
基于遗传算法优化BP 神经网络的中国企业OFDI 投资额预测模型
2021-05-12 10:51刘峻杉张磊尹寓
现代计算机 2021年7期
刘峻杉,张磊,尹寓
(1.四川大学计算机学院,成都610065;2.四川省大数据分析与融合应用技术工程实验室,成都610065)
0 引言
中国作为新兴的发展中国家,自改革开放以来,企业对外直接投资(Outward Foreign Direct Investment,OFDI)取得长足进展,《2019 年度中国对外直接投资统计公报》[1]指出:2018 年末,中国对外直接投资存量达2.2 万亿美元,分布在全球188 个国家和地区,影响力不断扩大,也催生出一大批具有较强跨国经营能力、能够在全球范围内布局生产网络的跨国公司。但是,相对于西方发达国家在跨国投资上的丰富经验,中国企业OFDI 起步较晚,经验不足,在新形势下仍面临许多问题和困难。同时,国际局势风云变幻,各种不确定因素叠加,主要发达国家逆全球化思潮抬头,给中国企业OFDI 带来了风险和挑战。
在中国企业OFDI 过程中,往往需要考虑多方面的因素,其中区位选择是一项非常重要的决策,事关投资成败。对相关文献进行梳理发现,以东道国为单位的研究容易忽略企业间的异质性,而以企业为单位的研究又容易忽略了区位间的差异性。并且,主流社会科学研究普遍采用统计方法来描述或检验自变量与被解释变量之间的关系,因此常常做出不切实际的假设[2]。此外,由于回归的统计数据通常仅代表平均结果,因此无法确定个别公司相关的特定关系的上下文关系[3]。与传统统计方法相比,用计算机领域的方法来解决现实世界的金融问题,能够考虑所有相关的特征[4]。
因此,针对上诉存在的问题以及实际需求,本文引入计算机方法来解决了中国企业OFDI。首先,自组织映射算法常被用来确定不明确聚类数目问题的初始聚类[5],但是,自组织映射用作聚类的一个缺陷在于,样本在特定聚类中的隶属度并不总是容易判断的。为此,本文采用模糊C 均值聚类,该方法融合了模糊理论的精髓,赋予每个样本属于每个簇的隶属度。其次,神经网络在许多不同的领域中得到了应用,其中BP 神经网络是一种应用最为广泛的神经网络,已证明它具有实现任何复杂非线性映射的功能[6]。因此,本文基于自组织映射和模糊C 均值聚类的结果,采用遗传算法优化的BP 神经网络构建中国企业OFDI 的投资额预测模型,解决了金融数据高维特征问题的同时,也对中国企业OFDI 的投资额进行了预测。
1 相关工作
一方面,在过去十年中,OFDI 已成为全球资本流动的一个主要因素,相关文献构建了这一领域的综合研究框架。跨国企业所有权优势、内部化优势和区位优势的不同组合决定了它们从事国际经济活动的方式[7-8]。其中,OFDI 驱动因素、进入模式和区位选择是论文最多的类别,占总数近70%[9]。现有文献大多认为,中国企业OFDI 具有区位偏好特征,Liu 和Deseatnicov 研究了过去经验对中国企业OFDI 区位选择的影响,发现OFDI 的企业会根据其他企业的投资经验进行区位选择[10]。Aw 和Lee 认为OFDI 不仅取决于东道国的因素,还取决于企业的生产力[11]。之后,Marti 等人便认为跨国公司的区位选择受到公司层面和国家层面的综合影响[12]。事实上,当地市场潜力、生产成本、运输成本、税收、地理、文化和制度距离[13-14]等都会对企业OFDI 产生影响。研究大多是运用财务模型和统计方法进行的实证研究。很少有人将计算机科学方法与OFDI 数据联系起来。
另一方面,一些研究者们将自组织映射和模糊聚类相结合进行特征提取,解决了很多实际问题。Xu 等人使用自组织映射和改进的模糊聚类算法对手机用户进行了用户特征聚类[15];Das 和Basudhar 根据已有的圆锥贯入试验结果,使用自组织映射和模糊聚类技术来分离分层土中的不同层[16];Yu 等人提出了一种利用上粒子群优化的全局能力的改进的模糊C 均值聚类算法将全国省份划分成不同的大类[17]。一些研究者将BP神经网络用于金融领域。Yang 和Ji 设计了基于BP 神经网络的风险识别工具,用于在商业银行贷款的风险预警[18]。Mao 和Liu 等构建了一个动态结合解释性BP神经网络和时间序列BP 神经网络的区域财政一般预算收入预测模型[19]。Wu 和He 构造了一个三层BP 神经网络对我国股票价格的波动趋势进行拟合[20]。Liu和Ding 提出了遗传算法和禁忌搜索算法解决了传统的BP 神经网络优化问题的同时,也提高了经济效益评价指标及其评价不确定性下的投资效益[21]。Shen 和Zhang 等在宏观投资中,利用改进的BP 神经网络建立了投资决策模型,实验证明BP 神经网络模型能反映投资各要素之间高度非线性的映射关系,可广泛应用于投资问题[22]。
通过相关文献启发,本文针对OFDI 所面临的复杂信息结构,采用自组织映射和模糊聚类的方法对大量东道国特征进行聚类以提取区位特征,然后结合基于遗传算法优化的BP 神经网络构建中国企业OFDI 的投资额预测模型,以辅助企业投资者进行投资决策。
2 方法
2.1 研究流程
在本文中,我们引入了一种新方法,将确定初始聚类的自组织映射和挖掘区位特征的模糊C 均值聚类算法结合起来,加以应用于基于遗传算法优化的BP 神经网络的投资额预测模型。图1 是SOM-FCM-GA-BP(SFGB)算法的设计步骤。

图1 SFGB算法的设计步骤
2.2 自组织映射算法
自组织映射(Self-organization Mapping,SOM)算法是一种无监督的神经网络算法,自动完成聚类过程,不需要预先设置初始簇数,因此用来作为不确定聚类数目情况下的预聚类[23]。SOM 由输入层和输出层构成,输入层根据输入神经元的数目获取属性信息,输出层根据用户的输入数据进行竞争输出,并根据其结构的不同,可以分为一维线性结构或者二维平面阵列,本文使用二维结构,便于可视化初始聚类结果。

(3)寻找获胜神经元
计算输入样本与输出神经元之间的距离dj,并选择距离最小的神经元c 作为获胜神经元,本文使用欧氏距离作为判断依据,即:
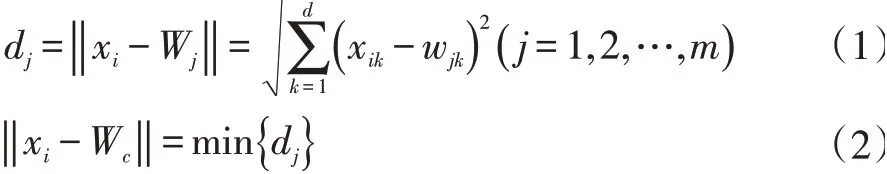
(4)参数调整
本文对获胜神经元及其领域内hj,i( t )所有神经元的权值作如下式(3)调整,领域外的神经元权值保持不变:

其中,0 <η( t,r )<1 为学习率,是关于领域半径r和迭代次数t 的函数,领域半径r 一般随t 的增加逐渐减小,并且调整的幅度也越来越小,趋于聚类中心,本文将学习率调整如下式(4):

(5)循环学习
将新的输入模式带入到下一轮迭代学习中,寻找新的获胜神经元并调整相应的参数,直到t=T 时结束循环,其中T 为设定的迭代次数。
对于传统的聚类算法,聚类的数目都需要提前的确定,对于不知道聚类数目的数据,随机确定的聚类数目往往会影响到聚类结果的优劣。而SOM 算法的优势就是不用提前确定聚类数目,其无监督的特性可以自动分类数据。因此,本文使用SOM 算法对区位特征进行初始聚类,确定聚类数目,并将结果用于下一步模糊C 均值聚类算法的初始输入。
2.3 模糊C均值算法
在实际情况下,数据集中的样本不能划分成为明显分离的簇,指派一个样本到一个特定的类不能满足实际的需要。而模糊聚类的思想就是估计样本点与聚类中心的隶属度,每个样本点都有对于聚类中心的不同隶属度,反映了该样本属于该聚类的程度。当然,基于概率的方法也可以给出这样的权值,但是有时候我们很难确定一个合适的统计模型,因此本文使用具有自然地、非概率特性的模糊C 均值(Fuzzy C-means,FCM)。


2.4 遗传算法优化的BP神经网络
(1)模型结构
在BP 神经网络模型中,有三层结构,输入层、隐藏层、输出层。
原始数据集是由连续特征和分类特征组成,其中分类特征是离散的、无序的。而分类器通常数据是连续且有序的,因此本文使用独热编码来处理分类特征。输入层节点数由企业特征和区位隶属度确定。输入层共有n 个神经元。
隐藏层的设计是一个非常困难和复杂的问题,特别是要确定隐藏层的数量及其节点数[24]。隐藏层节点数由细分的企业特征确定。隐藏层共有m 个神经元。
输出层节点为投资额。输出层共有l 个神经元。
(2)遗传算法优化
遗传算法(Genetic Algorithm,GA)是一种“优胜劣汰,适者生存”的并行随机搜索最优化方法。BP 神经网络用遗传算法得到的最优个体的权值和阈值来初始化,能够提高模型的精度和性能。
GA 优化可以采用实数编码和二进制编码。本文采用了三层BP 神经网络,并使用实数编码的方式,编码长度L 为:

GA 在优化的过程中根据个体的适应度值,本文采用均方误差MSE 作为适应度函数:

GA 通过不断的选择、交叉和变异,计算个体的适应度值,找到最优适应度值的个体。图2 是GA-BP 的流程图。

图2 GA-BP流程图
3 实验与评价
3.1 数据集
本文数据来源于前期已经匹配整合的四个数据库:
●第一个是商务部公布的境外投资企业机构名录,它包括了境内投资主体、境外企业名、业务范围、投资流入地以及投资时间等信息;
●第二个是商务部公布的《中国企业对外直接投资公报》,它包括了中国对每一个东道国的OFDI 流量和存量信息;
●第三个是Wind 数据库、CSMAR 数据库,它包括了沪深两地股市2004-2015 年期间持续存在的上市企业的所有企业信息和财务数据;
●第四个是中国工业企业数据库,它包含了企业相关的基础信息;
●第五个是世界银行、国际货币基金组织以及ICRG(International Country Risk Guide)等数据库,它包含了东道国的特征变量信息,如政治风险、基础设施、技术水平、资源禀赋等。
本文通过对上述数据进行整合、匹配,获得了2004-2015 年参与OFDI 的1000 多家企业国别对外投资数据。通过数据预处理,最终将建立包括近80 个企业层面与东道国层面的特征因素的中国企业投资信息数据库。图3 是预处理后的样本数据。

图3 数据样本
3.2 模糊聚类结果
该阶段首先利用SOM 算法对国家因素进行初始聚类,确定聚类数目。本文通过调整输出神经元参数,每种情况进行了10 次自组织映射算法实验,计算平均聚类数目。图4 是不同输出神经元参数下的平均聚类数目。
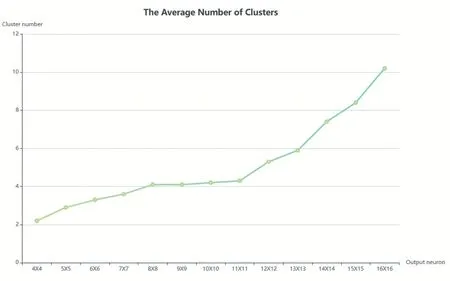
图4 平均聚类数目
本文将数据映射到二维地图空间的U-Matrix 改进到三维平面,便于更方便的显示输出神经元之间的关系。图5 是输出神经元之间的距离,神经元之间的距离越远颜色离红色越近,在图中表示为山脊;神经元之间的距离越近颜色离红色越远,在图中表示为山谷。
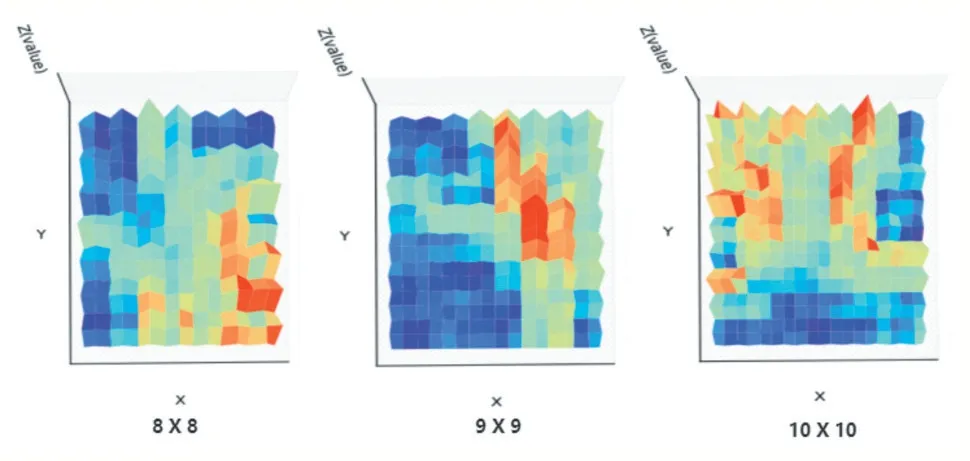
图5 三维U-Matrix
由实验结果可知,本文选择10×10 的输出神经元可以得到最好的初始聚类结果,设置初始聚类数目为4。然后输入到FCM 算法,得到企业投资区位的特征分布。表1 是根据聚类的中心选出的部分具有最大值的属性,通过对其分析,总结了每一簇的区位所具有的区位优势,其中将区位隶属度差距不大的样本同时归于两个区位。
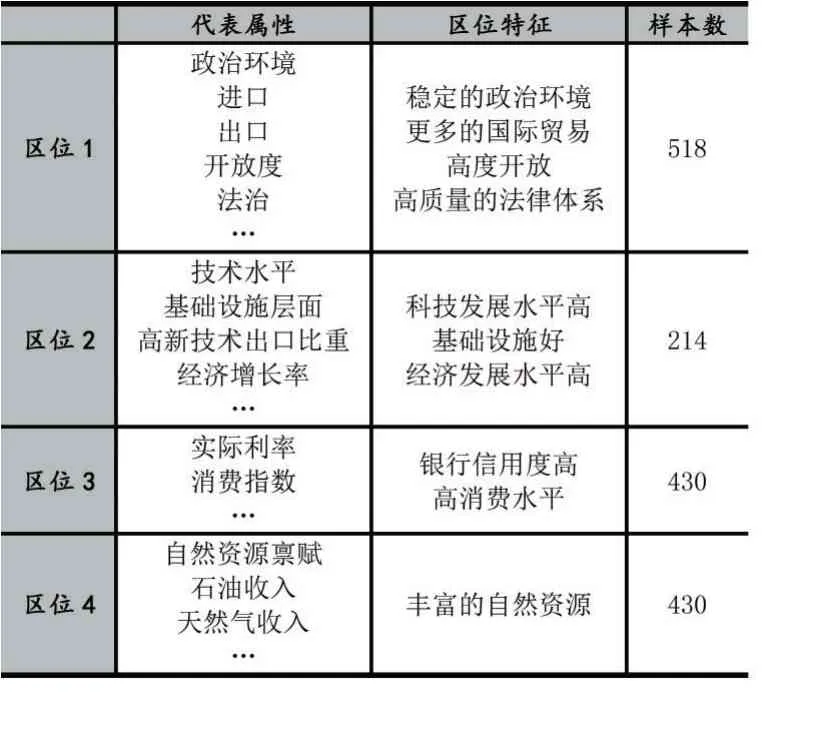
表1 每一簇的代表属性和区位特征
表2 是通过FCM 聚类过后企业投资区位所具备优势的程度,也就是FCM 聚类得到的隶属度,并将结果用于下阶段的投资额预测模型。
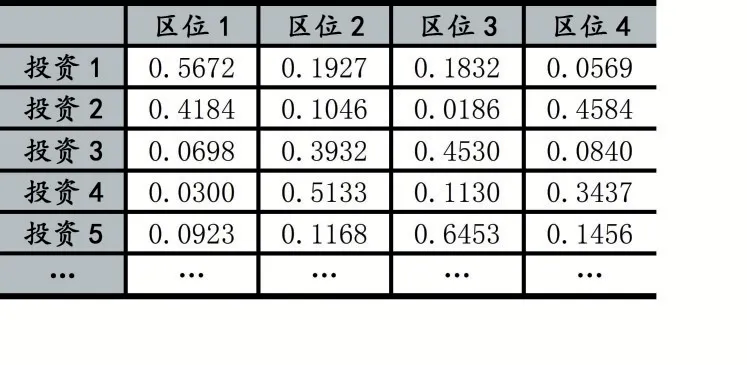
表2 区位特征隶属度
3.3 网络模型构建
该阶段是基于GA 优化的BP 神经网络的投资额预测模型。因为企业样本中存在不同层面的属性指标,本文将其分为企业综合能力属性(市值、周转率、收益等),企业人员规模属性(独董比例、监管层持股比例等)以及行业属性(所属行业、工业占比、服务业占比等),以及区位的隶属度,所以本文使用单个隐藏层,并将节点数设置为4。并且在输入层和隐藏层都加了一个偏差节点。图6 是BP 神经网络模型的结构。
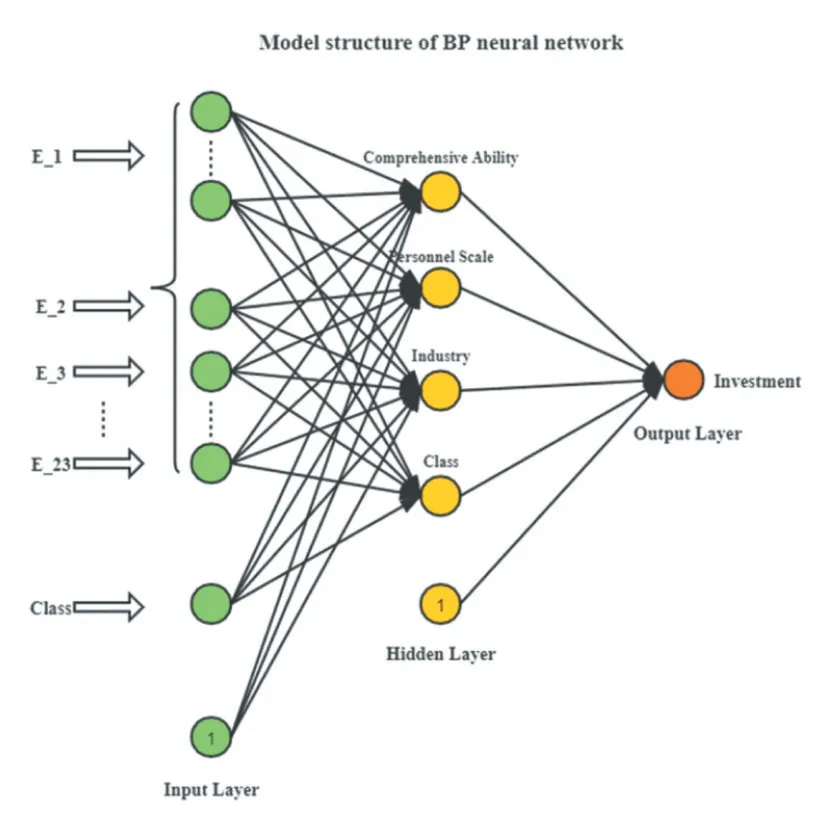
图6 BP神经网络模型结构
本文将原始数据按7:3 的比例划分训练集和测试集,经过实验,当学习率η=0.1 时MSE 具有最好的结果。图7 与图8 是基于BP 神经网络和基于GA 优化的BP 神经网络的MSE 与MAE 的比较。
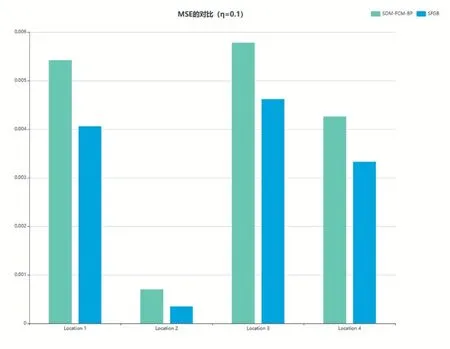
图7 均方误差MSE的比较(η=0.1)
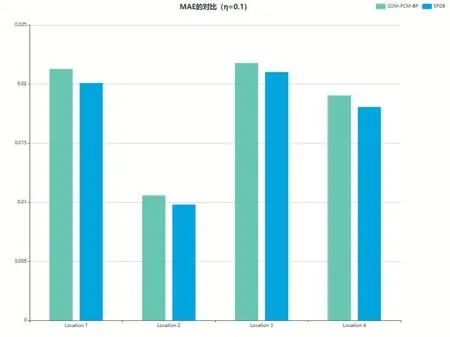
图8 平均绝对误差MAE的比较(η=0.1)
基于GA 优化的BP 神经网络在四个区位的MSE和 MAE 表 现 分 别 为 0.00406、0.00035、0.00462、0.00333 和0.02009、0.00980、0.02101、0.01806,要优于BP 神经网络的0.00542、0.00067、0.00578、0.00426 和0.02127、0.01057、0.02177、0.01902。其中,在区位2 上面MSE 和MAE 的表现都是最优的。
表3 是基于GA 优化的BP 神经网络和BP 神经网络迭代1000 步以内达到预设目标的比较。
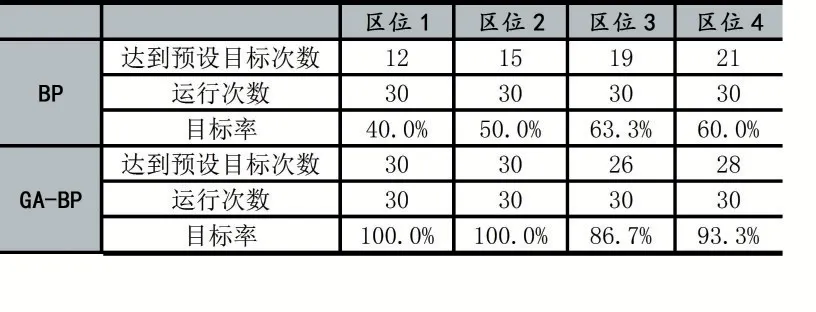
表3 迭代1000 步以内达到预设目标的比较
基于GA 优化的BP 神经网络在区位1 和区位2上迭代1000 步达到预设目标的目标率均为100%,在区位3 和区位4 上分别为86.7%和93.3%均要优于BP神经网络。相比于BP 神经网络,基于GA 优化的BP神经网络能够更迅速地拟合数据以达到预设目标。
4 结语
本文将计算机技术应用于中国企业OFDI 中,是一次有益的尝试,为实现智能化投资决策探索新方法提供新思路。针对金融数据的高维数据特征,本文提出自组织映射和模糊C 均值聚类的方法将东道国因素按区位特征进行聚类,并结合GA 优化的BP 神经网络构建投资额预测模型,进行有针对性的投资决策。从实验结果看,该算法在解决数据高维问题的同时也能有效的进行中国企业OFDI 决策。并且,与常用算法的对比实验可以得出,基于GA 优化的BP 神经网络具有更好性能和实用价值。
当然,本文还有很多不足之处。中国企业OFDI 影响因素复杂多变,黑天鹅等突发事件往往会影响到企业决策者的投资选择,加入实时特征是企业对外直接投资决策更深一步的工作。
猜你喜欢
决策(2022年6期)2022-07-05
包装工程(2022年11期)2022-06-20
汽车工程(2021年12期)2021-03-08
电子产品世界(2021年8期)2021-01-16
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
中国计算机报(2019年49期)2019-02-07
智富时代(2018年4期)2018-07-10
智富时代(2018年4期)2018-07-10
中国新闻周刊(2017年36期)2017-10-21
