
基于深度学习的遥感图像地物分割方法
2021-05-11 02:39沈言善王阿川
液晶与显示 2021年5期
沈言善,王阿川
(东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨 150000)
1 引 言
如何将遥感图像中的地物信息快速准确地进行分割是当前的研究热点之一[1]。传统的分割方法与地物的一系列特征有关,针对不同地物的特征,采用的方法也不同。针对森林植被分类,李亮等[2]提出了一种综合光谱、纹理、结构特征的高分辨率遥感影像变化检测方法。针对道路分类有最近邻[3]、隶属度函数[4]等方法。上述传统方法只能针对某种地物特性采用相对应的方法,分割的地物种类单一。而高分辨率遥感图像通常包含道路、建筑、水源、植物等具有丰富细节信息的地物目标。针对遥感图像中多种信息特征,传统的分割方法很难同时有效地进行多目标分割。近年来,计算机视觉技术发展迅速,语义分割作为研究热点之一,在卫星遥感图像和医学影像等领域都有着广泛的应用前景。Long 等[5]第一个提出了用于语义分割的全卷积神经网络(FCN),开启了全卷积网络用于图像语义分割的新篇章。其他优秀的语义分割网络结构还包括U-net[6]、SegNet[7]、MobileNetV2[8]、PSPNet[9]等。但是在遥感图像中,受目标类别分布不均衡等因素的影响,常用的语义分割方法针对高分辨率遥感图像的多类别分割问题并不能达到有效目的。
为了解决以上问题,本文借鉴了U-net模型结构,设计并提出了一种改进的全卷积神经网络模型用于高分辨率遥感图像的地物分类任务。通过使用扩张卷积作为卷积层之间的级联方式在不增加网络参数的情况下增大感受野,降低训练与预测时的计算量,提高了模型运行的效率。针对样本类别不均衡带来的模型偏好问题,采用加权交叉熵作为模型的损失函数提高了模型的泛化能力。实验结果表明,本文模型总体的分割效果优于U-Net和SegNet模型,证明了该模型在遥感图像地物分类中的有效性。
2 相关理论及网络设计
全卷积神经网络(FCN)的提出是在2016年,相比较于CNN和VGG等卷积全连接的网络结构,FCN将卷积层替代全连接层来处理语义分割问题。全卷积神经网络主要有3个特点:一是采用全卷积的方式对输入图像进行特征提取和下采样;二是使用双线性插值的方法进行特征图的上采样;三是使用跳跃连接进行对应层的特征融合。早期基于深度学习的图像分割以FCN为核心,旨在重点解决如何更好地从卷积下采样中恢复丢掉的信息损失。U-Net是一个结构对称的U型全卷积神经网络,它和FCN都是基于Encoder-Decoder[10]结构。Encoder负责特征提取,由卷积操作和下采样操作组成,在这里采用的卷积结构统一为 3×3 的卷积核,padding 为 0,striding 为 1。Decoder负责样本还原,由反卷积操作和上采样操作组成。反卷积的卷积核也为3×3,上采样采用双线性插值法。Skip Connection将U-Net中的底层特征中的位置信息和深层特征中的语义信息相融合,实现端到端的像素级分类。
2.1 数据集及其预处理
本文采用的数据集为2015年南方某地区的高分辨率卫星遥感影像,共包含5幅大尺寸的原始图像和5幅标签图。该数据集的标签图共标记了5种类别的地物目标。为了更好地观察标注情况,我们将人工标记图片可视化如下:紫色表示其他、蓝色表示植被、绿色表示道路、黄色表示建筑、红色表示水体。图1(a)和(b)分别是公开数据集样本和可视化的标记图。表1是本文所用数据集的样本分布统计情况。将数据集用4∶1的比例分开,分别用作实验的训练集和测试集。由于原始数据集中遥感图像尺寸从4 000×4 000到8 000×8 000不等,直接作为网络的输入图像会导致内存溢出而无法训练,因此使用OpenCV对其做了相应的数据增强处理。具体地,将用于模型训练的每幅标签图的4个地物类别分别截取成仅包含植被、道路、建筑、水体的4幅子图。把训练集中每幅原始图像和标签子图随机切割成256×256大小的图像块,然后对图像块做了旋转操作、色彩调整[11]、以及增加噪声操作(Gaussian noise,salt-and-pepper noise)。通过上述处理,新的训练集包含10万幅256×256大小的子图像。

(a) 原始图像(a) Original image

表1 数据集样本分布统计Tab.1 Dataset sample distribution statistics
2.2 改进卷积方式
针对遥感图像的语义分割是一种端到端的像素级分类任务,图像分割的精确度一定程度上取决于上下文的信息。传统的卷积计算通过增大卷积核的尺寸来获得更多的感受野,但这样会使网络的参数增多,消耗更多的硬件资源。扩张卷积[12](Dilated Convolution)是一种不同于传统卷积的卷积方式,能够对输入图像采用具有更大感受野的滤波器提取特征,并且不会增加网络的参数。如图2所示,红点表示两种相同尺寸不同卷积方式的卷积核,蓝色的区域表示感受野大小。图2(a)中扩张率为1,感受野大小为3,与传统卷积计算的感受野一样;图2(b)中扩张率为2,感受野大小为7。若采用传统卷积,则需尺寸为7×7的卷积核才能获得同样的感受野。对比图2(a)和(b)可知,相较于传统卷积,扩张卷积在不增加卷积核尺寸的同时能获得更大的感受野。图3(a)为2个标准3×3卷积层级联所组成的卷积序列。图3(b)为将两层级联的卷积层设置扩张率为1和2的扩张卷积序列。对比图3(a)和(b)可以看出,在使用扩张率为1和2的扩张卷积级联形成卷积序列中,高层神经元在输入层能具备更大感受野。通过图3(a)的方法将模型中的卷积模块变为扩张卷积模块,能够在增大高层神经元在输入层上感受野的同时保证了神经元的语义信息连续性。
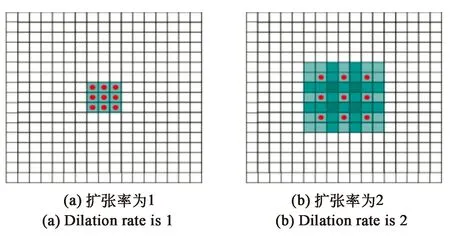
图2 扩张卷积示意图Fig.2 Schematic diagram of dilated convolution

(a) 标准卷积级联(a) Standard convolution cascade
2.3 激活函数的选取
激活函数是神经网络结构中的重要部分,其中经典U-Net 网络中采用RELU[13]函数作为激活函数,其定义如式(1)所示:
f(x)=max (0,x),
(1)
其函数变化曲线如图4所示。RELU实际上是一个分段函数,当输入为正值时输出不变,但在输入为负值时,RELU是硬饱和的,在反向传播的中梯度始终为0,权重参数无法更新,会导致神经元死亡。为解决输入为负值时神经元失活问题,将RELU函数的前半部分从0变为一个指数函数,得到了指数线性单元[14](ELU)。其定义如式(2)所示:

图4 RELU和ELU的函数图Fig.4 Function diagram of RELU and ELU
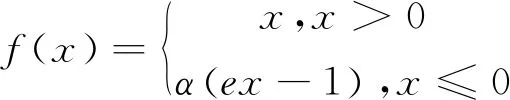
(2)
对于ELU的导数来说,如果输入为负值,输出不为常数0,就可以避开死亡RELU问题,同时还保持了一定的稀疏性,可以有效缓解梯度消失问题。
2.4 损失函数的设计
损失函数是遥感图像语义分割任务中重要的组成部分,常用的分类损失均可用作语义分割的损失函数。其中经典U-Net网络模型使用的二分类交叉熵作为损失函数,其定义如式(3)所示:
Loss=-[yij·lgpij+(1-yij)·
lg (1-pij)],
(3)
pij是像素i被模型预测为j类的概率,yij是样本实际标签,如果像素点i属于j类,取值为1,否则取值为0。
本文数据集目标地物类别有4类(不包括“其他”类),在表1中样本数量较少的道路和水体分别占6.5%和6.6%,而建筑和植被则占到了24.8%和32.6%。使用具有类别不均衡问题的数据作为训练集,网络在训练过程中拟合过的各地物类别的像素数量不同,影响了其对不同类别像素分割的准确率。在图片分类问题中,往往通过数据增强的方式使不同类别图片在数量上实现均衡。但遥感图像地物分类不同于图片分类任务,一幅遥感图像中的标签信息并非单个类别值,而是一幅二维平面上的类别分布图。在实验中发现,仅是通过数据增强的方法增加小类别图片的数量对模型的分割精度没有相应提高,因此对遥感图像的类别不均衡问题应该考虑通过在损失函数中添加权重项进行类别均衡。通过为小类别像素赋予更大的权重值,为大类别赋予较小的权重值,可缩小在模型训练中不同地物类别像素计算损失函数平均值的差距。
本网络采用根据样本不同地物类别比例作为权重项的加权交叉熵作为模型的损失函数,其定义如式(4)所示:
Loss=-[wijyijlgpij+(1-yij)lg (1-pij)],
(4)
pij是像素i被模型预测为j类的概率。yij是样本实际标签,如果像素点i属于j类,取值为1,否则取值为0。wij是权重系数,n为样本总像素数,nij为像素点i属于j类的像素数。
2.5 基于改进U-net的遥感图像语义分割模型
本文所改进的DL-Unet网络模型结构如图5所示。该网络包含9个卷积级联结构,每一个卷积级联设置为图3所示的扩张率为1和2扩张卷积序列,在卷积运算后加入BN层[15]。在网络的编码器部分,每个卷积层的卷积核尺寸为3×3,过滤器(Filter)深度为64。每两个卷积级联之间有一个窗口大小为2×2、步长为2的最大池化层(Maxpooling)。网络的解码器结构与编码器结构完全对称,卷积层的卷积核大小和过滤器深度与编码器部分相同。每两个卷积级联之间有一个窗口大小为2×2、步长为2的上采样层(Upsampling)。编码器和解码器部分相对应的卷积层采用跳跃连接的方式融合特征信息。
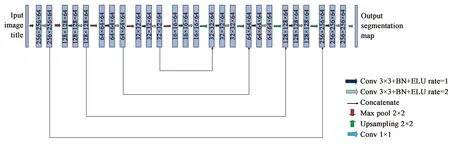
图5 DL-Unet模型网络结构Fig.5 DL-Unet model network structure
3 实验与分析
3.1 性能评价
遥感图像地物分类是一种图像分割问题,其本质上是一种图像像素分类。对分类后的遥感图像,可以使用像素准确率(Pixel Accuracy,PA)、平均像素准确率(Mean Pixel Accuracy,MPA)与平均交并比(Mean Intersection over Union,MIoU)等[16]常见的分类评价指标来评估模型好坏。评价每个像素的预测输出结果,即该像素分类结果取真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)4种结果中的一种,然后根据这4个指标计算,为了便于解释,假设k+1表示类别数量(其中包含一个空类或背景),pij表示假正例的像素数量,pji表示假负例的像素数量,pii表示真正例的像素数量。PA表示预测正确的像素占总像素的比例,定义如式(5)所示:
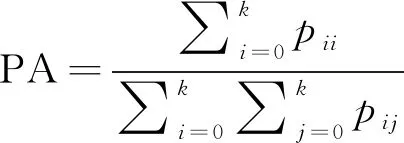
(5)
k+1表示类别数量(其中包含一个空类或背景)。
MPA表示分别计算每个类别分类正确的像素数占所有预测为该类别像素比例的平均值,定义如式(6)所示:

(6)
k+1表示类别数量(其中包含一个空类或背景)。
MIoU的定义为:将标签图像和预测图像看成是两个集合,计算两个集合的交集和并集的比值,将所有类别计算得出的比值取平均。定义如式(7)所示:
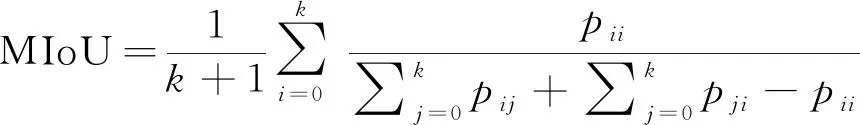
(7)
k+1表示类别数量(其中包含一个空类或背景)。
3.2 模型训练及测试
实际为每一类地物目标训练了一个二分类模型,共得到植被、道路、建筑、水体的分割模型。在上述的实验环境下对图5所示的网络模型进行训练。实验将数据集按5∶1比例进行划分,即75 000张图像作为训练集,25 000张图像作为验证集。模型训练采用批处理方式,每一个batch输入16张图片,完成一个epoch需要6 250个batch,设定模型完成30次epoch。模型基于keras 框架使用GPU 进行训练,优化器设置为Adam(Adaptive moment estimation),评价指标为准确率(Accuracy),使用加权的交叉熵损失函数。在模型训练的过程中设定监视对象为val_acc,当val_acc 最大时自动保存最优权值,保存在最优权重下的模型。训练过程中的学习率设置为0.001。如图6所示 ,随着迭代次数的增加,训练集和验证集的准确率与损失变化趋于平缓,表明模型达到了最优。

图6 训练过程Fig.6 Training process
将训练好的各类模型分别对测试图像进行植被、道路、建筑和水体的预测,共得到4幅预测好的子图。由于测试图像尺寸较大,需要将其分割为256×256 大小的多张图片进行预测,然后根据其位置再进行拼接成一幅完整的预测图。在合并4幅分割好的各类别子图时,使用相对多数投票的策略,即判定该像素的类别为4幅子图中出现次数最多的类别。如果某一像素点类别判定出现次数相同的情况时,则按照植被>道路>建筑>水体的优先级来确定该像素点的类别。遥感图像地物分割的流程如图7所示。

图7 遥感图像地物分割流程图 Fig.7 Remote sensing image feature segmentation flowchart
将预测出的结果写入灰度图中,像素值介于0~4 之间,为了便于观察,将每个像素值可视化为不同的颜色,如表2所示。
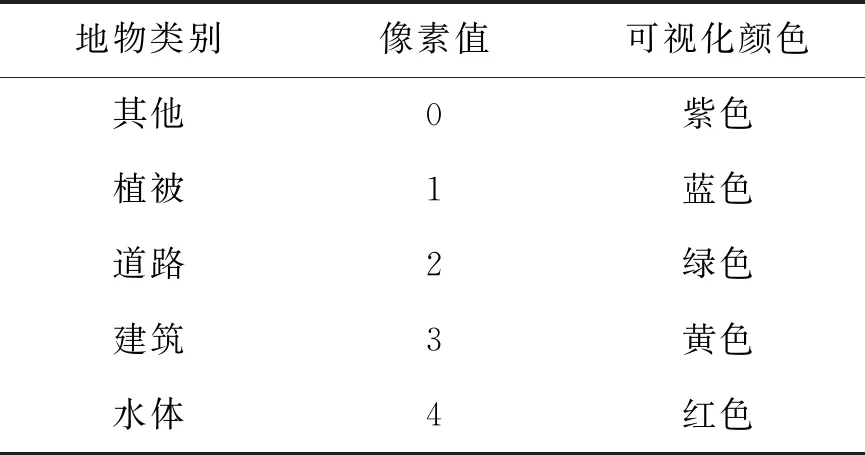
表2 数据可视化转换表Tab.2 Data visualization conversion table
3.3 实验结果分析
在上述实验条件下分别使用了经典的语义分割网络FCN-8s、DeconvNet、SegNet、U-Net和本文提出的方法进行训练和预测,各方法分割完成并可视化的结果如图8所示。
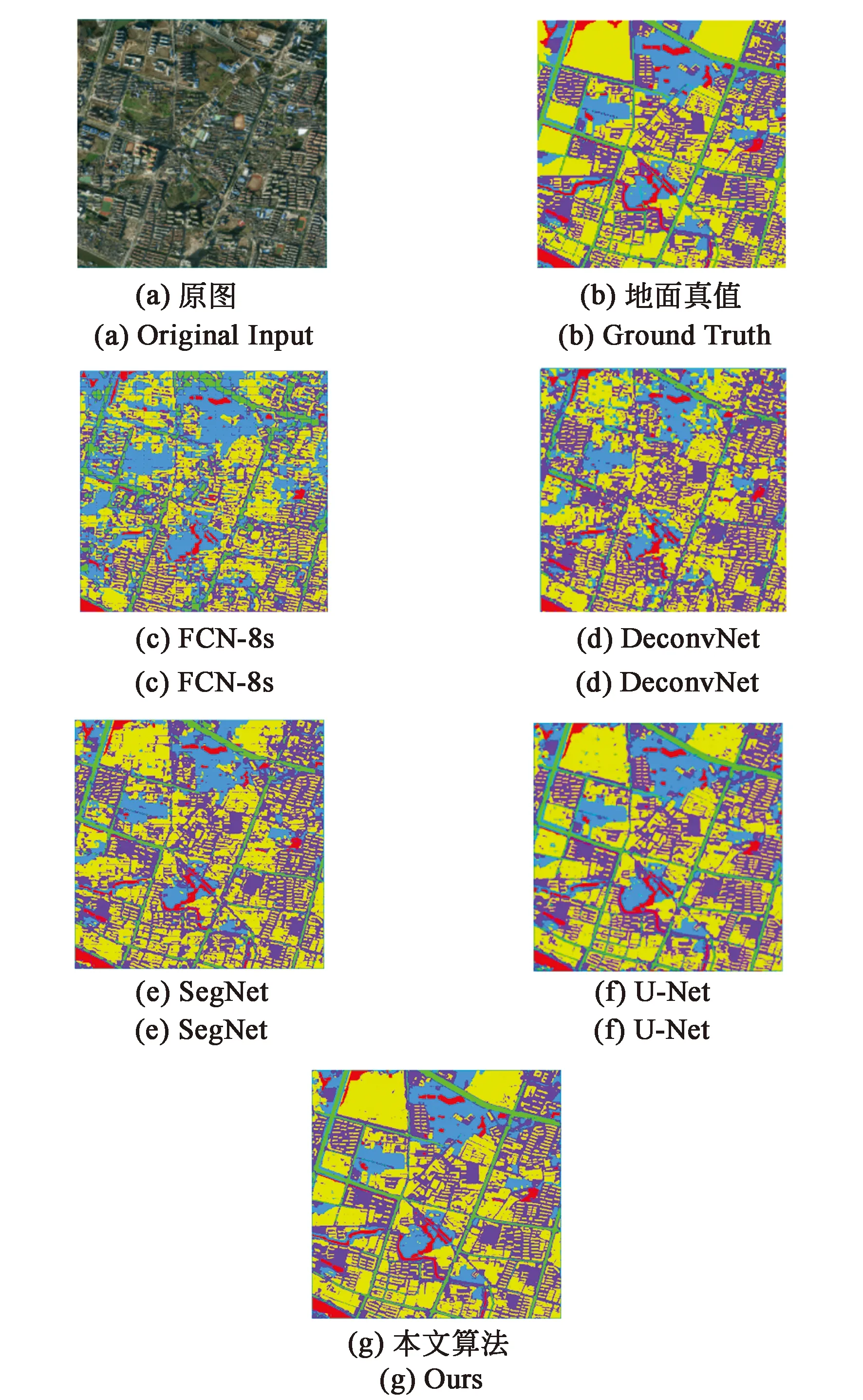
图8 测试图片分割结果Fig.8 Test image segmentation results
不同分割模型的各个地物类别的像素准确率(PA)如表3所示,各个模型在测试集上的平均像素准确率(MPA)和均交并比(MIoU)如表4所示。
从预测图和表3可以看出,本文的分割方法相较于多分类U-Net网络对于植被的像素准确率提高了3.30%,道路的像素准确率提高了5.40%,建筑的像素准确率提高了5.22%,水体的像素准确率提高了6.42%。从表4可以看出,本文的分割方法相较于U-Net网络在测试集上的平均像素准确率和均交并比分别提高了5.94%和9.45%。
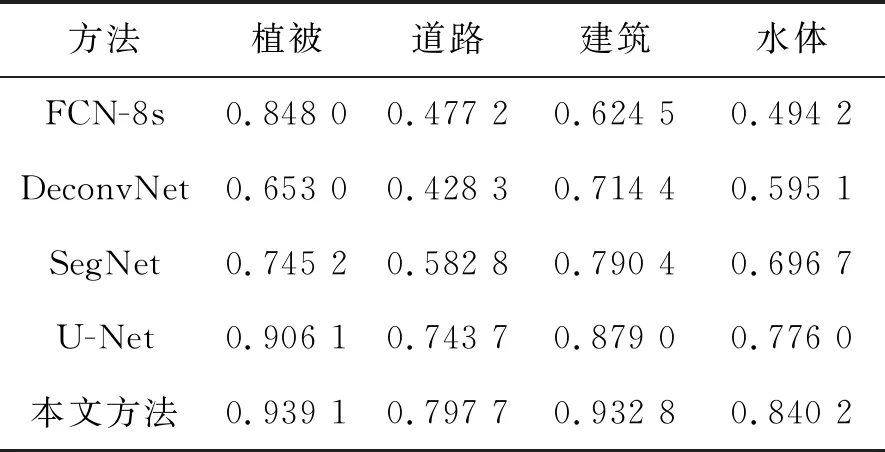
表3 各个地物类别的像素准确率Tab.3 Pixel accuracy of each feature category
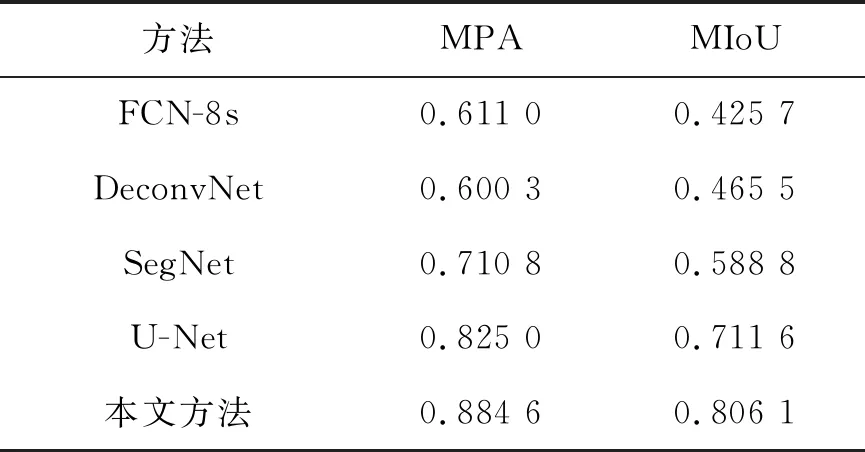
表4 不同模型的测试结果Tab.4 Test results of different models
在使用上述的数据集外,我们新增加了2020 CCF BDCI 遥感影像地块分割比赛的部分数据集来进行实验。该数据集包含20 000张分辨率为2 m/pixel、尺寸大小为256×256的原始图和20 000张包含建筑、耕地、林地、水体、道路、草地、其他、未标注区域这8个类别语义标签的标签图。为了更好地符合本文网络的输入,将耕地、草地、林地归为植被类别,将未标注区域归为其他类。
按3.2节所提的实验条件分别使用了经典的语义分割网络FCN-8s、DeconvNet、SegNet、U-Net和本文提出的方法进行训练和预测,各个模型在测试集上的平均像素准确率(MPA)和均交并比(MIoU)如表5所示。
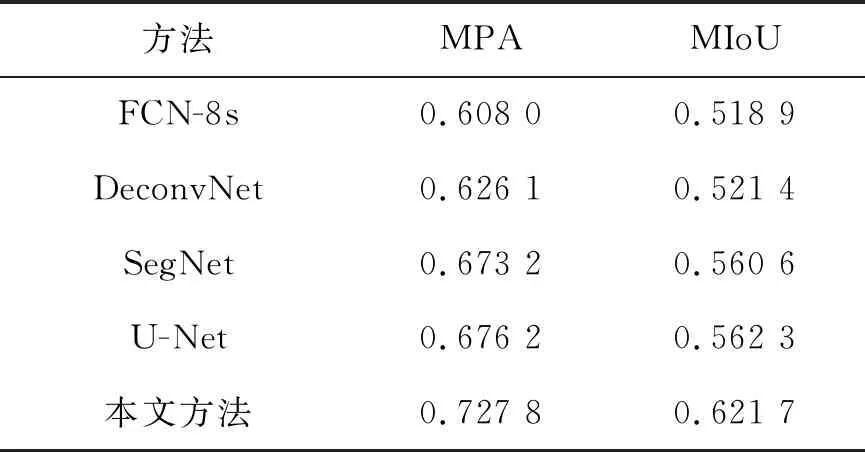
表5 在CCF BDCI数据集上的不同模型的测试结果Tab.5 Test results of different models on CCF BDCI database
从表4和表5可以看出本文方法在两个不同的遥感图像数据集上的平均像素准确率和均交并比优于U-Net和其他3种语义分割网络。
4 结 论
本文提出了一种基于U-Net网络改进的全卷积神经网络分割方法,对遥感图像实现了像素级别的分类。在保留了U-Net优点的同时,采用扩张卷积级联方式能考虑更多图像上下文信息并且不会增加网络的计算量。同时为了克服样本不均衡带来的模型选择偏好问题,本文采用了根据数据集地物类别比例来设置权重项的加权交叉熵作为模型的损失函数。对每一个地物类别都分别训练了一个二分类模型,然后采取相对多数投票策略并设置地物类别优先级的方法有效提升了预测图在各个地物类别的像素准确率(PA)。该模型的预测结果在平均像素准确率(MPA)和均交并比(MIoU)上相较于经典U-Net和SegNet有一定提升。实验结果表明,本文所提出的方法能够较精确地分割地物目标,达到比较好的效果。
但因硬件设备计算能力有限,模型的batchsize参数并不能设置得比较大,这影响了边缘分割的精细度。后续的研究将探索如何在进一步减少模型的参数情况下增加模型边缘分割的精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
电视技术(2014年19期)2014-03-11
中国中医药现代远程教育(2014年16期)2014-03-01
