
基于Spark和图论的电力脏数据智能动态检测方法
2021-04-13 04:38宾冬梅杨春燕
中国新技术新产品 2021年2期
余 通 宾冬梅 凌 颖 杨春燕 黎 新 谢 铭
(广西电力有限责任公司电力科学研究院,广西 南宁 530023)
0 引言
脏数据是指数据不在给定范围内、数据格式非法或不规范编码的数据,它是影响数据质量的主要因素。在电力系统中,要保证数据质量、提高数据利用效能的效率,同时为了有效利用电力数据来支撑电力系统运行的决策管控和决策知识,电力行业数据中的脏数据检测是其基础和重要保障,对电力系统稳定运行管控具有重要支撑意义。随着数字化和信息化在工业和能源等行业中的推进,应用数据呈指数级不断增长,每年应用数据的体量以TB数量级在增长。体量的不断增长在一定程度上使得数据的维度和密度在发生巨大变化,并且表现出了价值密度低的特点,并且掺杂了高比例的脏数据,这给传统的脏数据检测方法造成了困难。因此,研究人员提出了基于Spark和图论的脏数据智能动态检测方法。
长期以来,对脏数据检测的研究取得了大量成效。在文献[1]中,基于聚类分析思想将数据的重复问题映射为聚类分析问题,进而就可以数据的相似性问题;针对设备状态信息噪声的数据,提出了基于时间序列分析的数据清洗方法;而基于相似性测度的描述方法在判定记录的一致性方面也有一定表现,例如在文献[1]的文献综述中,针对模式匹配问题,提出了基于实体解析的模式匹配算法。上述方法在处理低维度的小数据集时具有良好的性能,但面对维度高、规模大的数据时,其检测性能大幅度降低,难以有效完成海量高维电力数据的脏数据检测。
因此,该文在将数据记录转换为对应指纹的基础上,设计了基于图论的指纹转换策略,并结合普聚类实现脏数据的智能检测;此外,鉴于Spark计算资源配置的合理性和其数据处理的优越性,提出了基于Spark和图论的电力脏数据智能动态检测方法,有效提高了大规模电力应用数据中脏数据检测的准确性。
1 检测原理
1.1 Simhash算法
Simhash算法[1]将高维数据映射为对应的低维二进制串(下文简称“指纹”),从而实现了数据与低维度二进制串间的映射,算法的功能具体描述为如下步骤:1) 特征关键词key的提取。即对待检测的数据进行关键词key的提取。2) 初始化向量。将Ψ维的向量v和s初始化为0。3) 计算签名。基于传统的标准Hash算法(例如MD5算法等)计算关键词key的签名b(Ψ位)。4) 判断签名正负位。即在b中,如果第i位是+1,则在v中的对应位置的数就设为+1,反之为-1。5) 关键词签名计算完毕之后,在v中,如果第i位的数字大于0,则s的对应位置的数就设为+1,反之为0。6) 输出s即为数据对应的指纹。
1.2 基于图论的指纹转换策略
为了实现指纹在极坐标下的动态映射,研究人员提出了基于图论的指纹转换策略。首先,将指纹与十进制数据进行转换,即将S=(si)映射为di(十进制数);其次,将di映射为二维坐标下的数据点vi(极坐标),并且有坐标vi(ρi,θi)=(di,di);再次,定义点与点之间的路径边Ei,j=│di,di│;最后,得到由指纹构建的图G=(V,E),从而将指纹动态地映射到极坐标下,具体步骤如下。
输入:S=(si),即输入指纹集
输出:极坐标下的图G=(V,E)。
步骤1:For each siin S do 。
步骤2:di=convertTodec(si) then 。
步骤3:vi=Creat((ρi,θi)=(di,di))。
步骤4:Ei,j=│di,di│。
步骤5:Update。
步骤6:if update=1 then goto步骤2。
Else
end for
步骤7:putout(G)。
该策略动态地实现了指纹在极坐标下的映射,最后输出的图中,不同节点就代表不同的指纹。
1.3 基于普聚类的脏数据智能识别模型
鉴于普聚类算法在处理高维数据中具有的优势,为了提高脏数据的检测精度,该文在指纹转换策略的基础上引入了普聚类算法,从而实现脏数据的智能识别,其数据模型如下。
1.3.1 无向权重图和相似矩阵模型构建
定义点vi(ρi,θi)=(di,di)和点vj(ρj,θj)=(dj,dj)之间的权重wi,j=Ei,j=│di-dj│,wi,j=wj,i,如果点vi和vj之间存在边,则wi,j=Ei,j=│di-dj│>0,反之,wi,j=Ei,j=│didj│=0。对任意点vi的度di为与之相连的所有边的权重之和,其表达式如公式(1)所示。

定义度矩阵Dn×n,是个对角矩阵,其主对角线的值对应第i行的第i个点的度数,定义如公式(2)所示。

定义邻接矩阵Wn×n=[wi,j],引入全连接法构建邻接矩阵Wn×n,此时邻接矩阵即为相似矩阵,其表达式如公式(3)所示。

式中:xi和yj为2个顶点;wi,j和si,j为2个顶点xi和yj间的相似度;σ为2个顶点xi和yj间的方差。
1.3.2 拉普拉斯矩阵和无向图切图模型构建
拉普拉斯矩阵L=D-W(D为度矩阵,W为邻接矩阵)。为了避免出现无向图分割均匀的现象,该文采用RatioCut切图,对每个切图都可以同时兼顾最小化cut(A1,A2,...Ak)和最大化子图点的个数,其表达式如公式(4)所示。

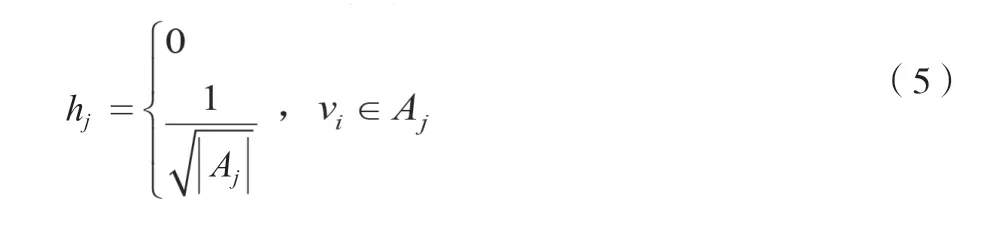
基于拉普拉斯矩阵的特性,可以推导出新的方程,如公式(6)所示。
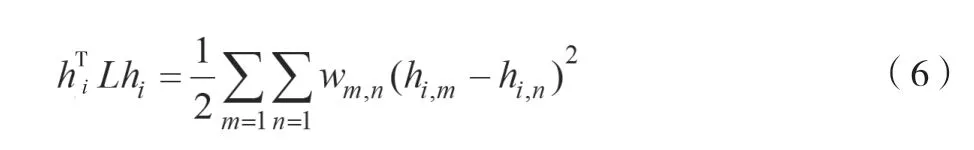
式中:hi为顶点i指示向量;T为向量的转置。
由公式(5)和公式(6),可以得到新的方程,如公式(7)所示。

由公式(7)可知,子图i的RatioCut对应于对于k个子图,其RatioCut函数表达式如公式(8)所示。
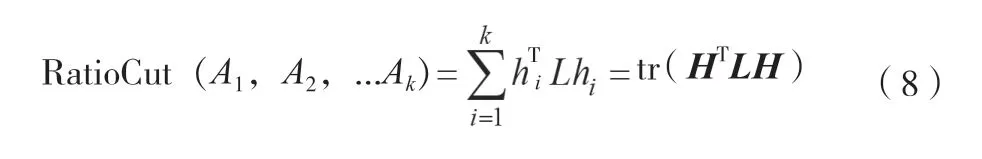
式中:H为hi的和,即指示向量的并集;tr(HTLH)为矩阵的迹。
由公式(8)可知,最小化tr(HTLH)即为RatioCut切图的过程。
1.3.3 基于改进的普聚类脏数据智能识别算法
基于改进的普聚类脏数据智能识别算法的步骤如下:1) 输入:样本集S={s1,s2,…,sn}。2) 簇划分C={c1,c2,…,cn}。3) 利用基于图论的指纹转换策略,构建S={s1,s2,…,sn}的无向权重图并生成相似矩阵S。4)构建邻接矩阵W,并生成度矩阵D。5)计算拉普拉斯矩阵L。6)构建标准化拉普拉斯矩阵D-1/2.L.D-1/2。7)计算D-1/2.L.D-1/2最小的k个特征值的对应特征向量fi...fk。8)基于行对fi...fk组成的矩阵标准化,生成特征矩阵F(n×k)。9)对F(n×k)中的k维样本,通过DBscan算法并利用RatioCut数学模型,输出簇划分C{cm},m=(1,2,3,...,m),表示聚类维数。
1.4 基于Spark的脏数据检测策略
1.4.1 Spark计算框架
Spark框架是基于内存的计算分布式平台,弹性分布式数据集(RDD)是其核心。Spark将各弹性分布式数据集的依赖串联起来,以此来构造有向无环图,并在RDD上执行Action函数操作,将有向无环图作为作业提交给Spark执行。
基于RDD的性质,该文结合基于普聚类的脏数据智能识别模型(DDI)与Spark计算平台,提出了基于Spark的脏数据检测算法(SP-MATCH-new),解决了大规模电力行业应用数据一致性清理的问题,实现了对脏数据的有效处理和检测。
1.4.2 实现基于Spark的脏数据检测算法SP-MATCHnew
为了应对海量、高维化电力数据带来的瓶颈,该文基于迭代的RDD和普聚类算法设计了适用于海量电力数据中的脏数据的检测策略。
对关系表Ek,k∈R,行号记为ID,表中第i行j列的属性值为Ai,j且Ai,j∈Ai;检测Ek中脏数据,SP-MATCH-new算法的描述如下:1) 输入样本集S={s1,s2,…,sn}。2)输出簇划分C={c1,c2,…,cn}。3) 调用SparkContext.textFile()方法和RDD.Cache()方法来读取样本S={s1,s2,…,sn},并以RDD加载到内存。4) 利用Simhash并输出数据关键字元组的指纹RDD,并按格式<key=IDi,value=si>的形式存储。5) 执行Map,将指纹映射为新的键值对并以格式<key=IDi,value=si>的形式存储6) Executor执行Reduce操作,输入Map的结果<key=IDi,value=si>。7) 以si为键进行归并。8) 调用相似矩阵生成方法,生成相似矩阵RDD邻接矩阵RDD和度矩阵RDD。9) 调用拉普拉斯数学模型,生成拉普拉斯矩阵RDD并进一步生成标准化拉普拉斯矩阵RDD。10) 对标准化拉普拉斯矩阵RDD调用数据步骤8)中的RDD,生成特征向量RDD。11) 将特征向量RDD缓存到内存。12)DBscan.RatioCut(特征向量RDD),生成DBscan.RatioCutRDD。13) 执行Action,调用saveAsTextFile方法,并以<key=si/valueslist=(ID1,…/…)>的形式将簇划分C{cm},m=(1,2,3...,m)输出;在输出的结果中,通过对异常离散点的判断,完成脏数据的识别。
2 实例分析
为了验证该方法的有效性和高效性,在I620-G20曙光服务器(16台服务器节点)中搭建Spark平台环境,配置见表1。
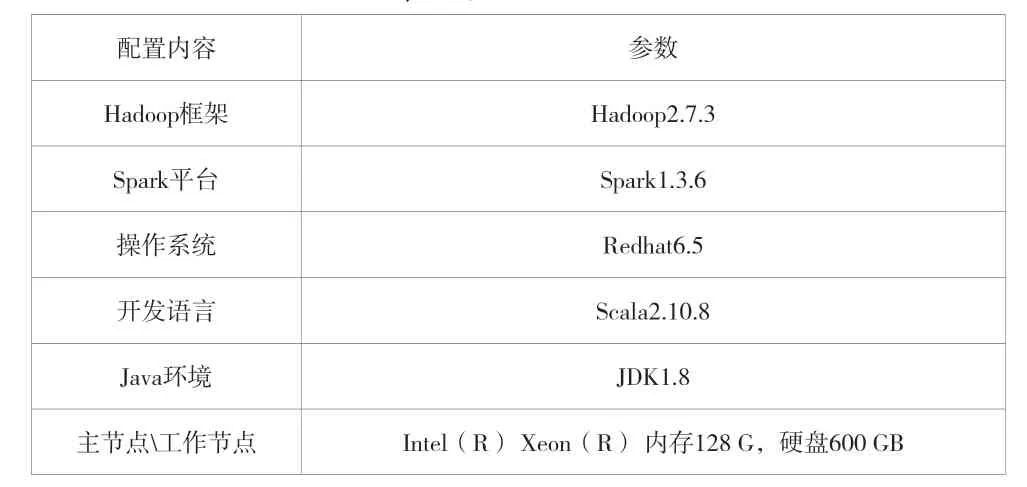
表1 实验环境配置
实验数据是用户用电的负荷数据,来自电力企业的应用系统。在实验中,采用文献[1]中的提取指纹长度和特征关键词的方法进行试验;标准哈希函数采用MD5算法。
2.1 精确性和稳定性的分析
将该算法的检测结果与文献[2]中性能最好的COSY算法进行对比。采用记忆率(R)、准确率(P)和F1-score(F1)作为运行效果的评价标准, 且F1与算法性能呈正相关;实验结果见表2。由表2可知SP-MATCH-new算法的平均检测精度略高,但其平均召回率和F1相对远大于COSY,由此可见,该算法具有更好的检测效果。

表2 SP-MATCH-new算法检测精度
检验数据规模对算法有关指标敏感度影响的实验结果见表3。

表3 SP-MATCH-new指标检测
由表3可知,当数据以10倍规模递增到1000 GB时,算法的检测精度(P) 和平衡性(F1)在6%内浮动,召回率(R) 在5%内浮动。其平均P为78%,平均R为96%,平均F1为84% 。随着数据规模的快速增加,SP-MATCH-new算法检测的P、R和F1,稍微降低P、F1的值,使它们的值在6%内浮动、R在5%内浮动,但算法受到的影响相对较小,能满足巨增数据体量的性能要求,表现出较高的稳定性。
2.2 算法效率分析
实验将该算法与基于MapReduce的算法的执行时间进行对比,实验结果见表4。由表4可知,相同条件下,SPMATCH-new算法比基于MapReduce的算法的执行效率提高了约79.2%;这是因为在SP-MATCH-new算法中,数据流的运行模式采用memory-to-memory的模式,该模式中只有在构建分布式弹性数据集的时候,数据I/0操作才涉及磁盘input/output流的开销,作业处理结构比基于MapReduce的算法更加高效。因此,SP-MATCH-new具有更高的运行效率和执行效果。

表4 SP-MATCH-new算法的执行效率
3 结语
针对单机环境下的计算资源和基于MapReduce的算法存在难以有效解决海量、高维化电力数据中脏数据检测的问题,研究人员设计了图聚类分析的脏数据检测策略,并提出了基于Spark和图聚类分析的脏数据检测算法,该算法有效解决了海量、高维化电力数据的脏数据检测和计算资源的合理利用问题,其算法高效、稳定,具有良好的适用性。研究人员需要继续研究如何提高算法的检测精度等寻优策略,使其更好地应用于海量电力数据的处理中,为获取更好的电力管控决策知识提供优质的数据支持。
猜你喜欢
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
铁道通信信号(2020年12期)2020-03-29
中等数学(2018年9期)2018-11-10
孙子研究(2016年4期)2016-10-20
自动化学报(2016年8期)2016-04-16
现代计算机(2016年11期)2016-02-28
青少年科技博览(中学版)(2015年7期)2015-08-12
电测与仪表(2015年3期)2015-04-09
中央民族大学学报(自然科学版)(2014年2期)2014-06-09
