
农田灌溉用水量客观测算模型数据库研究
2021-04-27 07:03王高旭吴永祥
水利信息化 2021年2期
吴 巍 ,王高旭 ,吴永祥 ,张 轩 ,许 怡
(1.南京水利科学研究院,江苏 南京 210029;2.水文水资源与水利工程科学国家重点实验室,江苏 南京 210098)
0 引言
我国是一个水资源严重短缺的国家,水资源供需矛盾突出是可持续发展的主要瓶颈[1]。为应对水资源短缺问题,我国开始实行最严格水资源管理制度[2],开展考核的工作难点之一是行政区用水量的核算工作。在各行业用水量中,农业用水量所占比例最大,约占总用水量的 60%。但农业用水的考核却是其中最薄弱的环节,目前农业灌溉用水量监测计量率不到 40%。农业用水量统计信息的获取途径和方式多种多样,统计结果受主观因素影响大,造成农业用水总量数据不可靠且无法客观核定,影响了用水总量考核工作的公正性和有效性[3–4]。
近年来,我国各级水利部门加强了对农业用水的监测、计量和考核管理工作,但各地农业用水监测比例仍较低,主要采用定额法进行推算统计[5–6],农业用水总量不可靠且缺乏农业用水过程,难以核算,严重影响农业用水量控制考核工作的开展。相关学者提出基于彭曼—蒙特斯和田间水量平衡等公式测算农田灌溉用水量[7][8]4–11,可为复核农业用水总量提供参考和依据。
用水量管理是保障水安全的重要环节,用水量的统计和测算方法是基础,充分利用数据库等信息化手段提升供用水基础数据管理水平是国内外政府机构和研究学者的共识。澳大利亚统计局(ABS)在其官网上每年发布 Water Account[9],记录不同地区不同用水部门的供用水量,其中农田灌溉用水细分多个类型,包括苗圃花卉生产,以及蘑菇蔬菜、果树及坚果、谷物、其他作物种植的灌溉用水。美国国家地质调查局(USGS)设立了“Water Availability and Use Science Program”,自 1950 年以来,每 5 a 编制出版Estimated Use of Water in the United States[10],并且收集美国各州各行业的用水量数据存储在 MySQL 数据库中,研发了美国国家水信息系统(National Water Information System)[11],用于向大众发布用水量数据,其中包括农田灌溉需水量。欧盟统计局(Eurostat)建立了用水量数据库,并通过官网提供农田灌溉用水量查询功能。上述数据获取方式虽然仍是统计方法,但相关机构都在运用数据库对基础数据进行管理,促进了基础数据管理的规范性[12]。联合国粮食及农业组织(FAO)对外公布全球用水量数据,其中包括农田灌溉取水量和需水量,由于全球不同区域的统计数据完整性不一致,FAO 研发了农作物蒸腾模型,用于补全世界各地区的农田灌溉用水量数据,并且研发了粮农组织全球水与农业信息系统(AQUASTAT),用于管理和客观测算农田灌溉用水量数据[13]。因此研究农田灌溉用水量客观测算模型,一方面可以复核统计数据的合理性,另一方面可以弥补统计数据的不全面性。由于数据库技术既能支撑客观测算模型运行,同时也为数据管理和共享奠定基础,因此有必要对农田灌溉用水量客观测算模型数据库进行深入研究。
1 模型参数分析
运用土壤水量平衡法、彭曼—蒙特斯公式构建农田灌溉需水量的计算模型,公式如下:
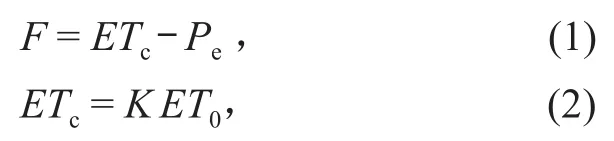
式中:F为单位面积灌溉需水量;ETc为作物需水量;Pe为有效降水量;ET0为参考作物需水量;K为作物系数。
相关参数分析如下:
1)参考作物需水量。参考作物需水量ET0的计算公式如下:

式中:Rn为作物表面上的净辐射;G为土壤热通量;T为 2 m 高处的日平均气温;u2为 2 m 高处的风速;es为饱和水汽压;ea为实际水汽压;Δ为饱和水汽压-气温关系曲线在T处的切线斜率;γ为湿度计常数。公式中各中间变量的计算方法参见相关参考文献 [8]。
2)作物系数。FAO 对标准状态下的作物系数推荐采用分段单值平均法表示[8]10–11,把作物系数的变化过程概化为几个阶段。对大多数一年生作物,作物系数按时间t的变化过程可概化为在 4 个阶段的 3 个值,变化过程线如图1 所示。4 个阶段的具体划分如下:a.生长初期,从播种到作物覆盖率接近 10%,此阶段内作物系数为Kini;b.快速生长期,从覆盖率 10% 到充分覆盖(大田作物覆盖率达到70%~80%),此阶段内作物系数从Kini提高到Kmid;c.生长中期,从充分覆盖到成熟期开始,叶片开始变黄,此阶段内作物系数为Kmid;4)生长后期,从叶片开始变黄到生理成熟或收获,此阶段内作物系数从Kmid下降到Kend。

图1 作物系数变化过程线
3)有效降水量。国内学者在有效降水量计算方面常采用经验公式法[14],计算公式一般为

式中:α为有效利用系数;P为实测降雨量。
2 模型数据需求分析
通过对农田灌溉用水量客观测算模型流程分析,结合现有数据情况,梳理模型所需的计算数据和数据流程,测算模型数据流程图如图2 所示。

图2 测算模型数据流程图
测算模型数据计算步骤如下:
1)计算参考作物蒸发蒸腾量。通过中国气象数据网可获取研究气象站点逐日的平均气压和风速,日最低和最高气温,平均相对湿度和日照时数,其中中国地面气候资料日值数据集(V3.0)的数据能够满足计算需求。在平均气压等数据的支撑下,经过中间变量计算,运用式 (3) 计算出参考作物蒸发蒸腾量,为计算实际农作物蒸发蒸腾量奠定基础。
2)计算实际农作物蒸发蒸腾量。结合不同地区不同作物的作物系数,参考作物蒸发蒸腾量,通过式 (2) 计算实际农作物蒸发蒸腾量。
3)计算有效降雨量。结合逐日降雨量,设置合理有效利用系数,运用式 (4) 计算有效降水量。
4)计算实际农作物灌溉需水量。结合计算得到的实际农作物蒸发蒸腾量、有效降雨量,运用式 (1)计算单位面积灌溉需水量,乘以农作物种植面积得到区域作物灌溉需水量。
经过分析,将农田灌溉用水量客观测算模型数据分为以下 4 种类型:
1)基础信息。实际测算过程中,为了更为精细化地测算农作物灌溉需水量,通常对区域进行分区处理,每一块分区被称为计算分区。基础信息包括气象站点的基本情况、计算分区情况及农作物类型,明确给出模型计算涉及的所有对象和信息。
2)基础数据。基础数据是模型计算所需的数据,包括气象站点数据、作物系数、农作物面积等,与基础信息中确定的对象密切相关。
3)关联数据。关联数据是为了应对精细化农作物灌溉需水量测算对数据之间的关联提出的更高要求的数据。关联数据使得计算分区和气象站点间形成有机的联系,气象站点与计算分区有对应关系。需要提出的是:作物种类、计算分区与作物面积和系数之间同样存在着此类关联关系,将通过外键的形式表述关联关系。
4)结果数据。结果数据是需水量测算结果。鉴于模型时间尺度,测算结果以日为单位进行存储,可通过对测算结果进行统计分析得出更为丰富的结果,为后续研究提供数据基础。
通过对测算模型数据的分析,数据具有以下几个特点:
1)数据类型多,涉及到气象、社会经济、农业等多个领域,数据结构差异性较大。
2)数据量繁杂,不同计算分区内种植的农作物种类繁多,日尺度的气象站点数据庞杂。
3)数据间的关联复杂,计算分区与气象站点间,计算分区与农作物种类和种植面积间,具有一对多、多对多的对应关系。
4)计算量大,随着复核区域扩大及对复核精细化的要求,计算分区不断增加,导致重复计算工作量增加。
这些特点对模型的计算和数据管理提出了更高的要求,数据的组织方式必须过渡到数据库方式,保证数据的规范性和一致性,刻画数据间的关联关系,提高数据检索速度,并支撑农田灌溉用水量测算模型。因此亟需探索适用于农田灌溉用水量测算模型的数据库建设方案,建立鲁棒性强、可扩展性高的数据库。
3 数据库设计与应用
3.1 表结构设计
按照表结构及标识符设计原则与约定,以数据需求分析中梳理的表为对象,确定表的编号、标识和名称,设计的 8 个表的编号和标识如表1 所示,其中作物分类表、计算分区表、气象站点表为基础信息表,气象站点数据表、作物种植面积表及系数表为基础数据表。
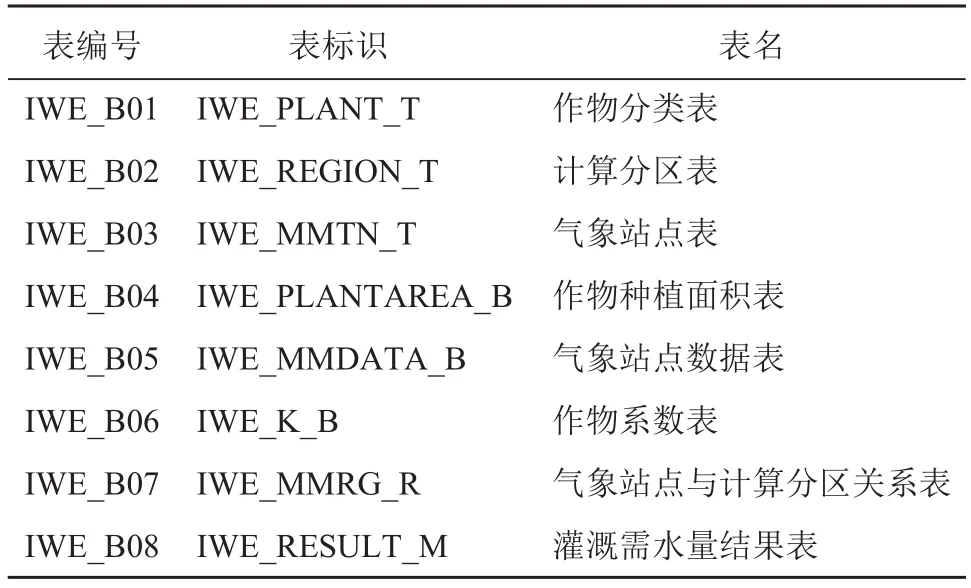
表1 表的编号和标识
选用 MySQL 数据库进行表结构的详细设计,各数据库表结构及其相互间的关联关系如图3 所示。
3.2 数据库应用
以表结构详细设计为基础,结合 MySQL 数据库,建立农作物灌溉需水量测算模型数据库。在汉江上游流域开展数据库应用,依据水资源分区嵌套县级行政区分析方法,将汉江上游划分为 60 个计算分区,筛选出 23 个与汉江上游有关的气象监测站,选择汉江上游 13 种主要农作物进行计算。收集2015 年的相关数据,并整理入库,建立汉江上游农田灌溉用水量客观测算数据库,基于数据库进行模型运算,将整年的用水量测算数据汇总到各个县,客观测算结果如图4 所示。汉江上游实例表明:
1)数据库的应用提升了对相关数据管理的能力,汉江上游年度测算涉及到 23 个气象监测站逐日监测数据,60 个分区中 13 种主要农作物逐日灌溉用水量结果等大量数据,数据库的应用便于业务人员进行数据查询及维护。
2)数据库的应用增强了农田灌溉用水量客观测算业务流程性,在基础数据准备到位的前提下,可复核任一时间区间、任一汉江上游区域的农田灌溉用水量。并且由于数据库的通用性,在汉江上游的应用极易扩展到全国范围,具有一定的推广应用价值。
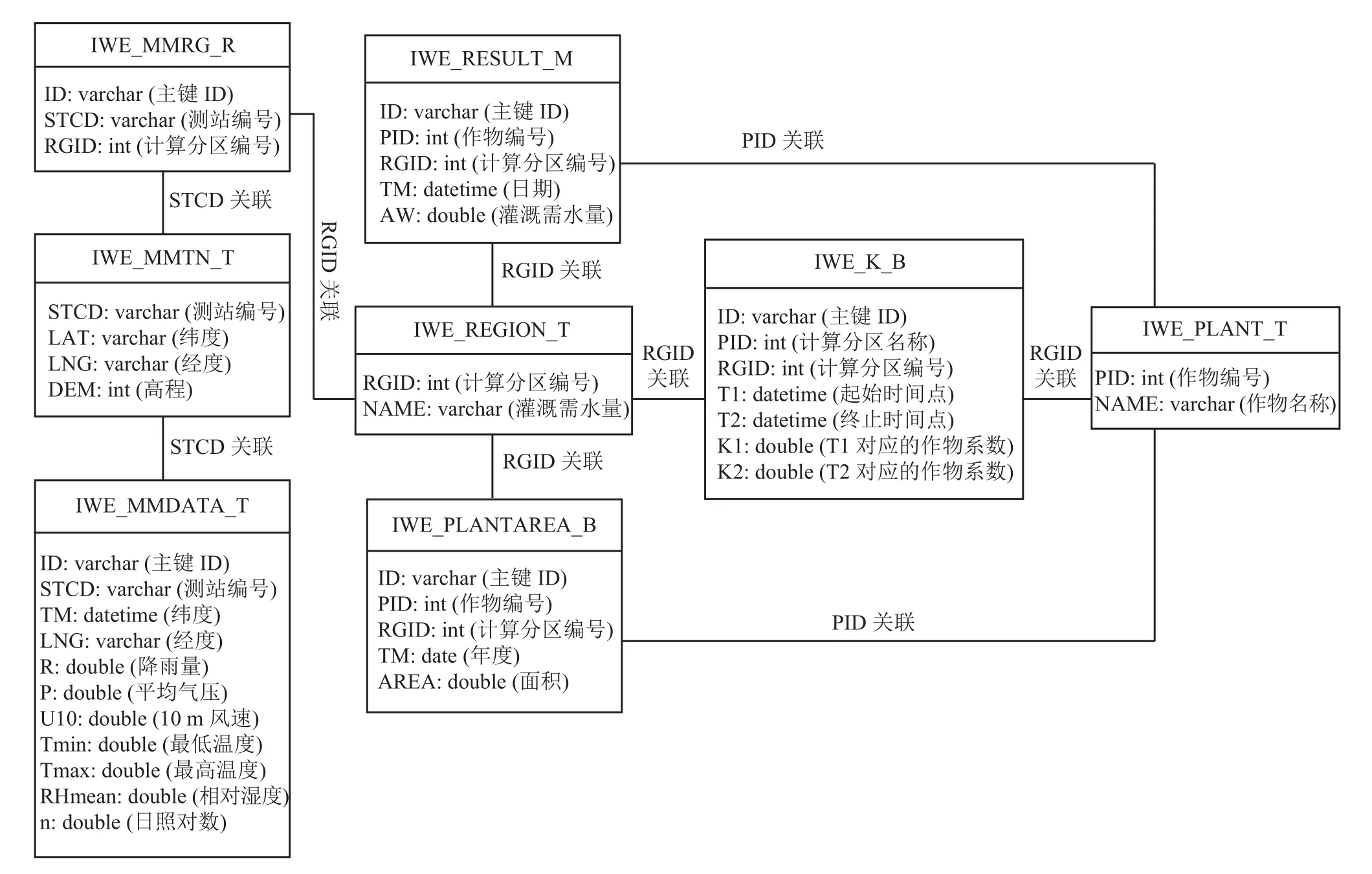
图3 数据库表结构及关联关系
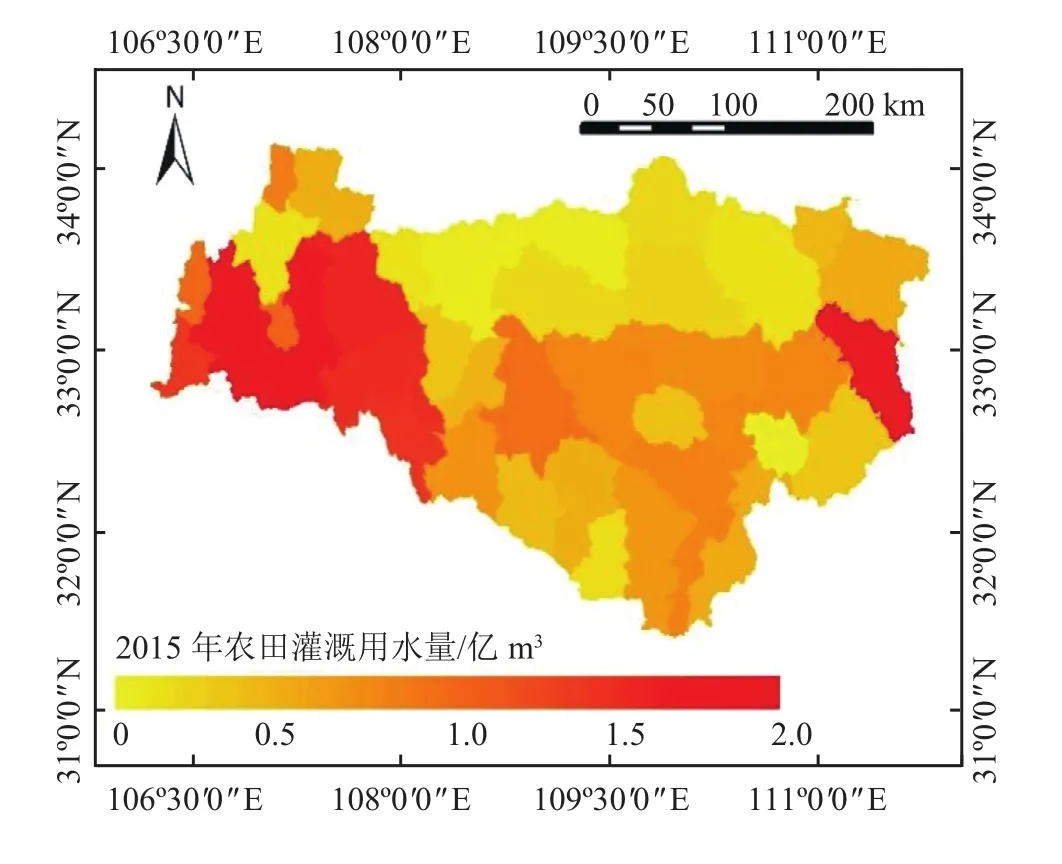
图4 汉江上游农田灌溉用水量客观测算结果
4 结语
本研究在充分探究农田灌溉用水量客观测算方法的基础上,提出数据库设计思路,主要应用于数据管理和支撑模型自动化运行,具体成果如下:
1)为应对农田灌溉用水量测算模型数据随着时间和空间增长的情况,构建了农田灌溉用水量测算模型数据库,保障了数据的一致性和规范性,为农田灌溉用水复核数据管理奠定了坚实的基础。
2)将农田灌溉用水量测算模型数据库设计思路应用于汉江上游,能够快速测算汉江上游农田灌溉用水量,并且有效地对测算结果进行时间和空间上的汇总分析,表明数据库可有效地支撑农田灌溉用水量测算模型。
降雨和种植面积在实际中均为空间分布,分布式农田灌溉用水量客观测算结果有助于提升核算准确性,能够较为精准地定位核算差异较大的区域。因此,后续将在本研究基础上拓展适应于分布式农田灌溉用水量客观测算的空间数据库研究,进一步提升农田灌溉用水量核算水平,为最严格水资源制度考核提供更为可靠的技术手段。
猜你喜欢
水土保持通报(2022年3期)2022-10-15
小学科学(学生版)(2021年5期)2021-07-22
小学科学(2021年5期)2021-06-24
黑龙江气象(2021年1期)2021-05-28
中国交通信息化(2020年5期)2021-01-14
今日农业(2020年14期)2020-12-14
环境影响评价(2020年2期)2020-12-02
环境保护与循环经济(2020年7期)2020-09-08
山东交通科技(2020年1期)2020-07-24
北京汽车(2018年5期)2018-11-07
