
Pathological tissue segmentation by using deep neural networks
2021-05-10 03:47:40BoPangJianyongWangWeiZhangZhangYi
TMR Modern Herbal Medicine 2021年2期
Bo Pang, Jianyong Wang, Wei Zhang, Zhang Yi,
1 Machine Intelligence Laboratory, College of Computer Science, Sichuan University, Chengdu, PR China.
Abstract Objective: The process of manually recognize the lesion tissue in pathological images is a key, laborious and subjective step in tumor diagnosis.An automatic segmentation method is proposed to segment lesion tissue in pathological images.Methods: We present a region of interest (ROI) method to generate a new pre-training dataset for training initial weights on DNNs to solve the overfitting problem.To improve the segmentation performance, a multiscale and multi-resolution ensemble strategy is proposed.Our methods are validated on a public segmentation dataset of colonoscopy images.Results: By using the ROI pre-training method, the Dice score of DeepLabV3 and ResUNet increases from 0.607 to 0.739 and from 0.572 to 0.741, respectively.The ensemble method is used in the testing phase, the Dice score of DeepLabV3 and ResUNet increased to 0.760 and 0.786.Conclusion: The ROI pre-training method and ensemble strategy can be applied to DeepLabV3 and ResUNet to improve the segmentation performance of colonoscopy images.
Keywords:Pathological images segmentation, Deep neural networks, Pre-training method, Ensemble method.
Background
Colorectal cancer is one of the leading causes of cancer-related death in the world [1].And Pathology is the gold standard for many medical programs, especially in cancer diagnosis [2].Therefore, the pathological image diagnosis of the colonoscopy examination has great significance [3].However, it is still a time-consuming and laborious task for pathologists to analyze pathological images.Because the maximum size of pathological images can reach 100,000 × 100,000 pixels and doctors need to examine images pixel by pixel.It is a good solution to relieve the pressure of doctors to develop the computer-aided diagnosis algorithm to automatically segment the lesion tissue in pathological images.
There has been a lot of work on pathological image segmentation.Early methods are mainly based on feature design technique, such as morphological features [4], fractal features [5], texture features [6], and object-like features [7].In recent years, due to the great success of deep neural networks (DNNs) in the field of computer vision [8,9], there are some attempts to use DNNs for pathological image segmentation.Different from the traditional hand-crafted feature extraction method, the convolutional neural network (CNN) can extract features from different datasets with the powerful abstraction ability.From the pathological image segmentation task [10,11,12], it can be seen that the DNNs based method has better performance than the traditional segmentation method.As we far know, the method [13] is proposed to improve the classification performance by using a novel graph based convolutionαl neural network for the WSL-level prediction.In our work, whole slide images are used for pixel-level segmentation.In the field of image segmentation, fully convolution neural networks (FCNs) [14] is an important job.The DeepLabV3, ResUNet, and so on are all based on the FCNs.
But all kinds of DNNs need a lot of labeled data.To solve the limitation of data quantity, transfer learning based on learning reuse has been widely used.It has been proved that transfer learning can significantly improve the network performance in the training phase of DNNs.The most common application of transfer learning is the pre-trained weights of the ImageNet dataset.Although it has more than 14 million images and 20,000 classes, the ImageNet dataset does not contain any pathological images.It is uncertain that ImageNet pre-training parameters can be applied to pathological image segmentation tasks as effectively as real image segmentation tasks.In view of this, a new pre-training method is proposed.
Because of the large size of the pathological image, the pathological image can’t be directly used as the input of the model.Images with high resolution will lead to the difficulty of model training.For highresolution image segmentation tasks, the common method is to cut the whole image into different small regions before segmentation, such as the sliding window method.Some work has studied the application of CNN in pathological image patches [15,16,17,18].However, as shown in Figure 1, the sliding window method often splits the whole lesion tissue, resulting in the loss of the lesion tissue information.To solve this problem, the overlap-tile strategy is proposed in [19] to enlarge the tissue region for better performance in the training phase.We also propose an ensemble strategy in the testing phase to retain more boundary information.

Figure 1.Pathological Image with the mask.T
Because of these two problems in the application of DNNs in the pathological image segmentation task, we propose two methods to improve the segmentation performance:
1) We propose a new pre-training method for pathological image segmentation.A new pretraining dataset is generated by using the label of the pathological image.DNNs are pre-trained on the pre-training dataset to solve the overfitting problem.Finally, the new pre-trained weights are used to fine-tuning the model.
2) We propose a multi-scale and multi-size ensemble method in the test phase to solve the problem that tissue information loss caused by image cropped operation in the pathological image segmentation task.The resized images and the different size images cropped from the original images are feed into the same model, and the prediction results with different precision are obtained.All results are ensembled to get the final output.
Methods
In this part, we describe the pathological image segmentation method.As shown in Figure 2, the proposed method consists of two parts.Firstly, the region of interest (ROI) pre-training method is proposed to generate a new pre-training dataset and get new pre-trained weights.Secondly, the fine-tuning method on the segmentation model by using pre-trained weights is described.Besides, the multi-scale and multi-resolution ensemble method used in the testing phase is proposed.
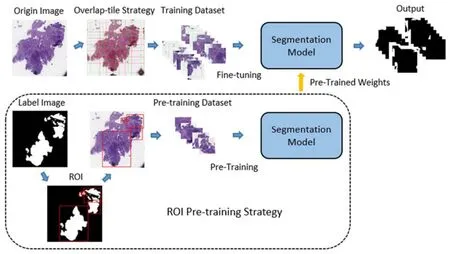
Figure 2.Pathological Tissue Segmentation.
Pre-training method
When the pathological segmentation model is trained with the ImageNet pre-trained weights, one problem is that the ImageNet dataset doesn't have any medical image.The effectiveness of transfer learning is questionable between data sets with large image differences.To solve this problem, the pre-training method based on ROI is proposed.The new pretraining dataset is generated from the label images.Suppose the label image size isw,ℎ.The first step is to binarize the label images by threshold T .The calculation is:

where threshold T is defined as a selected constant.After the binary operation, the label images’ pixel value is 0 or 1.
The second step is to mark different lesion regions in the binary image.The connected domain algorithm is used to generate irregular regions set which are expressed as.The two pixels are marked in the same connected domain when they are adjacent and they have the same pixel value (0 or 1.The minimum circumscribed rectangle set of every connected domain is expressed as.Although each connected domain is separate, the minimum circumscribed rectangle of every connected domain is cross, which causes a lot of repetitive regions.
The third step is to reduce the number of minimum circumscribed rectangle by using the intersection over union (IOU) strategy.If half of rectangleoverlaps the region, rectangleis deleted and rectangleenlarges to include the rectangle.The third operation generates a new region set which is expressed asAccording to these regions of label images, the same parts of the original image are cropped and added to the new pre-training dataset which is expressed as.The dataset consists of the training set of the original dataset.The dataset is divided into a training set and a validation set according to the ratio of 4:1.All images are resized to 5125123 .The DeepLabV3 and ResUNet are pre-trained on the.The pre-training process of each model is carried out independently and finished when up to 100 epochs, where the batch size is set to 8.Stochastic gradient descent (SGD) optimizer is set as the learning rate starts from 0.001, with a weight decay ofand a momentum of 0.9.
Fine-tuning method
In the training phase, the original pathological images need to be cropped, to avoid the difficulty caused by high resolution.To preserve more tissue information, the overlap-tile strategy is used instead of the sliding window method to crop the image.The researchers demonstrated that the region around the target provides useful background information for the segmentation task.The overlap-tile strategy generates a set of fixed size images from the original image and keeps the boundary fine by the mirror flipping the boundary area.
Suppose the size of the original image isw, ℎ.Because the size of the original image is not consistent.To facilitate the next step of the calculation, the size of the original image is adjusted towhere the k is defined as the kernel size and the number of images generated by clipping operation is nm.The core slides over the original image by sliding window method.The boundary region is a mirror image of the area with the width p of the kernel.The crop operation generates images composed of the core and the boundary region.Then the whole image’s size after the mirroring operation is:
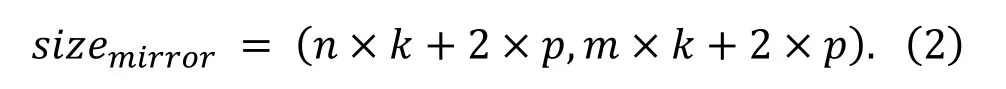
The size of the images generated by the overlap-tile strategy is size.The computation of the image size is:
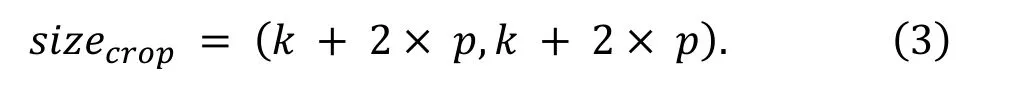
The cropped operation generates a new dataset which is expressed as.The new dataset is feed into the segmentation model to forecast the positive region.
The DeepLabV3 and ResUNet are fine-tuned based on the ROI pre-trained weights on the new dataset.The training phase of each model is carried out independently and finished when up to 200 epochs, where the batch size is set to 16.Stochastic gradient descent (SGD) optimizer is set as the learning rate starts from 0.001, with a weight decay ofand a momentum of 0.9.The input of the model is cropped from the original data.The complete algorithm needs to combine the output of the neural network to generate the prediction image with the original image size.The output set of the network is expressed as.And the kernel set which is cropped from output images is expressed as.The calculation formula of the final output is:
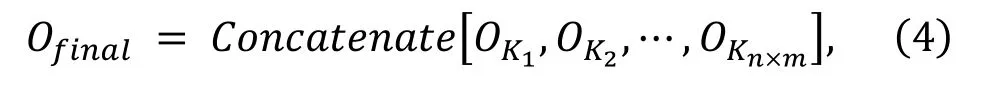
Multi-scal e and multi-resolution model ensemble
To avoid the loss of lesion tissue information, a multiscale and multi-resolution model ensemble strategy is adopted.
In the multi-scale ensemble method, the 5125123 images generated by overlap-tile strategy are resized to 384384 and 640640.The strategy provides multi-scale information and help improve performance.In the multi-resolution ensemble method, the images’ sizes generated by overlap-tile strategy are different, such as 512512, 768768, and 832832.When the receptive fields in the image domain are consistent, the input block with low resolution enlarges the receptive field, providing more background information for the network, while the patch with high resolution retains better boundary details.The ensemble method is accomplished by averaging these predictions.The combination of the two methods improves the precision of the model.
Results
Experimental setup
Experiments are implemented by using Pytorch framework which is an open-source library to develop and train deep learning models.All models are trained on a server with Linux OS and hardware of 64GB of RAM, 2 Intel Xeon CPUs, and 4 Nvidia P100 GPUs.The dataset comes from the Digestive-System Pathological Detection and Segmentation Challenge (https://digestpath2019.grand-challenge.org), which is part of the MICCAI 2019 Grand Pathology Challenge.The dataset is divided into three parts: training set, verification set, and test set.The ROI pre-training dataset comes from the training set of the original dataset.The cropped images are divided by 255 to ensure that each pixel value is between 0 and 1.After clipping operation, the number of the three datasets are shown in Table 1.
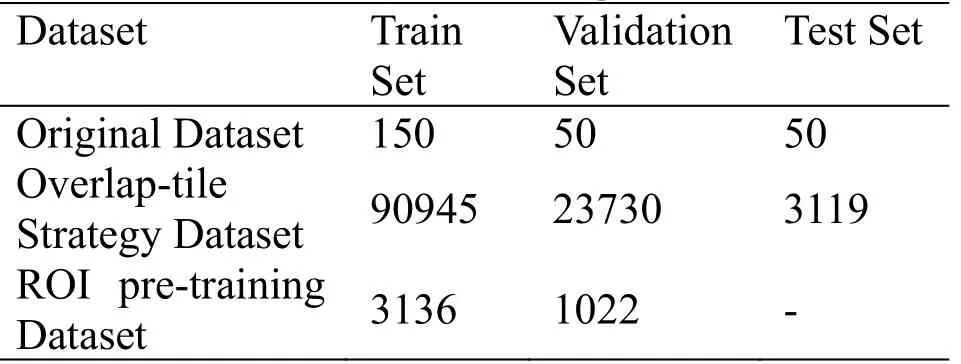
Table 1.The number of images in datasets.
Experimental results
The results of experiments are introduced.The first experiment verifies the effectiveness of the ROI pretraining method.The second experiment verifies the performance of the multi-scale and multi-resolution model ensemble method.
Pre-training method
This part introduces the experimental results of the ROI pre-training method.To suppress the interference, this experiment uses only the training dataset generated by the overlap-tile strategy for training and uses the verification set to verify the model effect.The effectiveness of the strategy is verified on DeepLabV3 and ResUNet.Both DeepLabV3 and ResUNet use Resnet50 as the basic feature to extract subnet.The Dice metric is used to evaluate the effect of the method.The Dice metric measures area overlap between segmentation results and annotations.The mean value and standard deviation value of dice are mainly investigated.The calculation formula of Dice metric is:

where A is the sets of foreground pixels in the annotation and B is the corresponding sets of foreground pixels in the segmentation result, respectively.
In the first step, the two models are pre-trained on the ROI pre-training dataset.Due to the diversity of image scales in the pre-training dataset, all images are adjusted to 5125123.The experimental results are shown in Table 2.
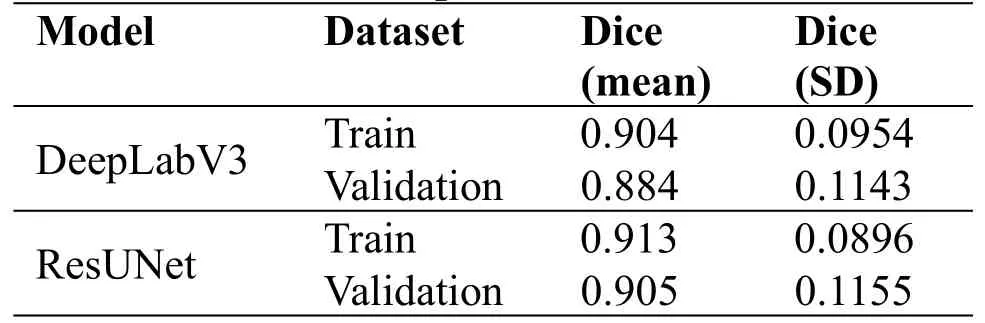
Table 2.Experimental results of the pre-training phase.
Because the new pre-training dataset greatly reduces the proportion of negative samples, the model can avoid overfitting.In terms of dice value, DeepLabV3 and ResUNet can reach 88% and 90% on the validation dataset.The pre-trained weights generated by this step are used in the next experimental process.
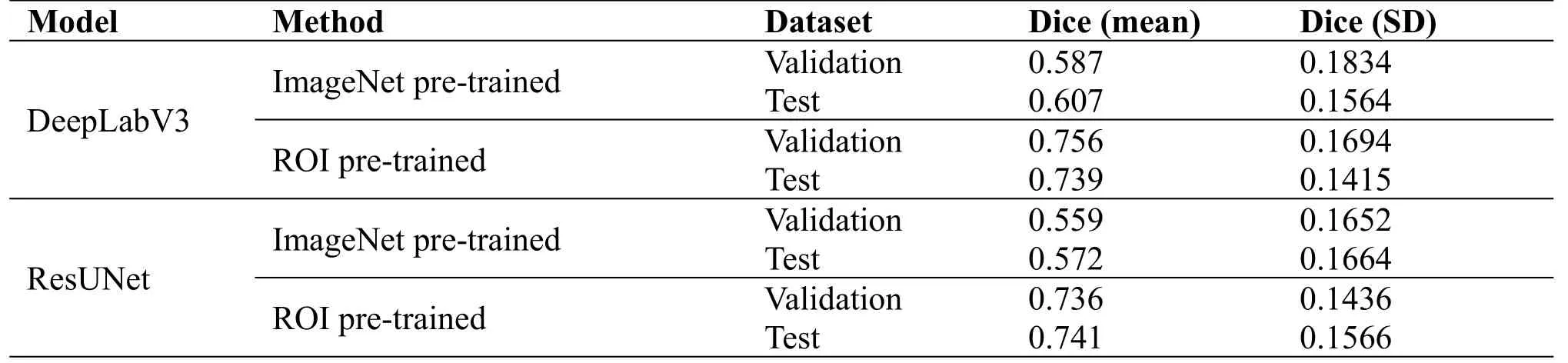
Table 3.Experimental results of training with ROI pre-training weights.
The DeepLabV3 and the ResUNet are trained on the overlap-tile cropped Dataset.The training results of the DeepLabV3 and the ResUNet with the ROI pre-trained weights are shown in Table 3.Although pre-trained weights on the ImageNet dataset are widely used in almost all segmentation tasks, the experimental results show that compared with the new pre-training method, the adaptability of ImageNet pre-training parameters in the pathological segmentation task is not strong enough.The results show that the ROI pre-training method is effective and feasible.
Multi-scale and multi-resolution model ensemble
This experiment verifies the effectiveness of the multiscale and multi-resolution model ensemble strategy in the testing phase.As shown in Table 4, the images of different scales cannot get better performance than the original scale under the same model.But the multiscale model ensemble method can obtain the information of different scale images and get better performance.

Table 4.Experimental results of using the multiscale model ensemble method.
The effectiveness of the multi-resolution image model ensemble method in the test phase is verified.As shown in Table 5, the images with a large size can get a higher dice value.The multi-resolution model ensemble method can obtain more information from different size images and get better performance.
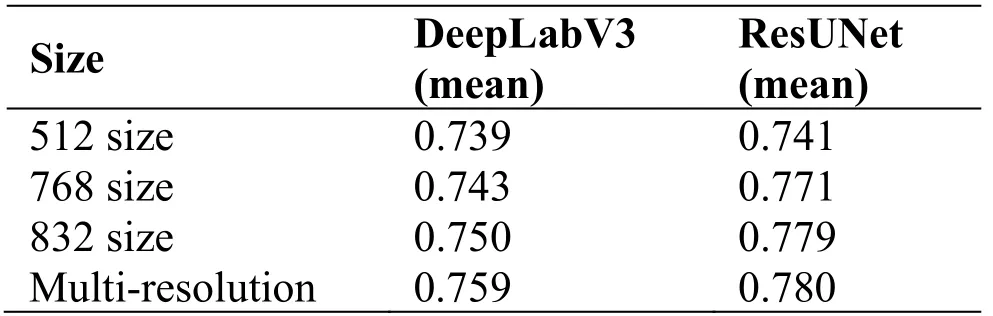
Table 5.Experimental results of using the multiresolution model ensemble method.
From the previous multi-scale and multi-resolution experiments, we can assume that the prediction of the model needs more information about the lesion tissue.Both multi-scale and multi-resolution provide additional information prediction to some extent.As shown in Table 6, the ensemble strategy is adopted and better results can be obtained on the test set.The experiment has been repeated based on ResUnet.In the repeated experiments, the Dice score is improved 4.7% and 4.4%.The effect of the ensemble strategy has been confirmed.

Table 6.Experimental results of using ensemble strategy.
Discussion
The automatic segmentation algorithm of colonoscopy tissue is an ideal method for pathology diagnosis.Experiments show that DNNs can be applied to the colonoscopy tissue segmentation with high performance.In many computer vision researches, they used the paradigm of "pre-training and fine-tuning".For example, DNNs can apply the image features learned before training (such as ImageNet) to the target task through the weights [20].This pre-training mode is also suitable for pathological image segmentation [11,15,18].However, the ImageNet dataset does not contain any medical image, and the effect of the ImageNet pre-trained weights in the medical image task is questionable.In the field of medical image, there are also some researches on the selection of pre-trained weights [21][21].Our work that obtains the ROI pretraining dataset from the original data is different from these jobs.In [21], they are still limited to the ImageNet dataset, only introducing new features through the gray change of the images.In [21], although their pretraining data is obtained from the medical data, a series of classifier models are trained on the dataset.Our method uses the medical dataset itself to get the pretrained weights which can better describe the characteristics of medical images.Then the segmentation accuracy can be improved through the normal segmentation model training phase.At the same time, the multi-scale and multi-resolution ensemble strategy provides more context information to the model and further improves the segmentation accuracy.
Although the ROI pre-training method has been verified in DeepLabV3 and ResUNet, it still needs to be tested on more models and datasets.And we need to test whether the pre-trained weights from one medical dataset still have good performance in another medical pathological segmentation task.Besides, we can try to use post-processing steps to improve the experimental results.
Conclusion
We propose a new method for colonoscopy tissue segmentation.Our method uses the training label images to obtain new pre-trained weights to accurately segment the lesion tissue from the pathological images.We also provide more information to model by using a multi-scale and multi-resolution ensemble strategy in the testing phase.By comparing the experimental results, the superiority of our method is proved.Future studies include evaluating our method in more pathological images segmentation task and promoting its application in clinical practice.
 TMR Modern Herbal Medicine2021年2期
TMR Modern Herbal Medicine2021年2期
- TMR Modern Herbal Medicine的其它文章
- Application of artificial intelligence in tongue diagnosis of traditional Chinese medicine: A review
- A brief overview of traditional Chinese medicine prescription powered by artificial intelligence
- JSON-ASR: A lightweight data storage and exchange format for automatic systematic reviews of TCM
- Artificial intelligence for the development and implementation guidelines for traditional Chinese medicine and integrated traditional Chinese and western medicine
- Auricular vagus nerve acupressure for patients with emotional distress under the COVID-19 pandemic: A smartphone-based, randomized controlled trial