
面向虚拟数据空间的智能TCP拥塞控制算法
2021-05-11 07:05王龙翔董凯李小轩董小社张兴军朱正东王宇菲张利平
西安交通大学学报 2021年5期
王龙翔,董凯,李小轩,董小社,张兴军,朱正东,王宇菲,张利平
(1.西安交通大学计算机科学与技术学院,710049,西安;2.西安美术学院信息中心,710065,西安)
当前,国家高性能计算环境中存储资源广域分散且隔离自治,大型计算应用迫切需要可支持跨域统一访问、广域数据共享、存储与计算协同的全局数据空间。因此,我国拟构建跨域虚拟数据空间,实现广域安全可靠数据共享、计算与存储高效协同、跨域多源数据聚合处理等关键科学问题,从而发挥广域资源聚合效应,有效支撑大型计算应用。虚拟数据空间的部署环境包括3个国家级超算中心(广州、济南、长沙)、两个国家网格南北主节点(中国科学院、上海)。虚拟数据空间在线存储近30 PB,活跃用户数超过6 000个,长期支撑数值模拟、大数据、人工智能等众多大型计算应用。虚拟数据空间存储数据规模达到PB级,其上层典型应用包括天气预报、全基因组关联分析等。不同超算中心在进行跨域节点数据迁移时,规模通常可达GB级甚至TB级,对网络传输性能提出了挑战。
为了实现虚拟数据空间可靠数据迁移,需要构建高效的可靠网络传输协议,而拥塞控制是实现高效可靠传输的关键技术。虚拟数据空间构建于广域网之上,其网络环境复杂多变,尽管在过去30年中研究者提出了各种各样的TCP拥塞控制算法(例如NewReno、Cubic等),但是这些算法普遍针对特定的网络环境,只能按照预先定义的规则进行拥塞控制,难以适应虚拟数据空间复杂多变的网络环境。
NewReno[1]和Cubic[2]使用数据包丢失来检测拥塞,并在检测到拥塞后降低拥塞窗口长度。Vegas[3]使用延迟、而不是丢包作为拥塞信号,可以解决基于丢包的拥塞控制问题。当Vegas检测到往返时延(RTT)超过设定值时,就会开始降低拥塞窗口长度。Westwood[4]改良自NewReno,基于传输能力的拥塞控制机制使用链路发送能力的预测作为拥塞控制的依据,通过测量确认字符(ACK)包来确定合适的发送速度,并以此调整窗口和慢启动阈值。混合拥塞控制机制组合两种拥塞控制机制,以得到它们各自的优势,进而更好地进行拥塞控制。Compound[5]、BBR[6]都属于混合拥塞控制机制。
传统拥塞控制机制使用确定的规则集对拥塞窗口及其他相关参数进行控制,很难适应现代网络的复杂性和快速发展。因此,研究者提出了基于强化学习的拥塞控制算法。强化学习作为机器学习的研究热点,已经广泛应用于无人机控制[7]、机器人控制[8]、优化与调度[9-11]以及游戏博弈[12]等领域。强化学习的基本思想是构造一个智能体,使智能体与环境进行互动,通过最大化智能体从环境中获得的累计奖赏,学习到完成目标的最优策略。相比传统拥塞控制算法,基于强化学习的拥塞控制算法适应性好,能自主从网络环境中学习新的拥塞控制策略。
文献[13]提出了一种基于强化学习的算法生成拥塞控制规则,专门针对多媒体应用优化体验质量。文献[14]使用强化学习算法来自适应地更改参数配置,从而提高了视频流的体验质量。文献[15]提出了一种自定义的拥塞控制算法Hd-TCP,应用深度强化学习从传输层角度处理高铁上网络频繁切换引起的网络体验较差的情况。文献[16]利用模型辅助的深度强化学习框架提高了虚拟网络功能的适用性。文献[17]主要针对灾难性5G毫米波网络,通过监测节点的移动性信息和信号强度,并通过预测何时断开和重新连接网络来调整TCP拥塞窗口长度。文献[18]提出了一种基于深度学习的5G移动边缘计算拥塞窗口长度。文献[19]基于深度强化学习,设计并开发了一种针对命名数据网络的拥塞控制机制DRL-CCP。TCP-Drinc[20]是基于深度强化学习的无模型智能拥塞控制算法,它从过去的网络状态和经验中获得特征值,并根据这些特征值的集合调整拥塞窗口长度。TCP-Drinc在吞吐量和RTT之间取得了平衡,比NewReno、Vegas等算法具有更稳定、平均的表现,但在吞吐量上并没有明显的改善。Rax算法[21]使用在线强化学习,根据给定的奖励函数和网络状况维持最佳的拥塞窗口长度。该算法丢包率较低,但对比Reno、PCC等算法,吞吐率提升较小。QTCP[22]基于Q-learning进行拥塞控制[23],吞吐率有进一步提升。Q-learning的核心思想是求出所有状态-动作对(s,a)的价值Q,Q代表了在当前状态s下选择a可以获得的回合内预期奖励值。如果求出了所有状态-动作对(s,a)的价值Q,则只需每次在状态s下选择能使Q最大的动作a即可实现最优拥塞控制策略。然而,Q-learning算法存在学习速度慢、收敛难的问题。由于Q-learning算法旨在求出所有状态-动作对(s,a)的无偏Q,因此需要根据Bellman方程反复迭代才能求出Q的准确值,当Q发生轻微变化时,可能导致训练过程发生反复振荡。当Q-learning算法的动作空间较大时,Q-learning极易收敛到局部最优解,而基于策略梯度的强化学习算法则解决了Q-learning算法存在的学习速度慢、收敛难等缺陷,策略梯度算法的思想是直接优化策略函数,通过梯度上升的方式使策略函数获得的奖励值最大。近端策略优化(PPO2)是目前最佳的策略梯度算法之一[24],已被OpenAI公司作为默认梯度策略算法。
有鉴于此,本文提出了基于PPO2算法的拥塞控制算法TCP-PPO2,该算法可以在学习过程快速收敛,实现虚拟数据空间的高效可靠数据迁移。与主流拥塞控制算法相比的结果表明,本文算法在虚拟数据空间应用环境中可行有效。
1 基于PPO2的TCP拥塞控制算法
TCP-PPO2算法框架如图1所示。强化学习需要构造环境和智能体。将虚拟数据空间网络作为环境,通过观察环境中的状态信息,构造智能体使用的策略函数,生成最优控制动作,策略函数采用人工神经网络进行拟合。智能体根据策略函数输出的动作对拥塞窗口长度进行调节,优化虚拟数据空间网络性能。在生成动作并与环境互动后,智能体会从环境中收获奖励值。智能体根据奖励值评判所选动作的优劣,并根据奖励值更新人工神经网络参数,使策略函数能够生成收获奖励值更多的动作。

图1 TCP-PPO2算法框架Fig.1 Framework of TCP-PPO2 algorithm
根据是否求出状态概率转移矩阵,可将强化学习分为无模型和基于模型两种类型。
基于模型算法从环境模型中交互得到样本,根据样本估计状态概率转移矩阵对环境进行建模。获得的样本能够多次使用,样本利用率高。根据状态概率转移矩阵能够更好地设计奖励值来引导智能体学习。但是,基于模型算法对环境的建模可能存在偏差。模型一旦确立,训练好之后,环境出现新的改变就会失效,泛化能力差。基于模型算法的典型代表是动态规划。
无模型算法直接根据从环境交互中得到的反馈信息(奖励值)求出最优控制策略,而不是求出状态概率转移矩阵。该算法泛化能力强,但是存在学习效率低、收敛慢的问题。这是因为该算法类似将环境作为一个黑盒进行反复试错求出最优控制策略,智能体缺少足够的指引。Q-learning[23]、PPO2[24]都是典型的无模型算法。
这两类算法的区别在于是否能够求出状态概率转移矩阵。对于本文要研究的虚拟数据空间网络拥塞控制,求出状态概率转移矩阵难度大、代价高,而且网络环境会不断发生变化,从而导致需要不断更新状态概率转移矩阵。因此,本文采用的是无模型算法,智能体在不了解状态概率转移矩阵的情况下求得最优拥塞控制策略。
1.1 问题形式化
将基于强化学习的TCP拥塞控制过程抽象为一个可部分观察的马尔可夫决策过程,定义为五元组{S,A,R,P,γ}。其中:S为所有环境状态的集合,st∈S表示在t时刻观察到的状态,初始状态为s0;A为可执行动作的集合,at∈A表示在t时刻所采取的动作;R为奖励值函数,定义为R(st,at)=E[Rt+1|st,at],表示在t时刻观察到状态为st、选择动作at后,在t+1时刻收到奖励Rt+1;P为转移概率矩阵;γ∈[0,1]为折扣因子,是对未来得到奖励的惩罚比例,折扣因子体现了强化学习算法的设计思想,即优先考虑能够立刻得到的奖励值,未来得到的奖励值会按一定比例进行衰减。
强化学习算法从初始状态s0开始,根据当前观察到的状态st,由策略函数π(at|st)选择动作at,根据状态转移概率P(st+1|st,at)到达新状态st+1,从环境中得到奖励rt+1。强化学习的目标是优化策略函数使奖励期望值最大,奖励值期望定义为
(1)
式中T代表结束时刻。
1.2 PPO2原理
强化学习算法需要设计策略函数π(at|st),使其能够在状态st下生成执行某个动作at的概率。人工神经网络理论上能够拟合任意函数,因此目前强化学习算法通过人工神经网络拟合策略函数π(at|st),神经网络参数记作θ。强化学习的目标是使得每次做出的动作都能取得最大奖励值,核心是如何评判所选择动作的优劣。为此,定义优势函数
(2)
式中Vφ(st)是状态st的值函数,反映了在状态st下,预期本次回合结束后能够取得的所有累计奖励值。优势函数反映了在时刻t选择动作at相对平均动作的优势。如果保存所有状态st和动作at对应的价值vt为二维表格,由于状态st取值范围庞大,会导致二维表格存储空间巨大而难以存储。因此,同样选择人工神经网络对值函数Vφ(st)进行近似表示。最终,定义强化学习的优化目标函数
(3)
式(3)函数的目标是通过更新策略函数参数θ使得每次做出动作都能获得更大的奖励值。然而,目标函数LMSE存在的问题是如果参数θ更新幅度过大,会造成梯度上升时反复振荡而无法快速收敛到最优点。为此,PPO2算法重新定义目标函数
Lclip(θ)=
(4)
式中:clip函数是截断函数,定义为
clip(r,1-ε,1+ε)=

(5)
rt(θ)为概率比函数,定义为
(6)
rt(θ)反映了参数更新的变化幅度,rt(θ)越大,则更新参数幅度越大,反之则越小。
式(3)的目标是求得值函数Vφ(st)的有偏估计,因此采用常用的最小二乘法定义目标函数,平方运算保证了目标函数非负性。式(4)中的优势函数取值为正时,代表当前动作获取的奖励值高于平均值,目标函数优化目标是让智能体尽量选择这类动作;优势函数为负时,代表当前动作获取的奖励值低于平均值,智能体应该避免选择该动作。Lclip(θ)函数通过截取rt(θ),将其限制在[1-ε,1+ε]之间,从而避免更新波动过大。Lclip(θ)函数示意如图2所示。当优势函数L>0时,如果rt(θ)大于1+ε,则将其截断,使其不会过大。同样,当L<0时,如果rt(θ)小于1-ε,也将其截断,使其不会过小。Lclip(θ)函数保证了rt(θ)不会出现剧烈波动。
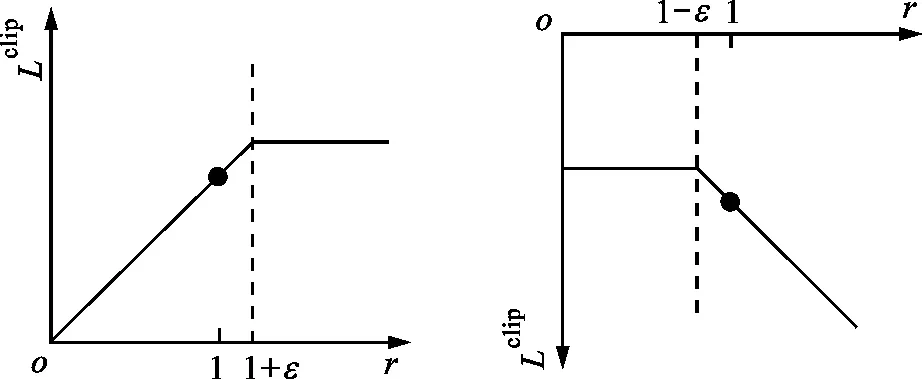
(a)L>0 (b)L<0图2 截断函数示意Fig.2 Schematic diagram of clip function
1.3 算法收敛性
PPO2在TRPO算法[24]基础上进一步改进,两者都是基于minorize-maximization算法,目标是最大化期望奖励η(θ*)。其中,η为折扣奖励函数,θ*为待寻找的最佳策略参数。在每一次迭代中,找到一个替代函数M,M为折扣期望奖励的下界,也是当前策略下对折扣期望奖励的估计。本文M为目标函数Lclip(θ),其迭代过程如图3所示。
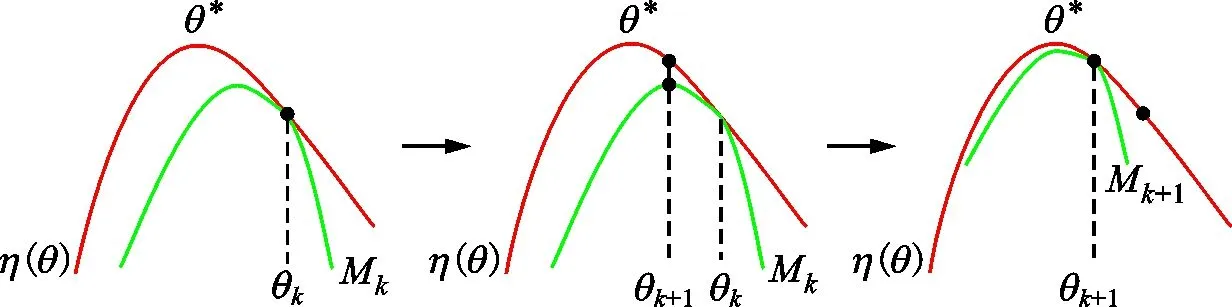
图3 PPO2迭代过程示意Fig.3 Schematic diagram of PPO2 iteration process
当前策略参数θk建立折扣奖励函数η的下界Mk。最优化Mk,找到θk+1作为下一个策略参数。用θk+1重新估计下界Mk+1,并重复这个过程。由于只有有限个可能的策略,且每一次迭代的策略都使得新策略更加接近最佳策略,PPO2最终会收敛到局部或全局最优。
为了对这一过程进行证明,定义折扣奖励函数
(7)
折扣奖励函数是强化学习算法要优化的目标函数。
定义函数
(8)
式中ρπ(s)是状态分布,公式为
ρπ(s)=P(s0=s)+γP(s1=s)+γ2P(s2=s)+…
(9)
文献[25]证明了不等式(10)成立
(10)
式中
(11)
(12)
其中DKL是两个策略之间的KL散度。
定义替代函数M为
(13)
根据式(10)定义有
η(πi+1)≥Mi(πi+1)
(14)
由于两个相同的策略KL散度为0,因此
η(πi)=Mi(πi)=Li(πi)
(15)
从而得到
η(πi+1)-η(πi)≥Mi(πi+1)-Mi(πi)
(16)
如果新的策略函数πi+1能使得Mi最优,那么有不等式Mi(πi+1)-Mi(πi)≥0成立,进而有
η(πi+1)-η(πi)≥0
(17)
因此,只要不断寻找能使Mi最优的策略就能保证强化学习目标函数η在每次迭代中不会下降,最终收敛到局部或者全局最优点,即
(18)
文献[25]指出,式(18)更新幅度过小,导致收敛慢。为增加策略更新幅度,可将优化问题转换为
(19)

(20)
新的优化问题为
(21)
对Lπθold(π)展开,并采用重要性采样进行替换,可将优化目标变化为
(22)
论述PPO2算法的文献[24]指出,为了算法更加易于实现,可将优化目标函数L变为
(23)
优化问题变为
(24)
式(24)仍然满足不等式(16),因此PPO2可以最终收敛到最优点。
1.4 状态空间设计
选取合理的状态st是实现高效强化学习算法的关键,只有观察到足够多的信息才能使强化学习算法做出正确的动作选择。然而,状态信息过多也会增加计算量,减慢学习速度。因此,本文参考了Cubic等主流TCP算法进行决策需要的状态参数,设计状态st。st包含以下参数。
(1)当前相对时间tr。定义为从TCP建立连接开始到目前已消耗的时间。在Cubic等算法中,窗口长度被设计为时间tr的3次函数。因此,tr是决定拥塞窗口的重要参数。
(2)当前拥塞窗口长度。拥塞控制算法需要根据当前拥塞窗口长度来调节窗口新值,如果当前拥塞窗口长度较小,则可以更快的速率增加窗口长度,如果窗口较大,则停止增加窗口或更缓慢地增加窗口长度。
(3)未被确认的字节数。定义为已发送但还未被接收方确认的字节数。如果把网络链路比喻做水管,则未被确认的字节数可以形象地理解为管道中储存的水量。该参数也是拥塞控制算法需要参考的重要参数,如果管道中水量充足,则应该停止或减少向管道中注水,如果管道中水量较小,则应该向管道中增加注水量,并且可以根据管道中的水量决定注水速率(拥塞窗口长度)。
(4)已收到的ACK包数量。该参数能够间接反映拥塞情况,如果收到的ACK包数量正常,则说明网络状况良好,未发生拥塞,可以适时增大拥塞窗口长度,否则说明网络发生拥塞,应该维持或减小拥塞窗口长度。
(5)RTT。时延指一个数据包从发送到接收确认包花费的总时间,可形象地理解为数据从发送端到接收端进行一次往返的时间。时延跟网络拥塞情况密切相关,如果网络拥塞严重,则时延会显著上升。因此,时延可以反映网络拥塞情况,拥塞控制算法可以根据时延对拥塞窗口进行调节。
(6)吞吐率。定义为接收方每秒确认的数据字节数。该参数直接反映了网络状况,吞吐率高说明目前链路中已发送足够的数据包,否则说明当前网络带宽剩余较多,可向链路中增加发送数据包。
(7)丢失包数量。丢失包数量越多说明当前网络拥塞严重,需要减小拥塞窗口长度,丢失包数量少说明当前网络未发生拥塞,应该增大拥塞窗口长度。
1.5 动作空间设计
at为在时刻t对拥塞窗口做出的控制动作。本文定义动作为将拥塞窗口长度c增加n个段长度s′
c=cold+ns′
(25)
式(25)设计的思路是提供一个泛化公式,根据观察到的状态参数信息,决定拥塞窗口长度增长速率。在不同的网络场景下,选择不同的策略。在高带宽环境下,调节n>1,使拥塞窗口长度以指数速度增长;在低带宽环境下,调节n=1,使拥塞窗口以线性速度增长;在网络发生拥塞时,调节n≤0,保持或减小拥塞窗口长度,减轻网络拥塞压力。
1.6 奖励函数
奖励rt定义为在时刻t从环境中收到的奖励,设计奖励函为
(26)
式中:O为当前观察到的吞吐率,Omax为历史观察到的最大吞吐率,两者的比反映了动作at能增加的吞吐率效果;l代表观察期间的平均时延,lmin代表历史中观察到的最小时延,两者的比反映了动作at改善的时延效果;α为权重因子,属于超参数,反映了吞吐率和时延对奖励的权重比例。α决定了拥塞控制算法的优化目标更侧重于吞吐率还是时延。本文选择α=0.5以平衡吞吐率和时延。此外,保存历史最小吞吐率与最大时延。当观察到当前吞吐率小于等于最小吞吐率或者大于等于最大时延时,设置获得奖励为-10,使智能体避免到达这两种极端状态。
1.7 算法描述及复杂度分析
算法的输入为网络当前状态st,输出为新的窗口长度cnew,伪代码如下。
输入:st={拥塞窗口长度,ACK包数量,时延,吞吐率,丢包率}
输出:调节后新拥塞窗口长度
1.初始化策略参数θ0=θold=θnew
2.运行策略πθk共T个时间步,收集{st,at}
3.θold←θnew
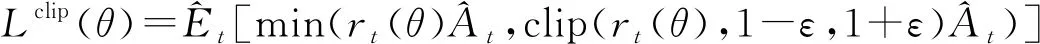
7.通过梯度上升法更新参数θ,使Lclip(θ)最大
8.c=cold+ns′
TCP-PPO2只需存储神经网络的参数,本文实验中构建了一个3层神经网络,因此空间复杂度为O(1)。TCP-PPO2在做训练和推理时需要根据输入的观察状态由模型计算得到动作值,因此时间复杂度与输入数据量成正比,即O(n)。
2 实 验
2.1 实验环境
2.1.1 软硬件环境 实验使用了一台高性能服务器,具体配置如下:①CPU,Intel(R) Xeon(R) Silver 4110 CPU @ 2.10 GHz;②内存,32 GB DDR4;③GPU,NVIDIA Titan V;④操作系统,Red Hat 4.8.5-28。
通过NS3仿真器模拟了虚拟数据空间网络拓扑结构,并实现了TCP-PPO2算法,与具有代表性的TCP拥塞控制算法Cubic、NewReno和HighSpeed进行了对比。Cubic在Linux内核2.6.19版本以后作为默认TCP拥塞控制算法;NewReno是经典的拥塞控制算法;HighSpeed是面向高速网络环境设计的拥塞控制算法。TCP-PPO2时间步长设为0.1 s,一共训练了50万步,在训练到6万步以后,获得的奖励值已趋于稳定,表明算法已经收敛。
2.1.2 网络拓扑 实验用经典的哑铃型网络拓扑结构模拟了虚拟数据空间两个超算中心中间的网络特点。网络拓扑如图4所示。图中:N1和N2代表两个超算中心之间的前端通信节点,负责进行虚拟数据空间网络数据迁移,N1为数据发送方,N2为数据接收方;N1-T1和N2-T2链路代表超算中心内部网络链路,平均网络带宽设置为1 Gb/s,时延为60 μs,丢包率为0;T1-T2代表广域网通信链路,实验中设置平均网络带宽为100 Mb/s,时延为80 ms,丢包率设为104。这些参数设置来源于虚拟数据空间广域网环境性能实测数据,尽量模拟了真实广域网特点。
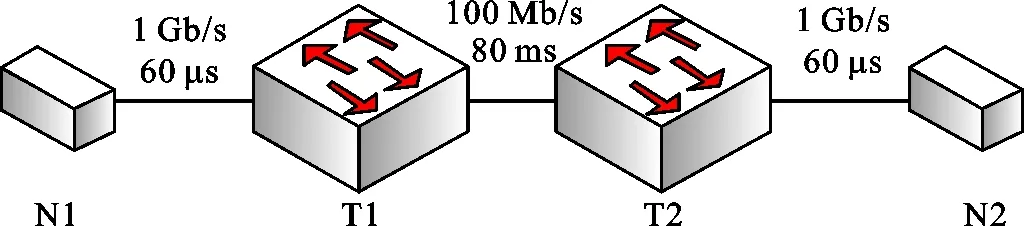
图4 网络拓扑Fig.4 Network topology
2.1.3 PPO2参数设置 PPO2的主要参数设置如下:折扣因子为0.99,学习速率为0.000 25,ε为0.2,每次更新运行的训练步数为128。
2.2 吞吐率对比
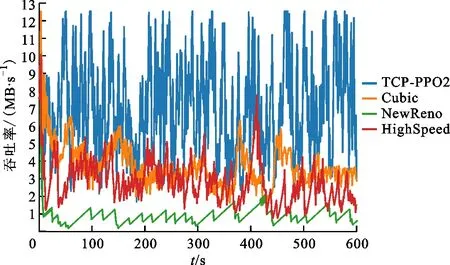
图5 吞吐率性能对比Fig.5 Comparison of throughput performance
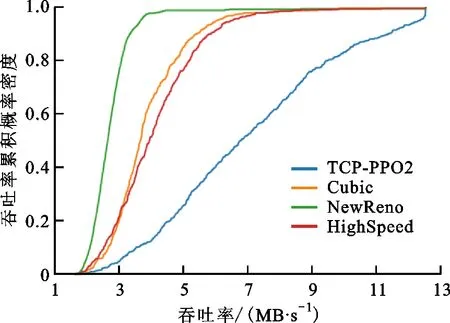
图6 吞吐率累计概率密度分布对比Fig.6 Comparison of cumulative probability density distribution of throughput rate
吞吐率为每秒确认的全部数据包数量。图5是吞吐率性能对比,可以看出,TCP-PPO2的网络吞吐率约为HighSpeed和Cubic算法的2倍,约为NewReno算法的3倍。图6是4种算法吞吐率的累计概率密度函数曲线对比,可以看出:NewReno只有约3%采样点的吞吐率大于4 MB/s,1%采样点的吞吐率大于6 MB/s;Highspeed和Cubic有30%采样点的吞吐率大于4 MB/s,约3%采样点的吞吐率大于6 MB/s;TCP-PPO2有90%采样点的吞吐率大于4 MB/s,40%采样点的吞吐率大于6 MB/s。结果表明:NewReno这类传统拥塞控制算法已无法适应虚拟数据空间的广域网特点,不适合应用于虚拟数据空间数据迁移;Cubic和Highspeed比NewReno具有显著的性能提升,但是仍未能完全有效利用可用带宽实现高速传输;TCP-PPO2具有最好的性能,在进行一定的学习后,能够充分利用网络带宽实现虚拟数据空间高效数据迁移。
2.3 网络时延对比

图7 RTT对比Fig.7 Comparison of RTT
RTT代表一个数据包从发送到接收到确认包的耗费时间,反映了当前网络延迟状况。图7是RTT对比,可以看出,总体上TCP-PPO2算法的RTT相比其他3种算法的有所上升,这是由于TCP-PPO2算法更加激进,尝试利用所有可用带宽,向链路中发送过多数据包,造成网络拥塞,导致RTT增加,但是TCP-PPO2算法的RTT相比其他3种算法的上升幅度不大。图8是RTT累计概率密度函数对比,可以看出,TCP-PPO2算法有80%的RTT小于167 ms。由于链路本身RTT最小值为160 ms,因此TCP-PPO2算法的大部分RTT相比最小值只增加了4%。
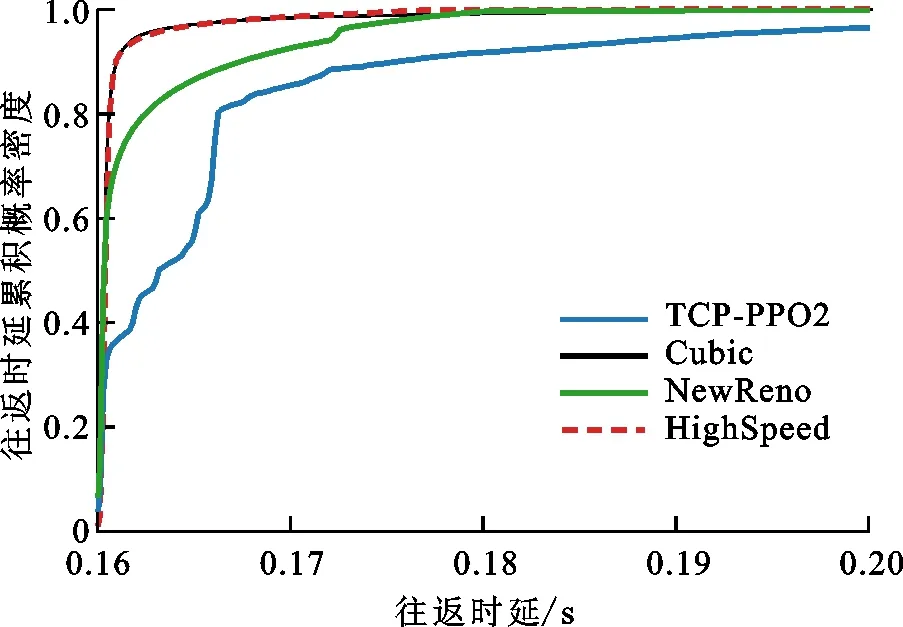
图8 RTT累计概率密度分布对比Fig.8 Comparison of RTT cumulative probability density distribution
2.4 队列长度对比
对T1上的队列长度进行了采样,结果如图9所示。可以看出,TCP-PPO2算法的队列长度显著高于其他3种算法的。这是因为TCP-PPO2算法单位时间内发送的数据包数量最多,所以在T1路由器上需要缓存的队列长度也最长。

图9 队列长度对比Fig.9 Comparison of queue length
2.5 丢包率对比
N1向N2发送数据过程中的丢包率如图10所示。可以看出:4种算法的丢包率都接近0.01%,与NS3参数设置一致;TCP-PPO2丢包率为0.124%,略高于其他3种算法的。这是因为TCP-PPO2发送的数据包最多,部分数据包由于链路节点缓存已满被丢弃,从而出现丢包现象。

图10 丢包率对比Fig.10 Comparison of packet loss rate

图11 收敛速度对比Fig.11 Comparison of convergence speed
2.6 收敛速度对比
DQN算法是Q-learning家族的最新研究成果,采用神经网络对Q表格进行了近似,已应用在Alpha Go智能围棋系统中。本文对PPO2算法和DQN的收敛速度进行了对比,结果如图11所示。可以看出,PPO2算法在训练到7万步以后,收到的奖励值已趋于稳定,表明算法已经收敛。根据1.3小节的收敛性分析,PPO2具有单调上升性,图11验证了该结论,PPO2收到的奖励值随训练步数不断上升,最终趋于稳定。DQN算法在训练到42万步以后仍然反复振荡,难以收敛。实验结果表明PPO2算法具有更快的收敛速度。
3 结 论
虚拟数据空间对于聚合国家高性能计算资源具有重要意义,高效可靠数据传输是构建虚拟数据空间的核心技术。本文针对主流TCP拥塞控制算法适应性差、无法有效利用虚拟数据空间网络带宽等问题,提出了一种基于近端策略优化算法的TCP拥塞控制算法,用于实现虚拟数据空间高效可靠数据迁移。本文得出的主要结论如下。
(1)提出了基于近端策略优化算法的TCP拥塞控制算法,将基于强化学习的TCP拥塞控制过程抽象为可部分观察的马尔可夫决策过程。通过借鉴主流算法,合理设计了状态空间、动作空间、奖励函数。
(2)通过NS3仿真实验对比得出结论,TCP-PPO2与HighSpeed、Cubic、NewReno算法相比吞吐率可达2~3倍以上。
未来将在真实虚拟数据空间系统中测试TCP-PPO2算法的性能,并针对测试性能结果,进一步提出优化算法,更好地服务国家高性能计算环境。
猜你喜欢
控制与信息技术(2021年2期)2021-07-23
小学生学习指导(低年级)(2020年10期)2020-11-26
小学生作文(低年级适用)(2019年5期)2019-07-26
中国测试(2018年9期)2018-05-14
读友·少年文学(清雅版)(2018年12期)2018-04-04
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
科技视界(2016年2期)2016-03-30
电子产品世界(2016年3期)2016-03-29
西南学林(2013年2期)2013-11-12
