
基于朴素贝叶斯算法的群众留言多标签分类的应用
2021-04-24 09:06方小宇罗补干周铄洋郭丽莎
科学技术创新 2021年9期
方小宇 罗补干 周铄洋 郭丽莎
(中南民族大学数学与统计学学院,湖北 武汉430074)
1 概述
近年来,互联网已经发展成为人们获取信息、关注热点事件、了解国情乃至了解世界的重要媒介。目前,我们已经步入了“互联网+”的生活时代。社会各方面高速发展、科技发达、信息泉涌,人们与政府之间的交流越来越密切,微信、微博、市长信箱、阳光热线等网络问政平台逐步成为政府了解民意、汇聚民智、凝聚民气的重要渠道。各类社情民意相关的文本数据量不断攀升,给以往主要依靠人工来进行留言划分的相关部门的工作带来了极大挑战。同时,随着大数据、云计算、人工智能等技术的发展,建立基于自然语言处理技术的智慧政务系统已经是社会治理创新发展的新趋势,对提升政府的管理水平和施政效率具有极大的推动作用。本文首先通过网络爬虫搜集到7 个类别的9210条留言,然后对搜集到的数据进行处理和分析,接着运用朴素贝叶斯算法建立了多标签分类模型,最后对模型进行评估。
2 数据预处理
为了模型建立的有效性,首先要对搜集的留言进行数据处理,包括数据清洗、文本分词、文本向量化等,具体处理流程如图1 所示。
2.1 去除无关字符

图1 数据预处理流程
通过对文本的分析,发现文本中存在许多无用无意义的字符或连接,如空白字符、“baidu.cm”等,这些无意义的字符给模型训练和评估带来负面的影响,因此,首先在文本中将这些无关字符去除。
2.2 文本分词
去除无关字符后,接下来就是对文本进行分词,常见的分词方法有:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法和基于规则的分词方法,每种方法下面对应许多具体的算法。对于此问题而言,本文采用Jieba 分词库。但因为jieba 词库中一些分词与现实生活中人们习惯的分词存在差别。比如下列一部分对留言主题的分词结果:
1''“[‘西湖’,‘建筑’,‘集团’,‘占’,‘道’,‘施工’,‘安全隐患’]”
2''“[‘市中坡’,‘山’,‘公园’,‘内溜狗’,‘有损’,‘景区’,‘环境’,‘应’,‘严禁’]”
3''“[‘农村信用’,‘合作’,‘联社’,‘208’,‘户’,‘合伙’,‘建房’,‘工程’,‘招投标’,‘问题’]”
4''“[‘申请’,‘市公’,‘租房’,‘问题’,‘咨询’]”
5''“[‘城市居民’,‘保障’,‘房’,‘相关’,‘政策’]”
6''“[‘校园’,‘暴力事件’,‘屡屡’,‘发生’]”
在这些分词中,划线的词语的分词都与现实生活中的分词不太符合,所以要对分词的词库进行添加,使这些词语能够符合现实的词语表达,比如:“‘占道’,‘公园内’,‘农村信用合作联社’,‘公租房’,‘保障房’,‘校园暴力’”。所以要将这些词语更新到词库中,再次进行分词。
2.3 去除停用词
在分词之后,会发现分词结果中存在大量无意义的词,比如:“‘了’,‘的’,‘地’”等,不仅对文本分类没有作用,还会增加之后的工作量,所以要将这些停用词过滤。首先是使用传统的停用词库去停用词,由第一次去停用词的结果,更新停用词库后,再次去除停用词。
2.4 文本向量化
定义一个词的权重通常采用的是TF-IDF 的方法。在信息检索理论中,TF-IDF 是Term Frequency-Inverse Document Frequency 的简写,TF 是词频,IDF 是逆文档频率,用于反映一个词对于语料中某篇文档的重要性。在信息检索和文本挖掘领域,它经常用于因子加权。TF-IDF 的主要思想就是:如果某个词在一篇文档中出现的频率高,也即TF 高;并且在语料库中其他文档中很少出现,即DF 低,也即IDF 高,则认为这个词具有很好的类别区分能力。
Cornell SMART 系统的词频的计算公式如下:

本文先将语料转化为词袋向量,根据词袋向量统计TF-IDF,根据数据集文本序列长度,通过计算发现98.6%的样本文本序列长度都小于2500。为了简化计算,做出每2500 词划分一次的调整,长度大于2500 的进行切分,小于2500 的进行填充。最终可以得到文本的TF-IDF 表示。
3 多标签分类
3.1 数据增强
首先,观察数据集,数据分布如图2 所示,共有七个分类,且数据具有不平衡的特性,最多的类别“城乡建设”的数量是最少类别“交通运输”的三倍多。由于多数类和少数类在数量上的倾斜,以总体分类精度最大为目标会使得分类模型偏向于多数类而忽略少数类,导致少数类被判断为多数类的概率大大增加,造成少数类的分类精度较低。

图2 类别分布图
对于数据不平衡问题,可以从三个角度予以解决,分别是数据角度、评价指标角度和算法角度。此处采用从数据角度来着手,对原始数据进行回译以达到增强数据的效果,即将目标数据进行多次不同语种翻译,再翻译回来的一种方法,将其它六类扩充到与城乡建设数量相同。扩充后数据集数量达到14063条。数据增强示意图如图3 所示。

图3 数据增强示意图
3.2 贝叶斯分类模型理论
3.2.1 贝叶斯定理
贝叶斯方法采用计算每一个样本属于每一类的概率,然后将样本划分为具有最大概率的那一类中。即已知样本x 的条件下,计算属于某一类的概率。
3.2.2 贝叶斯公式中的相关概率
先验概率P(cj):表示训练样本数据前cj(类别)拥有的初始概率。P(cj)常被称为cj的先验概率(prior probability),通常采用样例中属于cj的样例数|cj|与总样例数|D|的比值来近似表示。如(1)式所示:

后验概率P(cj|X):指当给定数据样本X,属于cj的概率。P(cj|X)被称为cj的后验概率(posterior probability),它反映先看到数据样本X 后cj成立的置信度。使用贝叶斯公式计算后验概率,如(3)式所示。
贝叶斯公式:

由于P(X)对所有类都是相同的,因此在实际的应用中我们只需计算贝叶斯公式分子部分,求取最大值,如(4)式所示,然后把X 就分到最大值对应的类ccmp中。

3.2.3 朴素贝叶斯分类器
由于计算(2)式相当困难,所以朴素贝叶斯分类器假设:在给定样本的目标值时属性之间的相互条件独立。即(2)式求取的类条件概率就是每个单独属性对应的概率的乘积,如(5)式所示。

因此,对于朴素贝叶斯学习方法就是从训练样本中估计不同的P(cj)和P(ai|cj),针对新的待分样本实例,采用(4)式、(5)式进行计算给出分类结果。
4 文本分类结果分析

表1
本文中使用准确率、召回率、F1-score 三个指标来评估算法效果。
4.1 精确率(Precision):分类结果中正确分类为Ci 的样本数占分类结果中所有分为Ci 类别的样本数,衡量分类的查准率:
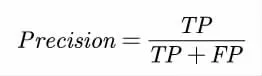
4.2 召回率(Recall):分类结果中正确分类为Ci 的样本数占所有Ci 类的样本数的比例,衡量分类的查全率:
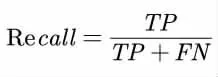
4.3 F1-score:在精确率和召回率的基础上提出了F1 值的概念,来对精确率和召回率进行整体评价:

最终得到整体的分类效果:
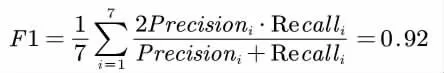
本文基于如上实验步骤实现了朴素贝叶斯分类算法,衡量分类效果的F1 值高达92%,实验结果表明朴素贝叶斯分类算法有很好的多文本分类能力。
5 结论
朴素贝叶斯是经典的机器学习算法之一,通过考虑特征概率来预测分类,是为数不多的基于概率统计学的分类算法,文章论述了贝叶斯模型的基本理论,采用贝叶斯分类器对网络问政平台的群众留言进行了多标签分类研究。通过将样本14063条数据80%划分为训练集,20%划分为测试集。进行测试评估,在测试集上准确率达到了91.68%,F1-Score 达到了0.9161。不足之处是贝叶斯分类模型需要知道先验概率,并假设属性之间相互独立,因此当属性个数较多或属性之间相关性较大时,分类效率比不上决策树模型。
猜你喜欢
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
校园英语·月末(2021年13期)2021-03-15
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
电脑爱好者(2017年5期)2017-05-04
