
一种基于图注意力网络的异质信息网络表示学习框架
2021-04-25 01:45康世泽吉立新张建朋
电子与信息学报 2021年4期
康世泽 吉立新 张建朋
(战略支援部队信息工程大学 郑州 450001)
1 引言
异质信息网络为具有多种类型(类型数量大于1)节点或边的复杂网络[1]。学术领域广泛研究的异质信息网络有两种:(1)具有简单模式层的异质信息网络;(2)具有复杂模式层(本体层[2])的知识图谱。异质信息网络中不同类型的边与节点使其蕴含丰富且复杂的语义信息,这为对其进行表示学习带来了挑战。
简单模式层的异质信息网络与知识图谱通常遵循不同的表示学习方法。之前主流的知识表示模型为TransE[3]及其相关变体。近年来又有基于卷积神经网络[4]或图神经网络[5]的知识表示方法。而简单模式层的异质信息网络大多基于元路径捕获网络结构信息以实现表示学习[6,7]。
上述表示学习方法的不同是由两种网络的差异造成的,具体表现在:(1)知识图谱的关系信息更加复杂。常用的异质信息网络在两个实体节点之间通常仅存在一种类型的边,而知识图谱中两个实体节点之间可以存在多种类型的关系。(2)两种网络面向的任务不完全相同。知识图谱面向的任务偏向推理,而简单模式层的异质信息网络面向的任务偏向分类。
为了同时表征知识图谱和简单模式层的异质信息网络,本文提出一种基于图注意力网络的异质信息网络表示学习框架。该框架可以分为3部分:基础向量部分,传播模型部分和任务模型部分。其中基础向量用于训练网络的基础向量,传播模型用于学习网络中的高阶信息,而任务模型用于执行不同的任务。本文的贡献如下:
(1) 本文对简单模式层的异质信息网络和知识图谱进行了异同点的总结,并提出了一种通用的异质信息网络表示学习框架,该框架既可以应用于知识图谱也可以应用于简单模式层的异质信息网络。
(2) 本文在多个数据集进行了广泛的实验。实验结果表明,本文所提模型与基准模型相比可以取得相对不错的效果。
2 定义
定义1(3元组) 给定一个异质信息网络G =(V,E),本文将每组节点 v1, v2和它们之间直接相连的边r定义为一个3元组( v1,r,v2)。 对于知识图谱,v1是头实体 ,v2是 尾实体,r 为两个实体之间的关系。
3 模型
本节详述基于图注意力网络的异质信息网络表示学习框架(HINs Embedding framework via Graph Attention Network, HE-GAN),该框架包括基础向量(b a s i c v e c t o r)部分,传播模型(propagation model)部分,以及任务模型(prediction)部分。本文引入Conv-TransE对知识图谱执行链接预测任务,构成面向链接预测任务的表示学习模型(HE-GAN toward Link Prediction, HE-GANLP)。本文通过将任务模型设计成节点分类模型,构建面向节点分类的表示学习模型(HE-GAN tow ard Node Classification, HE-GAN-NC)。
3.1 基础异质信息网络向量
基础向量用于保持网络的基础结构信息。本文采用在知识图谱领域广泛使用的TransE模型学习知识图谱的节点向量和边向量。由于简单模式层异质信息网络中直接相连的两个节点间仅存在一种边,本文认为这些边没有丰富的语义信息。因此本文没有学习简单模式层的异质信息网络的边向量,而是采用欧氏距离作为度量保留网络中的1阶和2阶相似度。
3.1.1 简单模式层异质信息网络的基础向量
对于图G任一3元组( v1,r,v2),其对应的向量为v1, v2(v1, v2∈Rn)。本文采用欧氏距离为该3元组建模

本文旨在最小化现有3元组对应分数函数的距离,因此定义基于间隔的损失函数


3.1.2 知识图谱的基础向量
对于知识图谱 G 中的任一3元组( v1,r,v2),其对应的向量为v1, v2和 r。本文采用TransE为该3元组定义的分数函数为
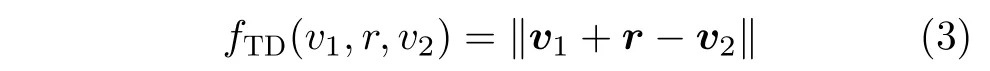
对于知识图谱中的所有3元组,本文定义基于间隔的损失函数

其中, Dr是 关系r对应的正3元组集合,是其对应 的负3元组集合。
3.2 传播模型
文献[5,9]中的结果证明通过图神经网络融合高阶的邻居信息可以提高知识图谱链接预测任务的性能;文献[7]也通过使用图注意力网络融合高阶邻居信息提升了异质信息网络的分类性能。本文借鉴这些方法[5,7,9]提出了一种既可以融合知识图谱高阶邻居信息,也可以融合简单模式层高阶邻居信息的图神经网络作为传播模型。
本文所提传播模型的示意图如图1所示,该图展示了为节点“中国”生成向量的过程。该图中向量下方的数字表示节点的编号,相同的编号表示同一节点。向量上方的数字为向量编号,相同的数字表示同一向量。虚线表示连接操作。对于传播模型的第1层,其输入是基础向量层的全体节点向量,对于知识图谱来说还包括基础向量层的全体关系向量。基础向量层的所有节点向量可以构成矩阵E ∈RN×m,其中N为网络中的节点总数。知识图谱在基础向量层对应的关系向量构成矩阵 R ∈RM×m,其中 M为网络中关系的总数。通过一层注意力层后生成的新向量可以构成矩阵 E(1)∈RN×m1,m1为新生成向量的维度;再通过一层注意力层后生成的新关系向量可以构成矩阵 R(1)∈RM×m2,m2为新生成向量的维度。
对于知识图谱中任一节点 vi对应的3 元组(vi,r,vj),本文定义注意力系数

其中,注意力系数 cirj表示节点vj在 关系r 的连接下对节点 vi的重要性;W1∈Rk1×m和 W2∈Rk2×2m为线性变换矩阵;∈Rk1+k2为线性变换向量;vi,r 和vj为 vi, r 和vj对 应的向量;[ ,]和‖都表示连接操作(concatenation)。
对于简单模式层的异质信息网络中的一个节点vi和 其任意一阶邻居vj,本文定义注意力系数

其中,W1∈Rk1×m和 W2∈Rk2×2m为线性变换矩阵,∈Rk1+k2为线性变换向量。与知识图谱不同,简单模式层的异质信息网络没有关系向量。
接下来,本文使用softmax来归一化与节点vi(知识图谱与简单模式层的异质信息网络通用)相关的注意力系数
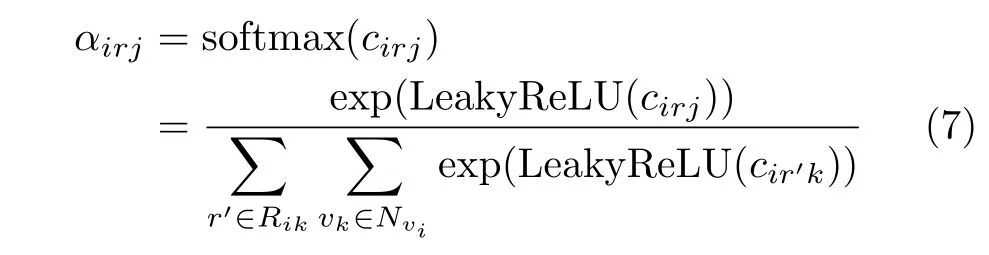
其中, Nvi为节点vi的1阶邻居集合,Rik表示节点vi和节点vk之 间所有的关系集合,L eakyReLU为神经网络中常用的激活函数。
为了聚合节点 vi在该传播层的邻居信息,本文将不同注意力系数线性结合并采用多头注意力[10],为知识图谱定义的聚合公式为

其中,K是多头注意力机制对应头的数量, Rij为节点 vi和vj之 间的关系集合,‖ 为连接操作。如图1所示,向量1和向量2由不同的注意力头生成,再采样连接操作将二者融合。
对于简单模式层的异质信息网络,本文定义的聚合公式为

以上是经过一个注意力层对一个特定节点的操作。所有新生成的节点向量构成矩阵 E(1)。对于关系向量,本文利用线性变换矩阵WR转化生成本注意力层对应的关系向量
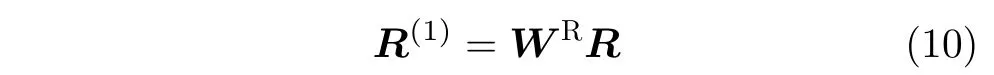
之后, E(1)和 R(1)可以作为下一层的输入,按照以上聚集邻居信息的方法,生成 E(2)和 R(2)。重复这个过程,最终可以生成n层的传播模型。本文将最后一层的节点和关系向量矩阵表示为 E(f)和R(f)。最后一层知识图谱的节点聚合公式为

简单模式层的异质信息网络,对应的节点聚合公式为

图1 知识图谱传播模型示意图



3.3 任务模型
对于简单模式层的异质信息网络,本文对其执行节点分类任务;对于知识图谱,本文对其执行链接预测任务。
3.3.1 知识图谱的链接预测
本文采用文献[9]提出Conv-TransE来执行知识图谱的链接预测任务,该模型既可以生成比较有效的特征又可以保留TransE模型的翻译特性。该模型对应的示意图如图2所示。
本文要求传播模型每一层的节点向量维度都和关系向量维度相等。链接预测任务旨在给出一个3元组的头实体和关系,预测尾实体。对于任务中的一个3元组( vs,r,n), 首先从E(f)和 R(f)中分别取出它们对应的向量 vs和 r (其维度都为ml),再将两个向量堆叠在一起。之后,利用C个卷积核对堆叠在一起的向量执行卷积操作,其中第c个卷积操作为



经过卷积操作之后的分数函数为
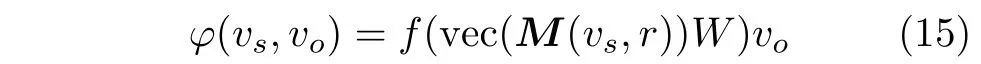
其中,W ∈RCml×ml是一个线性变换矩阵,而f 是一个非线性变换。矩阵M (vs,r)被转换为一个向量vec(M)∈RCml。在训练的过程中,本文对分数函数采用logistic sigmoid函数,如式(16)

3.3.2 简单模式层的异质信息网络的节点分类


给定任务模型的输入向量,本文执行节点分类任务。为了执行该任务,首先将分类标签编码为独热(one-hot)向量,再给输入向量接入几个全连接层,以使输出向量的维度等于标签对应独热向量的维度。最后,采用交叉熵损失来估计标签节点和预测值之间的差距
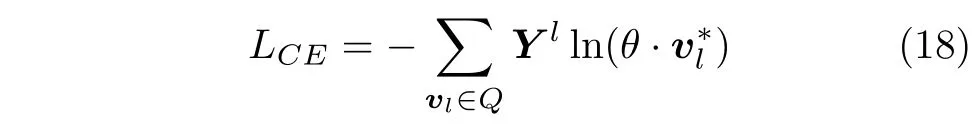
其中,Q为标记节点集合; Yl是对应标签的独热向量;是全连接层的最后一层输出的向量;θ 为分类 器的参数。
4 实验
本文主要执行两个任务:节点分类和链接预测。本文基于pytorch编程,所使用服务器的详细参数为:志强64核CPU;256 GB内存;8块TiTAN XP GPU。

图2 Conv-TransE示意图
4.1 数据集
4.1.1 简单模式层的异质信息网络数据集
DBLP是记录计算机领域学术论文信息的数据集。本文抽样了一个DBLP的子网络构建数据集。所构建的数据集包含4种类型的节点:论文(Paper,P),作者(Author, A),会议(Conference, C)和术语(Term, T)。数据集相关的4个研究领域包括机器学习、数据库、数据挖掘和信息检索。对于任一作者,如果他/她的大部分论文来自会议X,便将与会议X相关的研究领域标签分配给该作者。最后,本文选择了可以被明确分类的4000名作者用于节点分类任务。
IMDB是一个关于电影的数据库,包括演员、导演、评论、简介和电影的其他信息。本文从IMDB中抽取信息构建了一个由电影(Movie, M)、演员(Actor, A)和导演(Director, D)组成的数据集。最终,本文选择了3000部可以被明确分类为动作、喜剧或戏剧的节点来执行节点分类。
本文构建数据集的具体统计数据如表1所示。
4.1.2 知识图谱数据集
本文采用了两个知识图谱数据集[5,11]:WN18RR和FB15k-237。WN18RR和FB15k-237是为了解决相关关系问题[5]为WN18和FB15k分别创建的子集。
4.2 节点分类
本文采用KNN分类器来执行节点分类并设置KNN的参数k=5。本文采用Micro-F1和Macro-F1作为评估实验结果的指标。
4.2.1 基准算法
DeepWalk[12]将异质信息网络视作同质信息网络为每个节点生成向量。
Metapath2vec[6]利用随机游走获取每个节点的邻居信息,并利用异质Skip-Gram来学习每个节点的表示。本文对DBLP分别采用集合{APA, APCPA,APTPA}中的元路径生成向量;对IMDB分别采用集合{MAM, MDM}中的元路径生成向量。
Esim[13]使用预定义的元路径作为向导来学习向量。与Metapath2vec不同,Esim在学习的过程中可以使用多个元路径,而Metapath2vec在学习过程中只能采用一个元路径。
HAN[7]也是一种基于图注意力网络的表示学习模型,该模型分别针对节点级别和语义级别(元路径)的邻居信息进行建模。本文为DBLP采用元路径{APA, APCPA, APTPA};为IMDB采用元路径{MAM, MDM}。
Variant1为了测试简单模式层的异质信息网络是否需要学习关系向量,本文提出了令简单模式层的异质信息网络利用知识图谱的基础向量模型和传播模型生成向量的变体模型。
Variant2为了验证简单模式层的异质信息网络是否需要基础向量层,本文提出了仅包含传播模型和任务模型的变体模型。此外,本文首先训练了基于欧氏距离的节点向量,再用这些向量对传播模型进行了初始化。
训练本文利用Adam[14]对模型进行训练。本文对模型中所有的向量和图神经网络所有的线性变换矩阵实施L2正则化来防止训练过拟合。本文设置多头注意力机制对应头的数量为4;学习率 λ=0.001;图神经网络的层数 l=2。与HAN的原论文不同,本文的数据集没有使用任何额外的特征。本文令基础向量模型的向量维度 d=50,其他基准模型的向量维度也为50。经过第1层注意力层,单注意力头输出维度为25,总的维度为100;经过第2层注意力层,向量的输出维度为100;通过将不同层的向量连接,送入任务模型的向量维度为250。本文令负样本的大小n =5。对于DeepWalk, Esim和Metapath2vec,本文将每个节点的遍历数设置为50,并将步长设置为100。对于HE-GAN-NC和HAN,本文进行了10次实验并报告了平均结果。对于Metapath2vec,仅在测试所有给定的元路径后报告最佳结果。
4.2.2 实验结果
实验结果如表2所示。从实验结果可以看出,本文所提HE-GAN-NC优于所有的基准算法,证明本文所提模型对简单模式层的异质信息网络具有比较好的学习能力。此外,图神经网络模型(HAN和HE-GAN)的整体性能优于其他传统网络表示学习模型(DeepWalk, Esim和Metapath2vec),表明图神经网络生成的特征具有更强的表征能力。

表1 简单模式层异质信息网络数据集的统计信息

表2 简单模式层异质信息网络的节点分类性能
本文所提HE-GAN-NC的性能在所有数据集中都优于HAN。可能的原因是HE-GAN-NC不仅使用注意力机制来选择有用信息,而且还采用了欧氏距离来学习可以保留节点1阶和2阶相似度的基础向量。此外,由于HAN的效果是基于所给定的元路径的,相比之下本文所提的模型还具有更强的适用性。
本文所提模型的效果好于Variant1,说明学习简单模式层的异质信息网络的边信息并不能促进实验的效果。本文所提模型的效果好于Variant2,说明基础向量模型的提出可以更进一步提升模型性能。
4.3 知识图谱的链接预测
知识图谱的链接预测任务旨在预测3元组中丢失的头实体或者尾实体,即对于一个3元组(v1,r,v2)给定 ( r,v2)预 测v1或者给定( v1,r) 预 测v2。对于测试集中的每一个3元组( v1,r,v2), 本文通过将v1或 v2换成实体集合 E中的其他实体来构建损坏3元组并限定这些损坏3元组没有在知识图谱的训练、验证和测试集中出现过。本文采用的指标有平均倒序(Mean Reciprocal Rank, MRR)和Hits@N(正确的3元组在前N项中的排序),其中N在本文取1, 3和10。更高的MRR值和Hits@N值表示更好的实验效果。
4.3.1 基准算法
TransE[3]是比较简单有效的模型,它将尾实体看作从头实体经过关系的翻译。
ConvE[4]是一种多层卷积神经网络模型,其参数利用率高,善于学习复杂结构。
ConvKB[11]通过卷积神经网络捕获实体和关系间的全局关系与翻译特性。
SACN(GCN+Conv-TransE)[9]是一个端到端的图卷积网络模型,该模型利用加权的图卷积网络学习知识向量,并利用Conv-TransE执行知识图谱的链接预测任务。
relationPrediction(GAT+ConvKB)[5]使用图注意力网络并融合关系信息学习知识图谱的结构信息,并使用ConvKB作为解码器。
Variant3为了验证知识图谱的表示学习是否需要基础向量层,本文提出了仅包含传播模型和任务模型的变体模型。此外,本文首先利用TransE模型训练了知识向量,再用这些向量对传播模型进行了初始化。
训练本文利用Adam对模型进行训练。本文对模型中所有的向量和图神经网络所有的线性变换矩阵实施L2正则化来防止训练过拟合。本文设置多头注意力机制对应头的数量为4;学习率λ =0.001;图神经网络的层数l =2。对于卷积核数C,本文在FB15k-237数据集上取100,在WN18RR数据集上取200。本文令基础向量模型的向量维度 d=64。经过第1层注意力层,单注意力头输出向量维度为64,总的维度为256;经过第2层注意力网络,最终的 输出维度为256。本文令负样本的大小n =5。
4.3.2 实验结果
从表3的实验结果可以看出,本文提出的HEGAN-LP与基准算法相比取得了比较好的效果。在所有的模型中,TransE的实验效果最不理想。可能的原因是TransE是一种实验参数较少的线性模型,而其他神经网络模型可以生成更有效的特征。SACN的效果整体优于ConvKB,可能的原因是SACN提出的Conv-TransE可以更加有效地保留3元组的翻译特性。本文所提模型比其变体模型Variant3整体效果略好,可能的原因是基础向量层可以使输入图注意力网络的知识向量始终保持翻译特性。本文所提模型的效果整体上稍好于relation-Prediction(GAT+ConvKB)模型。其可能的原因是,本文所提模型具有基础向量层,而且利用了可以生成有效特征的Conv-TransE模型。
此外,在FB15k-237数据集上,基于图注意力网络的模型(relationPrediction和HE-GAN-LP)效果优于基于图卷积网络的模型(SACN);然而,在WN18RR数据集上,基于图注意力网络的模型并未比SACN模型有显著提升。可能的原因是FB15k-237数据集的平均入度比较高,注意力方法可以从各节点的邻居中选择有用的节点提升实验性能,而WN18RR数据集的平均入度太小(2.12),图注意力网络难以发挥优势。

表3 知识图谱的链接预测任务性能
5 总结与展望
本文提出了一种通用的异质信息网络表示学习框架,该框架可以分为3部分:基础向量模型,基于图注意力网络的传播模型以及任务模型。对于每一个模型,本文针对不同的异质信息网络,采用了不完全相同的设计方法,并解决了不同类型网络中存在的一些问题。该框架可以应用于多个任务并取得良好的效果。本框架的问题在于各模块对于不同类型的网络还需要特定的设计,未来计划提出更加具有通用性的表示学习模型。
猜你喜欢
电脑报(2021年14期)2021-06-28
计算机与生活(2019年5期)2019-07-18
刑法论丛(2018年2期)2018-10-10
法律方法(2018年3期)2018-10-10
吉林大学学报(理学版)(2018年2期)2018-03-29
学习月刊(2016年4期)2016-07-11
湘江法律评论(2016年0期)2016-06-15
云南师范大学学报(自然科学版)(2015年5期)2015-12-26
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
物理实验(2015年10期)2015-02-28
