
Application of FCM Algorithm Combined with Artificial Neural Network in TBM Operation Data
2021-04-29 07:51JingyiFangXueguanSongNianminYaoandMaolinShi
Jingyi Fang,Xueguan Song,Nianmin Yao and Maolin Shi,★
1School of Computer Science and Technology,Dalian University of Technology,Dalian,116024,China
2School of Mechanical Engineering,Dalian University of Technology,Dalian,116024,China
ABSTRACT Fuzzy clustering theory is widely used in data mining of full-face tunnel boring machine.However,the traditional fuzzy clustering algorithm based on objective function is difficult to effectively cluster functional data.We propose a new Fuzzy clustering algorithm,namely FCM–ANN algorithm.The algorithm replaces the clustering prototype of the FCM algorithm with the predicted value of the artificial neural network.This makes the algorithm not only satisfy the clustering based on the traditional similarity criterion,but also can effectively cluster the functional data.In this paper,we first use the t-test as an evaluation index and apply the FCM–ANN algorithm to the synthetic datasets for validity testing.Then the algorithm is applied to TBM operation data and combined with the crossvalidation method to predict the tunneling speed.The predicted results are evaluated by RMSE and R2.According to the experimental results on the synthetic datasets,we obtain the relationship among the membership threshold,the number of samples,the number of attributes and the noise.Accordingly,the datasets can be effectively adjusted.Applying the FCM–ANN algorithm to the TBM operation data can accurately predict the tunneling speed.The FCM–ANN algorithm has improved the traditional fuzzy clustering algorithm,which can be used not only for the prediction of tunneling speed of TBM but also for clustering or prediction of other functional data.
KEYWORDS Data clustering; FCM; artificial neural network; functional data; TBM
1 Introduction
Cluster analysis belongs to unsupervised pattern recognition and is a multivariate statistical analysis method.It divides an initial sample set into several subsets according to a certain criterion, so as to achieve clustering of sample sets and analyze clustering results.Because in the actual engineering application, the research objects without clear classification boundaries occupy the main position, the fuzzy clustering is mainly used to cluster such objects, that is,the objects can belong to two or more categories at the same time [1,2].In practical applications, the more general method is the fuzzy clustering method based on the objective function.This method transforms the cluster into a nonlinear programming problem with constraints,and then obtains the fuzzy partitioning and the clustering of the datasets through optimization.In the clustering algorithm based on objective function, Fuzzy c-Means (FCM) algorithm has the most complete theory and the most widely used.The algorithm was originally proposed and developed by Bezdek and Hathaway [3-5].It introduces the concept of membership degree based on the hard c-means (HCM) algorithm and implements fuzzy clustering by means of alternating optimization.
There have been many researches on FCM algorithms.Yu et al.[6] proposed the generalized fuzzy clustering regularization (GFCR) model based on various fuzzy clustering algorithms such as FCM algorithm, and verified the validity of the model.Zhang et al.[7] applied an improved weighted fuzzy c-means (WFCM) model and introduced an interval number, making it easier to obtain appropriate weights.Askari et al.[8] proposed a Generalized Entropy based Possibilistic Fuzzy C-Means (GEPFCM) algorithm for noise data clustering, which is more accurate than the Possibilistic Fuzzy C-Means (PFCM) algorithm.Li et al.[9] improved the FCM algorithm for the clustering problem of data with missing attribute values, and realized the clustering of incomplete datasets.
In the research of FCM type clustering algorithm, the research of clustering prototype has always been an important direction.The initial clustering prototype is a “point” in space, which is only suitable for the detection of hypersphere clustering structures.In order to detect the nonhypersphere clustering structure, Bzedek et al.[10] proposed a new clustering prototype, which is a multi-dimensional linear cluster over a certain point.In addition, according to different clustering structures, the researchers also developed a variety of clustering prototypes, such as the spherical shell [11,12] and the ellipsoid shell [13,14] two clustering prototypes.With the deepening of research and the expansion of application requirements, clustering prototypes have been extended to more forms.For example, Suh et al.[15] proposed a fuzzy clustering algorithm based on the polyhedral shell as a clustering prototype.Although these clustering prototypes can detect the detection of one or more clustering structures, they need to use prior knowledge to select prototypes before clustering.This does not enable efficient clustering when encountering functional data with high complexity and inconspicuous clustering structure.
Functional data refers to data obeying a function, and can also be regarded as random observation data of a function in an interval.With the development of data acquisition and storage capabilities, data can be collected in many fields with functional features.Functional data has been applied to many fields such as economics, medicine, meteorology and neuroscience [16-19].Functional data clustering analysis is a research hotspot in recent years.Researchers have proposed a variety of clustering methods for different objects.From the data itself, Zambom et al.[20] proposed a new method based on functional data clustering combining parallel hypothesis testing and mean testing.Delaigle et al.[21] first project data onto a finitedimensional space, and then use the K-means algorithm to achieve clustering.Bruckers et al.[22]used data interpolation with multiple imputations for functional data with missing values, and then clustered the imputed datasets.
Although the above method can achieve clustering of some functional data, it lacks universality in application.Because some of these methods require high accuracy of data, they cannot be implemented with high data noise.Others will ignore certain parameter information, resulting in low classification accuracy.
In the recent period, machine learning methods represented by deep learning have been applied to many fields, such as computer vision, natural language processing, and data mining.Since deep learning has good feature learning capabilities, it is also used as an alternative method for engineering problems.Samaniego et al.[23] combined DNN in the configuration method and the deep energy method to provide a novel idea for solving partial differential equations.Guo et al.[24] applied a deep learning method to the thin plate bending problem, which is suitable for the bending analysis of Kirchhoff plates with various geometric shapes.Vien et al.[25] proposed a deep energy method for processing nonlinear large deformation hyperelasticity based on DNN, which can quickly and efficiently obtain numerical solutions.Anitescu et al.[26] proposed an adaptive configuration strategy using artificial neural networks to solve partial differential equations, and obtained the desired results in solving boundary value problems.
In the field of fuzzy clustering, there are also many studies that combine neural network methods.ANN simulates a biological neural network and builds a training model from multiple nodes to achieve regression and approximation of complex functions.Xu et al.[27] proposed a WLAN hybrid indoor positioning method based on FCM and ANN, which reduces the positioning error while ensuring efficiency.Karlik et al.[28] proposed a new fuzzy clustering neural network (FCNN) algorithm as a pattern classifier for real-time odor recognition systems.The FCNN algorithm uses FCM clustering to reduce the number of data points before inputting to the neural network system, thereby shortening the training cycle of the neural network.In addition, Mohd-Safar et al.[29] and Moradi et al.[30] also combined FCM and ANN, proposed different models, and applied them to engineering problems.However, in these methods, FCM and ANN are independent of each other, which will not only increase the computational burden but also fail to achieve effective clustering on complex problems such as the clustering of functional data.In addition, in these studies, FCM is used more as a data preprocessing method and serves ANN.The algorithm we proposed takes FCM as the overall framework and ANN as a way to describe the functional relationship.The structure achieves the integration of the two, and at the same time carries out end-to-end training, which can realize the effective clustering of complex functional data.
For the clustering problem of functional data, this paper proposes the FCM-ANN algorithm.It obtains an approximate functional model through the ANN training dataset.Then the function model is used as a new clustering prototype to replace the clustering prototype of the traditional FCM algorithm, and participates in the algorithm’s alternating optimization.Finally, the algorithm will obtain the clustering result of the dataset and the corresponding functional data ANN model.
The rest of this paper is organized as follows.In Section 2, we first introduce the FCM algorithm and the artificial neural network algorithm, and then propose the FCM-ANN algorithm.Section 3 introduces the clustering results of applying the algorithm to synthetic dataset experiments and compares it with the traditional FCM algorithm.Section 4 introduces the experimental results of applying the FCM-ANN algorithm to the operation data of the tunnel boring machine(TBM) and compares it with the method of not performing classification modeling.In Section 5 we make some conclusions on this paper.
2 Proposed Algorithm(FCM–ANN)
2.1 Fuzzy c-Means Algorithm
The FCM algorithm is a fuzzy clustering algorithm based on objective function.For a given datasetX={x1,x2,x3,...,xn}⊂Rs, the FCM algorithm dividesXintoc(2 ≤c≤n)clusters by minimizing the clustering objective function.The clustering objective function is as follows:

wherexk=[x1k,x2k,x3k,...xsk]Tis the target data,xjkis thej-th attribute value of the data;pi(i=1,2,...,c)represents the clustering prototype vector of thei-th cluster, and the clustering prototype matrix is represented asis the membership degree,which indicates the degree to which the dataxkbelongs to thei-th cluster.For ∀i,k, there isµik∈[0,1], and it satisfies the following relationship:

The partition matrix is expressed asU=[µik]∈Rc×n;mis a weighting parameter, also called a smoothing parameter,m∈(1,∞);‖·‖ is the Euclidean distance in thes-dimensional space.
Combined with the constraint Eq.(2), the Lagrange multiplier method can be used to minimize the objective function.The final formula for the partition matrix and clustering prototype is as follows:

The specific steps of the FCM algorithm are as follows:
Step (i) Set the number of subclusters of fuzzy clusteringc, for 2 ≤c≤n,nis the number of data of the target dataset; set the iteration stop thresholdε; initialize the cluster prototypeP(0); set the iteration counterb=0.
Step (ii) Calculate (or update) the partition matrixU(b)using Eq.(3) andP(b).
Step (iii) Update clustering prototypesP(b+1)using Eq.(4) andU(b)
Step (iv) Calculate the discriminant Eq.(5):

If the Eq.(5) is established, the algorithm stops and outputs the partition matrixUand and the cluster prototype matrixP; otherwise setb=b+1 and re-execute Step (ii).In Eq.(5), ‖·‖ is a suitable matrix norm.
The algorithm can also start by initializing the fuzzy partition matrixU, then calculate(update) the clustering prototype matrix with the Eq.(4), and then update the fuzzy partition matrix with the Eq.(3), until the stopping criterion is met.
2.2 Artificial Neural Network(ANN)
As a hotspot in recent years, artificial neural network is a multi-disciplinary subject area with a wide range and depth.A neural network is a broad and interconnected network of adaptive simple units whose organization mimics the interactions of the biological nervous system with the real world.The most basic building block in a neural network is a neuron.Each neuron is connected to other neurons, and each neuron transmits information through signals.
In this paper, we use the BP (error BackPropagation) algorithm to construct a neural network,which is the most common neural network learning algorithm by far.For a given training datasetD= {(x1,y1),(x2,y2),...,(xn,yn)} forxi∈Rdandyi∈Rl, that is, the input data containsdattribute values, and the output data containslattribute values.We abstract the algorithm model into a feedforward neural network structure as shown in Fig.1.

Figure 1:Feedforward neural networks with one hidden layer
The structure hasdinput neurons andloutput neurons.The hidden layer neurons can be assumed to bem.The threshold of thej-th neuron in the output layer is represented byθj, and the threshold of theh-th neuron in the hidden layer is represented byγh.The connection weight between theh-th neuron in the hidden layer and thej-th neuron in the output layer isωhj, and the connection weight between thei-th neuron in the input layer and theh-th neuron in the hidden layer isυih.
For ad-dimensional inputx= [x1,x2,x3,...,xd]T∈Rd, the output valuey= [y1,y2,y3,...,yl]T∈Rlcan be obtained according to the neural network structure.The final calculation result ofyjis as follows:
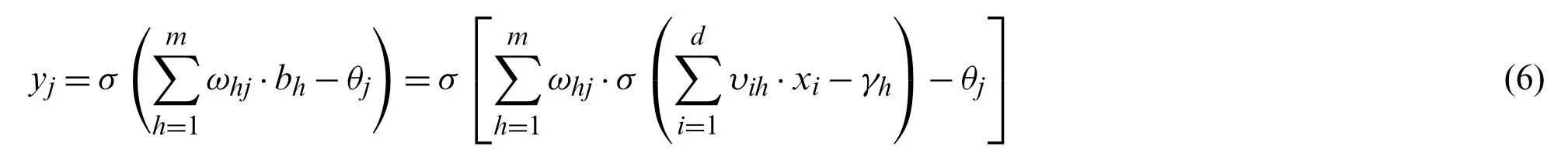
whereσis a sigmoid function, its equation is:

2.3 FCM–ANN Algorithm
In view of the fact that the traditional FCM algorithm can not effectively solve the fuzzy clustering problem of functional data, we propose the FCM-ANN algorithm.In the FCM-ANN algorithm, we replace the clustering prototype in the traditional FCM algorithm with the neural network prediction value.This makes the clustering prototype change to conform to a certain data partitioning function, thus achieving accurate clustering of data.
For functional data, the iterative process of the FCM-ANN algorithm can be expressed as follows:
Step (i) Set the number of subclusters of fuzzy clusteringc, for 2 ≤c≤n,nis the number of data of the target data set; set the iteration stop thresholdε; initialize the partition matrixU(0); Set the membership thresholdΩ; set the iteration counterb=0.
Step (ii) The clustering result can be obtained according to the partition matrixU(b).We use the clustering results as training data set to input artificial neural networks for training, and then we can obtain different neural network prediction models,i∈{1,2,...c}.
Step (iii) The prediction model is used for the independent variablesX={x1,x2,x3,...,xn}⊂Rsin the dataset to obtain the corresponding predicted output.
Step (iv) Use the predicted output as a clustering prototype, the corresponding Euclidean distancecan be obtained according to the distance function:

Step (v) Update the partition matrixU(b+1)by the Eq.(9).

Step (vi) Calculate the discriminant:

If the Eq.(10) is established, stop the algorithm and output the partition matrixUand neural network prediction modelsANNi,i∈{1,2,...c}; otherwise setb=b+ 1 and repeat Step (ii).
The FCM-ANN algorithm combines the advantages of both FCM and ANN.FCM makes the iteration always go in the direction of gradient descent.ANN provides accurate prediction results and can approximate any nonlinear function.In theory, the algorithm can achieve fuzzy clustering of arbitrary functional data.

Algorithm 1:FCM-ANN Algorithm Require: X={x1,x2,x3,...,xn}⊂Rs,c,ε,Ω Ensure: U(0), b=0 1:for k=1 →n do 2: x′k ←images/BZ_397_563_616_581_662.pngx1k,x2k,...,x(s-1)kimages/BZ_397_950_616_968_662.pngT 3: yk ←xsk 4:end for 5:if‖‖‖U(b+1)-U(b)‖‖‖>ε then 6: for i=1 →c do 7: for k=1 →n do 8: if µ(b)ik >Ω then 9: traini.appendimages/BZ_397_917_1003_936_1049.pngx′k,ykimages/BZ_397_1057_1003_1075_1049.png10: end if 11: end for 12: end for 13: for i=1 →c do 14: ANNi ←ANN train data sets traini 15: end for 16: for i=1 →c do 17: ˆy(b)ik ←ANNiimages/BZ_397_775_1435_793_1481.pngx′kimages/BZ_397_851_1435_869_1481.png18: end for 19: for i=1 →c do 20: for k=1 →n do 21: d(b)ik ←images/BZ_397_725_1635_739_1681.pngimages/BZ_397_725_1662_739_1708.pngimages/BZ_397_725_1690_739_1736.pngyk-ˆy(b)ikimages/BZ_397_902_1635_917_1681.pngimages/BZ_397_902_1662_917_1708.pngimages/BZ_397_902_1690_917_1736.png22: end for 23: end for 24: for i=1 →c do 25: for k=1 →n do 26: µ(b+1)ik =images/BZ_397_760_1931_792_1976.pngcimages/BZ_397_795_1974_843_2020.png j=1images/BZ_397_853_1931_881_1976.pngimages/BZ_397_881_1944_912_1990.pngd(b)ik d(b)jkimages/BZ_397_978_1944_1009_1990.png 2 m-1images/BZ_397_1077_1931_1105_1976.pngimages/BZ_397_1105_1931_1137_1976.png-1 27: end for 28: end for 29: b=b+1 30:end if 31:return U,ANN1,...,ANNi,...,ANNc
3 Experiments on Synthetic Datasets
3.1 Synthetic Datasets
In this section, we construct some synthetic datasets to study the validity of FCM-ANN algorithms and their effect on predictions with the different number of samples, number of attributes, and noise.
The synthetic datasets are created as follows.In each cluster of each dataset, the objects ofi-th cluster exceptxobjare first randomly sampled.Thexobjof each object is calculated according to the setted FRA.After that, the data of different cluster are combined as the obtained dataset.Each dataset is given a denomination by the number of object data, attributes, clusters and functional relationships among attributes.For instance, N400A2C2F1 denotes that the dataset contains 400 object data and can be divided evenly into two clusters, A2 denotes the dataset has two attributes.The clustering performance of the proposed clustering algorithm is compared with FCM.
Number of samplesThe synthetic datasets that discuss the effect of the number of samples size are divided into four groups.Each group of dataset consists of two clusters, each of which has 50, 100, 150, and 200 object data.And each cluster has two attributes, which is a functional relationship ofx2=f (x1).The specific function relationship corresponding to the two types of data is as shown in Eqs.(11.1) and (11.2).At the same time, the noise is set to satisfy 3% of the standard functional relationship data and is subject to a Gaussian distribution.
Number of attributesThe synthetic datasets that discuss the effect of the number of attributes are divided into five groups.Each dataset consists of two clusters, and the number of attributes of each cluster is 2-6, separately.They respectively satisfy the relationship as shown in Tab.1.Each dataset have 200 samples.The noise is also set to 3%, as well as the Gaussian distribution is satisfied.

Table 1:Functional equation corresponding to the number of attributes
3.2 Experimental Results
In order to test the clustering performance, we carried out a comparison experiment between the proposed algorithm and the FCM algorithm.
The clustering performance is evaluated in terms of misclassification (MS), which is calculated as follows:

whereNerroris the number of misclassified object data;Ntotalis the total number of object data.
We set the fuzzification parameterm=2, convergence thresholdc=10-4.The misclassification is discussed in each experiment by controlling the membership threshold.Tabs.2-4 present the average results over 30 experiments, with the optimal results being indicated in bold.
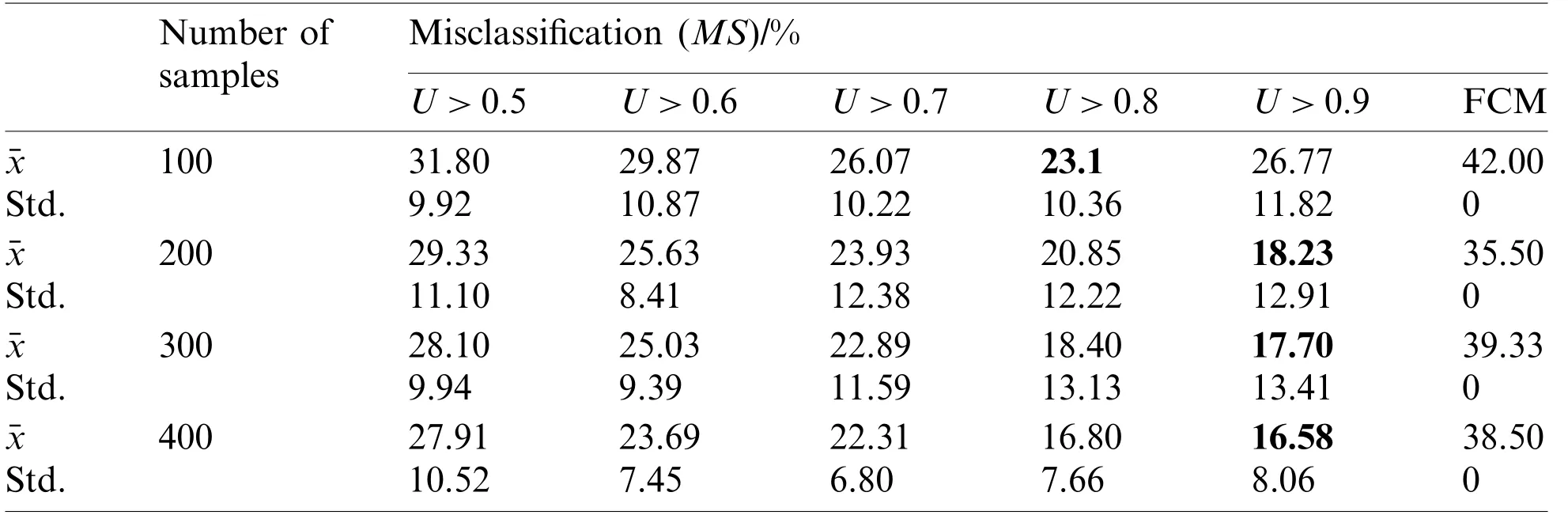
Table 2:Effect of the number of samples on algorithm prediction

Table 3:Effect of the number of attributes on the algorithm prediction
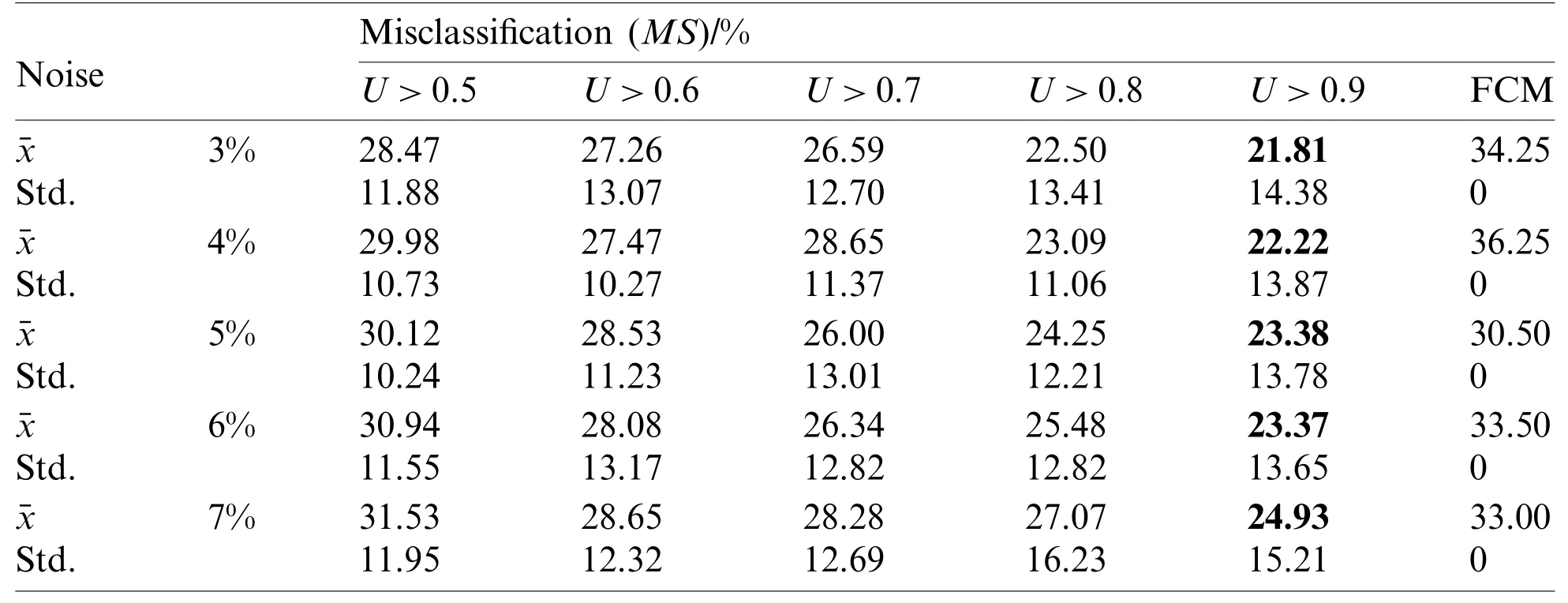
Table 4:Effect of the noise on the algorithm prediction
We use thet-test as the measure to analyze the convergence of the experimental results.Thet-test is mainly used for a normal distribution with a small sample size and an unknown population standard deviationσ.Thet-test uses thet-distribution theory to infer the probability of occurrence of the difference, thereby comparing whether the difference between the two means is significant.Thet-test can be divided into the one-samplet-test, the two-samplet-test and the pairedt-test.The paper uses the one-samplet-test method to test the results of clustering.
The one-samplet-test is used to test whether the difference between the average of a sample set and the known population mean is significant.When the distribution of the population shows a normal distribution, the sample size is small and the standard deviation of the population is unknown, the dispersion statistics of the sample mean and the population mean aret-distributed.
The statistic for the one-samplet-test is:

whereNis the total number of samples, ¯Xis the mean number of samples,µis the mean of the population, andSis the sample standard deviation.Thetstatistic obeys thet-distribution with a degree of freedom of(n-1)whenµ=µ0.
Thet-test was performed using the data in Tabs.2-4.The hypothesis is as follows:
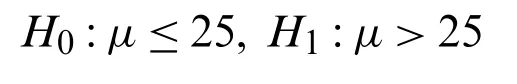
Under the condition of the significance levelα=0.05, the rejection region of the hypothesis ist >t0.05(n-1)=t0.05(29).Checking out the table oft-distribution to get the upper quantilet0.05(29)=1.6991.
This hypothesis is tested by calculating the statistictusing the Eq.(17).The results are listed in Tab.5, where the results over the upper quantile are indicated in bold.
In order to evaluate whether there is a significant difference between the results obtained by the FCM-ANN algorithm and the FCM algorithm, we also used the SPSS software to conduct a Wilcoxon rank-sum test.We compare the results in Tabs.2-4 with the results of the FCM algorithm according to different membership thresholds and calculate their rank-sum.The results of the rank-sum test are shown in Tab.6.Given the significance levelα=0.05, we can obtain the critical value of the rank sum of 166 ~240.According to the calculated rank-sum, we can judge whether the difference between the results of the two methods is significant.
3.3 Discussion
1) By analyzing Tabs.2-4, the mean of misclassifications obtained by using the FCM-ANN algorithm is significantly lower than that of the FCM algorithm, except for the experimental results corresponding to 3% noise in Tab.4.In addition, from the Wilcoxon rank-sum test results in Tab.6, it can be seen that the results obtained by the FCM-ANN algorithm are significantly different from those obtained by the FCM algorithm.Therefore, we can conclude that the clustering result of the FCM-ANN algorithm is better than the FCM algorithm.At the same time,according to the results in Tabs.2-4, as the membership threshold increases, the misclassifications show a downward trend.The results show that the higher the membership threshold, the more the invalid data can be avoided to participate in the artificial neural network training, so the fitting result is more accurate and the prediction effect is better.However, as the membership threshold increases, the standard deviation of the misclassification increases, which results in a decrease in the stability of the results.
2) According to the results of Tab.2, in the case where the membership threshold is the same, the misclassifications will decrease as the number of samples increases.According to the results, as the number of samples increases, the training dataset provided by the experiment will also increase, which makes the prediction effect of the algorithm more accurate.
3) According to the vertical comparison Tab.3, the clustering results of the dataset are better when the different number of attributes are taken.Therefore, it can be concluded that the FCMANN algorithm can achieve effective clustering of functional data with the different number of attributes.This also shows that the algorithm has favorable stability.
4) According to the results of Tab.4, when the noise increases, the misclassifications of the experiment using the FCM algorithm has no significant change, which indicates that the increase of noise will have less influence on the clustering result of the FCM algorithm.However,in the test results using the FCM-ANN algorithm, misclassifications will increase as the noise increases.Therefore, improving the accuracy of datasets and the reduction of noise can improve the clustering effect of the FCM-ANN algorithm.
5) According to Tab.5, most of the results of the test are below the upper quantile.Therefore,it can be considered that the hypothesisH0is valid, and the FCM-ANN algorithm can effectively implement the clustering of functional data.However, the results in the reject domain appear when the membership threshold is small.Therefore, appropriately increasing the membership threshold can make the clustering result more accurate.
3.4 Computation Cost and Convergence Analysis
3.4.1 Computation Cost
We use the average of running time to measure the computation cost of the algorithm.The experimental environment is intel(R) Core (TM) i5-9300H 2.40 GHz CPU, 8 GB RAM, Windows 10 operating system, Python 3.7.0.Tab.7 show comparisons of running times for experiments on synthetic datasets.
According to the results in Tab.7, although the FCM-ANN algorithm runs less time than the FCM algorithm, the results are still within acceptable limits.Therefore, the FCM-ANN algorithm can be considered to have a lower computation cost.At the same time, in the results, the running time will increase with the increase of the membership threshold, so the computation cost should be considered to set a reasonable membership threshold.
3.4.2 Convergence Analysis
Then, we concentrate on the convergence analysis of FCM-ANN algorithm.In the Synthetic data sets, we selected data sets with the number of attributes of 2-5 for testing, as shown in Fig.2.
It can be seen that in the case of different number of attributes, the objective function value declines rapidly in the first 6 iterations and then tends to converge gradually.Therefore, it can be further proved that the proposed algorithm is effective.
4 Engineering Application on TBM Operation Data
4.1 Project Review
The tunnel project studied in this paper is located on a metro line in China, with a length of 2,000 meters and a diameter of 6.4 meters.The project adopted earth pressure balance (EPB)shield TBM.This system consists of a cutterhead, chamber, screw conveyor, tail skin and otherauxiliary.The operation data adopted in this paper are collected from TBM construction projects,and there are 52 parameters, among which each parameter has different correlation with the tunneling speed.The statistical chart of the datasets used in this paper is listed in Appendix A.
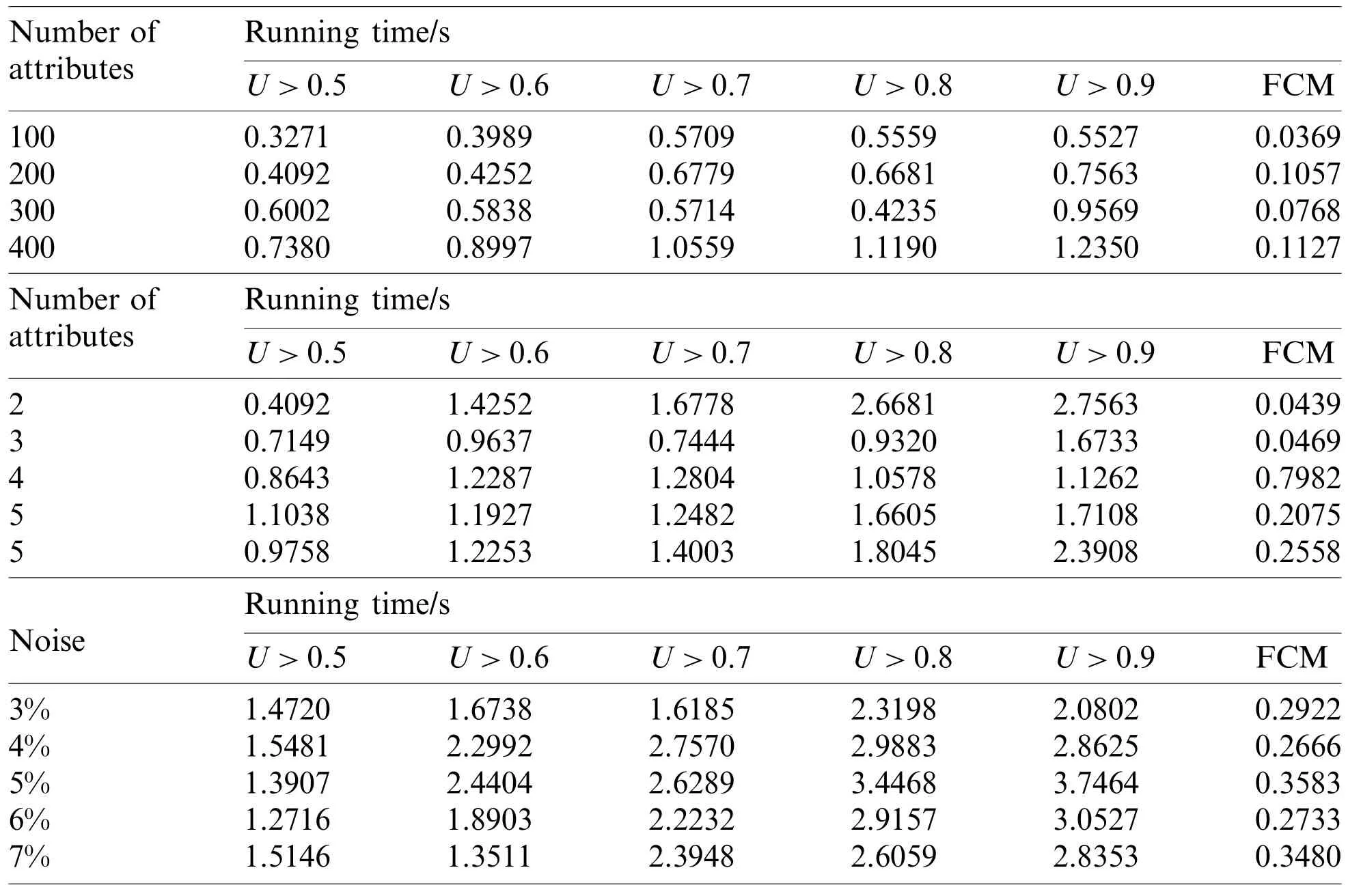
Table 7:Comparison of running times
4.2 Experiments and Results
The experiment is divided into two parts.Experiment 1 uses the neural network algorithm to directly train the TBM operation data to establish the prediction model of predicting the tunneling speed.Experiment 2 uses the FCM-ANN algorithm to cluster the TBM operation data firstly, aiming to obtain clustering results and prediction models for each cluster, and then use the model to predict each cluster of data.The two experimental results are compared to verify the practicability of the algorithm.
The same 1200 sets of TBM operation data were used in both experiments.We divide the datasets into three parts:Training set, validation set, and test set.Among them, the test set accounts for 20%, and the remaining 80% of the data is divided into training sets and validation sets.In addition, in order to prevent over-fitting problems, we perform 5-fold cross-validation on the training set and the validation set.The data are randomly divided into 5 equal parts, and each of the 5 equal parts is used as a separate test set, and the remaining 4 parts are used as the training set for building the model for validity verification.We use mean square error(MSE) as an indicator to evaluate the prediction accuracy of the validation set, which is calculated by Eq.(18).

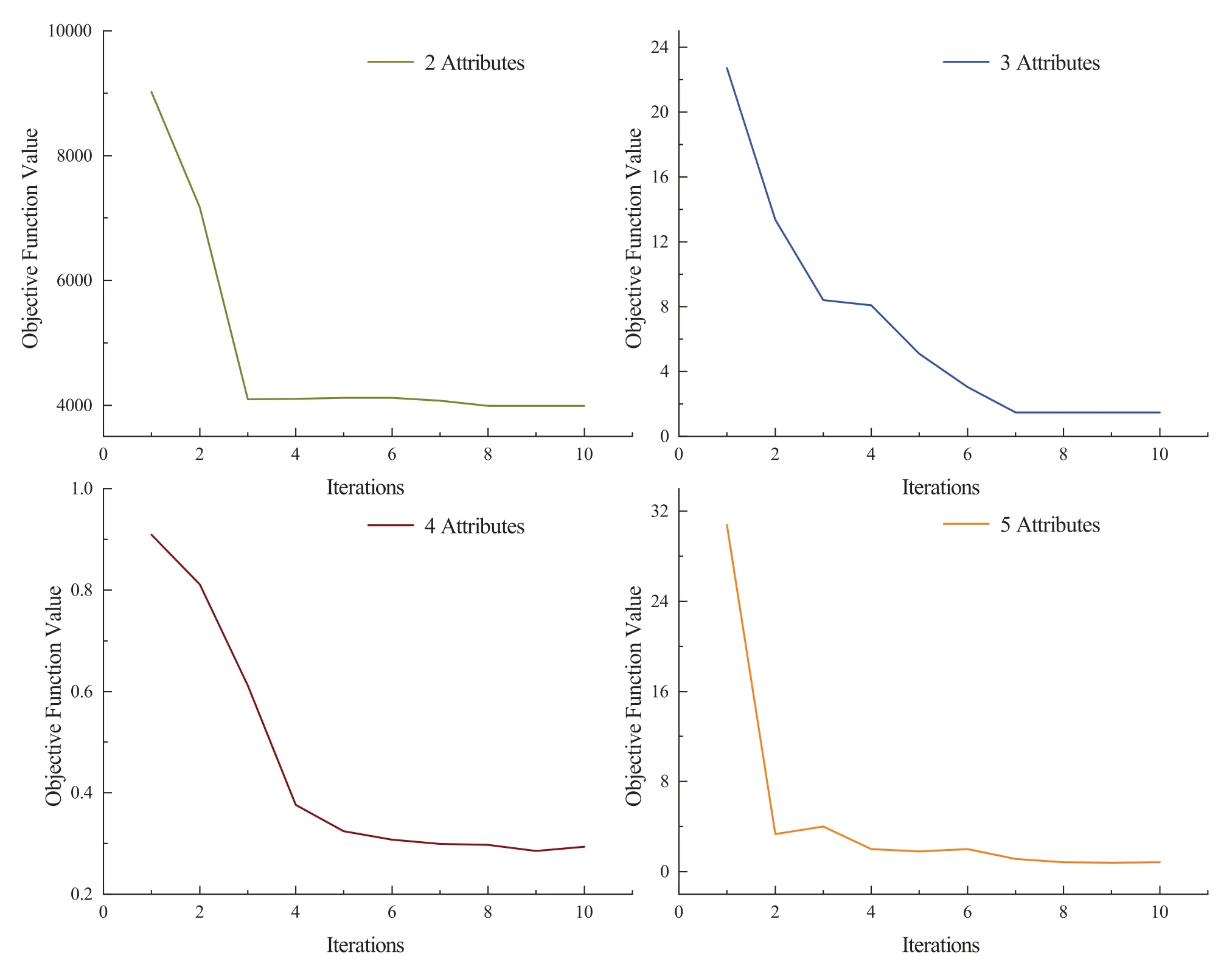
Figure 2:Objective function value in the iterative procedure
1) The steps of Experiment 1 are as follows:
①Use the neural network algorithm to train the training set and the validation set, and adopt the cross-validation method to obtain multiple neural network prediction models.
②Use MSE as an indicator to evaluate the predictive effect of each model, and select the optimal model.
③Apply the optimal model to the test set for prediction to obtain prediction results of the tunneling speed.
④Compare the prediction results of the tunneling speed with the target values to evaluate the prediction results of the neural network algorithm.2) The steps of Experiment 2 are as follows:
①Use the FCM-ANN algorithm to train the training set, so as to obtain the clustering results of the training set and their corresponding neural network prediction models.
②Use the FCM-ANN algorithm to train the validation set, then the clustering results of the validation set can be obtained.
③According to the clustering results of the validation set, the neural network prediction models obtained by the training set is used to predict each cluster of corresponding data, then the prediction results of the validation set can be obtained.
④Use the cross-validation method to repeat Steps 1-3, and use MSE as an indicator to evaluate the effect of each prediction, and select the optimal model.
⑤Use the FCM-ANN algorithm to train the test set, then the clustering results of the test set can be obtained.
⑥According to the clustering results of the test set, the optimal neural network prediction models are used to predict each cluster of corresponding data, then the prediction results of the tunneling speed can be obtained.
Tab.8 shows the comparison results of the MSE of the validation set obtained through cross-validation during the two experiments.According to the above steps, Experiment 1 and Experiment 2 are executed and we obtain 240 sets of data were respectively.Compare this with the target values and the results are shown in Figs.3 and 4.

Table 8:Comparison of Validation MSE
As can be seen from Fig.3, the differences between the target values and the predicted values of the tunneling speed are obvious.This indicates that the neural network algorithm cannot accurately predict the tunneling speed without the cluster.But in Fig.4, the target values of the tunneling speed show a good correlation with the predicted values.
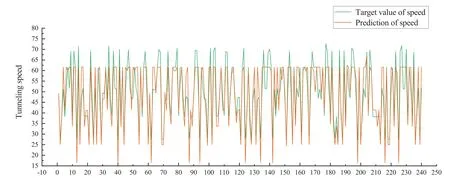
Figure 3:Correlation between predicted and target values (Experiment 1)
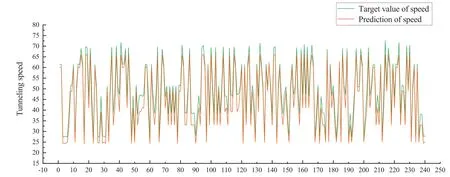
Figure 4:Correlation between predicted and target values (Experiment 2)
4.3 Comparison of Results
In this section, we use root mean square error (RMSE) and coefficient of determinationR2as statistical criteria to evaluate the performance of the algorithm.The root mean square error (RMSE) is a measure of goodness-of-fit that best describes the average measure of error when predicting a dependent variable.For a set of datay=(y1,y2,...yn), the result of regression prediction isTheRMSEcan be expressed as the form shown in Eq.(19).

The coefficient of determinationR2is also a measure of the goodness-of-fit.It can be used to test the error of the predicted dependent and target values at the variable level.Before describing the goodness-of-fit, several additional indicators, namely the population squaredTSS,the regression squaredESS, and the residual squared sumRSS, need to be introduced.


The value range ofR2is [0,1].The closerR2is to 1, the higher the goodness-of-fit.
In the prediction experiment of the tunneling speed, 8 independent experiments were performed, and theRMSEandR2indicators were calculated for each experiment.The results are shown in Figs.5 and 6.

Figure 5: RMSE indicator evaluation results
The results of Experiment 1 and Experiment 2 can be compared by the above figure.As can be seen from Fig.5, most of the RMSE values of Experiment 1 are much higher than Experiment 2, and the results of Experiment 1 varied so much that the maximum value reached 16.92.However, the results of Experiment 2 remain stable between 3.5 and 6.5.As can be seen from Fig.6, theR2of Experiment 1 vary so much that some negative values appear.But theR2of Experiment 2 are always maintained above 0.9.Therefore, according to the results of RMSE andR2, it can be concluded that the FCM-ANN algorithm can accurately predict the tunneling speed of TBM, and the effect is obviously better than the neural network algorithm.
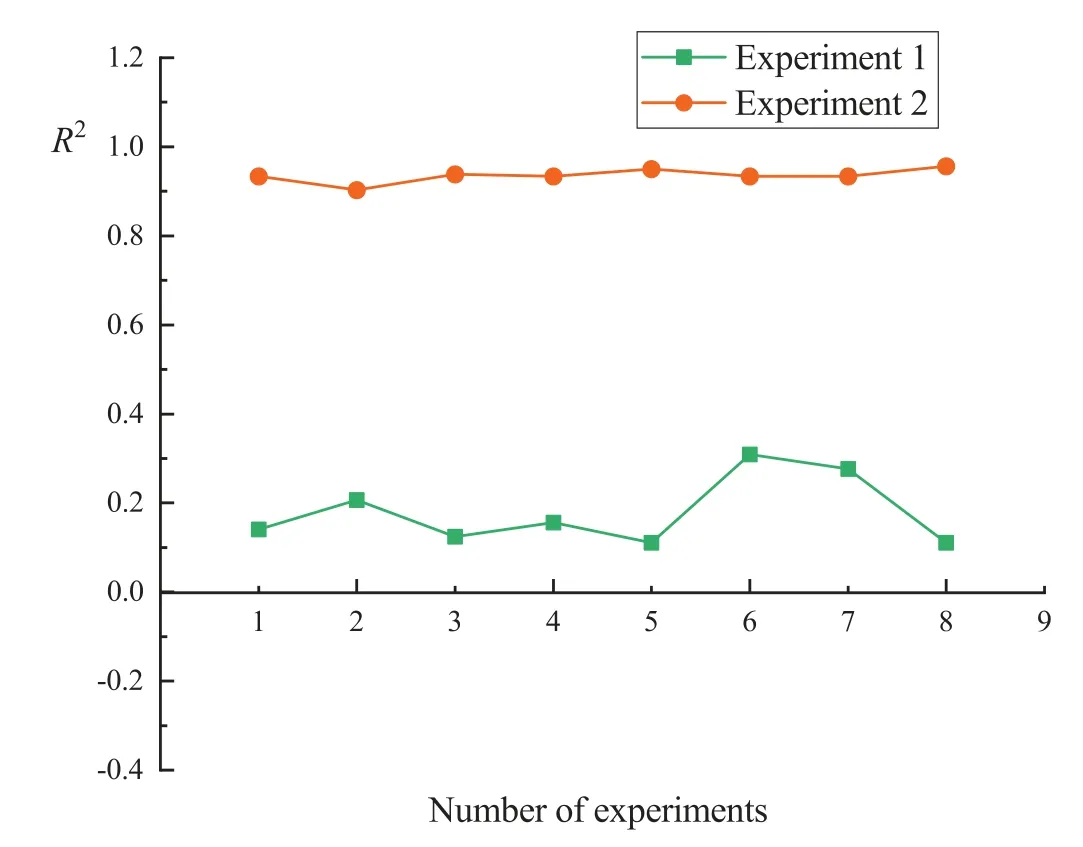
Figure 6: R2 indicator evaluation results
5 Conclusions
In this paper, we propose the FCM-ANN algorithm for functional data that is difficult to cluster effectively in traditional methods.The FCM-ANN algorithm is based on the FCM algorithm and uses the predicted value of artificial neural network as the clustering prototype to perform the iterative update of the algorithm.We first apply the algorithm to the synthetic datasets and discuss the effects of different number of samples, different number of attributes, and different noise on the clustering results under different membership thresholds.Then the algorithm is applied to the TBM operation data and compared with the method of modeling without clustering.The results show that the FCM-ANN algorithm can accurately and effectively predict tunneling speed.The future work will be mainly focused on replacing existing ANN models with more sophisticated neural network models while improving algorithm theory to make the iterative process more complete.
Funding Statement:This research is supported by the National Key R&D Program of China(Grant Nos.2018YFB1700704 and 2018YFB1702502) and the Study on the Key Management and Privacy Preservation in VANET, The Innovation Foundation of Science and Technology of Dalian (2018J12GX045).
Conflicts of Interest:We declare that we have no conflicts of interest to report regarding the present research.
Appendix A:Statistics of TBM Operation Data
Appendix A:(continued)Parameter (X21) (X22) (X23) (X24) (X25) (X26)(X27) (X28) (X29) (X30)Min.-4.31 0.00 1.47 1.30 1.59 1.51 1.37 0.22 30.53 0.00 1st quartile -4.09 0.02 1.68 1.48 1.76 1.67 1.60 2.15 39.84 0.00 Mean -4.03 0.04 1.92 1.54 2.21 2.10 1.70 2.57 41.20 0.00 3rd quartile -3.97 0.10 2.00 1.61 2.29 2.17 1.78 3.53 43.00 1.48 Max.-3.84 0.14 2.25 1.80 2.53 2.34 2.04 6.39 51.24 5.11 Parameter (X31) (X32) (X33) (X34) (X35) (X36) (X37) (X38) (X39) (X40)Min.0.00 0.00 0.00 1.22 1.44 1.69 1.15 0.52 1.20 0.00 1st quartile 0.00 0.00 0.00 3.18 3.97 3.82 3.26 2.28 1.37 18.39 Mean 0.00 0.00 0.00 12.47 5.70 5.36 5.17 2.70 1.70 25.99 3rd quartile 0.94 0.00 0.00 18.35 15.02 15.09 15.01 3.67 1.80 31.85 Max.5.12 0.00 1.49 74.67 61.05 48.54 43.46 5.89 2.04 53.75 Parameter (X41) (X42) (X43) (X44) (X45) (X46) (X47) (X48) (X49) (X50)Min.0.00 314.98 335.83 306.87 291.67 0.36 22.79 4.53 0.19 10099.52 1st quartile 3.00 685.91 720.30 702.94 683.34 8.21 35.54 23.89 0.20 14692.63 Mean 3.00 1086.51 1073.90 1040.60 1050.74 10.17 49.59 45.41 7.37 15640.34 3rd quartile 3.00 1334.75 1383.33 1368.67 1334.47 19.48 64.42 48.42 11.75 16340.86 Max.3.00 1805.12 1828.83 1795.89 1778.86 21.59 66.08 51.73 12.76 16967.07 Parameter (X51) (X52)Min.0.50 0.55 1st quartile 0.64 33.67 Mean 1.90 48.02 3rd quartile 2.06 60.31 Max.2.12 72.64
 Computer Modeling In Engineering&Sciences2021年1期
Computer Modeling In Engineering&Sciences2021年1期
- Computer Modeling In Engineering&Sciences的其它文章
- Estimating the Impact of COVID-19 Pandemic on the Research Community in the Kingdom of Saudi Arabia
- Mesoscopic-Scale Numerical Investigation Including the Influence of Process Parameters on LPBF Multi-Layer Multi-Path Formation
- A Meshless Collocation Method with Barycentric Lagrange Interpolation for Solving the Helmholtz Equation
- Multiquadric Radial Basis Function Approximation Scheme for Solution of Total Variation Based Multiplicative Noise Removal Model
- Hybrid Security Assessment Methodology for Web Applications
- Isogeometric Boundary Element Analysis for 2D Transient Heat Conduction Problem with Radial Integration Method