
基于改进VGG模型的人脸表情识别研究
2021-05-07 02:24张士豹王文韬
现代信息科技 2021年23期
关键词:卷积神经网络
张士豹 王文韬




摘 要:针对目前人脸表情识别的准确率偏低、训练速度较慢、泛化能力弱等问题,提出了改进的VGGNet,添加BN算法和PReLU激活函数,在图像预处理时加入高斯滤波和直方图均衡化,并且使用FER2013、AffectNet、JAFFE、CK+四种数据集进行比较分析。最终的实验结果表明,该模型在四种数据集上的识别准确率都有所提高,在四种数据集上的准确率达到73.52%、84.66%、94.28%、95.26%。在测试集上的泛化能力较强,训练速度也变快。
关键词:卷积神经网络;激活函数;BN算法;表情识别
中图分类号:TP391.4;TP183 文献标识码:A文章编号:2096-4706(2021)23-0100-04
Research on Facial Expression Recognition Based on Improved VGG Model
ZHANG Shibao, WANG Wentao
(Nanjing University of Information Science & Technology, Nanjing 210044, China)
Abstract: In view of the low accuracy, slow training speed, and weak generalization ability of facial expression recognition at present. An improved VGGNet is proposed, adds Batch Normalization (BN) algorithm and PReLU activation function. Gaussian filtering and histogram equalization are used in image preprocessing, and four data sets of FER2013, AffectNet, JAFFE, CK+ are used for comparative analysis. The final experimental results show that the recognition accuracy of the model has been improved on the four data sets, and the accuracy of the mode on the four data set has reached 73.52%, 84.66%, 94.28% and 95.26%. The generalization ability of the model on the test sets is strong, and the training speed is also faster.
Keywords: convolutional neural network; activation function; BN algorithm; facial expression recognition
0 引 言
人臉表情识别是人脸识别技术的分支。随着计算机技术发展,人脸表情识别可以实现对人脸表情的理解,有效改变人与计算机的关系。人脸表情识别技术在人机交互、心理学、在线学习、广告营销、机器人制造、智能制造、动画合成等领域有很广泛的应用。
人脸表情识别有两大类方法:对人脸表情进行特征提取和深度学习的方法。何颖等人[1]融合了局部方向模式(LDP)和中心二值化模式(CBP)对全脸和局部特征进行提取,并引入HOSVD进行精确匹配,准确率提高了17%。张庆等人[2]提出循环链码编码的人脸表情几何特征提取算法,比经典LBP特征鉴别方法准确率提高约10%。Lajevardi等人[3]使用Gabor滤波器、log Gabor滤波器、局部二值模式(LBP)算子、高阶局部自相关(HLAC)和HLACL的方法对选定的帧进行处理以生成脸部特征,并比较其准确性。虽然新的特征提取的方法可以提高准确率但其误差依然比深度学习方法要大。深度学习方法则是以人工神经网络为架构,通过多层处理以及误差反向传播对人脸特征进提取的。近年来随着深度学习的广泛应用,人脸表情识别也通过使用深度学习方法来提高泛化性和鲁棒性并取得很好的效果。
Minaee等[4]提出了一种基于ACN的深度学习方法,该方法能够专注于人脸的重要部分,并在多个数据集上实现了显著的改进。Jiao等[5]提出了一种基于融合的VGG网络集成方案。利用4个对MEC数据集进行微调的VGGFace模型集成,对验证数据的精度分别为51.06%。Zhong等[6]提出了一种基于ResNet和SENet的简化高效神经网络。FFE2013和CK+数据库上的识别准确率分别为74.14%和95.25%。与VGG相比提高了模型的精度,而且减小了模型的尺寸,在模型参数的大小和识别精度方面与现有方法相比具有竞争力。程换新等[7]设计了一种基于卷积神经网络(CNN)和长短期记忆神经网络(LSTM)的方法,使用3个数据集验证模型准确性,所提出的模型具有较强的泛化能力。
本文则在VGGNet网络的基础上,在输入层加入Batch Normalization操作,使每层神经网络输入是相同分布,加快训练速度,提高学习率,并且在激活函数上使用自适应PReLU来提高收敛速度、降低错误率。将改进VGG网络在FER2013、AffectNet、JAFFE、CK+四个数据集上的运行结果和原始VGGNet、ResNet、MobileNet进行对比分析,准确率有所提升。
1 VGGNet网络及其改进
1.1 VGGNet网络
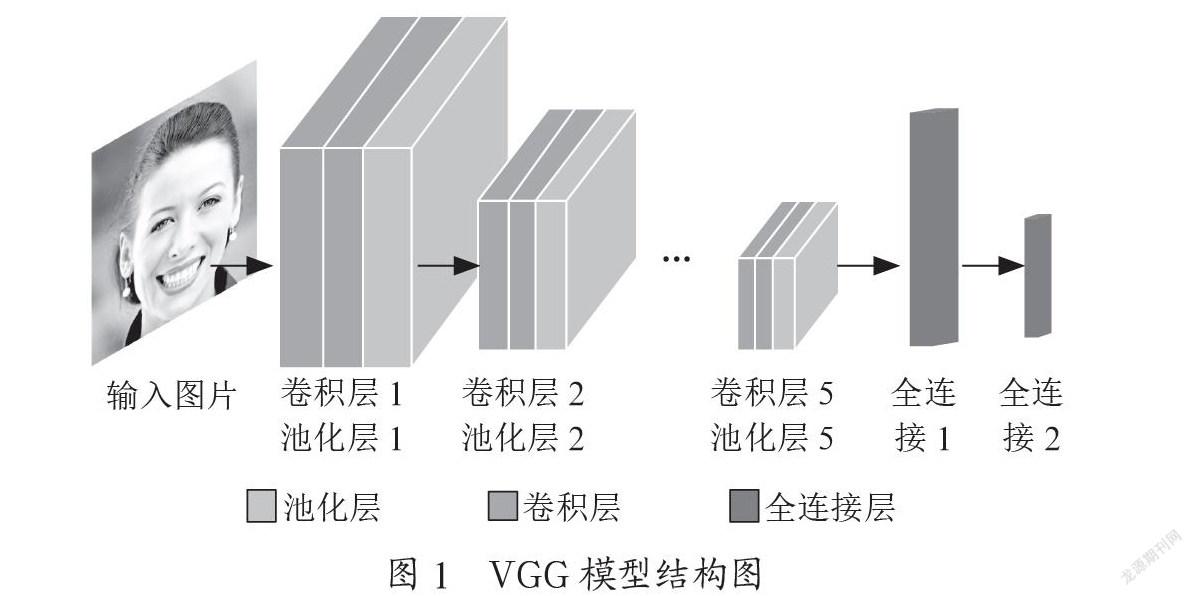
VGGNet是由Karen等[8]于2014年提出的,主要是通过提高网络深度来提高网络性能,用堆叠的小卷积核来替代大的卷积核,在相同感知野下能提高网络深度。VGGNet根据网络深度不同可以分为VGG16和VGG19。其基本结构包括卷积层、池化层、全连接层,VGG网络模型具体形式如图1所示。
1.2 VGGNet网络的改进
改进的VGGNet网络在原始网络框架的基础上,对图像进行预处理,添加BN(Batch Normalization)算法以及PReLU激活函数,来提高模型收敛速度以及解决梯度消失和网络深度加深,进行训练时会引起数据参数变动过大问题。
高斯滤波是一种简单、快速的线性平滑去噪方法。根据我们选择的窗口大小及窗口内任何像素与中心像素点的距离,利用高斯函数进行权值分配。其中Wху表示的是中心像素(x,y)的邻域,ωd表示权重因子,会根据距离的远近而变化。
(1)
高斯滤波的权重因子是根据二维的高斯分布而确定的:
(2)
直方图均衡化(Histogram Equalization)也称直方图平坦化。直方图均衡化的本质是对图像进行非线性拉伸,使动态范围得到了增加。直方图均衡化的目的是使图像灰度的概率密度变平坦,让整个图像的灰度值近似于均匀分布。这样图像会有较高对比度和丰富的细节。具体的方法是通过读取图像画出直方图,通过直方图得到变换函数,利用变换函数即可实现直方图均衡化。如图2所示为经过高斯去噪和直方图均衡化的结果。
经过高斯去噪和直方图均衡化后的数据依然不能满足pytorch中卷积神经网络API的设计,因此还需将图像数据进行reshape以及将numpy数据类型转化为tensor數据类型。为了避免数据输入模型后会因数据不匹配而报错,所以要将数据指定为torch.FloatTensor型。
BN是在数据输入前对网络做归一化处理,可以改善网络梯度,减少对初始化的强烈依赖。E(x(k))和Var(x(k))是一批训练数据各神经元输入值的平均值和方差。对于式(3)会产生数据分布的破话,需要使用式(4)进行线性变换对公式的鲁棒性进行优化,这样使神经元有γ、β这两个参数。
(3)
(4)
BN算法在解决网络训练收敛速度慢及模型精度低的情况下有很好的效果,同时也克服了内部协变量偏移和梯度消失等问题。
PReLU是LReLU的改进版本。PReLU的特点是收敛速度快,用于反向传播训练,相对于LReLU、ReLU来说增加了极少量的参数。当不同的通道使用相同参数时,模型参数便更少。PReLU的计算公式为:
(5)
yi是激活函数在第i个通道输入,αi是激活函数在负轴上的斜率。上面的公式也可表示为:
(6)
2 实验过程及结果分析
2.1 数据集介绍
人脸表情识别将人脸表情分为七种离散标签:开心、悲伤、惊讶、害怕、厌恶、生气、中立。但Extended Cohn-Kanade Dataset(CK+)[9]除了上述七个表情以外,还增添了轻蔑这个表情。
FER2013[10]是用于kaggle竞赛的人脸表情识别数据集,通过Google引擎搜索,存放在.csv文件中,有三列数据,分别为:图像种类、图像像素点、图像用途。共35 887张图片。
AffectNet[11]的图片总数达18万张,并且提供离散及连续的两种表情标签,但目前提供标签的只有4.5万张图片。该数据集图片数也是目前真实状态下表情识别图片数最多的数据集。
TheJapanese Female Facial Expression (JAFFE) Dataset[12]是日本学者选取10名女性实验者通过做不同表情得到的数据集,每个女性都做七类表情并且每个表情做3次或4次,虽然数据量很小,大约200多张,但每张图片分辨率较高,为256×256。
Extended Cohn-Kanade Dataset(CK+)是比其他数据集多一类表情(轻蔑)的数据集,数据集以视频形式给出,视频分辨率有640×490和640×480两种。实验者通过提取最后几帧作为实验样本。该数据集合JAFFE一样也是由实验者通过做不同表情得到的数据集,但参与者是JAFFE的10倍以上。
2.2 实验设计与结果
将上述的人脸表情识别数据集按照6∶2∶2的比例划分为训练集、测试集、验证集。通过训练集得到神经元内部参数,验证集来调整外置参数,测试集则用来评估模型泛化能力及模型好坏评估。数据的batch size设置为128,epoch设置为50,learning rate设置为0.01,损失函数使用交叉熵损失函数,采用自适应矩估计(Adam)的训练策略。实验使用FER2013、AffectNet、JAFFE、CK+这四种数据集,通过VGG16、ResNet、MobileNet以及改进的VGG16四种方法进行实验结果的对比分析。
图像在输入训练器前,需要对数据进行预处理,数据集在经过图像预处理前后准确率对比。可以看出在经过预处理后两个数据集的准确率均有所提高,说明预处理的效果是有效的。
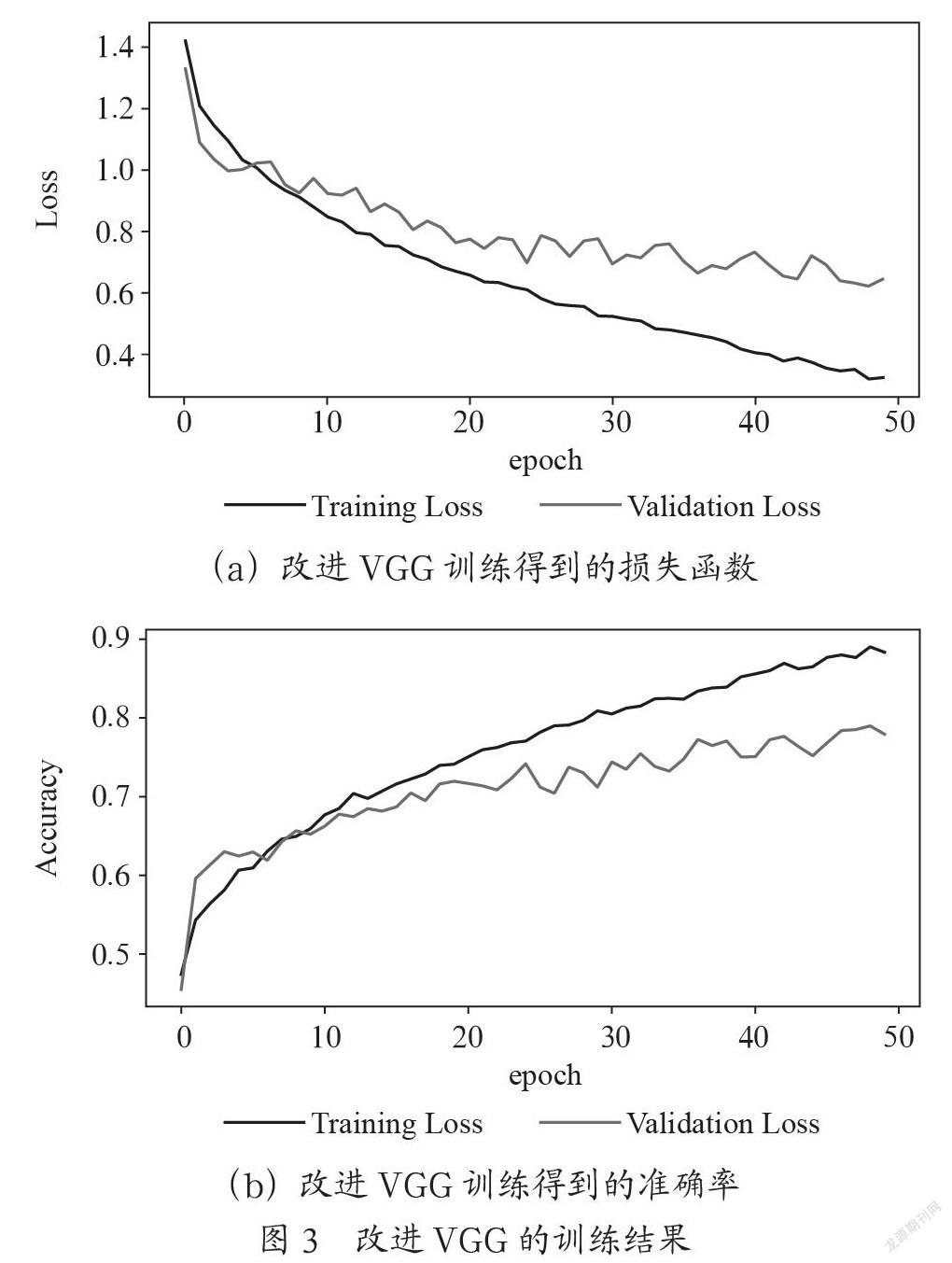
为了说明训练过程,以FER2013数据集为例,展示改进后的VGG16的运行结果。改进后的损失函数及准确率随着epoch的改变,如图3所示。由图3可知在经过50个epoch后训练集和验证集的loss都降到1以内,准确率均超过0.75。说明改进的VGG16的分类效果较好。
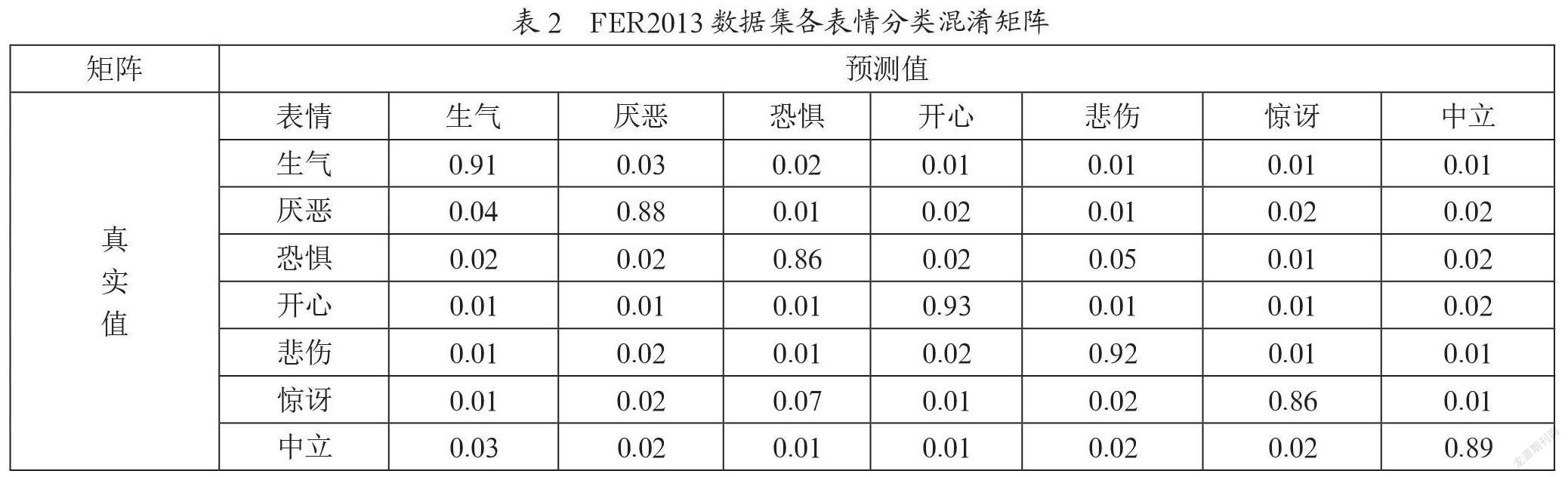
在这种情况下,只能看到整体的准确率是不够的,还需要具体查看分类器对哪种表情分类效果较好,以及了解分类器出现误分类比较严重的情况。为此需要对实验的结果绘制混淆矩阵如表2所示。其中按行排列的表情是真实的表情类别,按列排列的则是分类器输出的表情类别。从表中可以看出整体分类效果较好,都超过80%。对惊讶的表情分类效果较差,最容易将惊讶归类为恐惧,不过这也符合实际情况,在某些情况下人也很难将这两种表情区分开。对开心这个表情的识别较好,在现实中开心这个表情也容易跟其他表情区分开。
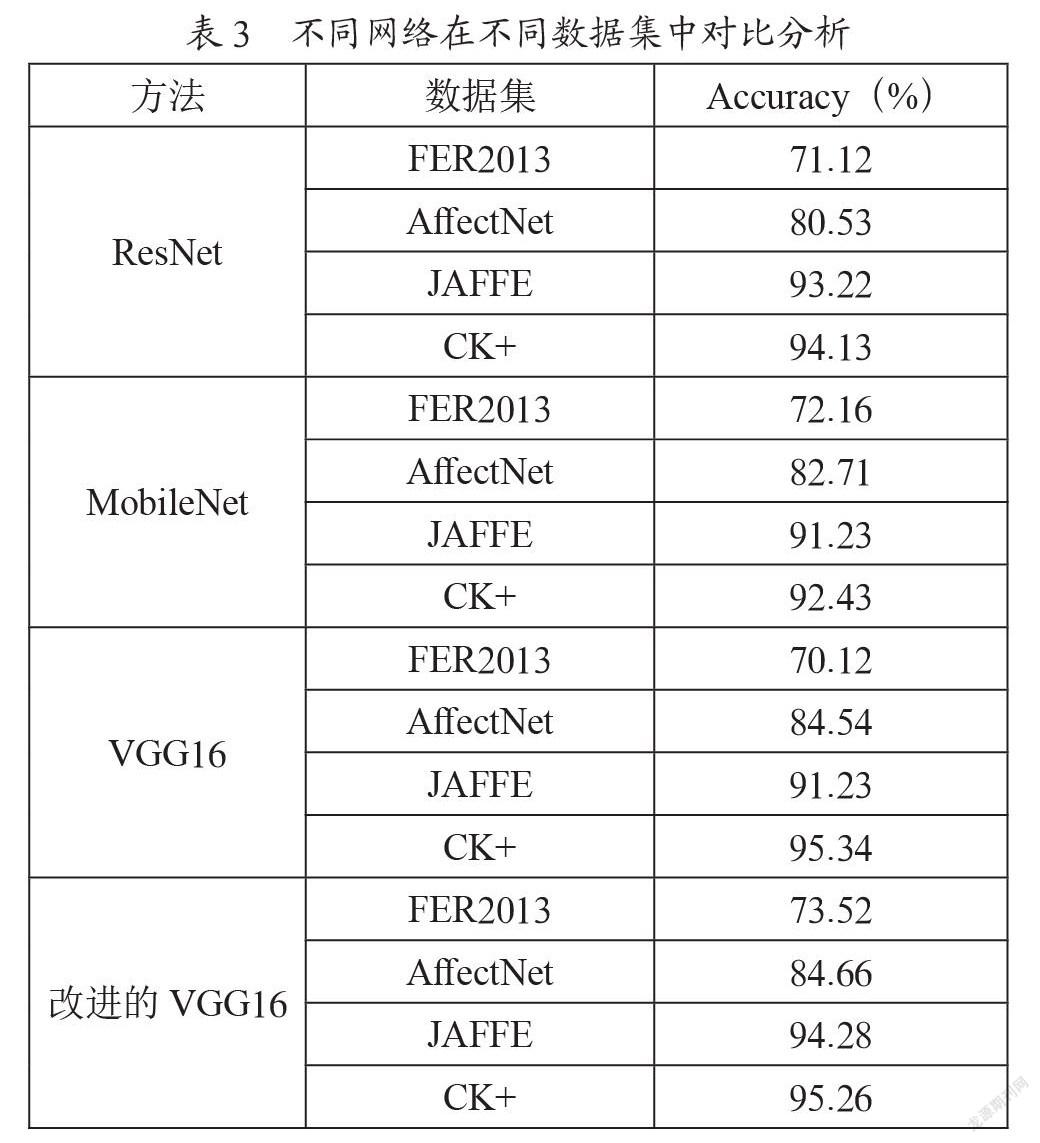
将不同的神经网络方法应用在四种数据集进行训练后,把训练的模型保存下来。将测试集代入模型,得到测试集的准确率如表3所示。从表中可以看出CK+和JAFFE这两个数据集在不同网络的分类结果较好。但FER2013在所有的网络模型的准确率均不高,没有超过80%,效果最好的模型是改进VGG16达到75.52%,这与FER2013的图像分辨率较低有关。从表中可以看出改进的VGG16在不同数据集的效果都比其他神经网络要好,在FER2013提升的效果不是太高,在JAFFE的提升较好。
3 结 论
本文对VGG16模型进行改进,加入BN算法,使输入分布服从均值为0方差为1的分布,避免了梯度消失问题,对参数调整效率也变高。同时引入PReLU激活函数,在保留有部分小于0的信息又达到了激活函数的目的,小于0的部分的斜率也是可学习的,比ReLU具有更好的激活效果。在图像预处理方面也通过高斯去噪、直方图均衡化处理使人脸表情识别效果更好。关于人脸识别的数据集有很多,本文选择FER2013、AffectNet、JAFFE、CK+四种数据集并使用ResNet、MobileNet、VGG16、改进的VGG16四种方法进行比较分析。实验结果表明改进的模型识别的准确率比其他三种模型要高,泛化能力也较强。
虽然目前的很多人脸识别方法的准确率较高,在各个方面也有好的应用。但目前人脸识别在遮挡、人脸侧面、强光照射等方向研究较少,此外人脸标签目前针对是离散的标签的研究,如何在人脸连续标签进行研究也是未来值得研究的方向。
参考文献:
[1] 何颖,陈淑鑫,王丰.基于HOSVD分类的非特定人脸表情识别算法 [J].计算机仿真,2021,38(10):193-198.
[2] 張庆,代锐,朱雪莹,等.基于链码的人脸表情几何特征提取 [J].计算机工程,2012,38(20):156-159.
[3] LAJEVARDI S M,HUSSAIN Z M. Automatic facial expression recognition:feature extraction and selection [J].Signal,Image and Video Processing,2012,6:159-169.
[4] MINAEE S,MINAEI M,ABDOLRASHIDI A. Deep-Emotion:Facial Expression Recognition Using Attentional Convolutional Network [J/OL]. arXiv:1902.01019 [cs.CV].[2021-11-03].https://arxiv.org/abs/1902.01019v1.
[5] JIAO Z J,QIAO F C,YAO N M,et al. An Ensemble of VGG Networks for Video-Based Facial Expression Recognition [C]//2018 First Asian Conference on Affective Computing and Intelligent Interaction.Beijing:[s.n.],2018:1-6.
[6] ZHONG Y X,QIU S H,LUO X S,et al. Facial Expression Recognition Based on Optimized ResNet [C]//2020 2nd World Symposium on Artificial Intelligence(WSAI).Guangzhou:IEEE,2020:84-91.
[7] 程换新,王雪,程力,等.基于CNN和LSTM的人脸表情识别模型设计 [J].电子测量技术,2021,44(17):160-164.
[8] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].[2021-11-03].https://arxiv.org/abs/1409.1556.
[9] LUCEY P,COHN J F,KANADE T,et al. The Extended Cohn-Kanade Dataset (CK+):A complete dataset for action unit and emotion-specified expression [C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops.San Francisco:IEEE,2010:94-101.
[10] GOODFELLOW I J,ERHAN D,CARRIER P L,et al. Challenges in representation learning:A report on three machine learning contests [J] Neural Networks,2015,64:59-63.
[11] MOLLAHOSSEINI A,HASANI B,MAHOOR M H. Affectnet:A Database for Facial Expression,Valence,and Arousal Computing in the Wild [J].IEEE Transactions on Affective Computing,2019,10(1):18-31.
[12] LYONS M J,KAMACHI M,GYOBA J. Coding Facial Expressions With Gabor Wavelets (IVC Special Issue) [J/OL].arXiv:2009.05938 [cs.CV].[2021-11-03].https://arxiv.org/abs/2009.05938.
作者简介:张士豹(1996—),男,汉族,安徽滁州人,助教,硕士在读,研究方向:图像处理;王文韬(1998—),男,汉族,江苏苏州人,助教,硕士在读,研究方向:图像处理。
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22
电脑知识与技术(2016年33期)2017-03-21
科技创新与应用(2017年5期)2017-03-16
电脑知识与技术(2016年30期)2017-03-06
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件(2016年5期)2016-08-30
电脑知识与技术(2016年10期)2016-06-16
