
基于熵值赋权的粒子群聚类方法研究
2021-04-20 02:36李楚贞林剑添
电子技术与软件工程 2021年1期
李楚贞 林剑添
(广东理工学院信息技术学院 广东省肇庆市 526100)
随着网络销售在企业销售占比的增长,众多企业对网络销售相关运营数据的关注度日益提高。网络销售的运营数据获取成本低,且和门店运营数据相比,有更多的指标去反映消费者的消费行为信息,如商品详情页跳出率、消费者平均停留时长等,这些指标是在门店销售的运营中无法低成本获得的。有效的数据挖掘工作一方面可以帮助企业深层次地挖掘消费者的消费情况,为消费者提供个性化服务,另一方面基于产品运营数据进行商品重分类,从而为企业制定运营策略提供决策指导[1]。
对于电商运营数据的聚类研究,传统研究视角是基于消费者行为数据进行聚类分析。韩利东基于消费者购买商品记录,通过聚类将相似的消费者归为同一类簇,从而实现个性化服务[2]。王越通过基于改进遗传算法的模糊聚类对电子商务用户数据进行聚类分析[3]。钱丹丹研究商业智能(BI)体系下的大数据应用于消费者行为预测,主要对顾客购买药片的频率、消费金额和消费者价值进行聚类分析,以此作为消费群体划分的依据[4]。电商产品数据特征更易获得,同时对产品的重分类问题的研究更有利于库存订货策略[5]。本文从电商服装产品的视角出发,采用基于熵值赋权的粒子群聚类方法对服装产品销售平台的支付转化率、访客数、详情页跳出率、平均停留时长、访客平均价值、客单价进行聚类,并以此为依据对产品进行销售预测划分。
粒子群优化算法是通过群体中不同粒子之间的合作和相互竞争来实现在寻优空间中的搜索过程以找到所求问题的最优位置[6]。由于算法结构构造简单,参数少,涉及专业知识少,易于实现,得到广泛的科研工作者的关注与应用[7-8]。本文在文献[9]的基础上改进粒子群聚类方法,对运营指标引入了熵值赋权,采用轮廓系数作为聚类结果的评价指标,将其与传统粒子群聚类及K_Means 聚类算法的聚类效果作比较。
1 数据规范化与指标赋权
原始数据采集于某商务男装企业电商平台上某一季度的电商后台数据,其后台的数据指标众多,然而电商运营的关注点始终在服装产品的热卖程度、消费者的购买意愿及消费者购买情况上[10]。本文选用服装产品中6 个可量化的运营指标,分别是支付转化率、访客数、详情页跳出率、平均停留时长、访客平均价值、客单价,其指标含义如表1所示。支付转化率和访客数反映该商品的热卖程度;商品详情页跳出率和平均停留时长反映商品详情页设计对访客的吸引力,是消费者购买意愿的体现;访客平均价值和客单价反映消费者的购买情况。
1.1 数据规范化处理
原始数据共670 条,考虑到运营数据的分析价值,删除支付转化率为零的运营数据和奇异值数据,剩余有效数据472 条。粒子群算法初始速度的设定需要消除各个运营指标量纲与数量级的差异,故需要对数据进行标准化处理。这里使数据标准化的方式是平移——标准差变换后,采用文献[11]的数据处理公式进行归一化:

表1:电商运营指标含义

式中:Xip为第i 个样本的第p 个特征分量。
1.2 指标赋权
聚类分析的本质是根据数据自身的特征,按照某种要求对数据进行分类,使具有相似特征的数据归集为一类,数据聚类的基本原则是类间差距尽可能大,类内差距尽可能小,以便对数据的共性进行分析[12]。为了达到这种效果,本文采用熵值赋权的方式对各个指标进行赋权处理。
其熵值赋权的流程为:①确定指标的比重;②确定指标的熵值;③确定指标的差异系数;④确定指标的权重。运用到的公式具体如下:

式中:Pij为第i 个样本第j 个指标的比重;N 为样本量。

式中:ej为第j 个指标的熵值;k=1/1nN。

式中:gj为第j 个指标的差异系数。

式中:ωj为第j 个指标的权重。
2 改进的粒子群聚类方法
根据聚类问题的本质,将N 个样本对象聚成K 个类簇,并满足目标函数最小。一般采用欧式距离的平方构成目标函数,这里在文献[9]的目标函数的基础上进行改进,公式为:

图1:基于熵值赋权的粒子群聚类算法流程
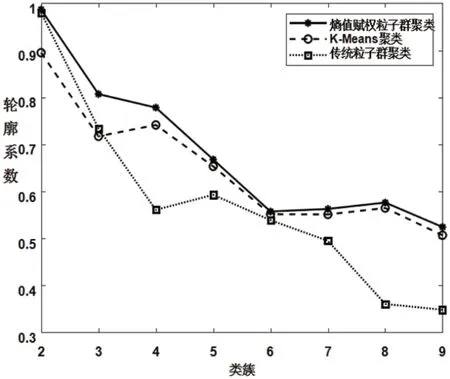
图2:各算法平均轮廓系数

式中:Xip为第i 个样本的第p 个特征分量;c 为1 个K×N 的聚类中心矩阵;Cjp为第j 类的第p 个特征分量;wij为N×K 的布尔矩阵,当wij=1 时,样本i 属于第j 类,当wij=0 时,样本i 不属于第j 类。
2.1 粒子的分布

图3:聚类数目为3 的雷达图
粒子群算法用于聚类有两种方法[9]:一种是目标函数所求的解为聚类结果,结果需要取整表示,取整过程加入惩罚函数等措施,会影响算法的寻优能力和计算复杂性;另外一种是解就是聚类中心,寻优过程易于实现。故本文采用第2 种方法。若将N 个样本聚成K类,则每个粒子的位置由K 个聚类中心组成。
在样本数据中随机选取K 个样本作为初始聚类中心,即作为粒子群的初始位置,初始聚类中心根据式(7)和粒子的速度与位置更新聚类中心。
2.2 粒子速度和位置的更新
粒子通过跟踪个体极值pbesti和群体极值gbest 来跟新自己的位置,使得自己的位置与目标函数的距离不断缩小。粒子速度与位置的更新公式[13]为:

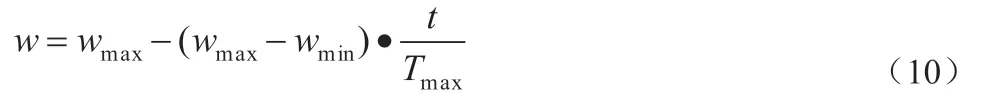
式中:Tmax为最大迭代次数,t 为当前迭代次数,wmax,wmin分别为开始时和结束时的权重。
2.3 粒子群算法的改进
式(10)是应用比较广泛的惯性权重更新的算法,基于进化代数进行更新,每一代粒子无论好坏都采用同样的惯性权重,前期大范围全局搜索,后期小范围搜索,可能导致错过最优粒子,后期不易跳出局部极值,收敛速度较慢[13]。这里采用随机权重,当粒子在起始位置接近最优点,可能产生较小的权重,正好克服惯性权重的缺点。公式为:

式中:N(0,1)为标准正态分布;σ 为标准差,一般取0.3 或0.5;rand 为[0,1]区间的随机数。
2.4 基于熵值赋权的粒子群聚类的实施步骤
基于熵值赋权的粒子群聚类算法主要执行过程如下:
(1)数据标准化后,求出各个指标的权重;
(2)随机选取初始聚类中心;
(3)根据式(6)计算适应度函数值,求得个体最优解和全局最优解;
(4)根据式(11)和(12)分配权重,采用式(8)和(9)更新粒子速度与位置,得到新的聚类中心,按适应度函数进行重新聚类;
(5)根据新的聚类结果采用式(7)重新计算聚类中心,更新适应度函数。

表2:各个运营指标的赋权权重

表3:聚类类别为3 的聚类结果

表4:聚类类别为4 的聚类结果

表5:聚类类别为5 的聚类结果
本文提出的基于熵值赋权的粒子群聚类,具体实现流程如图1所示。
3 运行结果与聚类效果评估
3.1 运行结果
将运营数据标准化后,由式(2)、(3)、(4)、(5)计算得到各个运营指标的赋权权重,如表2所示。
由表2可知,ω5>ω6>ω2>ω1>ω4>ω3,表明运营指标中,访客数、访客平均价值、客单价在样本中的数据差异化较大,为了更好依据其差异进行聚类,赋予更大的权重,使数据差异更加明显。
(1)采用熵值赋权后的数据,按上文粒子群算法流程进行聚类,取wmax=0.8,wmin=0.3,c1=c2=2,σ=0.5,Tmax=100,群体规模s=100,依据期望聚成不同类别的数目,可得到相应的聚类结果。
(2)采用标准化数据,数据不经过熵值赋权,参数取值同(1),可以得到相应的聚类结果。
(3)采用K_Means 聚类方法,数据经过预处理后,不经归一化和熵值赋权处理,直接进行聚类,根据初始聚类中心随机选取,得到聚类结果。
3.2 聚类效果评价
从单纯的计算结果不易评估聚类的优劣,需要借助于聚类评估模型,通常采用FMI,轮廓系数法,Calinski-Harabasz 评价模型等研究聚类效果。这里采用轮廓系数来评价聚类的效果,其包含类内相似程度和类间差异度[14]。其公式为:

式中:Si∈[-1,1],为元素i 的轮廓系数,取值越大,说明该次聚类效果越好,当Si<0 时,说明当前的聚类效果较差;a 是元素i与同类的其他点之间的平均距离;b 为一个向量,其元素是第i 个点与不同类的类内各点之间的平均距离。将基于熵值赋权粒子群聚类、K_Means 聚类和传统粒子群聚类及的聚类结果,运用式(13)进行计算,并取相应类别的均值,为了保证结果可靠性,每种聚类方法计算20 次,再取均值,结果如图2所示。
由图2可知,在基于熵值赋权粒子群聚类的聚类、K_Means 聚类及传统粒子群聚类聚类的聚类结果中,平均轮廓系数最大的是运用基于熵值赋权粒子群聚类算法所获得的聚类结果;K_Means 聚类的聚类结果次之;传统粒子群聚类聚类的聚类结果比K_Means 聚类的稍小。这表明聚类效果:基于熵值赋权粒子群聚类算法 > K_Means 聚类算法 > 传统粒子群聚类聚类算法。
4 聚类结果对电商运营的管理分析
聚类方法可在对数据样本信息知之甚少的情况下将其自动归类,使原本杂乱无章的数据清晰化、条理化。基于上述聚类效果,采用基于熵值赋权粒子群聚类,将聚类数目分别聚为3、4、5,并以聚类数目3 为例,使用雷达图分析法对聚类结果进行分析,阐述聚类结果背后电商服装产品运营的管理价值。聚类结果如表3、表4、表5所示。
由图3可知,服装产品运营数据被聚成3 类,类别1 的客单价、访客平均价值、平均停留时长都是最大的,可见类别1 产品吸引高质量的消费者的,但产品占比不高,需要多引进该类产品;类别2访客量最大,商品详情页跳出率最好,说明该类产品页面设计比较吸引消费者的眼球,其产品占比最大,但消费群质量不高,建议考虑产品成本进行订货和销售;类别3 支付转化率最高,该类产品容易吸引新消费群并完成交易,说明这类产品是促销产品,主要用于吸引流量,其价值主要在淡季体现出来。由分析可知,通过算法可以将服装产品的运营数据背后的管理价值呈现出来,表明该算法可以为电商企业的日常运营管理提供决策依据。
5 结论
本文通过对电商后台数据采集、预处理、标准化、熵值赋权及随机粒子群优化聚类,计算出聚类结果,并用K_Means 聚类、传统粒子群聚类聚类计算出聚类相应的聚类结果,运用轮廓系数对三种聚类算法的结果进行评估。结果表明,基于熵值赋权的粒子群聚类算法的平均轮廓系数比其他两种聚类算法大,即其分类效果比其他两种聚类算法好。以聚类数目3 为例,使用雷达图分析法对聚类结果进行分析,分析了聚类结果背后电商服装产品运营数据的管理价值,表明该算法可以为电商企业的日常运营管理提供决策依据。
猜你喜欢
中国西部(2022年2期)2022-05-23
南大法学(2021年6期)2021-04-19
当代陕西(2020年17期)2020-10-28
活力(2019年15期)2019-09-25
测控技术(2018年6期)2018-11-25
人大建设(2018年5期)2018-08-16
电子测试(2017年15期)2017-12-18
电信科学(2017年6期)2017-07-01
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
