
采用最大均值差异和权重约束的服装识别迁移学习
2021-04-29 00:58钟跃崎
毛纺科技 2021年4期
王 鑫,钟跃崎,2
(1.东华大学 纺织学院, 上海 201620; 2.东华大学 纺织面料技术教育部重点实验室, 上海 201620)
服装图像识别是人工智能和深度学习图像识别的重要研究方向,现有研究的预测准确率已较高[1],例如在大规模服装识别数据集DeepFashion上, Liu等[2]提出的FashionNet网络结构将服装类型识别的Top-3准确率提高到83.58%。然而,使用深度学习模型在取得这样的预测性能同时,仍然存在2个重要问题:①模型训练对于数据的需求很大,例如DeepFashion数据集使用800 000张图像来训练FashionNet模型;②训练好的模型泛化性能不佳。换言之,训练好的模型在预测任务发生变化时通常不能继续使用。如当时尚季节所发布的新品不存在于原来的数据集时,原来的模型将无法被重复使用,只能重新训练。上述问题加大了深度学习模型在服装图像识别任务中的部署难度。
一个常用的解决之道是利用迁移学习[3-4]的思想,即从一个源域识别任务提取知识并向另一个相似的目标域迁移,从而提高目标域的预测性能,减少训练时间和训练样本的数量[5]。迁移学习要求源域和目标域的数据之间存在相似性,不相似的源域和目标域数据可能会导致目标域的识别任务性能下降,即“负迁移”现象[3]。在服装图像识别领域,由于DeepFashion数据集包含丰富的已标注图像,经常被用作迁移学习的源域,文献[6-7]将DeepFashion划分为不同子集进行迁移学习实验,但是这些工作实验中的源域和目标域图像在同一个数据集之中,真实的服装迁移学习需要训练不同来源的图像和更加不同的目标域。文献[6-7]使用权重初始化方法仅能设置模型的初始权重,并不能很好地建模训练完成源域和目标域模型的相关性。因此还需要深入探索不同服装数据集之间的迁移学习,同时尝试建立源域和目标域的相关性。
本文测试了多个公开服装数据集之间的迁移学习。为了建模源域和目标域的相关性,受文献[8]的启发,本文提出一个双分支网络模型,该模型分别为源域和目标域建立了一个完整的卷积神经网络分支,2个分支之间使用最大均值差异(Maximum Mean Discrepancy,MMD)来约束输出特征的分布差异,使用权重约束损失函数来约束模型权重的差异,2个网络分支的权重存在相关性,但是不完全相同。
1 数据集的选择
为了实现不同服装识别任务之间的迁移学习,本文使用多个公开的服装图像数据集,包括DeepFashion[2]、ACWS[9]、HipsterWars[10]、IDesigner[11],由于DeepFashion数据集标注丰富,因此实验中使用DeepFashion数据集作为源域,其他数据集作为目标域。源域和目标域的关系如图1所示,其中每个线框中左边为数据集图像示例,右边为数据集词云图像。可以发现DeepFashion数据集和ACWS数据集的预测标签更加类似,均为服装类别。而HipsterWars和IDesigner数据集中的预测标签为服装风格。
对于每个数据集的简要介绍如下:DeepFashion是最早提出的大规模服装图像数据集,其包含800 000张图像,每张图像包含服装类别、服装属性、服装区域边框标注。本文使用该数据集作为源域进行实验。
ACWS[9]是2012年提出的服装图像数据集,其包含15个服装类别。其中一些类别和DeepFashion重合,另一些类别则不相同。如图 1所示,ACWS的图像来源和DeepFashion没有较大差别。在实验中被用来验证在预测服装识别任务相似时,迁移学习能否有效帮助目标域服装识别的训练。

图1 服装识别迁移学习任务示意图
HipsterWars[10]是2014年公开的预测服装风格的数据集,数据集包含5种服装风格。服装风格识别和服装类型识别任务相似但不同,该数据集可以验证服装识别的不同子任务之间迁移学习的效果。
IDesigner[11]是2019年公开的关于服装设计师风格的数据集。该数据集收集了50个不同服装设计师作品的舞台展示照片,数据集中图像背景通常变化较小,着装人体姿势多为模特走秀姿势。
表1示出本文实验所使用数据集的图像数量和类别数量等数据的统计信息。可以发现:ACWS数据集的图像数量最多,但是缺乏服装属性标注,并且服装类别种类较少;而DeepFashion数据集的图像数量在一个数量级,且包含服装属性标注,并且拥有更多的服装类别标注种类,训练出的模型可以包含更多的信息向目标域进行迁移学习,因此实验中使用DeepFashion数据集作为源域。

表1 实验服装数据集统计信息
2 基于最大均值差异和模型权重约束的迁移学习方法
2.1 模型介绍
本文认为源域和目标域均为服装图像识别,任务之间存在相似性,因此网络模型的权重之间也应该存在相似性,同时输出的特征分布不应存在明显的分布差异[8]。有鉴于此,本文使用如图2所示的双分支网络结构,2个分支分别在源域和目标域上进行输入图像的卷积神经网络计算,2个支网络的输出特征使用MMD损失来减少数据分布间的差异,并通过权重约束损失来减少分支间权重的差异。
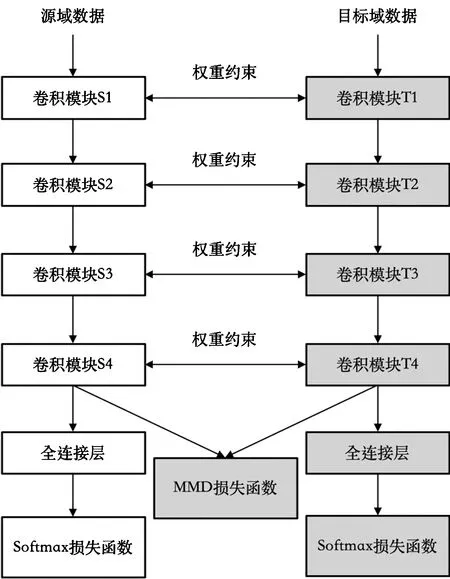
图2 用于迁移学习的双分支网络结构
本文使用的卷积神经网络为Resnet50[12],其网络结构可以分解为4个模块,对应图 2中源域网络的卷积模块S1至S4,和目标域中的卷积模块T1至T4。每个卷积模块的计算可以表示为xi+1=fi(θi,xi),其中θi为网络模型的参数,xi为输入的特征。最后一个卷积模块输出的特征经过全连接层后得到对应于各个类别的预测分数。卷积神经网络的参数通过最小化损失函数进行更新模型参数。在本文所用的迁移学习模型中,损失函数L包括用于分类的损失函数和用于迁移学习的损失函数:
L=Ls+Lt+λwLw+λrLMMD
(1)
式中:Ls和Lt分别为源域和目标域上的分类损失函数,对于单标签分类任务使用交叉熵损失函数,对于多标签分类任务使用多个二元分类损失函数;Lw为权重约束损失函数;LMMD为MMD损失函数;λw为损失函数值Lw的权重,λr为损失函数值LMMD的权重。
2.2 最大均值差异损失函数
最大均值差异[13](Maximum Mean Discrepancy,MMD)是一个衡量2个分布之间距离的度量方法。其将1个分布映射到1个再生希尔伯特空间(Reproducing kernel Hilbert space,RKHS)上,每个分布对应1个RKHS上的点,则2个分布的差异就可以用这2个点的内积来表示。

(2)
式中:φ(·)为1个到RKHS的映射,由于实践中该映射通常是未知的,因此可将上式展开,并利用核函数改写为如下形式:
(3)

2.3 权重约束损失函数
为了度量模型之间的相似性,使用权重约束损失函数Lw计算2个模型权重之间的差异。由于2个模型并非完全相同的任务,仅仅是相似的任务,因此不能简单地使用2个模型权重之间的差值,而应对一个模型的权重进行线性变化之后,再计算与另一个模型的差值:
(4)

2.4 训练细节

图3 混合数据采样示意图
源域和目标域的模型均采用DeepFashion数据集上预训练的模型进行初始化。在训练阶段,源域的网络分支和目标域的网络分支,其权重参数都会被更新。为了同时训练双支网络,在采样2个来源数据时采用混合数据采样的方法,如图3所示,数据源1和数据源2的数据依次交替采样,然后输入到2个网络,在数量较少的数据源(如图3中的数据源2)采样完成后即完成一个周期的训练。
实验中,将λr设置为1,λw设置为0.000 1,优化器采用随机梯度下降法,学习率为0.001,训练周期设置为50个轮次。硬件配置为英特尔处理器(Core i6500)和显存为12 GB的英伟达显卡(NVIDIA GTX 1080Ti)。
3 评价指标
对于单标签分类任务,评价指标采用准确率(Accuracy),即预测正确的样本数量(CorrectCount)占全部样本的(TotalCount)比例:
(5)
对于多标签分类任务,由于预测目标的真实值存在大量为0的情况,如果仅使用准确率作为评价指标,可能导致模型在将全部结果预测为0时依然取得很高的分数,因此这里采用的评价指标为TopN召回率(TopN Recall)和TopN准确率(TopN Accuracy)。召回率表示真值为1的样本被预测正确的比例,数值越高意味着更多真值为1的样本被正确预测,其公式表达为:
(6)
式中:TP为正阳性样本(真值为1,且预测值也为1),FN为负阴性样本(真值为1,但预测值为0)。本文分别使用了Top3召回率,Top5召回率,Top3准确率和Top5准确率。
4 迁移学习效果与讨论
4.1 迁移学习对目标域的影响
实验发现,MMD损失函数和权重约束损失函数同时使用的时候可以取得更高的预测效果。表2显示了目标域服装识别任务在不同迁移学习方法下的预测性能表现,其中每列使用的方案含义为:①使用ImageNet数据集[14]上的预训练模型初始化目标域模型;②使用DeepFashion数据集预训练模型来初始化目标域模型;③使用权重共享的多任务网络同时训练源域和目标域任务;④仅使用MMD损失函数的双分支网络;⑤仅使用权重约束损失函数的双分支网络;⑥结合MMD损失函数和权重约束损失函数的双分支网络。

表2 不同方法迁移学习后目标域的预测性能对比 %
通过观察可以发现,DeepFashion初始化方案下的表现未能超过ImageNet 初始化方案。尽管如文献[6-7]的结果所示,当源域和目标域为DeepFashion数据集不同的子集时,DeepFashion数据集上的预训练模型能有效提高预测表现,但是本文发现当源域和目标域为不同数据集的相似的服装识别任务时,这样的初始化带来的提升十分有限。由于ImageNet数据集预训练模型具备通用图像识别能力,因此用其作为模型初始化权重在服装图像识别上依然具有很好的适应性。
在权重共享的多任务网络方案下,所有模型预测性能大幅下降,这说明相似但是不同的服装图像识别任务需要提取不同的视觉特征。多任务网络约束了源域和目标域识别任务使用共同的特征提取器,然而结果显示,相同的特征提取器不能在不同的服装识别任务中取得更好效果。同时从表2还可以发现,对于更加相似的2个任务,如DeepFashion和ACWS,权重共享的网络带来的负面影响较小,但是对于源域为DeepFashion而目标域为Hipster或IDesigner时,其结果下降得更为明显,说明服装类别属性和服装风格所需视觉特征不完全一样。
表2后3列显示了单独添加MMD损失函数和权重约束损失函数时,均能有效提高目标域性能,二者叠加可以产生最好的结果。使用MMD差异和模型权重约束的双分支网络,以及多任务网络均包含2个分支,但是前者取消了共同的模型权重,使用了约束更小的损失函数来模拟2个任务的相关性。MMD损失函数约束了2个特征的分布差异,而权重约束损失函数则使得2个模型间的参数不要相差太大。从表2可以看出,这样的约束可以很好地适应不同服装识别任务的迁移学习。
4.2 迁移学习对源域的影响
实验中得出,使用MMD损失函数和权重约束损失函数的迁移学习不仅可以提高目标域服装识别的性能,对于源域服装识别也有帮助。如表3所示,仅使用卷积神经网络Resnet50在DeepFashion数据集训练后得到的服装类别准确率为67.45%,服装属性的Top3召回率为28.31%。如果使用多任务网络,在目标域为ACWS的情况下,源域上的预测性能有所下降但是差距不大,但是当目标域为任务相似性低的HipsterWars时,预测性能下降到60.58%,其原因是服装识别任务内部不同的子任务依然需要提取不同的特征。当使用基于MMD损失函数和权重约束损失函数的迁移学习方法时,由于强调源域模型和目标域模型使用完全一样的特征提取网络,故源域的网络预测性能不仅没有受到影响,反而略有提高,其原因在于迁移学习时所使用的MMD损失函数,同时会使用目标域数据继续训练源域的特征分布,源域在迁移学习时得到了更加充分的训练。

表3 不同方法迁移学习后源域(DeepFashion)的预测性能变化 %
5 结束语
本文使用包含MMD损失函数和权重约束损失函数的双分支网络来实现不同服装识别任务之间的迁移学习。通过与其他迁移学习方案进行对比得出,本文方案相对于其他方法可以提升2%的预测准确率。迁移学习后的Resnet50卷积神经网络模型在ACWS数据集上达到预测准确率69.01%,在IDesigner数据集上达到预测准确率91.18%。说明约束源域和目标域输出特征间的分布差异,以及减少2个模型之间的权重参数的差异,可以更好地完成服装识别的迁移学习任务。
此外,使用权重初始化的方法进行服装识别的迁移学习时,DeepFashion预训练模型不一定优于ImageNet预训练模型,说明通用图像识别任务对于服装识别仍有很好的适应性。而通过权重共享的多任务网络进行迁移学习时,对于相似但是不同的服装识别任务(如服装类别识别和服装风格识别)使用同样的卷积神经网络提取源域和目标域的特征将会导致性能严重下降。
猜你喜欢
今日农业(2022年15期)2022-09-20
心理学报(2022年5期)2022-05-16
计算机技术与发展(2020年11期)2020-12-04
当代陕西(2020年17期)2020-10-28
小天使·二年级语数英综合(2019年10期)2019-11-08
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
青年文学家(2015年29期)2016-05-09
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
