
利用深度学习实现腹盆部CT图像范围及期相分类:临床验证研究
2021-04-26 01:51孙兆男崔应谱刘想张晓东王霄英刘伟鹏王祥鹏黄嘉豪
放射学实践 2021年4期
孙兆男, 崔应谱, 刘想, 张晓东, 王霄英, 刘伟鹏, 王祥鹏, 黄嘉豪

表1 腹盆部器官各期增强扫描的延迟时间 (s)
在传统影像诊断模式中,某些疾病的诊断需基于特定期相或序列,如脂肪肝的CT诊断需测量平扫图像的肝实质密度,肾结石检出在平扫图像上较敏感,怀疑肝细胞肝癌需关注动脉期及门脉期的强化方式等。因此获取合格的图像是进一步完成影像诊断任务的前提,扫描期相不准确和扫描范围不足等图像质量问题有可能影响疾病的诊断,是医学影像质控的关注点之一。
人工智能(artificial intelligence,AI)是一种模仿人类思维方式的技术,在训练AI模型时,研究者通常基于传统影像诊断经验,针对不同任务收集特定扫描时相及扫描范围的图像[1-2]。由于真实临床工作中机型多样、命名规则冗杂和扫描方案差异等因素,缺乏有效的整理方法,即特定AI任务相关的患者队列选择,这是AI模型的主要瓶颈之一。AI辅助诊断软件在实验阶段效能很好,但临床验证过程中,发现许多模型预测错误的病例是由于图像质量不合格导致的[3],而提升图像质量会明显提高模型效能。因此,亟需高效的方法筛选出满足临床应用场景的图像,去除无关的冗余图像。无论是医生承担的传统影像诊断任务还是基于AI模型的辅助诊断,其共性需求是提供合格的图像[2]。本研究目的是研发腹盆部CT图像扫描期相及范围AI分类模型,并利用对模型进行临床验证,探索其植入临床实践流程的可靠性。
材料与方法
本研究获得了伦理审查委员会的批准(2017-1382),按照本单位AI模型训练规范执行研究方案。
1.用例定义
根据本单位AI训练管理方法,首先定义研发腹盆部CT图像范围分类模型的用户样例(use case),内容主要包括腹盆部CT图像性质分类AI模型的ID、临床问题、场景描述、模型在实际工作中的调用流程及模型输入输出数据结构等。AI模型返回结果的定义:图像范围模型返回结果为“腹部”或“盆部”或“腹盆部”;扫描期相模型的返回结果为“平扫”或“动脉期”或“门静脉期”或“延迟期”或“排泄期”。
2.研究队列的建立
本研究图像来源于本院放射科4台CT扫描仪:Siemens Somotom Definition Flash CT,GE Lightspeed VCT,Philips Brilliance 256 iCT和GE Disco-very CT750HD。腹盆部CT增强扫描各期相延迟时间的确定采用自动跟踪触发和固定时间两种模式。使用自动触发扫描模式时,触发点设置在第12胸椎椎体水平的腹主动脉内,触发阈值为100 HU;固定时间扫描模式中,不同目标脏器的增强扫描方案均按临床规范执行,详见表1。其它扫描参数:120 kV,自动毫安秒,螺距0.600~0.984,采集层厚5.0 mm,重建层厚1.0 mm,矩阵512×512,对比剂为碘佛醇(350 mg I/mL),注射流率4.0~5.0 mL/s,注射剂量为0.5 gI/kg或采用固定值90 mL,随后注射20 mL生理盐水冲管。
研究数据的分组情况详见图1。模型训练数据集(数据集A)为回顾性搜集2019年10月14日-2019年10月18日本院PACS中连续416例行腹盆部CT平扫及增强检查患者的所有图像。临床验证数据集(数据集B)为2020年1月1日-1月3日本院连续268例患者的腹盆部CT平扫及增强检查图像。
按照临床实践规则,将图像范围分为三个类别,三个类别的定义如下。腹部:从膈面到髂嵴,肝脏可见,膀胱未见;盆部:从髂嵴到盆底,膀胱可见,肝脏未见;腹盆部:从膈面到盆底,肝脏、膀胱均可见。
不同目标脏器的检查方案略有差异,按照定义规则将扫描期相分为5个。平扫:任何器官均不含对比剂;动脉期:腹主动脉、肝动脉明显强化,脾脏呈“花斑样”强化,肾脏皮髓质界限清晰,门静脉可有对比剂,肝静脉没有对比剂;门静脉期:门静脉、肝静脉可见对比剂充盈,肾脏皮髓质界限不清晰,脾脏均匀强化无“花斑样”;延迟期:主动脉无明显强化,肾实质均匀高密度,肾盂有少量对比剂,输尿管可有对比剂,膀胱内小于1/3对比剂,肝脉管结构模糊;排泄期:集合系统可见对比剂充盈,膀胱内对比剂大于2/3其余器官未见对比剂。

图1 研究队列的数据分组情况。
3.数据处理
将训练数据图像导入数据管理平台,将DICOM格式转换为NIFTI格式,按照图像大小将1.4M以下图像排除,以去除定位像、跟踪触发图像和重组图像等无效图像。
4.模型训练
训练腹盆部CT扫描范围及期相分类模型时,将416例数据随机分为训练集(train set,)332例、调优集(validation set)42例和测试集(test set)42例。输入图像的窗设置为窗宽300 HU、窗位30 HU,图像大小为96×128×128,输出数据为对模型分类的预测结果。图像扩增方法包括±10°以内的水平及垂直旋转,上下、左右随机平移的最大幅度为图像大小的10%和体素值上下浮动万分之一的随机噪声(0.0001)。训练3D-ResNet深度学习模型时,硬件为GPU NVIDIA Tesla P100 16G,软件包括Python3.6、Pytorch 0.4.1、Opencv、Numpy和Simple-ITK[4]。使用Adam作为训练优化器。模型训练时批尺寸(batch size)设定为40,学习率(learning rate)为0.001,训练迭代次数设置为300个周期(epoch)。
5.模型的临床验证
临床验证数据集(数据集B)为268例患者的657个序列的腹盆部CT图像。模型自动预测得到分类结果,以两位影像医师的分类结果为金标准,使用混淆矩阵进行模型分类结果与真实值的比较。
结 果
1.扫描范围分类模型在数据集B中的预测结果
以扫描序列为单位统计,表2为扫描范围分类模型在数据集B中的预测结果。分类模型在腹部、腹盆部和盆部的符合率分别为95.7%(243/254)、98.4%(362/368)和94.3%(33/35)。分类正确的638个序列均是执行标准扫描规范的图像,19个序列的分类结果为未知类别,均是由于扫描范围不足或过多所导致,具体情况:6个腹盆部序列的图像由于扫描范围下限不足,未包全膀胱及耻骨联合;2个盆部序列的图像为同一患者的薄层及厚层图像,由于扫描范围整体上移,未包全膀胱及耻骨联合;11个腹部序列的图像由于扫描范围过大,扫描范围内包括了部分盆腔(图2)。
2.扫描期相分类模型在数据集B中的预测结果
扫描期相分类模型在数据集B的腹部图像中的预测结果见表3。扫描期相分类模型在平扫、动脉期、门静脉期的符合率分别为100.0%(77/77)、97.6%(82/84)和100.0%(11/11),腹部图像中无延迟期和排泄期图像。对172个腹部扫描序列的图像进行分析,170个序列分类正确,2个序列将动脉期误判为门静脉期,此2个序列为同一例患者的动脉期薄层及厚层图像,模型均预测错误。
扫描期相分类模型在数据集B的腹盆部图像中的预测结果见表4。扫描期相分类模型在平扫、动脉期、门静脉期、延迟期和排泄期的符合率分别为96.6%(144/149)、100.0%(9/9)、100.0%(106/106)、66.7%(44/66)和100.0%(32/32)。对362个腹盆部扫描序列进行分析,333个序列分类正确,模型对平扫序列的分类效能较好。误判情况分析:仅4个平扫序列误判为排泄期,其中2个序列为腹主动脉及分支弥漫粥样硬化,1个序列是在前者基础上合并腹部术后金属伪影,另外1例为标准的平扫图像;1个平扫序列被误判为动脉期,分析原因为腹主动脉及分支弥漫粥样硬化及腹部术后金属伪影。模型对延迟期图像的分类效能欠佳,仅44个序列分类正确,误判情况分析:1个序列被误判为排泄期,分析发现图像采集时间稍晚于标准延迟期,膀胱内可见小于1/3对比剂;21个序列的图像被误判为门静脉期,其中11个图像采集稍早于标准延迟期,另10个序列为标准延迟期,模型分类错误。
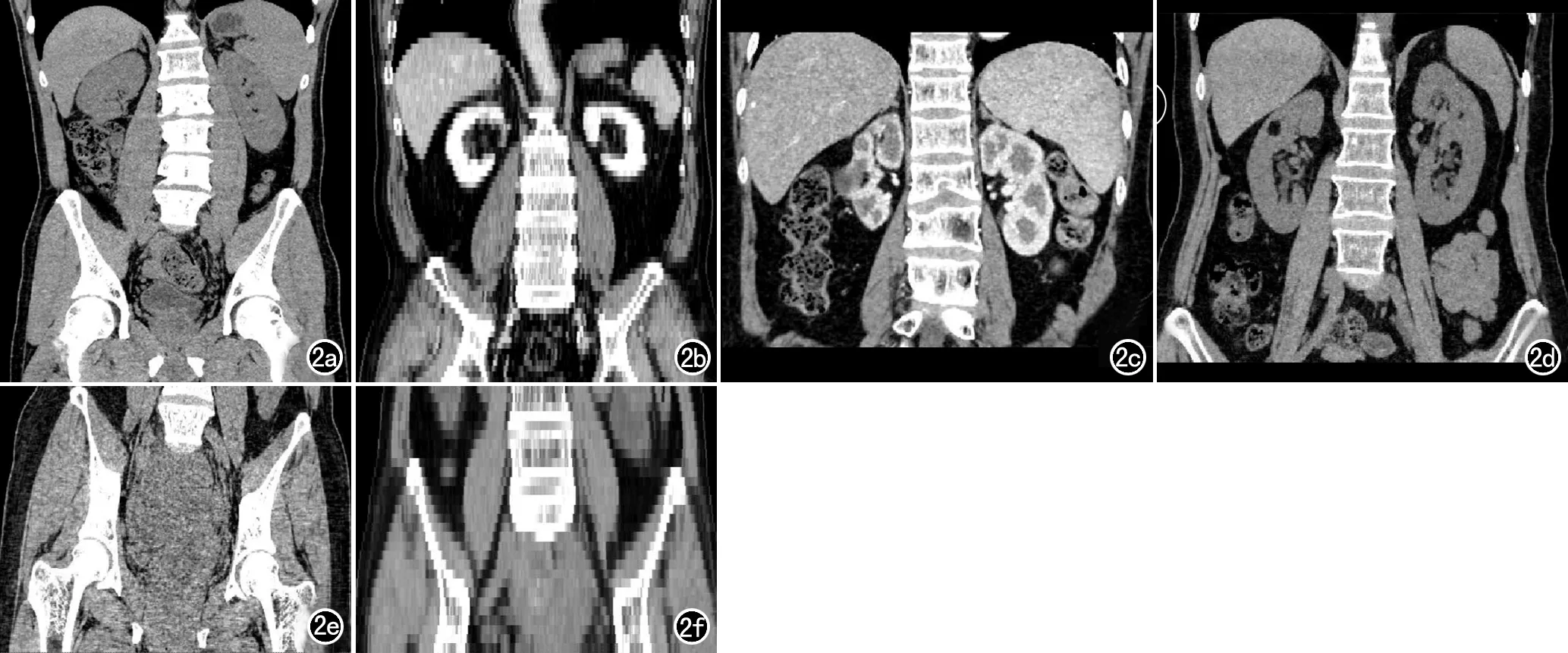
图2 数据集B中模型预测结果为未知类别的三种情况。a)正常腹盆部扫描范围;b)测试集中腹盆部图像(层厚5mm)的扫描范围下限不足,未包全膀胱及耻骨联合;c)正常腹部扫描范围;d)测试集中腹部图像的扫描范围过大,包括了部分盆腔;e)正常盆部扫描范围;f)测试集中盆部图像(层厚5mm)的扫描范围整体上移,未包全膀胱及耻骨联合。

表3 扫描期相分类模型在数据集B腹部图像中的预测结果

表4 扫描期相分类模型在数据集B的腹盆部图像中的预测结果
扫描期相分类模型在数据集B的盆部图像中的预测结果见表5。扫描期相分类模型在平扫、门静脉期、延迟期和排泄期的符合率分别为100.0%(13/13)、70.0%(7/10)、88.9%(8/9)和100.0%(1/1),盆部图像中无动脉期图像。对33个盆部序列的图像进行分析,29个序列分类正确,3个门静脉序列被误判为延迟期,1个延迟期序列被误判为门静脉期。

表5 扫描期相分类模型在数据集B的盆部图像中的混淆矩阵
讨 论
利用AI提升医学影像服务全流程的安全、质量和效率是其临床应用的方向。目前已有很多研究报告了深度学习和影像组学工具在病灶分割[5]、疾病分类[6]和预后预测[7]中发挥了较好的作用,而且在临床工作中可将多个诊断模型组成AI诊断系统植入到影像报告流程中[8],提升诊断任务的工作效率,并提升诊断诊断率。本研究不是从影像诊断角度利用AI工具,而是探索了AI对图像质量的应用可能性,目的是提高AI诊断模型输入数据的质量,以保证AI诊断模型的达到较高效能。
腹盆部CT由于检查费用低、成像速度快和密度分辨率高等优势,在我国各级医院广泛开展,在影像科整体工作量中占比较高。数据是人工智能的最核心和最关键的组成部分,CT检查数据量是相当可观的,有效分类管理这些数据是当前需要解决的问题。本研究基于深度学习方法建模,对腹盆部CT图像做出扫描范围与期相的分类,临床验证结果显示,模型对分类任务的准确性可基本达到临床需求。这与近期研究结论相似[9],该研究表明不同的网络结构对于CT期相多分类任务均表现出较好的分类效能。利用深度学习自动分类前列腺MR图像序列研究亦有相似的结论[10]。本研究中对于扫描规范合格的图像,扫描范围分类模型效能很好,而对于扫描范围过多或不足的图像,模型会分为未知类别,以将非标准范围的图像筛选出来。综合分析扫描期相分类模型,腹盆部图像的门静脉期和延迟期两类的分类效果欠佳,分析原因为个体循环差异、扫描时间差异等原因,导致图像本身特征差异不明显,其余期相分类效能较好。
临床中执行规范的腹盆部CT扫描协议,理论上所产生的图像应该是符合规范的,可以通过RIS中既定筛选条件及PACS中的DICOM Tag收集目标图像。但实际工作中,由于命名规则不统一、机器型号不同、特殊病例的个性化扫描等潜在原因,存在真实图像与扫描规范要求匹配不一致情况。临床工作或科学研究时涉及图像收集的任务时,往往先通过既定条件从RIS中筛选目标检查项目,再通过医生阅图分类,使图像分类整理任务繁琐。腹盆部CT图像性质自动分类模型可辅助解决上述问题,简捷、高效地完成腹盆部目标图像的筛选任务,并且可服务于后续其他AI诊断模型,保证输入合格图像,不合格的图像则无法进入AI模型,而由医师诊断,以得到真实可靠的预测值。
在临床实际工作中,由于扫描技师个人失误、患者配合欠佳等特殊情况,使得扫描范围不合规范或扫描期相采集不准确,往往是诊断医生发现图像质量不合格后,反馈给技师和患者进行补扫或加扫图像,整个沟通时间长且容易产生医疗纠纷。未来腹盆部CT图像性质自动分类模型可植入临床工作流程中,在扫描完成时立即判断图像质量是否合格,如果不合格,可通过AI模型修正或提升图像质量[11],也可通过信息系统实时反馈给技师,实现快速沟通,以便采取相应措施补救,降低甚至规避临床风险[12]。
本研究存在一定局限性。腹盆部CT图像性质多分类模型在实际应用中配合其他数据预筛方法共同完任务,并不是单独承担所有数据处理工作。首先是对于一项检查所产生的所有图像数据进行预筛。一项检查会产生部分对图像诊断无效图像数据,比如去除定位像、跟踪触发图像和重组图像等,经统计,这些图像在NIFTY格式下文件大小通常小于1.4M,当前临床数据首先通过图像大小滤过小于1.4M的无效数据,再输入模型,临床验证时发现此方法不能完全达到目的,存在极少数大于1.4M的无效数据没有被过滤,输入模型后导致模型诊断效能受一定影响,未来可叠加其他方式做图像预筛,是后续研究内容之一。
腹盆部CT图像性质自动分类只是图像质控方面的一个小分支,未来从患者登记、扫描、判断最佳扫描方案、扫描参数设定、图像质控、图像诊断、结构化报告等各个环节都有可能通过AI辅助全流程[14]。在这个过程中,AI不仅可用于分析图像,而且分析文本信息,结合多种信息做出辅助决策,从而实质性地改变医学影像工作流程[15-16]。
综上,以3D-ResNet为基础架构的多分类模型效能是临床可接受的,模型植入临床工作流程可行,未来应进一步推广临床验证。
猜你喜欢
现代仪器与医疗(2022年3期)2022-08-12
中国典型病例大全(2022年13期)2022-05-10
昆明医科大学学报(2022年1期)2022-02-28
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
