高1.5、2.1和2.1倍(P<0.05)。峰宽时间为>10 s的代谢物中,进样量为1 μL时,两组的CV均数相近;进样量为2和4 μL时,DDA组的CV均数分别较FSA组高2.0和2.0倍(P<0.05)(图4B)。

A.technical CV distribution of metabolites with different abundance; B. technical CV distribution of metabolites with different chromatographic peak width; *P<0.05 compared with full scan acquisition图4 两种数据采集方式鉴定代谢物丰度和峰宽的实验操作CV重复性分布比较Fig 4 Distribution of repeatitive technical CV comparison of metabolites with different abundance and chromatographic peak width in two acquisition
3 讨论
本研究比较了FSA和DDA两种质谱采集方法在非靶向代谢组学分析方法中的结果。通过分析代谢物标准品混合样和健康人尿液代谢物,结果表明,两种模式都能对上述样品进行定性定量分析,拥有各自的优缺点。
FSA模式鉴定的代谢物数目更多,并且鉴定的代谢物丰度总体高于DDA模式,定量的重复性和准确度更高。在FSA模式中,质谱将全部的时间用于采集一级谱图。因此,采集代谢物色谱峰的数据点数多,定量的准确性更高;另一方面,因为有更多时间进行数据采集,可以采集到色谱峰的最高点,定量的色谱峰面积更大,因此强度更高。定性方面,FSA模式的二级鉴定使用了4种不同的碰撞能量,可以采集更多信息量,因此鉴定的代谢物多。以往文献报道,在非靶向代谢组学中,FSA模式相比DDA模式可以捕获更多代谢物特征,由于FSA模式采集一级谱图的时间更多,这与本研究结果一致[10]。 但是,FSA模式仍存在不可忽略的问题,该模式下代谢物的定量与定性分析是分开检测的,需要进行两批次的质谱分析,这对液质联用系统的稳定性要求高。只有色谱的保留时间在一致的情况下,才能确保两次采集的数据具有可分析性。尤其是,对大批量样品进行长时间分析时,技术难度相对较大。因此,该方法更适用于小规模样品量的代谢组分析。
DDA模式可同时进行一级和二级谱图的采集,定性与定量仅需采集一次即可实现。但是,由于DDA模式的一级谱图采集分配了很大一部分采集时间用于二级谱图的产生,导致错过色谱峰的最高点,定量的峰面积较低,峰强度较低;而且,采集色谱峰的点数减少,导致定量的准确性降低。而定性方面,由于DDA模式的二级碰撞能量只有一种,采集的信息量较少。因此,鉴定的代谢物数目相对少。虽然DDA模式有以上问题,但DDA模式定量的CV在10%左右,尚在误差允许范围内,定性数目也仅少10%。考虑到DDA模式对系统的稳定性要求相对较低,并且操作简便,省时省样本量,因此,其更适用于长时间大样品量分析。
本研究全面分析了尿液代谢组学非靶向质谱分析法常用的两种数据采集模式,评价其各自的优缺点,为非靶向分析方法的选择提供了参考。
猜你喜欢
现代临床医学(2022年4期)2022-09-29
成都信息工程大学学报(2021年5期)2021-12-30
理化检验-化学分册(2020年5期)2020-06-15
农药科学与管理(2019年5期)2019-08-13
中成药(2018年12期)2018-12-29
系统医学(2016年8期)2016-02-20
质谱学报(2015年5期)2015-03-01
中国检察官(2015年14期)2015-02-27
中国检察官(2015年12期)2015-02-27
中国现代医生(2014年10期)2014-04-23
