
基于改进YOLOV3的道路目标检测
2021-04-22 04:11:42徐向荣朱永飞陶兆胜
龙岩学院学报 2021年2期
周 攀,徐向荣,朱永飞, 陶兆胜
(安徽工业大学 安徽马鞍山 243032)
自动驾驶、智能交通等研究领域的发展使得道路目标检测技术的应用变得愈加广泛。道路场景目标检测是运用计算机视觉判断道路上是否含有车辆、行人等目标并识别出目标的种类及其具体位置,对维护道路安全畅通、实时监测道路信息等具有重要作用。
传统目标检测算法主要依赖人为设计特征,首先从图像中利用穷举法选取候选区域,然后提取其特征,最后利用分类器对其进行分类,特征提取主要使用HOG[1]、SIFT[2]等,分类器主要使用SVM[3]、Adaboost[4]等。然而人为设计特征的泛化性和鲁棒性差,难以适应复杂的实际场景;并且利用穷举法提取候选区域的时间复杂度高满足不了实时性。自2006年HINTON等[5]学者提出深度学习的概念后,基于深度学习的目标检测算法逐渐成为计算机视觉领域研究的热点,凭借强大的特征表达能力取得广泛应用。目前主流算法包括基于区域推荐的检测算法和基于回归的检测算法,前者主要包括R-CNN[6]、Fast R-CNN[7]、Faster R-CNN[8]等,后者主要包括YOLOV1[9]、YOLOV2[10]、YOLOV3[11]、SSD[12]等。
2014年,GIRSHICK等人提出R-CNN模型,首次将卷积神经网络的概念引入目标检测领域,但是每个区域建议框都要单独进行特征提取导致难以满足实时性。针对R-CNN的不足,2015年GIRSHICK R等人提出Fast R-CNN算法,运用SPP-Net[13]的原理,通过ROI[7](regions of interest) Polling层将不同大小的特征图统一采样成固定大小,并且将分类损失和边界框坐标回归损失统一训练,极大提高检测速度。2015年提出的Faster R-CNN增加了RPN[8](region proposal network)层,并且提出一种全新的映射机制——锚框(anchor box),通过设置不同尺度的锚框在RPN的特征层中提取候选框来代替选择性搜索等传统的候选框选取方法,实现网络的端到端训练。
2015年,REDMON团队提出YOLOV1模型,将目标检测和类预测任务集成到神经网络模型中,同时预测边界框位置和类别并实现端到端检测,但是由于定位损失过大,所以对小物体的检测效果不好。YOLOV2采用Darknet-19为特征提取网络,沿用Faster R-CNN的锚框机制,提升速度和精度,但是对复杂环境的目标检测效果不理想。2018年REDMON J团队提出YOLOV3算法,由于其检测速度较高,近年来被广泛应用于道路场景检测中,李汉冰等[14]在原始YOLOV3的基础上使用反残差网络进行特征提取减少参数量以提高模型的检测速度;张富凯等[15]设计6个卷积特征图与残差网络中相应尺度的特征图进行融合以提高特征融合的融合效果;郑秋梅等[16]根据待检测目标的尺寸调整损失函数的影响权重以改善小目标及遮挡环境的检测效果;杜金航等[17]通过精简Darknet53骨干网络构建了含30个卷积层的卷积神经网络兼顾检测速度和检测精度。虽然YOLOV3已经取得较好的实时检测效果,但对于道路场景检测来说仍有不足。
本文针对道路目标检测中存在检测精度低和实时性不足的问题,提出一种基于YOLOV3改进的道路目标检测算法。为提高特征提取部分的特征学习能力,对特征提取部分的网络结构作出改进,利用ResNext[18]网络代替原YOLOV3结构中基于ResNet[19]的残差结构,同时采用K-means[20]算法聚类得出锚框参数以提升在特定任务下的目标检测精度,提高模型的检测速度和检测精度。
1 YOLOV3原理
1.1 网络结构概述
YOLOV3的网络结构主要由特征提取部分DarkNet53骨干网络和多尺度预测部分YOLO网络组成。 Darknet-53部分由卷积层、批量归一化层、张量连接层等组成。Darknet-53相比YOLOV2采用的Darknet-19,加深了网络层数,可以充分提取图像的内部特征,并且引入ResNet的残差块结构和跨层连接操作,缓解反向传播中的梯度弥散问题,其处理速度虽然比Darknet-19慢,但是比同精度下的ResNet快。YOLO部分主要由卷积层、批量归一化、激活层组成,借鉴特征金字塔[21]思想,采用多尺度融合的检测方法对不同尺度的目标检测具有较好的鲁棒性。
YOLOV3的网络结构图如图1所示,DBL和Res unit分别表示卷积模块和残差模块,resn(res1、res2…)表示该残差结构中含有n个Res unit模块。其中输入图像的尺寸是416×416×3,在经过特征提取网络DarkNet53处理后,得到尺寸分别为208×208、104×104、52×52、26×26、13×13的特征图。采用上采样和特征融合方法,通过 13×13、26×26和 52×52 三个不同尺度的融合特征图对目标进行独立检测,有效地增强了对大小不同物体和被遮挡物体的检测效果。


图1 YOLOV3网络结构
1.2 多尺度检测
卷积经网络在特征提取过程中, 浅层特征图感受野较小包含位置信息较为丰富,深层特征图感受野较大包含语义信息较为丰富,YOLOV3采用多尺度融合的检测方式,得到分别经过下采样32倍、16倍以及8倍处理的特征图,每个特征图划分为S×S的单元格,每个单元格通过B个预测框对C个类别进行检测,得到每个检测框的坐标信息和置信度。每个特征图的输出维度是S×S×[3×(4+1+C)],式中:S×S是输出特征图的单元格数,3是每个单元格锚框数目,1是预测框的置信度,C是目标类别数,4是每个锚框的网络预测坐标信息tx、ty、tw、th。如式(1)所示,对坐标信息进行解码得到检测框的最终坐标
(1)
式(1)中:cx、cy——网格的坐标偏移量;pw、ph——预设锚框的长宽;bx、by、bw、bh——最终预测框的坐标值;tx、ty、tw、th——网络预测坐标。
如图2所示,对锚框的预测坐标修正得到检测框最终坐标信息,σ(tx)和σ(ty)是预测框中心点基于左上角的坐标点的偏移量,σ是激活函数,pw和ph是预选框的宽和高。
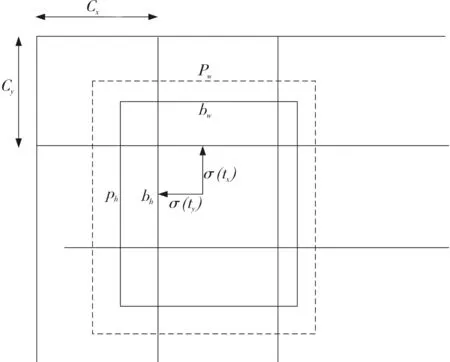
图2 锚框修正图
1.3 损失函数
损失函数作为深度神经网络对误检样本评判的依据,在很大程度上影响神经网络模型收敛的效果。如式(2)所示,YOLOV3的损失函数由坐标误差损失、置信度误差损失及分类误差损失三部分相加组成。坐标损失包括中心点坐标值损失和宽高值损失,采用平方和损失函数,分类误差和置信度误差采用二元交叉熵损失函数,将所有类别的分类问题归结于是否属于这个类别,即二分类问题。交叉熵损失函数可以避免均方误差损失函数出现的因为梯度弥散导致的学习速率降低的问题,只有当预测值和真实值无限接近时,损失才趋近于0,从而保证模型的收敛速度。
(2)
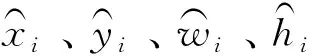
2 改进的YOLOV3方法
2.1 特征提取网络改进
YOLOV3的特征提取网络Darknet-53利用基于ResNet残差网络结构的跳跃连接机制,其中卷积层部分采用1×1和3×3卷积核,通过设置卷积核的个数保证残差结构中的输入和输出的维度保持不变。但是该种卷积层的设置使得参数量过多,检测速度变慢。
为提高道路场景目标的检测速度,本文着重于在保证检测精度的前提下减少参数量。YOLOV3中的Darknet-53主体结构中包含有5组残差网络,每组网络中各包含有1,2,8,8,4个残差模块,每组网络的结构相似,只有卷积核的尺寸和输出的特征图的尺度不同。虽然网络层的深度越深意味着模型的抽象层级会加深,有更强非线性表达能力从而学习到更复杂的表达,可以拟合更加复杂的特征输入,但是网络层过深将导致模型结构过于复杂,训练参数过多导致训练过程繁琐,满足不了实时性并且增大对数据量的要求。如图3所示,将Darknet-53网络进行精简,精简后结构中每组网络包各含有1,2,6,6,4个残差模块,参数量减少17%导致运算复杂度降低从而提高检测速度。
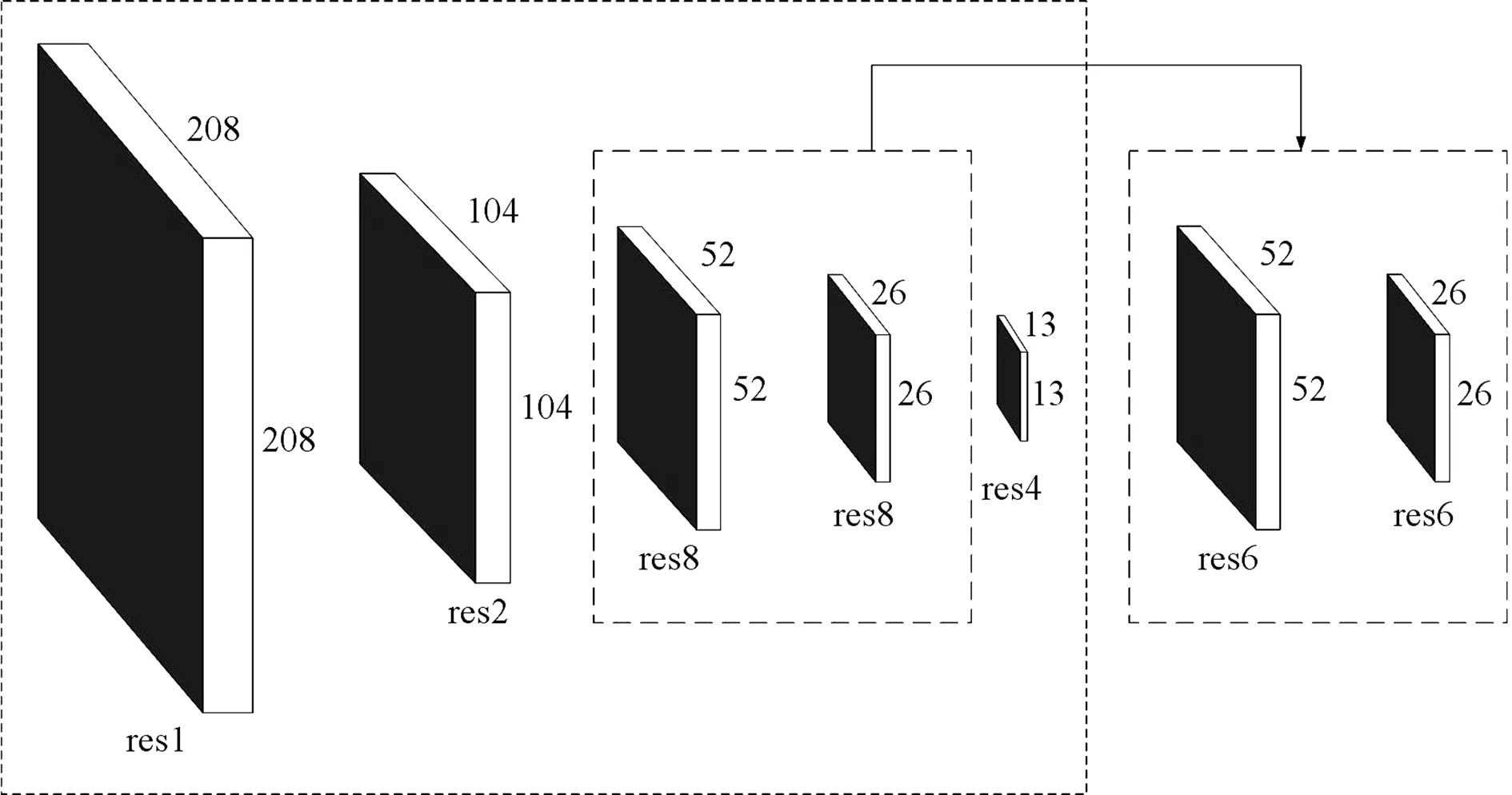
图3 特征提取网络改进
原YOLOV3算法中的残差结构是基于ResNet,利用基于ResNext的残差结构网替换它,ResNet的残差结构和ResNext的残差结构分别如图4(a)、(b)所示。ResNext提出一种介于普通卷积核和深度可分离卷积的策略:分组卷积,通过控制分组的数量达到两种策略的平衡。分组卷积的思想源自Inception,Inception需要人工设计每个分支,而ResNext的每个分支的拓扑结构是相同的。ResNext通过1×1的卷积的网络层控制通道数先进行降维,再进行升维,保证输入和输出的维度保持不变。利用多分支结构提升网络的宽度,让每层结构可以学习到更加丰富的特征,如不同方向、不同频率的纹理特征,进一步提高目标特征的判别能力。假设输入维度和输出维度均为256为例,ResNext网络分为32个分支,如式(3)、(4)所示为二者参数量计算式,虽然ResNext相比ResNet来说增加了网络宽度,但是参数量比ResNet结构少57%,极大降低训练复杂度。
32×(256×1×1×4+4×4×3×3+4×1×1×256)=70144 ,
(3)
256×1×1×64+64×3×3×256=163840,
(4)

(a)基于ResNet的残差结构 (b)基于ResNext的残差结构
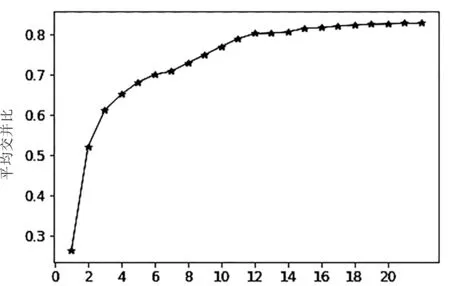
锚框数量/个 图5 锚框数量和平均交并比的关系
2.2 利用K-means确定锚框参数
锚框是Faster R-CNN算法用于取代传统的图像金字塔方法预测多尺度目标开创的一种机制,它的平移不变性和多尺度有利于提取图像中不同尺度目标物体的特征,SSD算法和YOLOV3算法均延续这一机制。Faster R-CNN 在特征图的每个单元格处采用3个不同的尺度和高宽比产生9个锚框,SSD使用6个宽高比生成6个锚框。原YOLOV3采用基于COCO数据集的高宽维度固定的锚框,提前优化锚框的个数和宽高维度可以加快模型的收敛速度并提高检测精度。
本文采用基于K-means的聚类算法,通过对数据集的边界框聚类分析选取最适合数据集的预选框,K-means算法的距离定义如式(5)所示,最终确定锚框参数为(8,7)、(14,10)、(8,22)、(26,21)、(19,16)、(36,20)、(22,49)、(58,32)、(95,59)、(139,194)、(182,187)、(218,198)。
d(box,centroid)=1-IOU(box,centroid),
(5)
式(5)中:box代表样本中提前标注的样本框,centroid代表K-means算法中的聚类中心,IOU 表示样本框大小和聚类框大小的交互比,作为衡量两个框大小相似的度量。
3 实验流程与结果分析
3.1 数据集介绍
采用KITTI[22]数据集,该数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,包含大量采集于市区、乡村以及高速公路等场景中的图像数据,主要应用于目标检测、光流、3D跟踪等计算机视觉任务。
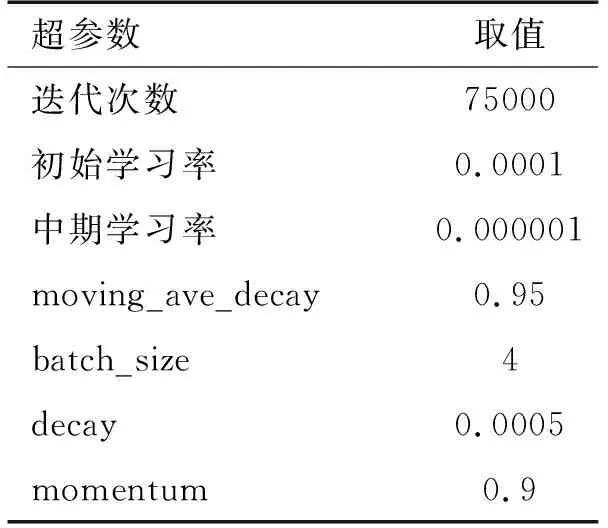
表1 训练期间超参数取值
使用KITTI数据集中应用于目标检测任务的部分,将原数据集的“Car”“Truck”“Van”“Tram”合并为“Car”类,“Pedestrian”“Person (sit-ting)”合并为“Pedestrian”类,“Cyclist”类不变,忽略“Misc”类。选择7481张图片作为实验数据集,其中5000张作为训练验证集,2481张作为测试集。
3.2 实验配置与执行细节
实验在Win10系统上运行,采用英伟达公司的GenForce RTX 2070显卡。深度学习环境是Tensorflow-GPU 1.13、CUDA 10.0、CUDNN 7.5。训练参数如表1所示。
模型采用平均精度(mAP)和检测速度(fps)作为衡量指标如式(6)(7)所示。
(6)
(7)
式中:N代表数据集中的目标种类数目,Pi代表第i个种类的精确度, frame代表帧数,second代表时间(秒数)。
3.3 实验结果分析
如图6所示为本文提出的改进算法在KITTI数据集中的检测效果,图a、b、c、d分别显示了普通道路场景、光照较强的道路场景、具有遮挡物的道路场景、具有遮挡物的光照较强的道路场景中的检测实例。图6(a)中包含尺度大小不同的车辆,图6(b)中包含处在较强光照环境中的行人,图6(c)中包含相互遮挡的车辆目标,图6(d)中包含处在较强光环境并且相互遮挡的车辆目标,从检测效果图中可以看出该算法在复杂多样的道路场景目标检测任务中具有较好的鲁棒性,但是对某些光照较强环境的小目标检测效果不理想,比如图6(b)中较远处的小目标被漏检。
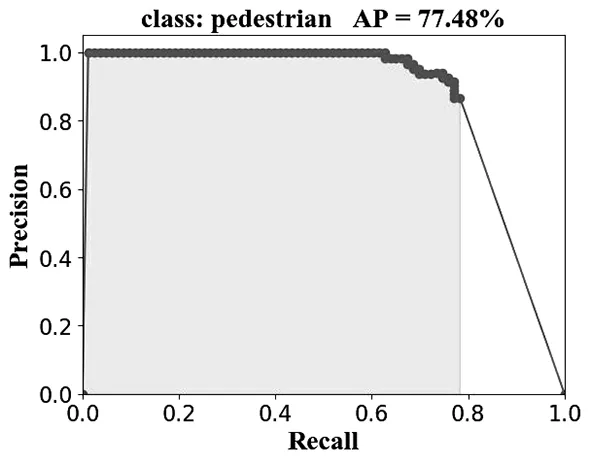
将YOLOV3算法和本文改进的YOLOV3算法分别进行训练,在KITTI测试集上通过检测精度测试其性能。通过比较真实值和计算值的误差计算模型的查全率(recall)和查准率(precision),计算P-R曲线下面积(area under curve,AUC),验证本文改进算法的性能。如图7所示,其中 a、b、c、d子图中左右分别为原算法及改进算法P-R曲线图及mAP值,本文改进的YOLOV3算法在“Pedstrain”“Cyclist”“Car”类中AP值分别提高3.47%、1.50%、0.91%,整体的mAP值为87.60%,相较于原YOLOV3算法的85.68%提高1.92%。综上所述,本文改进算法在“Pedstrain”“Cyclist”“Car”类的检测中均取得检测精度的提升。
3.4 不同目标检测算法之间的对比
为进一步验证本文改进算法的性能,利用Faster R-CNN、SSD、YOLOV3等目标检测算法在KITTI数据集上进行测试,通过对比检测精度和检测速度两个指标对上述算法和本文改进算法比较,如表2所示,本文的改进算法在检测精度上相对于SSD、Faster R-CNN、原YOLOV3等分别有6.12%、4.86%、1.92%的提高,并且本文改进算法的检测速度达到75.32fps,相比于原YOLOV3算法有了显著的提高,在实际道路场景检测中可以满足实时性。
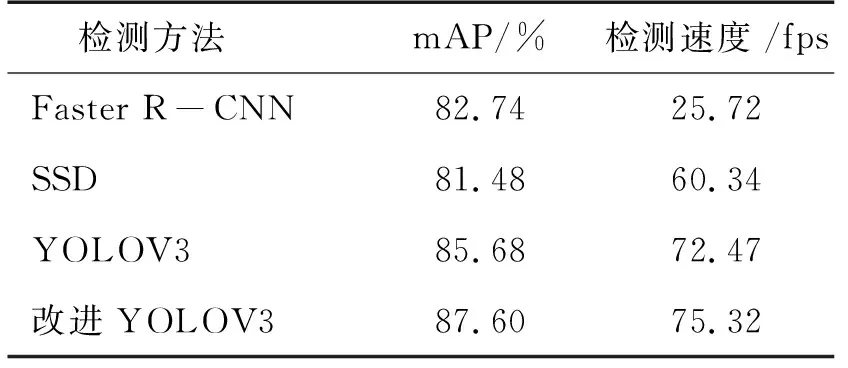
表2 不同方法在KITTI数据集上的效果对比
综上所述,本文的改进YOLOV3的性能相比原YOLOV3有所提升,通过K-means算法聚类得出适合于数据集的锚框参数,使目标的定位更加准确;对特征提取网络作出精简,利用多分支网络提升网络的特征学习能力,兼顾了检测速度的同时提高了检测精度。但是复杂多变的背景环境和光照条件、目标之间的遮挡、目标距离的动态变化、精确性与实时性的兼顾是道路场景目标检测面临的主要挑战。
4 结论
提出一种基于YOLOV3改进的道路目标检测算法,对特征网络结构作出精简和改进,利用K-means聚类分析确定锚框参数。实验表明,本文的改进算法比原YOLOV3算法的检测效果好,可用于实际的道路场景目标检测任务中。然而道路目标检测领域依然具有一定挑战性,在后续的研究中,还需要注重在保证实时性的前提下提高复杂场景中目标检测的精确度,减少容易误检、漏检的情况。相信随着深度学习技术的进一步发展,智能交通将带来前所未有的出行体验,并且随着硬件设备的发展,运算量将不会成为实时检测的掣肘。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
河南科技(2015年8期)2015-03-11 16:23:52
