
城市轨道交通工程施工安全事故聚类分析
2021-04-13 02:23杨志勇刘东军翟世鸿曾德星
科学技术与工程 2021年7期
刘 文, 杨志勇, 刘东军, 翟世鸿,4, 曾德星
(1.中交第二航务工程局有限公司, 武汉 430040; 2.华中科技大学土木工程与水利学院, 武汉 430074; 3.交通运输行业交通基础设施智能制造技术研发中心, 武汉 430040; 4.长大桥梁建设施工技术交通行业重点实验室, 武汉 430040)
城市轨道交通工程施工过程中安全事故的问题日趋凸显,如何保证城市轨道交通工程的安全施工,受到全社会广泛关注[1-2]。对城市轨道交通工程施工风险因素的相关文献研究表明,现阶段鲜见专门管理城市轨道交通工程事故报告的数据库,使研究人员获取信息受到较大限制,这对城市轨道交通工程施工安全风险管理是十分不利的[3-4]。
在城市轨道交通工程施工安全风险相关文献研究过程中,发现目前没有建立城市轨道交通工程施工事故报告管理的具体数据库。研究人员仅针对部分发生的城市轨道交通工程施工事故进行了基础性风险分析。例如,Lee等[5]对中国台湾高雄地铁施工发生的地表塌陷事故进行研究,归结事故原因为管涌或水力劈裂引起的地下水失控漏水,导致了盾构机开挖面的涌水涌砂。Copur等[6]对伊斯坦布尔锡利夫里市盾构机掘进室内发生的严重甲烷爆炸事故进行研究,推测事故原因为螺旋输送机和套管之间的摩擦火花,引起开挖室所用泡沫剂中氧气与地层中甲烷之间产生爆炸。尽管职业安全与健康管理局(occupational safety and health administration, OSHA)数据库(2000—2016)包含17种工程建设项目,但没有关于城市轨道交通工程建设项目事故案例的数据库。因此,现创新性建立结构化的城市轨道交通工程施工安全事故数据库,应用K-means聚类分析方法来获取安全事故的潜在风险,确定施工中的主要突发及常规事故,采用对应安全管理措施来降低安全事故的发生具有重要意义。
现从客观角度切入,采用定性和定量分析方法对城市轨道交通工程施工安全事故案例报告进行结构化研究。首先,收集281项城市轨道交通工程施工事故案例报告,通过定性分析形成事故数据库,作为深入定量分析的原始材料;并且将事故后果严重程度定义为从“1”(轻微损失)到“5”(死亡)的五点量表;然后,基于数据库的变量定义进行聚类分析建立集群。将每个集群发生各种严重程度后果的情况与其他集群以及整个数据库相比较,形成该集群潜在风险可能性的量化结果。
1 基于K-means的安全事故聚类
K-means聚类算法为常用无监督学习的基础方法[7],其主要步骤如下:
1.1 特征向量和事故距离确定
聚类分析首先需要根据一组变量定义每个事故,即描述事故的特征向量[8]。聚类分析的解完全依赖于所选的特征向量,特征向量的合理选择对聚类分析结果的可靠性至关重要。
表1总结了文献中用以描述城市轨道交通工程施工安全事故的相关变量。显然,在以往的研究中经常考虑诸如日期(季节/星期/时间)、事故的严重性、作业(盾构机)的状态、事故的阶段、事故的类型和事故的原因等变量,而考虑“合同安排”变量的情况较少。所建立的数据库中采用8个变量,包括季节、时间段、作业状态、事故的严重程度、盾构机的状态、事故的阶段和事故的原因,对收集到的281个安全事故进行详细描述,具体由变量组成。

表1 安全事故数据库具体分类及其变量组成Table 1 Specific classification and variable composition of safety accident database
每个安全事故都由8个向量描述,整个数据库由一个281行8列矩阵表示。以矩阵来描述安全事故的形式,使得数据库具有模块化的特征,便于通过增加或删除变量,实现对安全事故特征向量的持续改进。
然后将事故转换为特征向量。事故发生原因由25个变量表示,若事故发生原因变量的值为1~25,则表明该变量是此次事故的发生原因。以事故1为例,01表示事故1的发生原因为:始发-到达端洞口土体加固及降水不当,其他所有事故发生原因变量的值均设为0,以此类推。
聚类将使类似的事故分为一组。事故的相似性通过规定的距离度量来评估。为了量化数据库中的安全事故之间的距离,首先进行数据min-max标准化(归一化)处理,使数据指标之间具有可比性。然后,使用欧氏距离式(1)来定义两个事故向量之间的距离[10]。

(1)
式(1)中:ni为数据库中事故的数量,n=281;j为每个事故的第j个组成元素;xij及yij为向量取值;d为矩阵元素的值为事故之间的距离。
任意一对事故之间的距离用n×n矩阵表示,矩阵对角线上的元素表示一个事故到自身的距离,其值为零,由于从事故1到事故2(d12)的距离与从事故2到事故1(d21)的距离相同。
1.2 风险程度
基于庞大的安全事故数据库,评估事故的风险程度,首先,计算给定事故造成给定后果严重度水平的次数。然后,计算每个后果严重度水平发生的概率,以获得事故导致给定后果严重度水平的百分比。从现有数据库中识别相似的集群评估风险程度。根据式(2)计算风险程度,识别每个集群中,各个事故最后发展成某一后果严重度水平事故的可能性。以此类推,每个事故无论其后果,均可确定成为给定等级事故的可能性。
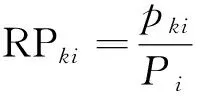
(2)
式(2)中:RPki为集群k在后果严重度水平i的风险程度;k为集群的编号;i为事故后果严重度水平,i=1~5;Pi为发生不同后果严重度水平的事故在数据库中的比例,%;pki为发生不同后果严重度水平的事故在每个集群中的比例,%。RPki越大,表示在i后果严重程度水平的风险程度越大。当发生i后果严重度水平的事故在集群k中的比例高于发生i后果严重度水平的事故在数据库中的比例时,RPki的值大于1,反之,RPki<1。
1.3 决定集群数
1.3.1 盾构法(含明挖基坑)聚类分析过程
聚类分析的第一次运行,包括了盾构法(含明挖基坑)安全事故数据库201个事故的8个变量属性,通过测量欧氏距离处理变量整体结构,当k=5时产生结果。然而,其最大轮廓值为0.446,最大平均轮廓系数值为0.306,结果不理想。因此,使用8个变量聚类评估风险程度是不够的,须减少数据库结构维数(变量数),以达到良好的聚类效果。
Balbi[11]提出了一种降低维数和消除不相关变量的方法,使得可用较低维数和较少噪声的系统表示数据信息。例如,星期一和星期二与星期三和星期四发生事故几乎没有区别。因此,在排除了与背景有关的变量(即季节、时间、工作日和施工作业状态)之后,执行k=4,5,6第二轮聚类分析,即将盾构法(含明挖基坑)安全事故数据库聚类为4、5、6类。通过对比不同聚类数目情况下的轮廓系数(图1),判断轮廓系数值大小,最终确定盾构法(含明挖基坑)安全事故聚类结果。

图1 盾构法(含明挖基坑)安全事故轮廓系数值对比Fig.1 Numerical comparison of safety accident contour coefficient of shield method
由图1可知,当k=6时,数据库的聚类平均轮廓系数值最大,即盾构法(含明挖基坑)安全事故数据库聚类为6类时结果聚类最佳。通过构法(含明挖基坑)安全事故数据库聚类算法运行结果可得结论:①显著的群集具有“合理的”结构;②所有其他集群也是结构化的,但只是较弱的结构;③使用8个变量维度的聚类结果被丢弃,因为其包含非结构化数据(最大轮廓值及最大平均轮廓系数值并不理想);④聚类数k=6时,盾构法(含明挖基坑)安全事故结果最为理想。
1.3.2 矿山法聚类分析过程
在排除了与背景有关的变量(即季节、时间、工作日和施工作业状态)之后,执行k=4,5,6聚类分析运行,即将矿山法安全事故数据库聚类为4、5、6类。通过对比80个事故不同聚类数目情况下的轮廓系数(图2),判断轮廓系数值大小,最终确定矿山法安全事故聚类结果。
由图2可知,当k=4时,平均轮廓系数值最大,即矿山法安全事故数据库聚类为4类时结果聚类最佳。通过矿山法安全事故数据库聚类算法运行结果可得结论:①当k=5,6时,显著的群集不具有“合理的”结构,第二聚类集群仅一件事故;②当k=5,6时,所有其他集群也是结构化的,但只是较弱的结构;③当k=4时,矿山法安全事故结果最为理想。

图2 矿山法安全事故数据库轮廓系数值对比Fig.2 Numerical comparison of contour coefficient of mine safety accident database
2 安全事故整体结果分析
2.1 盾构法(含明挖基坑)施工
对整个数据库的事故安全风险因素分布进行分析,确定最常见的特征,并与其他特征进行比较,以评估其重要性。根据安全事故风险因素随盾构法(含明挖基坑)施工时间在整体数据库的分布变化,拟合安全风险变化曲线,如图3(a)所示。它是以施工时间为横坐标,以事故安全风险因素(FD)整体数据库百分占比为纵坐标的一条曲线。该曲线规律显示:①FD1始发-到达端洞口土体加固及降水不当;②FD8盾构开挖面土体失稳;③FD18穿越临近建构筑物、江河湖等特殊工况风险;④FD22基坑开挖及支撑体系施工不当,对盾构法(含明挖基坑)施工安全有显著的影响。

图3 盾构法(含明挖基坑)施工安全风险变化曲线规律Fig.3 Curve rule of safety risk in shield method
对整个数据库的事故所处施工阶段分布进行分析,确定事故发生最为频繁的施工阶段,并与其他阶段进行比较,以评估其重要性。根据安全事故施工阶段随盾构法(含明挖基坑)施工时间在整体数据库的分布变化,拟合安全风险变化曲线,如图3(b)所示。它是以施工阶段为横坐标,以事故所处施工阶段(SD)整体数据库百分占比为纵坐标的一条曲线。该曲线规律显示SD1盾构始发阶段、SD2掘进阶段和SD10明挖土方开挖阶段对盾构法(含明挖基坑)施工安全有显著的影响。
综上所述,根据客观发生的盾构法(含明挖基坑)施工安全事故,构建的结构化数据库的变量整体分布,拟合得出了盾构法(含明挖基坑)施工全过程安全风险变化曲线规律,体现了盾构施工在不同阶段内安全风险高低的规律。基于安全风险变化曲线,得出盾构始发与掘进、明挖土方开挖阶段为重点阶段,始发-到达端洞口土体加固及降水不当、盾构开挖面土体失稳、穿越临近建构筑物、江河湖等特殊工况风险及基坑开挖及支撑体系施工不当为主导风险因素的结论。
2.2 矿山法施工
对整个数据库的事故安全风险因素分布进行分析,确定最常见的特征,并与其他特征进行比较,以评估其重要性。根据安全事故风险因素随矿山法施工时间在整体数据库的分布变化,拟合安全风险变化曲线,如图4(a)所示。它是以施工时间为横坐标,以事故安全风险因素(FK)整体数据库百分占比为纵坐标的一条曲线。该曲线规律显示:①FK1断层、围岩地质松散、地下水、不明障碍物、管线、有害气体等不良复杂地质条件;②FK6掌子面失稳(如含水率变化等)、FK7初期支护不及时、施工不当(临时支撑不合理或过早拆除等),对矿山法施工安全有显著的影响。

图4 矿山法施工安全风险变化曲线规律Fig.4 Curve rule of safety risk in mining method
对整个数据库的事故所处施工阶段分布进行分析,确定事故发生最为频繁的施工阶段,并与其他阶段进行比较,以评估其重要性。根据安全事故施工阶段随矿山法施工时间在整体数据库的分布变化,拟合安全风险变化曲线,如图4(b)所示。它是以施工阶段为横坐标,以事故所处施工阶段(SK)整体数据库百分占比为纵坐标的一条曲线。该曲线规律显示SK3隧道开挖施工阶段对矿山法施工安全有显著的影响。
综上所述,根据客观发生的矿山法施工安全事故,构建的结构化数据库的变量整体分布,拟合得出了矿山法施工全过程安全风险变化曲线规律,体现了矿山法施工在不同阶段内安全风险高低的规律。基于安全风险变化曲线,得出隧道开挖施工阶段为重点阶段,断层、围岩地质松散、地下水、不明障碍物、管线、有害气体等不良复杂地质条件为主导风险因素的结论。
3 施工事故聚类集群结果分析
3.1 盾构法(含明挖基坑)聚类集群
3.1.1 盾构法(含明挖基坑)施工事故聚类集群
为了更好地解释已确定的6个集群(k=6时)的特征和模式,本节对每个集群的风险程度进行了详细的评估和分析。具体而言,k组中所有事故的风险程度,定义为第k个聚类分组事故发生率pki与整体数据库事故发生率Pi的比值。根据式(2)计算风险程度值。
在盾构法(含明挖基坑)施工现场,应该高度重视“死亡”这类严重的后果。对于“死亡”后果严重水平,第3、6集群显示出高风险程度,其风险程度的结果都大于1。其中,由于RP35和RP65为最高值,并且在轻微伤害、重大伤害风险程度值都大于1,可认为第3和6组聚类集群具有最高的风险程度。相比之下,集群1的轻微伤害、重大伤害、死亡风险程度计算结果都小于1或者等于0,并且在最低事故严重程度的轻微损失风险程度表现出较高可能性。因此,可认为第1组聚类集群具有最低的风险程度。
3.1.2 盾构法(含明挖基坑)高风险程度集群
在“死亡”和“重大伤害”方面,集群3和集群6的风险程度评级最高,确定集群3和集群6具有高危风险的最高可能性。对比分析集群和整体数据库变量的计算结果,如图5及表2,其具体特征如下:

图5 确定的6个聚类群集安全风险因素数据分布Fig.5 Data distribution of security risk factors of six clusters determined

表2 确定的6个聚类群集安全风险因素数据表Table 2 Data table of security risk factors of six clusters determined
(1)集群3和集群6主要包含的工作阶段变量分布显示盾构始发阶段、盾构到达阶段及邻近建构(筑)物等特殊工况是盾构施工中最危险的阶段。其中,邻近建构(筑)物等特殊工况在集群6中占比为32%,远高于整体数据库水平的7.9%。
(2)集群6的地表沉降(隆起)超限、坍塌事故比例高于全库水平。本集群地表沉降超限发生情况为43%,全数据库为28%。
(3)集群3事故的风险因素集中于两个方面,且高于整个数据库的风险水平:盾构施工参数控制不合理、盾构开挖面土体失稳发生的情况数高于整个数据库;集群6事故的风险因素集中于三个方面,且高于整个数据库的风险水平:始发-到达端洞口土体加固及降水不当、基坑开挖及支撑体系施工不当、模板支撑体系缺陷发生的情况数高于整个数据库。
3.2 矿山法施工事故聚类集群结果
3.2.1 矿山法施工事故聚类集群的风险程度
矿山法施工事故聚类集群分为4类是最佳结果。根据式(2)计算风险程度。
对于“死亡”后果严重水平,第4集群显示出高风险程度,其风险程度的结果都大于1。其中,由于RP45为最高值,并且在重大伤害风险程度值都大于1,可认为第4组聚类集群具有最高的风险程度。相比之下,集群1的轻微伤害、重大伤害及死亡风险程度计算结果都等于0,并且在最低事故严重程度的轻微损失风险程度表现出较高可能性。因此,可认为第1组聚类集群具有最低的风险程度。
3.2.2 矿山法集群风险程度
对比分析集群和整体数据库变量的计算结果,如图6及表3,可知高风险程度集群4与低风险程度集群1的施工阶段、事故类型及风险因素有共同分布趋势,说明样本量的特性趋于一致,具体特征如下。

图6 确定的4个聚类群集安全风险因素数据分布图Fig.6 Determined data distribution of security risk factors of four clusters

表3 确定的4个聚类群集安全风险因素数据Table 3 Data of security risk factors of four clusters determined
(1)矿山法集群主要包含的工作阶段变量分布显示隧道开挖施工阶段、初期支护阶段及二次衬砌施工阶段是施工的危险阶段。其中,隧道开挖施工阶段在这两个集群中占比远高于整体数据库水平。
(2)矿山法集群突涌及大变形、滑坡、塌方事故比例高于全库水平。高风险程度集群4突涌发生情况为13%;大变形、滑坡、塌方发生情况为15%,全库为14%;机械伤害发生情况为53%。
(3)矿山法集群事故的风险因素集中于3个方面:断层、围岩地质松散、地下水、不明障碍物、管线、有害气体等不良复杂地质条件;初期支护不及时、施工不当;二次衬砌施工不规范、强度不够。
4 结论
针对城市轨道交通工程施工安全事故,通过K-means均值聚类算法,分析验证安全风险分布的重点阶段与主导因素,同时,确定城市轨道交通工程施工事故的主要类型,得到以下结论。
(1)高风险程度集群分析结果表明:事故主要发生在盾构始发-到达阶段及邻近建构(筑)物等特殊工况阶段,最大的风险因素是始发-到达端洞口土体加固及降水不当、基坑开挖及支撑体系施工不当、模板支撑体系缺陷、盾构施工参数控制不合理、盾构开挖面土体失稳,其事故的主要类型为地表沉降(隆起)超限、坍塌。
(2)聚类集群的分析结果表明:事故主要发生在隧道开挖施工阶段、初期支护阶段及二次衬砌施工阶段,最大的风险因素是断层、围岩地质松散、地下水、不明障碍物、管线、有害气体等不良复杂地质条件,其事故的主要类型包括突涌及大变形、滑坡、塌方。
猜你喜欢
建材发展导向(2021年22期)2022-01-18
建材发展导向(2021年22期)2022-01-18
建材发展导向(2021年18期)2021-11-05
建材发展导向(2021年11期)2021-07-28
建材发展导向(2021年12期)2021-07-22
铁道建筑技术(2021年4期)2021-07-21
模具制造(2019年7期)2019-09-25
军事运筹与系统工程(2019年4期)2019-09-11
建材发展导向(2019年3期)2019-08-06
信息化建设(2019年2期)2019-03-27
