
基于RAU-net的视网膜OCT图像快速自动分层研究
2021-04-23 01:51:32曾兴晖许祥丛王茗祎钟俊平熊红莲
华南师范大学学报(自然科学版) 2021年2期
曾兴晖, 许祥丛, 李 晓, 王茗祎, 钟俊平, 熊红莲*
(1. 佛山科学技术学院机电工程与自动化学院, 佛山 528225; 2. 佛山科学技术学院物理与光电工程学院, 佛山 528225)
光学相干层析成像(Optical Coherence Tomography,OCT)视网膜图像的定性评估可以为临床决策提供关键信息,包括眼部疾病的分类和检测信息[1-2]. 量化OCT视网膜数据对于诊断眼科疾病、研究眼睛形态的变化非常重要[3-4],能帮助眼科医生发现早期疾病、跟踪疾病进展和监测治疗效果[5-6]. 视网膜层分割是OCT图像分析中的一项基础性工作,开发可靠的OCT视网膜图像分割方法一直是研究与视网膜层厚度相关疾病的重点. 将OCT视网膜图像分成10个区域,大多数自动分割方法关注的焦点是区域间的9条边界. 从眼睛内部向外,这10个区域包括:玻璃体、视网膜神经纤维层(RNFL)、神经节细胞层和内丛状层(GCL+IPL)、内核层(INL)、外丛状层(OPL)、外核层(ONL)、内段(IS)、外段(OS)、视网膜色素上皮层(RPE)、脉络膜.
为了快速准确地得到OCT视网膜图像分层结果,视网膜层的自动分割技术已被广泛研究[7-13]. 水平集方法[7-8,13]在获得拓扑结构正确的视网膜层分割技术中效果显著,但是水平集方法计算耗时较长,分层结果的运行时间往往需要几个小时. 基于图像搜索的方法[9,10]也已被广泛应用于视网膜图像的分割. 最新技术使用机器学习[12,14-15]的方式(如随机森林[12])进行像素级的标记分类,并使用图像搜索方法来提取分层结果. 虽然这些方法已经表现出显著的优点,但是受到手动选择特征和模型参数的限制,面对不同采集环境下的数据时需要重新选择合适的特征和参数.
近年来,深度学习在医学影像的分割任务中取得了一定的进展. FANG等[11]针对OCT视网膜图像中9条边界的自动分割问题,提出了一种基于卷积神经网络(CNN)和图像搜索(Graphical Search,简称CNN-GS)的方法. 该方法采用CHIU等[10]基于图论的OCT视网膜分割方法,但用CNN代替了边缘检测的步骤. FANG使用深度网络预测给定图像块中心像素的类别,利用图像搜索对预测的类别信息进行边界提取操作,该方法对每个像素位置都选定固定大小的窗口,预测单张视网膜图的结果就需要对上万个图像块进行计算,这样产生了计算冗余,使结果预测十分费时. 本文使用RAU-net对视网膜层进行分割,只需要将单张视网膜图像剪切为20个图像块并进行预测,就能得到单张图的视网膜层分割结果. 再采用图像搜索方法对分割的边界进行优化,可以快速准确地提取视网膜层的9条边界.
1 研究方法
提出的方法主要分为三部分:首先是对视网膜图像进行预处理,剪切为128 px×128 px的图像块;然后利用RAU-net实现对视网膜层的分割;最后运用Dijkstra方法[16]进行边界优化,最终得到分层结果. 具体流程如图1所示.

图1 算法流程图
1.1 预处理
采用AURA(Automated Retinal Analysis Tools)工具包对OCT视网膜图像(784 px×1 024 px,128帧)进行强度归一化和压平处理[12]:首先以视网膜层的BM(Bruch’s Membrane)边界为基准压平图像,并将每张B-scan图像剪切为128 px×1 024 px大小的图像块,保留需要分割的视网膜部分,去除脉络膜和玻璃体部分;然后从每张B-scan图像中提取20个水平重叠大小为128 px×128 px的图像块用于训练. 在测试中,将输出的分割结果按输入图像块在原图像的位置重建为完整的视网膜分割图像.
1.2 残差网络和注意力机制结合的分割网络
1.2.1 残差网络 为了使模型学习更多视网膜层的抽象特征,一般采用更深层次的网络来学习高级特征,但更深的网络往往会带来梯度消失或者梯度爆炸的问题. HE等[15]提出了残差网络(Resnet),通过引入残差块(Residual Block)构建深层网络,这在很大程度上消除了深层体系结构中存在的梯度消失和爆炸的问题. 如图2所示,残差块以x为输入项,H(x)为输出项,其中F(x)为残差映射函数. 当构建深层网络时,模型难以直接拟合实际映射H(x),残差网络通过引入快捷连接将问题转换为拟合残差映射函数F(x),此时实际映射H(x)表示为H(x)=F(x)+x.

图2 残差块结构
在极端情况下,如果单位映射是最优的,那么将残差构建为0,比通过非线性层来拟合单位映射更容易,即此时F(x)=0,用一个恒等映射函数H(x)=x表示一组堆叠网络层的最佳解映射,模型只需最小化残差函数F(x)=H(x)-x来逼近实际映射,以解决网络层堆叠的性能退化问题.
假设现有L个残差块进行堆叠连接,以x(l)表示第l个残差块的输入项. 可推导第L个残差块的输出项为:
(1)
由式(1)可知,残差网络的特征是各层残差特征的累加,保证了l+1层比l层拥有更多的特征信息.
1.2.2 注意力机制 注意力机制(Attention Mechanism)的实质是计算注意力的概率分布,对重要的特征分配更多的注意力,突出关键特征对结果的影响,常用于时间序列分析相关的深度学习模型中[17]. 在U-net中编码器用于提取图像特征,对提取的特征图进行上采样,生成分割图像. 在U-net的解码器端引入注意力门(Attention Gate,AG)[18],对编码器中通过跳跃连接(Skip Connection)传播得到的重要特征进行增强处理,并抑制无关的特征. 注意力门模块是一种柔性注意力机制的应用,具体的内部结构如图3所示.
若采用尿沉渣分析仪和尿干化学分析仪联合方法,对尿液红细胞进行检测时,结果均提示为阴性,则提示光学显微镜镜检结果是正常;若前一检测仪结果为阴性而后一检测仪结果呈阳性时,究其原因,可能是尿液中含有肌红蛋白、某些不耐热的酶等,如果红细胞处于PH环境中或不同渗透压而造成的溶血;若前一检测仪结果为阳性而后一检测仪结果呈阴性时,那么可能是由于晶体汇集、类酵母菌和细菌的干扰,其中最为常见的是结晶干扰。

图3 注意力门的结构
注意力门的输入项是门控信号g和特征映射x. 在U-net[14]结构上,将跳跃连接的特征信息作为输入项x,将解码器中上采样后的特征信息作为门控信号g. 模块的构成包括线性变换Wg、Wx和ψ,偏置为bg和bψ,激活函数为Relu和Sigmoid,其中线性变换通过1×1通道的卷积实现,线性变换Wg和Wx的结果通过相加的方式结合,其目标是对每个像素矢量xi计算注意力系数αi[0,1]:
(2)
使用三线性插值进行网格重采样后得到注意力系数α. 注意力门模块的输出项为输入项特征x和注意力系数α的乘积.
1.2.3 网络结构 本模型使用U-net为基本框架[14],在此基础上结合残差网络和注意力机制,因此该网络模型称为残差和注意力U-net(Residual and Attention U-net,RAU-net). 如图4所示,与U-net类似,该网络结构包含编码和解码两部分,在编码部分输入OCT视网膜图像并提取特征,解码部分使用特征图和语义信息来生成预测图像作为分割结果.

图4 RAU-net结构
与传统U-net框架不同,RAU-net使用残差块结构进行特征提取[19],采用[3×3]卷积层、激活函数Relu来构建残差块. 在编码与解码部分跳跃连接处加入注意力门. 在编码部分,第一个残差块处理后的通道数是32,将网络的编码中每个残差块处理后的通道数加倍,使用[2×2]最大池化(Maxpooling)和[2×2]上采样将数据在不同尺度之间转换. 残差块的结构有助于解决梯度问题,能够在加深网络层次、提取高维度特征的同时抑制梯度问题的出现. 通过结合残差块结构和注意力门结构,RAU-net可以获得更高级的特征,以及模型更加关注于视网膜层重要特征的分割. 该模型的输入项是大小为128 px×128 px的OCT视网膜切块图像,输出项是8个大小为128 px×128 px的概率图,分别表示7个视网膜层和背景(玻璃体和脉络膜)的预测结果.
1.3 边界优化
首先通过RAU-net分割得到视网膜层的分层结果,然后对结果进行拓扑校正,再由校正的结果确定9条边界的感兴趣区域(Region of Interest,ROI),最后应用Dijkstra方法优化视网膜层的9条边界.
由于层边界具有连续性,因此可通过拓扑校正发现异常区域并将其清除,然后由线性插值对边界上的点拟合出容忍边界,限制2条边界之间的层越界,有效保证了图像搜索结果的鲁棒性. 最后由Dijkstra算法确定最小加权路径[16],即视网膜层的分层边界. 视网膜B-scan模拟(图5)将视网膜图表示为节点图并进行权重分配[10]. 以视网膜层分割后的9条边界作为基准线,通过上下拓宽2 px来确定搜索区域,寻找最优边界.

图5 节点图分割过程
1.4 实验数据集
研究数据来自佛山科学技术学院光电技术实验室的数据库,采集于15 名受试者的视网膜OCT数据. 所用采集仪器为眼底断层扫描系统(3D OCT-1 Maestro,日本拓普康). 每一组视网膜OCT数据包含128张B-scan图,且每张图的尺寸为2.3 mm×6 mm,包含784 px×1 024 px.
1.5 评价标准
使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)来评价算法在测试数据上的结果. 将P定义为预测结果,G定义为实际值,计算公式如下:
(3)
(4)
2 结果与讨论
2.1 准确率与损失函数
本文模型基于keras框架,使用Adagrad方法优化权值和偏置,达到最高的准确率和最小的损失函数值. 使用交叉熵损失函数计算损失函数值. 模型的准确率及损失函数曲线如图6所示. RAU-net模型表现出较高的准确性,准确率达到了98.39%.
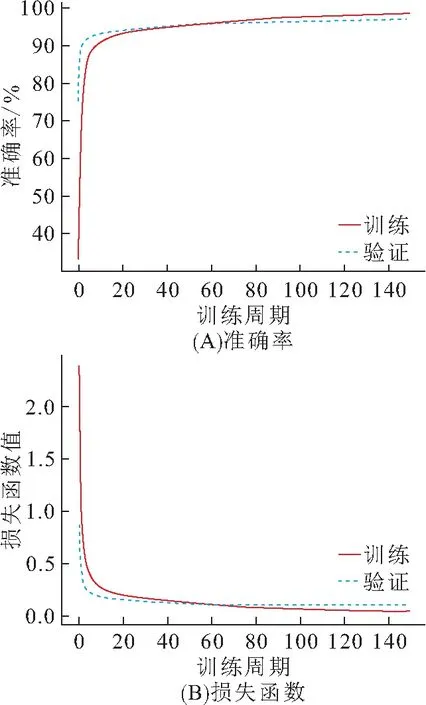
图6 准确率和损失函数曲线
2.2 RAU-net分割结果的分析
基于RAU-net的视网膜层分割过程(图7A),将RAU-net得到的分割结果进行拼接,得到完整的B-scan分割图(图7B),不同层之间用不同颜色表示. 图7B中校正前第二层可见明显的红色斑块,这是由于高反射伪影或散斑噪声的影响产生误差而导致的异常点. 通过层之间的拓扑关系,对异常点进行定位并清除(图7B). 这有效保证了图像搜索结果的鲁棒性.

图7 视网膜分割
2.3 ROI区域搜索的结果
为了提高分层边界的精度,根据RAU-net的分割结果确定了含有9条边界的ROI区域(图8),在该区域内搜索最优边界,可得到更精准的视网膜边界. 另外,所划定的ROI区域较小,有助于提高搜索效率.

图8 9条边界的ROI区域
2.4 定性与定量分析
对比研究FANG的方法[11](图9A、B)与本文方法(图9C、D)在视网膜上的分层结果可知:本文的分层结果与实际分层结果更加贴合,尤其针对存在血管阴影的视网膜图(如图9B中与图9D中血管造成的阴影位置),FANG的方法把血管阴影的边界当作了视网膜层的边界. 这是由于FANG采取边界分类,且所采用的网络深度太浅,导致学习到的特征信息有限,将血管的边界误判为视网膜层的边界. 而RAU-net针对视网膜层做分割,网络能够更好地理解每个视网膜层的区域性. RAU-net应用残差块加深了网络的深度,提取高维特征的同时避免梯度问题,能提取视网膜图像中更高级的特征. 而注意力门结构的突出有利于分割重要特征,减少无关特征信息的干扰,从而消除了血管阴影对分层的影响.
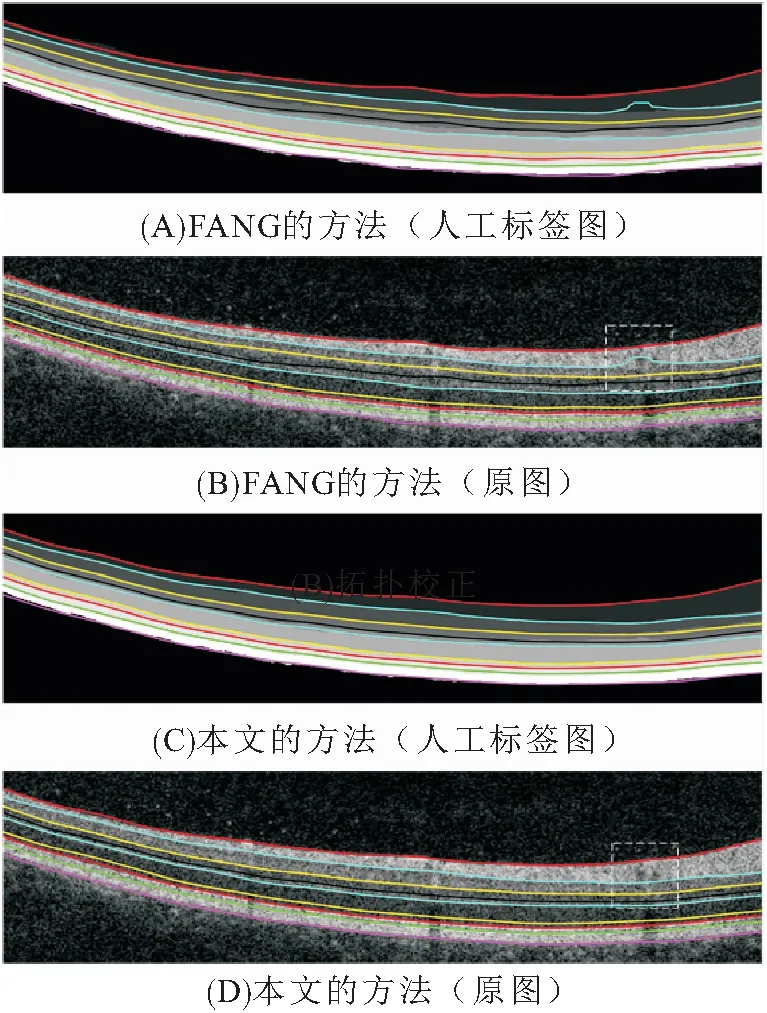
图9 本文与FANG的方法[11]分割的结果
将RAU-net+Dijkstra方法与FANG采用的CNN-GS方法在视网膜自动分层的准确性和效率上进行比较(表1).

表1 2种方法的像素级评估
与FANG的方法相比,本文方法表现出了更高的准确性. ILM、RNFL-GCL、INL-OPL、OPL-ONL、ELM、IS-OS、OS-RPE、BM的均方根误差均小于2,只有IPL-INL边界的均方根误差达到了2.127 3,而FANG的方法均方根误差达到了4.163 2. 这是由于RAU-net和Dijkstra法相结合,得到了更多的视网膜边界特征,提高了自动分层的精确度,使误差明显降低. 由实验可知,FANG的方法分层处理每张B-scan图像需10 min,而本文方法仅需4 s. 这在实际应用中可以显著提高医疗诊断效率.
3 结论
针对OCT视网膜图像的自动分层成像,提出了一种基于RAU-net与图像搜索结合的快速分层方法,快速、精确地完成视网膜的分层成像. 结果表明:本文的实验结果在精确度上表现优秀,且速度快. 研究结果为OCT视网膜图像边界的分割提供了一种新的思路,为临床诊断治疗提供了一种高效的定量参考方法.
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11 09:53:56
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:28
中医眼耳鼻喉杂志(2021年2期)2021-07-21 08:53:34
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
证券法律评论(2018年0期)2018-08-31 02:33:08
湖南中医药大学学报(2016年1期)2016-12-01 04:08:18
河南科技(2015年8期)2015-03-11 16:23:52
