
基于卷积神经网络的道路多目标检测方法
2021-04-21 14:15迟志诚
汽车实用技术 2021年7期
迟志诚
基于卷积神经网络的道路多目标检测方法
迟志诚
(长安大学 汽车学院,陕西 西安 710064)
得益于数字图像处理技术快速的发展和计算机硬件性能的提高,基于机器学习和深度学习的图像处理技术,成为智能驾驶视觉感知的重要支撑。为了在实际道路环境中持续高效的检测道路目标,文章利用了YOLO神经网络作为主要检测框架。使用卷积神经网络可以同时捕捉到目标的底层和高层特征。物体的底层特征可以符合人的视觉感知特征和主观感受,确定物体的所属种类和外观形状,将底层特征与高层语义特征结合进一步增强神经网络识别的准确度和鲁棒性。
卷积神经网络;目标识别;自动驾驶;YOLO v3
前言
环境感知作为智能驾驶实现第一环节,位于智能驾驶车辆与外界环境信息交互的关键位置,是实现车辆自动驾驶的前提[1]。实现高级别的智能驾驶正是要让车辆模拟人类驾驶员的感知和决策能力,凭借机器更快的运算速度和环境识别能力,弥补人类驾驶员在行驶过程中的缺陷,达到减少交通事故发生,提高交通安全环境的目标。相机、雷达、定位导航系统等为智能驾驶车辆提供了海量的道路环境和车辆本身运行状况的数据,这些包含诸如图像,激光点云等形式的数据构造出了整个车辆的运行环境。
在相机等光学设备的观测下,车辆和行人的外观、颜色和大小会随着光线,距离等因素发生变化。当地的天气条件如雨、雾等也会影响光学仪器的正常工作。在恶劣的天气条件下,相机只能拍摄到低分辨率图像,造成检测器无法正常检测、跟踪目标,影响了驾驶系统正常工作。这就要求目标检测算法具有鲁棒性、准确性和实时性的技术特点。为了解决目前存在的影响目标跟踪精度的问题,我们基于YOLO v3[2]对原有目标检测框架进行了一系列改进,使算法在保证实时运行的同时,增强其在复杂环境下的识别精度和准确度,提高了算法的鲁棒性。
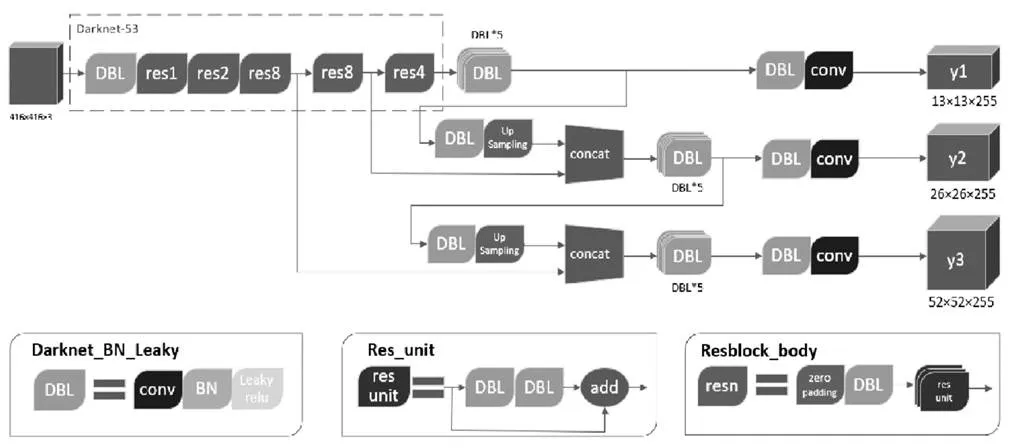
图1 YOLO v3整体结构图
1 YOLO v3神经网络
1.1 网络结构
目前主流的目标检测算法大致可以被分为两类,即两步式和一步式的检测算法[3]。与两步式检测算法不同的是,YOLO v3作为一种基于卷积神经网络的目标检测方法,可以直接针对目标的位置和类别作出预测。合理的网络结构和检测算法的改进保证了YOLO v3运行速度的同时也实现了与两步式算法相同的检测精度。
YOLO v3首次使用了Darknet-53神经网络,借助残差结构可以更有效的提取图像中丰富的语义特征信息,使神经网络在训练时可以学习到更具有辨别力的外观模型,在一定程度上也可以加速模型的收敛。在主干网络的后面则采用了多尺度预测,保证了目标检测框架对大目标和小目标的检测精度,使得检测框架可以完全捕捉图像中的目标特征。
1.2 Darknet-53
YOLO v3使用了Darknet-53神经网络的前52层作为整个检测框架的核心网络。在深度学习任务中,伴随着卷积层数的加深,网络会发生“退化”现象,即训练时的损失函数不会随着网络深度的增加而一直下降,而是在达到饱和以后反过来逐渐增加。为了解决网络退化问题,Darknet-53大量采用了残差单元连接,以尽可能减少全卷积网络的梯度退化问题。如图示的5个残差块当中,每个残差块的结构相同,即由零值填充层和最基本的卷积归一化单元作为前半部分,多个残差单元与其连接共同组成一个完整的残差块。
1.3 多尺度预测
如图所示,YOLO v3结构中有两次上采样的过程。在骨干网络输出图像的特征向量以后,我们得到了32倍降采样的结果,但是降采样后的特征太小,仅仅关注了图像中细小特征,对较大尺寸的物体的检测效果不足。因此使用了两次步长为2的上采样,将32倍降采样的结果的大小分别增加一倍和两倍,这样可以充分利用网络中的深度特征和浅层特征,两者通过张量拼接结合,随后通过一系列的卷积池化操作,输出最终的目标位置和预测类别。
2 运行过程
本文使用Python语言基于Tensorflow深度学习框架构建了目标检测框架。使用的计算机配置为8核 3.4GHz Intel Core i7-3770和NVIDIA GeForce GTX 1080Ti的GPU,内存容量为16G。预训练采用PASCAL VOC 2007和2012数据集,设置训练时的批量大小为64,训练次数为200次。使用Adam自适应梯度下降法,设置权重衰减和动量的值分别为0.9和0.0001。

图2 目标检测结果
选择MOT 16[4]多目标跟踪数据集中具有代表性的场景图片进行测试,可直观地观察YOLO v3目标检测网络在实际道路环境下的检测效果。从图像上可以看出,大部分目标的置信度分数在60%以上,同时也没有出现类别误判的现象,行人和车辆的位置信息和类别信息可以准确的标定和输出。在部分目标出现遮挡或者缺失的情况下依然可以在正常完成道路目标检测的工作。
3 结论
全卷积神经网络的YOLO v3算法可以很好地完成道路上多目标的检测任务,在保证检测精度的同时也可以做到实时性。目标检测算法可以提高自动驾驶车辆对周边环境的感知程度,一定程度上增加车辆安全性能,也为诸如道路多目标跟踪等视觉感知任务作出了铺垫。
[1]《中国公路学报》编辑部.中国汽车工程学术研究综述·2017[J].中国公路学报,2017,30(06):1-197.
[2] Redmon J, Farhadi A.YOLOv3:An Incremental Improvement[J].ar Xiv e-prints, 2018.
[3] 卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(01):1-17.
[4] Milan A,Leal-Taixe L,Reid I, et al. MOT16:A Benchmark for Multi- Object Tracking[J].2016.
Multiple Object Detection Method Based on Convolutional Neural Networks on Road
Chi Zhicheng
( Chang'an University, School of Automobile, Shaanxi Xi’an 710064 )
Because of the rapid development of digital image processing technology, image processing technology based on machine learning has become an important support for the visual perception of intelligent vehicle.In order to continuously and efficiently detect targets in the actual road environment, we use the YOLO v3 neural networks as the main detection framework. This network can simultaneously capture the bottom and high-level features of the target. The low-level features of an object can conform to human visual perception features and subjective feelings, determine the type and appearance of the object. We combined the low-level features with high-level semantic features to further enhance the accuracy and robustness of neural network recognition.
Convolutional neural networks;Object recognition;Autonomous driving;YOLO v3
10.16638/j.cnki.1671-7988.2021.07.008
U471.1
A
1671-7988(2021)07-23-02
U471.1
A
1671-7988(2021)07-23-02
迟志诚(1996-),男,长安大学研究生,车辆工程专业,研究方向为汽车NVH。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算机仿真(2022年7期)2022-08-22
舰船科学技术(2022年11期)2022-07-15
成都信息工程大学学报(2022年2期)2022-06-14
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
煤气与热力(2022年2期)2022-03-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
