
自适应多视角子空间聚类
2021-05-10 12:48唐启凡张玉龙何士豪周志豪
西安交通大学学报 2021年5期
唐启凡,张玉龙,何士豪,周志豪
(西安交通大学软件学院,710049,西安)
近年来,随着计算机性能的大幅度提升和互联网通信速度与用户的大规模增长,海量的数据被提取出来。人们希望从这些海量的数据中找出有意义的结构信息,其中以多视角数据最为突出。举例说明多视角数据:①新闻既有视频形式也有音频形式;②网页既可以被URL地址所表示也可以被其中内容所表示;③雕像可以从不同侧面表示;④同一种语义有多种语言的表达方式。聚类算法作为一种行之有效的手段受到了研究人员广泛的关注,聚类的目的是将具有潜在相似结构的数据归为一类,从而为后续其他针对于数据的处理做准备。传统的单视角聚类算法在对待多视角数据时,会将每一个视角上的特征简单地连接在同一个矩阵中,并在该特征矩阵上直接运行聚类算法,例如k-means、谱聚类等算法。但是,这样做有极大的缺点和限制:对于样本数较小的数据,如果将所有视角的特征简单连接起来会造成维度灾难,而且在连接时没有考虑不同视角数据之间的互补性和异构性,会造成多视角数据大量信息的缺失。由此,多视角聚类算法凭借其对于多视角数据独特的处理能力、良好的鲁棒性及泛化能力得到了研究人员越来越多的关注和研究。
从21世纪开始,有许多科研人员在多视角聚类领域内取得了不错的成果。为了挖掘数据的潜在结构,Elhamifar等提出稀疏子空间聚类算法,该聚类算法的主要思想是高维数据通常能被低维的子空间数据所表示,可由公式X=DC来表示,其中矩阵D为字典矩阵,矩阵C为权重矩阵[1]。通过对权重矩阵添加稀疏性约束,从而发掘出数据矩阵的低维表示。对学习出的权重矩阵应用传统的聚类算法,便可得到最终的结果。在Elhamifar等[1]的基础上,Liu等提出了对权重矩阵添加低秩性约束,并在损失中加入噪声矩阵E,从而在挖掘出数据隐藏结构的同时去除数据矩阵中夹杂的噪声点、离群点以及损坏点[2]。通过对噪声矩阵约束不同的范数,从而达到对不同噪点的良好处理效果。在Elhamifar等[1]和Liu等[2]的研究中可以发现,现实中为了简化问题的处理,通常所使用的字典矩阵D都是原始数据矩阵X,这一做法的原理是数据的自表达性质,即类内数据点可以被类中其他所有数据点线性表示。Ji等在传统深度学习网络Auto-Encoder的基础之上,通过利用数据的自表达性质,设计了神经网络的一个卷积层,使其夹在编码网络层和解码网络层中间[3],开创了多视角聚类深度学习的先河。
这些算法取得了瞩目的成绩,但绝大多数受制于参数选择。为了选择更好的参数,这些算法都会利用归一化互信息评价指标来评价算法的性能,这又要求数据必须包含标签。但是,现实中的数据由于数据量过大,绝大多数情况下都很难对数据做出标注,例如道路视频监控数据、互联网舆情文本数据等。为此,许多免除参数选择的算法被提出[4-8]。这些算法利用计算得到的权重矩阵、相似度矩阵、指示矩阵来直接计算参数,在算法运行过程中不断更新参数,从而免除了人工选择参数。但是,这类算法依然存在缺陷,例如:在Peng等提出的算法中,由于数据表示矩阵Z和相似度矩阵S仅考虑了单个视角内的相关性,缺失了对于表示矩阵和相似度矩阵在多视角范围内的相关性约束,造成了算法在特定多视角数据集上的性能失效[8];在Nie等提出的算法中,使用RatioCut切图算法,通过指示矩阵迭代更新各个聚类的权重,该切图算法使聚类之间相似性最小,但在考虑类内相似度时,仅将最大化类内数据点数作为目标,缺乏对于类内数据点之间相似度的深入挖掘,导致在大规模数据集上应用效果欠佳[4]。
为此,本文提出自适应多视角子空间聚类算法ASC,基于不同视角数据点对之间的相似度近似的原理,在多视角范围内约束表示矩阵和相似度矩阵间的相关性,构建了全新的损失函数,并使用块坐标下降法来优化,从而彻底解决了这类算法在部分数据集中失效的问题,提高了算法的性能。
1 相关工作
近几十年来,聚类算法的研究大致可以分为单视角聚类和多视角聚类两大类。本节挑选了其中最具代表性的算法进行简单总结,基本上概括了聚类算法的发展历程。
1.1 单视角聚类
在早期数据结构不复杂且数据量不庞大的背景下,聚类算法研究的普遍共识是同一类别的数据会围绕在一些标志性点的附近。所以,只要找出几个标志性的数据点,并根据其他数据点与标志点的相似度,便可以得到数据的分类情况。最具代表性的以这种思想为核心的算法为k-means算法。该算法首先根据聚类数来随机初始化标志性点,再将数据点分配到离它们最近的标志性点,最后根据每个聚类的重心更新标志点,循环往复直到标志点不再变化。与k-means不同,研究者基于概率密度函数和高斯混合模型,提出了最大期望算法。该算法将每一个类别都看作一个单高斯分布模型,在E步用高斯概率密度函数计算每个数据点所属的类别,在M步计算每个聚类的联合概率分布,优化聚类参数。这两种算法都是在原始数据矩阵上直接应用聚类算法,算法性能往往会受限于原始数据结构,而谱聚类算法首先对原始数据矩阵进行处理,挖掘出数据矩阵潜藏的结构,处理完成后再使用k-means等基础算法聚类。相比于k-means算法,谱聚类算法性能提高显著,尤其对于处理稀疏矩阵效果良好。
k-means、最大期望、谱聚类这3种算法假定所有数据点都处于同一维空间,对于高维数据,性能往往下降严重。为此,研究者提出了子空间聚类算法,将数据矩阵视为由多个维度子空间构成的公共空间,处于同一子空间中的数据点划分为一类。空间聚类算法中最具代表性的算法为Elhamifar等提出的稀疏子空间聚类[1]以及Liu等提出的低秩子空间聚类[2],这两种子空间聚类算法分别对学习出的系数矩阵约束L1范数和核范数的正则化项,最终所学习出的系数矩阵具有良好的块对角性质。文献[9]采用L2范数作为正则化项,同样取得了不错的成果。在Elhamifar等[1]和Liu等[2]的基础上,Wang等将低秩和稀疏的性质结合起来,使得学习出的系数矩阵同时具有稀疏与低秩两种特性[10],从而提升了算法性能。
单视角聚类算法虽取得了长足发展,但随着其他各学科的发展,数据视角数越来越多,数据量也越来越大。因此,对聚类算法的要求也逐步提高,聚类结果既要保持多视角数据的一致性,也要挖掘出多视角数据的互补性。此外,单视角聚类算法还要面对包含大量噪声的数据,已逐步无法满足性能要求。
1.2 多视角聚类
与单视角聚类算法相比,多视角聚类算法通常可以挖掘出多视角数据中的隐藏信息与结构,并可以利用这些信息与结构显著地提升算法性能。多视角聚类算法通常分为基于图的多视角聚类、基于矩阵投影的多视角聚类以及多视角子空间聚类3类。
基于图的多视角聚类算法将数据点看作图中的结点,图中边上的数据为结点之间的相似度,常用的相似度度量算法有高斯核函数、knn算法等。构建好图之后再采用切分图的算法将图分为几类,最后应用单视角聚类算法即可[11-13]。Kumar等将协同正则化算法与基于图的多视角聚类算法相结合,将成对视角的数据矩阵投影到嵌入空间中,使它们在该空间中的相关性达到最大[14],但仅限于成对的视角,算法的性能随着视角数的提升而下降。基于矩阵投影的算法是将不同视角的数据投影到公共低维特征空间中,再进一步优化它们之间的相关性,最典型的算法为Chaudhuri等提出的算法,他们通过结合CCA算法来达到这一目的[15]。多视角子空间聚类算法与单视角子空间聚类算法本质相同,但加入了更多的正则化项来挖掘多视角数据潜在的互补信息与数据结构。Cao等引入了希尔伯特施密特准则来衡量视角之间的多样性,从而挖掘出更多的互补性信息[16]。Zhang等在子空间聚类的基础上引入了张量,基于张量对矩阵进行分解,并加入矩阵低秩约束,得到了较好的效果[17]。本文算法归属于多视角子空间聚类算法,在子空间聚类基本原理的基础上加入了多个行之有效的正则化项,同时根据数据结构寻找自适应超参数,既保持了多视角数据的一致性,也挖掘出了多视角数据之间的互补信息。
2 自适应多视角子空间聚类
2.1 损失函数
设矩阵X1,…,Xi,…,Xv表示输入的多视角数据矩阵,Xi∈Rn×d,符号v、n、d分别表示视角数、样本数和特征数。数据矩阵Xi既可以来自于人工数据集,也可以来自于真实数据集,例如,图像数据、文字媒体数据等。
本文提出的损失函数为
(1)
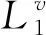
(2)

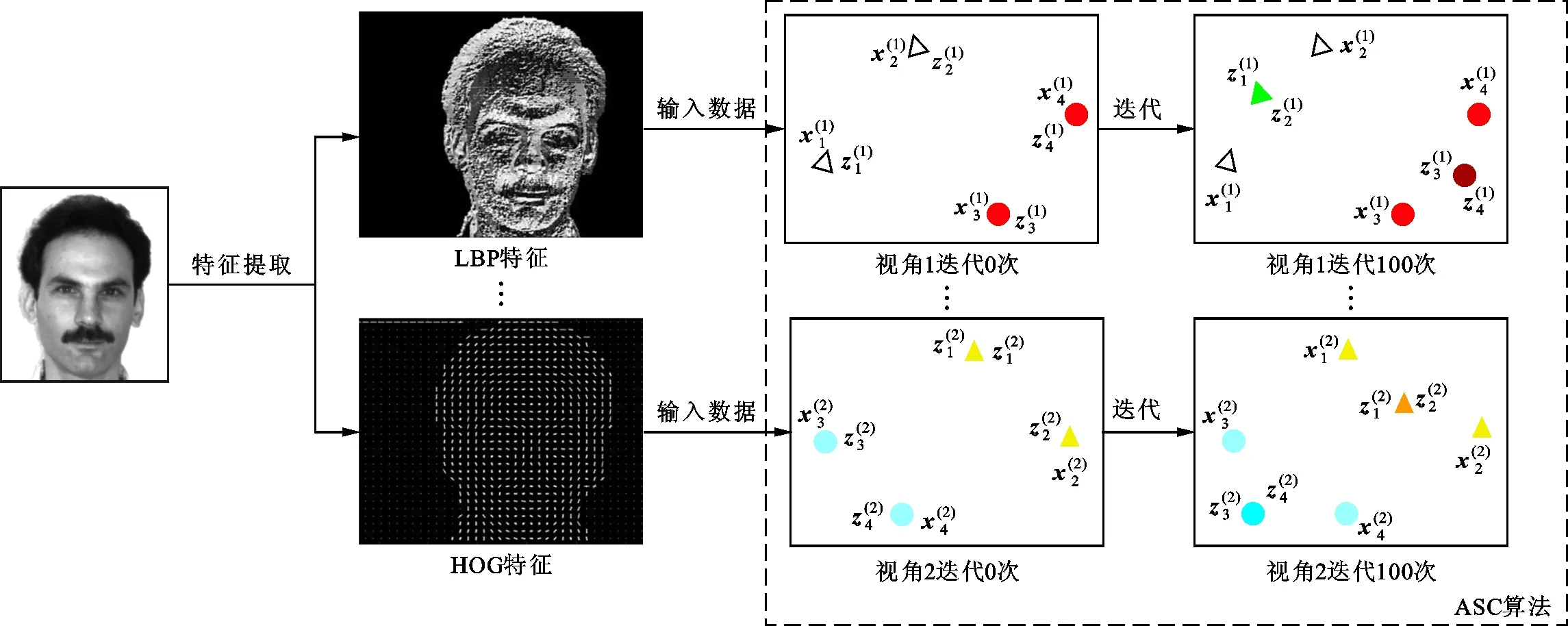
图1 ASC算法基本原理Fig.1 Basic principle of ASC algorithm
为了挖掘数据矩阵X的潜在结构,本文重构矩阵X为新的表示矩阵Z,因此矩阵X与Z之间具有天然的相关性,本文在式(2)中的第一项对数据点xi与zi之间的欧几里得距离进行约束。针对式(2)第2项,本文采用文献[2,18-19]的思想,在迭代的过程中,属于同一类别数据点的表示点zi会逐渐靠近,并最终坍缩为少数几个标志性点。ASC算法基本原理如图1所示。首先,对原始图片分别提取局部二值模式(LBP)、方向梯度直方图(HOG)等多种特征,代表多个视角的数据。在得到视角数据后,将其输入到ASC算法当中。这里对数据做了简化处理,图1中仅假设包含三角和圆两种类别。迭代一开始,表示矩阵Z与原始数据矩阵X一致,当算法迭代100次后,相同类别的表示数据点zi会逐渐靠近。同时,处于不同视角相同类别的数据点,它们之间的表示点zi也在逐渐靠近,反之逐渐变远,即不同视角中相同数据点对之间的相关性应该相同。
为了实现这一过程,本文在式(2)第二项针对一对表示点zi与zj的欧几里得距离添加惩罚函数δ(·)。理想状态下,δ(·)应为l0范数,但由于l0范数是非凸的,造成问题无解,因此通常都松弛到l1范数。然而,来自于真实数据集的矩阵会包含大量的噪点,通过这种数据矩阵计算出的最近邻数据点集合ε会包含虚假的数据点,也就是并无相关性的点对。l1范数是数据绝对值的和,在优化的过程中,噪点并不会随着迭代而被排除,从而造成算法性能的下降。所以,本文中选择使用l2范数来进行约束,式(2)转换为
(3)

(4)
(5)
(6)
式中
(7)


(8)
2.2 优化
当Zv固定时,去掉式(8)中的无关项,并求导为0,可得
(9)
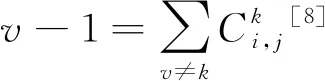
(10)

(11)
将式(11)改写为X=ZM,可以看出,式(11)的解法与线性最小二乘法问题解法相同。将式(11)中的一部分提取出来设为Θ
(12)
易得Θ为拉普拉斯矩阵,根据拉普拉斯矩阵性质,可得到M为对称半正定矩阵,因此在Xv已知的情况下,便可根据式(11)对Zv进行求解。
2.3 自适应参数选择
(13)
通过施加数据矩阵X与Θ之间最大奇异值的比例系数,达到前后两项之间的平衡。每一次迭代都仅改变Θ,数据矩阵X不变,因此本文只需在预训练中计算好‖X‖2即可。对于参数μ,本文初始化μ为θ2,其中θ为矩阵W中最大边的长度。ASC算法伪代码如下。
输入:具有v个视角的数据矩阵X1,…,Xi,…,Xv
1 预训练权重矩阵W以及‖X‖2
2 初始化连接矩阵C为单位矩阵,表示矩阵Z为数据矩阵X,根据2.3节对参数λ和μ进行计算
3 repeat
5 利用式(11)更新Zv
6 根据式(13)更新λ
7 until满足收敛条件或达到最大迭代数
输出:通过在得到的连接矩阵C上应用谱聚类算法,得到最终聚类分配结果
3 实 验
3.1 数据集
为了验证算法的鲁棒性及有效性,本文实验所采用的7种数据及均来自于现实世界,并对个别数据集做了相应的调整。
MSRCV1[21]包含8种类别的240张图片。本文挑选了7种类别,分别为树、建筑、飞机、牛、人脸、汽车和自行车。同时,对这些图片采用6种特征进行描述,即有CENT、CMT、GIST、HOG、LBP、SIFT共6个视角。
BBCSport[22]包含从BBC Sport网站中收集的来自5个顶尖领域的544篇体育新闻,由两种视角构成。
ORL[23]包含40种不同的对象,每种对象包含10张不同的特征图像,有Intensity、BP、Gabor共3种类型的特征被选取。
Caltech101[24]包含从20种类别中挑选出的2 386张图片,每张图片由Gabor、WM、CENT、HOG、GIST、LBP共6种不同的特征构成。
LandUse-21[25]包含21种类别的100张河流领域卫星图片,有GIST、PHOG、LBP共3种特征。
Movies617[26]包含从IMDb网站收集的17种类别共617场电影数据。由两种视角构成,这两种视角分别为1 878个关键字及1 398个演员,每个关键字至少用于2部电影,一个演员至少出演3部电影。
Scene-15[27]包含4 485张室内和室外场景图片。图片的特征与Caltech101数据集一致。
3.2 评价指标
本文采用归一化互信息指标(N)、聚类性能评估指标(V)、预测精确度指标(A)从聚类划分的准确度、聚类性能以及预测精度3个方面对算法进行评价,这3种评价指标都是值越大越好。N的计算公式为
(14)
式中:I为互信息;H为熵。V的计算公式为
(15)

(16)
式中ncorrect表示聚类划分结果中符合预期的样本数。
3.3 实验设置
对比算法均来自本领域非常经典且具有代表性的算法,其中单视角聚类算法2种,多视角聚类算法5种,自适应多视角聚类算法1种。对于单视角聚类算法,取它们在多个视角中表现最好的那个视角,给k-means算法设置对应的聚类数,LRR算法的超参数根据Liu等[2]的设置,在[3,5]内使用最小二乘法逼近10次,取最好的结果。对于有参数的多视角聚类算法,首先根据它们各自对应文献中推荐的超参数进行取值,再根据经验对超参数逼近10次,取结果最好的那个参数。对于自适应的多视角聚类方法COMIC,使用文献[8]中推荐的超参数。
3.4 实验结果
每种算法在每个数据集上均运行30次,指标采用“平均值±标准差”的格式进行展示。综合排名是本文算法与其他算法在同一数据集上相同评价指标下的排序,1表示效果最好。实验结果如表1~7所示,其中ASC为本文算法。
由表1~7可知:相比于无参数多视角聚类算法COMIC,本文算法在数据集BBCSport、ORL、Movies617数据集中不会失效,在MSRCV1数据集中综合性能提升9.3%(N、V、A这3个指标提升百分比的平均值),在Caltech101数据集中综合性能提升6.8%,在LandUse-21数据集中综合性能提升55.8%,在Scene-15数据集中综合性能提升15.39%;相比有参数多视角聚类算法,本文算法在MSRCV1、Caltech 101、LandUse-21、Movies617数据集中均取得了前2名的成绩,在其他数据集中平均排名2.15。
在BBCSport、ORL和Scene-15这3个小规模数据集中,本文算法性能与手动调参聚类算法性能有差距,原因主要有两点:①在小规模数据集中,手动调参聚类算法可以在较短时间内找到准确的超参数,而在大规模数据集中,由于可选参数范围很大,即使经过较长时间的调参,也很难达到较好的性能;②在小规模数据集中,超参数需要更多轮算法迭代才能获得性能更优的值,而本文算法收敛过快,导致超参数计算不够精准。

表1 MSRCV1数据集对比实验结果

表2 BBCSport数据集对比实验结果

表3 ORL数据集对比实验结果
综合来看,本文算法在大规模数据集Caltech 101、LandUse-21以及噪声数据集Movies617表现突出,取得了首位排名的好成绩,并在全部7个数据集中相对于无参数算法性能均有提升。由此可见,本文算法性能优异。

表4 Caltech101数据集对比实验结果

表5 LandUse-21数据集对比实验结果
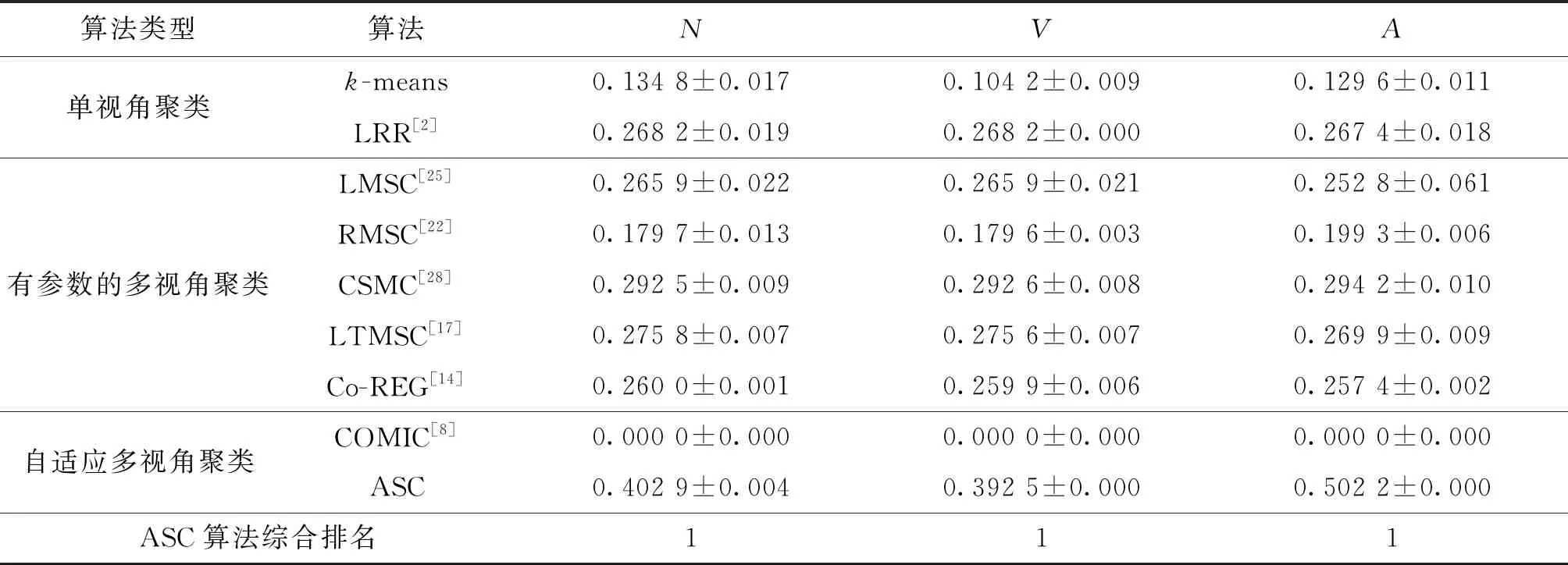
表6 Movies617数据集对比实验结果

表7 Scene-15数据集对比实验结果
3.5 时间复杂度分析
在Caltech101数据集上,根据经验对超参数λ和μ进行人工调参,结果如图2所示。
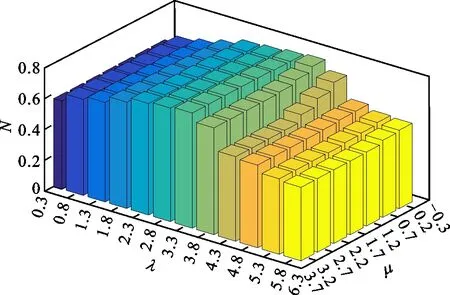
图2 时间复杂度分析实验结果Fig.2 Time complexity analysis of experimental results
共进行80次手动调参,耗时14 h 18 min,超参数λ和μ最终收敛在3.8和0.2附近,并得到归一化互信息评价指标最大值为0.751 3。本文自适应超参数算法耗时11 min 54 s,与手动调参相比性能差值仅为1.18%。由此可知,本文算法所得超参数基本发挥出算法的最大性能,且在时间和人力成本上有着明显优势。
3.6 收敛性分析
在Caltech101、LandUse-21这两个大规模数据集上进行收敛性分析实验,结果如图3和图4所示。可以看出,即使是在大规模数据集中,本文算法依然能够快速收敛,在Caltech101数据集中,迭代38次后基本收敛,在LandUse-21数据集中,迭代26次后基本收敛。这一实验结果证明了本文算法为块坐标下降法属类的基本判断,具有优良的收敛性能。

图3 Caltech101数据集上的收敛性分析Fig.3 Convergence analysis on Caltech101 dataset

图4 LandUse-21数据集上的收敛性分析Fig.4 Convergence analysis on LandUse-21 dataset
4 总 结
高维数据矩阵通常包含多个低维度子空间,本文认为处于同一子空间中的数据是属于同一类的数据。基于此,本文利用子空间进行聚类,提出了自适应多视角子空间聚类算法,结论如下。
(1)来自于现实世界的数据通常都是无标签数据,超参数调优往往是聚类算法难以应用于现实的障碍。本文算法将超参数自适应算法与子空间聚类算法相结合,在保证算法性能的同时极大地降低了通常算法调优过程中所耗费的人力物力成本,使子空间聚类算法应用于现实无标签数据成为可能。
(2)相比于多视角聚类领域中已经提出的无参数聚类算法,本文在前人的基础上进行改进,成功解决了其在特定数据集上算法性能失效的问题,并在多个大规模数据集中取得了良好的性能提升。
(3)本文算法在小规模数据集中与有参数聚类算法存在性能差距,这也是无参数聚类算法的普遍缺陷,后续研究可考虑在小规模数据集的性能上做出提升。
猜你喜欢
分子催化(2022年1期)2022-11-02
今日农业(2022年14期)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
纺织科技进展(2021年5期)2021-07-22
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
电脑报(2019年17期)2019-09-10
读与写·教育教学版(2017年10期)2017-11-10
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
