
人脸属性识别系统的设计与实现
2021-04-24 11:37王高升
电子技术应用 2021年4期
王高升
(华北计算机系统工程研究所,北京 100083)
0 引言
人脸的属性包含了人的面部相关重要的信息,如人的年龄、性别、种族等属性信息。人脸属性的识别就是借助提取出的人脸面部的属性信息然后再进行识别的过程。最近的几年来,随着计算机视觉技术、深度学习及卷积神经网络的飞速发展与应用,出现了许多人脸检测与识别相关的应用,其中常见的一些应用场景包括:道路上的行人监控系统(如检测道路上的行人是否佩戴墨镜或者口罩等)、人脸识别的门禁系统[1]以及采用人脸识别的打卡签到系统等。虽然目前在人脸检测与人脸属性识别的方面得到了非常大的发展,不过很多的之前的研究仅仅局限于预测单个的人脸的属性(例如性别或者年龄)或者为每个的人脸属性信息都通过学习得到一个单独的用于进行识别的模型。
相比于基于HOG-多尺度LBP 特征的人脸性别识别[2]的93.0%准确率,本文采用的人脸属性识别网络在性别属性识别的准确率上有了4.32%的提升。文献[2]提出了一种方向梯度直方图和多尺度局部二值模式多特征融合的人脸性别识别算法。首先,对输入图像进行裁剪和缩放得到多个分辨率的人脸图像,再分别提取LBP 统计直方图并合成一个特征向量;然后提取目标图像头肩模型的HOG 特征得到HOG 特征向量;最后,将LBP 特征向量与HOG 特征向量合成一个新的特征向量,应用支持向量机进行训练。而相比于本文提出的采用深度卷积神经网络进行人脸检测及人脸属性的识别,本文的网络结构在性别属性识别上有着更好的效果。
同时本文采用的网络结构相比于DEPGHAN A[3]提出的基于MTL 的DCNN 网络去识别人脸的属性,其网络是基于不同的任务采用不同的数据集去训练该DCNN网络,本文通过采用Resnet50 深度残差卷积神经网络同时进行人脸多属性的识别,使用一个网络结构实现多个人脸属性的识别而非单一人脸属性识别,同时本文人脸多属性识别的准确率相比于基于MTL 的DCNN 网络在年龄属性识别及性别属性识别上分别有7.64% 和6.32%的提升,提升显著。
1 基于深度学习的人脸属性识别方法
人脸属性的识别整体过程主要能够分成2 个阶段:人脸的检测阶段和人脸属性信息的识别阶段。由于深度学习当前在图像处理中具有较强的特征提取能力,在学习高层的语义特征方面具有着先天的优越性能。因此,本文主要是应用深度卷积神经网络进行人脸的检测及人脸属性信息的分类识别。
1.1 人脸检测
本文在进行人脸检测操作的阶段采用的是经过修改后的MTCNN(Multi-task Cascaded Convolutional Networks)网络[4]进行人脸检测,其由3 个级联的轻量级CNN 完成:Proposal Network(P-Net)、Refine Network(R-Net)和Output Network(O-Net)。
MTCNN 为了兼顾性能和准确率,避免滑动窗口加分类器等传统思路带来的巨大的性能消耗,先使用小模型生成有一定可能性的目标区域候选框,然后再使用更复杂的模型进行细分类和更高精度的区域框回归,并且让这一步递归执行,以此思想构成3 层网络,分别为P-Net、R-Net、O-Net,实现快速高效的人脸检测。在输入层使用图像金字塔进行初始图像的尺度变换,并使用P-Net生成大量的候选目标区域框,之后使用R-Net 对这些目标区域框进行第一次精选和边框回归,排除大部分的负例,然后再用更复杂的、精度更高的网络O-Net 对剩余的目标区域框进行判别和区域边框回归。图像数据先后经过以上3 个网络的处理,最终得到人脸检测结果,也即是得到了人脸区域框的左上角像素以及右下角像素在输入图像中的坐标信息。
通过使用WIDERFace 人脸数据集[5]对经过改进后的MTCNN 网络进行有监督的训练,并且在网络训练过程中仅进行边框回归操作,不对关键点信息检测进行训练,因为人脸属性识别过程不需要关键点的位置信息,可以进一步加快网络训练与推理的速度。通过训练获得边框预测准确度比较好的深度卷积神经网络模型,最后采用这个深度卷积神经网络模型进行人脸的检测操作过程[6]。
人脸检测阶段中改进后的MTCNN 网络的推理过程如图1 所示。
1.2 人脸属性识别
人脸属性信息的识别阶段主要是利用人脸检测阶段检测网络获得的人脸区域的图像,对这个获得图像通过深度卷积神经网络进行信息提取并输出性别、年龄及种族人脸属性信息。
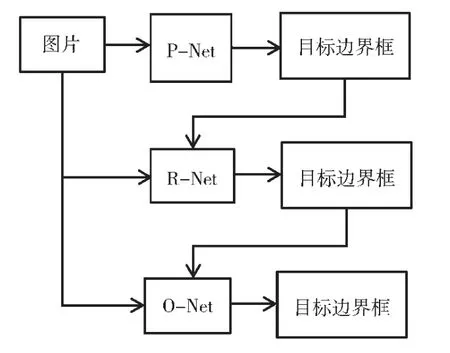
图1 改进后的MTCNN 网络的推理过程
在Renset 网络之前,卷积神经网络主要采用将卷积进行堆叠的方式增加网络结构的深度,以使得网络模型的表现性能具有更好的效果。但是由于在网络深度的增加的同时,就会出现网络模型的训练过程中梯度进行反向传播比较困难的现象,较容易出现梯度消失或者梯度爆炸的问题,由此,Resnet 网络引入了残差网络结构。这种网络结构极大地简化了网络的学习目标和学习的难度,使得网络具有更强的恒等映射的能力,从而在拓展了网络深度的同时也提升了网络模型的性能。残差结构使用跳跃连接的方式实现,通过引入残差结构,可以对更深的网络进行训练,同时不会出现梯度消失或者梯段爆炸的问题。
由于深度卷积神经网络能够通过使用一系列的卷积层操作、池化操作层操作等自动地提取出输入的图像的特征,更深的网络能够得到更具有表达能力的特征信息,因此当前应用于特征提取的并且取得较好效果的是一些深度卷积神经网络。因此本文在人脸属性识别阶段采用改进的Resnet50 网络[7],由于Resnet50 具有较深的卷积结构,能够很好地提取图像特征信息,因此,改进的Resnet50 网络的全连接层修改成108 个神经元,也即是108 维的张量输出,其中0~100 代表年龄,101~102 代表性别(101:Male,102:Female),103~107 代表种族(对应的依次分别为白人、黑人、亚洲人、印第安人、其他类型(如拉丁人、西班牙人等)。
通过使用UTKFace 人脸数据集[8](其中包含性别、年龄及种族信息)及Resnet50 的预训练模型,采用交叉熵损失函数[9],对修改后的网络模型进行训练,对数据集中的年龄、性别及种族都采用one-hot 编码[10],3 种属性在训练时都是采用分类的方法。
使用交叉熵损失函数能够更好地度量出来两个概率分布之间存在的差异性,交叉熵的公式如式(1)所示:
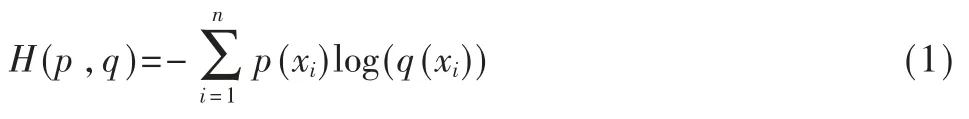
其中,p、q 分别表示一种概率分布,x 为随机变量。
交叉熵能够度量出来相同的一个随机变量中的两个存在差异的概率分布之间的差别的程度,交叉熵的值越小,两个不同的概率分布之间的差别越小。在进行网络训练时,输入网络的数据与标签信息已经完全确定,而且目标的标签信息采用了独热编码的形式,一次可以把输入网络的标签信息看作为真实的概率的分布P(x),而Q(x)即是网络预测的概率的分布,而网络模型的训练过程其实就是不断地把网络预测的概率与真实分布的概率之间的差异减小的过程,所以采用交叉熵损失函数来计算网络的损失,通过不断地更新网络参数,来减小网络预测损失的大小,提高网络模型预测的精度。
在使用训练好的网络模型时,性别、种族和年龄属性均采用分类的方法得到结果,如年龄属性多分类使用的方法主要是对全连接网络层的0~100 的输出张量首先使用Softmax 对网络输出的数据进行归一化的操作,得到对应人脸年龄的概率大小,根据概率的大小排序,得到人脸的年龄属性结果信息。
人脸属性识别阶段的Resnet50 网络推理过程如图2所示。人脸检测网络训练过程的损失变化如图3 所示。进行人脸属性分类识别的Resnet50 网络的训练过程中损失变化如图4 所示。
通过人脸检测阶段及人脸属性识别阶段,可以得到人脸的性别、年龄及种族属性信息,整个人脸属性识别过程采用端到端的方式,进一步使得网络的精度得到提升,并且能够预测多种人脸的属性信息[11]。
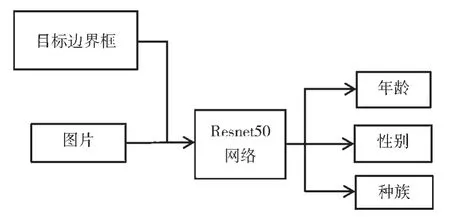
图2 改进后的Resnet50 网络模型的推理过程

图3 人脸检测网络训练过程损失变化
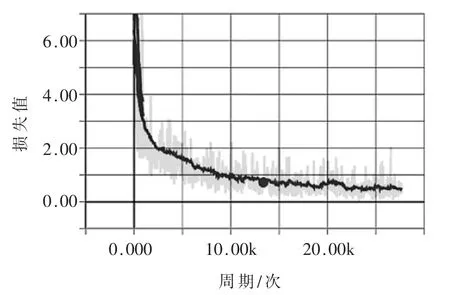
图4 Resnet50 网络训练过程中损失变化
2 实验结果与分析
实验中采用的数据集由WIDERFace 和UTKFace 人脸数据集组成,其中测试集的占比约为5%。
人脸检测阶段采用的是WIDERFace 人脸数据集进行网络的训练,由于人脸属性识别过程不需要人脸的关键点位置信息,因此人脸属性识别系统中人脸检测阶段改进后的MTCNN 网络只使用了数据集中人脸的边框位置信息进行网络模型的训练,训练后的人脸检测网络模型推理结果得出的只有人脸的边框位置信息[12]。
人脸属性识别阶段采用的是UTKFace 人脸数据集对改进后的Resnet50 网络进行网络的训练,改进后的Resnet50 网络采用了UTKFace 数据集中的age、gender、race 信息,并对这些数据进行了数据清洗、one-hot 编码等数据预处理过程,然后加载Resnet50 网络的预训练模型进行迁移学习训练,采用预训练模型可以加速网络收敛,大幅度减少网络训练所需要耗费的时间。训练后的网络模型在推理过程中输出的是108 维的特征向量,这个结果分别代表年龄、性别及种族信息。人脸属性识别中,性别、种族及年龄均采用分类方法,性别是二分类,种族是多分类(识别的种族包含5 种),年龄属性同样是多分类任务。
人脸属性识别网络经过端到端的训练之后,各属性识别的准确度如表1 所示。
从表1 中可以看出,网络模型在性别属性的识别预测的精度最高,达到97.32%;种族识别预测的准确度为92.13%;年龄识别预测的准确度则达到了71.64%。改进后的网络模型进一步提高了人脸各属性信息识别的准确率,得到了更好的识别效果。
在实际的场景中,种族及年龄的识别预测受到光线及角度的影响较为严重,光照对种族识别预测的影响比较严重,主要原因是在采用的种族识别预测的数据集中,种族的识别预测更多地是根据肤色来进行,因此光照会造成结果有很大的偏差[13]。同时人脸的不同角度对于人脸属性的识别也有一定的影响,所以通过加入人脸矫正过程可能对人脸属性识别的准确率有一定的提升。光照及角度对识别的影响需要进一步通过预先进行图像处理等方式来降低对识别网络进行预测产生的影响[14]。
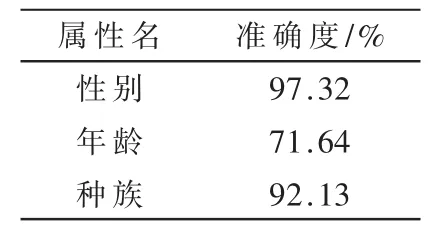
表1 验证集各属性识别的准确度
3 人脸属性识别系统的实现
人脸属性识别系统主要是采用Python 及其Tkinter库进行系统的开发与实现,并把人脸属性识别网络及训练好的网络模型加入到系统中,最后通过Pyinstaller 把整个系统程序打包成在Windows 操作系统下能够直接运行的可执行程序(人脸属性识别系统.exe)[15]。
人脸属性识别应用系统的主界面如图5 所示,界面功能主要有摄像头的选取功能,通过下拉列表可选取系统运行时采用电脑自带的摄像头或者使用外接的摄像头设备,在开启摄像头时该设置不可进行修改,可在关闭摄像头之后再次进行选取。通过开启摄像头或者关闭摄像头功能按钮,可以对指定的摄像头设备进行数据读取或者关闭摄像头设备。右侧为对识别到的人脸采用网络模型进行运算后输出的人脸属性信息进行详细的显示以及检测到的人脸图片显示。系统程序采用多线程方式进行人脸属性识别与界面信息显示。系统在进行人脸属性识别时未检测到人脸时的系统界面如图6 所示,识别成功时的系统界面如图7 所示(注:人像图片来自公开人脸数据集LFW),当视频中出现多个人脸时只对其中面积最大的人脸进行属性识别。系统在进行人脸属性识别时网络模型的运算速度能够达到约20 f/s,系统整体运行速度较快,操作简单,运行状态稳定。
4 结论
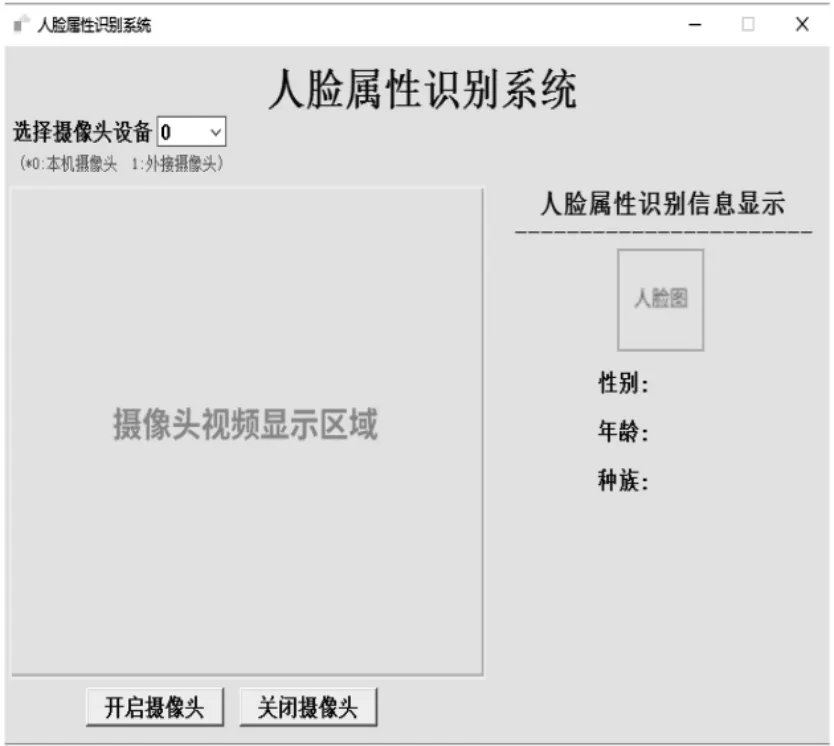
图5 人脸属性识别系统主界面

图6 未检测到人脸时系统界面

图7 识别成功时的系统界面
本文详细论述了人脸属性识别系统设计与实现以及网络改进方法,相比于传统的识别方法,文中所提出的基于深度学习的人脸属性识别方法采用了端到端的网络训练方法,进一步地提高了人脸属性识别的准确度;本文的网络采用了较深的卷积神经网络结构,通过深度卷积神经网络能够更好地提取出人脸图像中的人脸特征信息,采用交叉熵损失函数训练网络模型,提高了人脸属性的识别准确率[16],使得人脸属性识别系统能够很好地进行人脸属性的识别。但是该识别方法会受到一定程度上的光照及角度的影响,因此,后续研究可在该方法的基础上加入图像预处理方法来减少光照及人脸角度问题产生的影响。同时通过更多的数据集的收集,后续可以加入更多的人脸属性信息进行识别。而对于人脸属性识别系统,后续可以对系统界面进行美化以及进一步增加各种相关功能,使得人脸属性识别系统能够对更多的属性进行识别[17]。
本文的网络结构及系统设计方面还有许多可以改进和优化的地方,随着深度学习及计算机视觉的快速发展,将会出现更多计算机视觉相关成果的产品。
猜你喜欢
英语文摘(2021年11期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年11期)2019-07-04
反歧视评论(2018年0期)2019-01-23
动漫星空(2018年9期)2018-10-26
英美文学研究论丛(2018年2期)2018-08-27
北京航空航天大学学报(2018年1期)2018-04-20
时代英语·高一(2017年5期)2017-11-14
