
YOLOv4的车辆检测方法研究
2021-04-12 01:44江汉大学智能制造学院杨英彬郭子彧蔡利民
电子世界 2021年5期
江汉大学智能制造学院 杨英彬 郭子彧 蔡利民
随着城市的发展,城市交通流和人流密度成为城市道路交通拥挤的重要原因。随着人工智能技术和计算机视觉技术的飞速发展,可以用来目标检测的模型越来也多。在目标检测中车辆检测是非常重要的检测目标之一。基于深度学习的目标检测其检测率非常之高并且有很强特征的提取能力。近几年深度学习网络在计算机视觉上因为AlexNet在ImageNet大赛上大放异彩而飞速发展。2014年VGGNet为了追求深层网络的性能发现梯度会消失,但增加网络的深度会提高性能。2015年ResNet网络解决了梯度消失的问题,其模型收敛时间大大减少但尺度大的卷积核增加的网络模型的计算量,使模型的检测速度和训练速度降低。在计算机视觉目标检测中现有的方法分为两种分别为two-stage和one-stage两类。One-stage方法是单段检测算法,其在检测时单个激活映射来的边框和预测的类,极大的提高了检测的速度。SSD系列、YOLO系列、RetinaNet等是典型的代表。Two-stage方法生成的边框会映射到feature map的区域,然后将该区域重新输入到全连接层进行分类和回归其检测速度较慢,以faster-rcnn为代表。文本采用的YOLOv4方法进行车辆检测。YOLOv4在COCO数据集上可以达到43.5%AP,速度高达65FPS。可以完成车辆实时检测的任务。
1 YOLO模型
YOLO(You Only Look Once)算法是基于深度学习的回归方法由REDMOND J在2016年提出,将图片分成S×S的网格,如果某个物体的中心落在网格当中,那么这个网格就负责预测这个物体。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。如果图像中每个格子包含多个物体例如鸟类却只能检测出其中一个。
YOLOV2对预测准确率、识别更多对象、速度这三个方面做了改进,提出联合训练法使用一种分层的观点对物体进行分类用巨量的分类数据集数据来扩充检测数据集。YOLO2也尝试采用先验框微调边框的位置和检测神经网络中是否存在对象。

图1 YOLOv4网络结构
YOLOV3的模型相对于之前的模型复杂了很多,通过改变模型结构的大小来权衡速度和精度。采用darknet53网络作为主干结构,使用残差结构加强了主干提取特征的能力。YOLOv4算法主要通过CSPDarknet53网络提取特征将图片分成S×S的网格,目标检测通过目标中心所在的网格完成,利用残差网络上采样和下采样对特征进行特征融合,使用SPP结构对不同尺度的最大池化后进行堆叠,最终经过度尺寸的特征提取得到目标的类别和位置。我们所熟知一般的卷积神经网络,经过若干次池化和卷积,在全连接层后利用softmax分类或者sigmoid判断物体是否存在。而对于yolo,它将一个图片分成19×19的网格,在每个网格里寻找物体。物体的表现形式为(Pc,bx,by,bh,bw,c),Pc代表物体存在与否,x,y代表方框中心,h高度,w宽度,都是相对于整体1的数字,c代表类别。c为(c1,c2……)每个cn都是1或0。而针对一个19×19方格出现多个物体,用anchor boxes解决。假如有80类要探测,且每个方格至多可能出现5个个体。YOLOv4网络结构如图1所示。
2 车辆检测模型
本文利用深度学习对车辆进行检测,主要分为两个阶段分别为车辆模型训练阶段和车辆模型检测阶段。在训练之前需要首先制作相应的VOC数据集,生成训练的样本。将VOC的数据集输送到神经网络进行训练,提取三个网络特征层并进行5次卷积操作之后下采样加强特征融合获得有效特征,最后将车辆检测的结果输出出来。
为了对图片中设定类别进行检测,每个网格都需要预测B个边界框和分别属于设定类别的条件概率并且在边界框中输出目标类别和边界框准确度的置度信息Conf(Object)。当出现一个物体被多次框的时候,就需要用到交并比(Intersection over Union)简称IoU,IoU 计算的是预测的边框和真实的边框的交集和并集的比值。
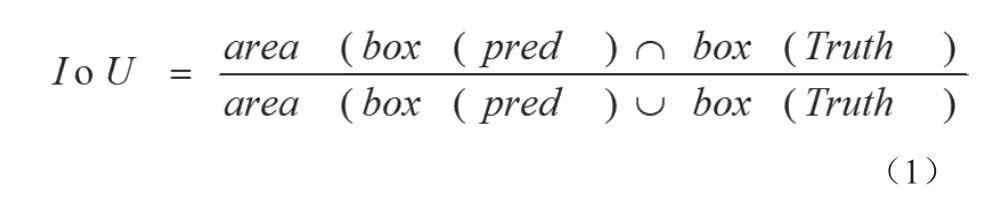
其中,box(pred)为真实边界框,box(Truth)为预测边界框。

Pc(Object)表示目标物是否落入候选的网格中,如果有就是1,没有就是0。
损失函数的设计是为了提高精度而不增加推断时间。传统的目标检测器一般采用均方误差直接对边界框的中心点坐标和宽度和高度进行回归并没有考虑对象的完整性。原模型损失函数将边界框坐标预测误差、物体识别类别误差、边界框置信误差已经考虑在内。本设计对损失函数进行了改进,给交叉熵函数添加调制系数α解决数据集样本不均匀的问题。
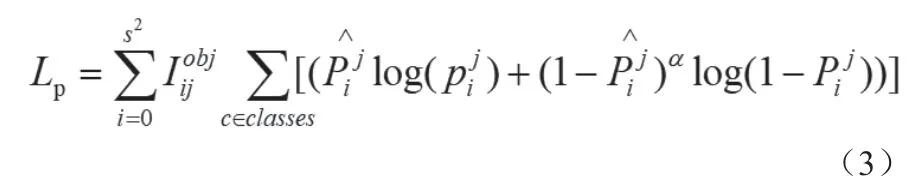
Iijobj为第i个网格区域出现了感兴趣目标,为第i个区域预测的类别是实际目标类别的概率,为第i个区域为实际目标类别的概率。
与此同时根据 YOLOv3 的启发,为了提高车辆检测的精准度,其 YOLOv4 的损失函数利用高斯函数来进行改进,增加对车辆边界框可靠性判断。用对边界框x坐标预测值进行修改来增加可靠性判断计算公式如下:


图2 数据标注
上式中tx:边界框的中心坐标相对于网格左上角x坐标的偏移量;utx:边框的坐标。
3 实验结果与分析
3.1 实验数据
本文采用的VOC数据集,对车辆进行识别训练,该数据集有1890张照片,按照9:1的比例分为训练集和测试集,通过labelImg标注工具对其进行标注信息。标注过程为将图片放入标注工具中手动选框对图片中的车辆进行框取如图2绿色选框所示。
3.2 实验平台
本实验平台配置为:显卡860,显存4G,CPU为Inter Core i5-5800,内存16G,Windows10操作系统,环境为tensorflow和keras。本实验设定的最大学习效率为0.001,衰减系数是0.005,在中途中断训练后可以解冻训练。
3.3 实验过程及分析
本次实验数据集有些图片比较难分辨因为在图片中占比比较小,所以将送入网络的图片分辨率设置为608×608以此来提高检测的精准度可以检测多个小物体。在训练过程中还使用不同尺寸大小的图片进行训练,来提高训练模型的鲁棒性。
针对采集数据集数量有限的问题,先用制作的目标检测数据集在同等环境下分别对 YOLOv4 网络和本文改进的 YOLOv4 网络预训练,将预训练参数作为模型初始参数。实验发现,模型在经过7000迭代次数之后,训练损失值快速下降并且最终达到一个较低值水平。本文改进的 YOLOv4 模型和原始 YOLOv4 网络在车辆识别中的检测结果对比如表 1 所示。

图3 检测效果1
本文通过对损失函数改进给交叉熵函数添加调制系数α,用对边界框x坐标预测值进行修改来增加可靠性判断,通过实验对比发现本文算法相较于原来的YOLOv4算法在检测时间和速度上都有了提升,检测的平均精度也比原来的算法高出2%。

表1 YOLOv4与改进算法对比

图4 检测效果2
本次实验训练出的模型因为数据集不够多在测试集中平均检测精度为93%,能够较好的识别车辆,在测试视频中对视频中的车辆进行检测。
检测的效果如图3、4所示,其分别对检测视频中不同时间段的检测效果进行截图。
通过对摄像头采集的视频进行检测发现该训练好的模型能够较好的识别车辆,并且可以对车辆进行实时的检测能够满足实时性的要求。
总结:本文运用YOLOv4算法并对其进行损失函数进行改进给交叉熵函数添加调制系数α,用对边界框x坐标预测值进行修改并进行训练,利用训练好的模型对车辆进行识别,通过与原来算法的对比发现检测的时间、速度和平均精准度有了提升并且能够对视频中的车辆进行实时性检测,由于数据集不够多训练的精准度还比较低,接下来讲制作大量的数据集进行训练。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
儿童时代·幸福宝宝(2021年11期)2021-12-21
现代装饰(2020年4期)2020-05-20
中学生数理化·高一版(2020年1期)2020-02-20
数学年刊A辑(中文版)(2019年3期)2019-10-08
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
证券法律评论(2018年0期)2018-08-31
北京航空航天大学学报(2017年6期)2017-11-23
浙江大学学报(工学版)(2016年10期)2016-06-05
科普童话·百科探秘(2015年4期)2015-05-14
