
基于深度学习的罐式炼炉送料口视觉检测与跟踪方法
2021-04-12 06:48闫河,李焕,罗成
重庆理工大学学报(自然科学) 2021年3期
闫 河,李 焕,罗 成
(1.重庆理工大学,重庆 400054;2.重庆市两江人工智能学院,重庆 401135)
在机械控制生产中,钟料罐是必不可少的设备,而在视频流中能够准确、鲁棒性地检测与跟踪送料口成为工业生产的重中之重。同时炼炉罐的负荷存在变化,转速并非均匀。而且炼炉罐高温易产生大量的烟雾,对送料口的检测与跟踪会有一定的干扰。
传统图像处理的目标检测方法是通过手工设计特征来实现的,代表的特征有方向梯度直方图HOG[1]、局部二值特征LBP[2]、尺度不变特征变换SIFT[3]等。分类器常见的有支持向量机SVM[4]、DPM[5]等。传统的目标检测存在2个主要的问题:一是需要手工的设计特征,滑动窗口的选择往往没有针对性,提取的特征不够,最后检测出来的目标存在漏检及误检的问题,准确率低;二是对于多样变化的物体,手工设计的特征鲁棒性低。传统视觉检测和跟踪算法受炼炉高温产生烟雾的影响,易导致送料口检测和跟踪失效。
近年来,随着AlexNet[6]网络在ILS-VRC-2012比赛中取得胜利,深度学习中卷积神经网络(CNN)[7]逐渐的走入研究者的视线中,卷积神经网络具有快速特征提取和分类的特点。相比较于传统的目标检测,深度学习提取到的特征更多更丰富。基于此特征,研究人员提出了一系列目标检测算法。在2014年Girshick等[8]提出了区域卷积神经网络(RCNN),该网络首次使用候选区域(region proposal)网络代替传统目标中使用的滑动窗口的方法,使用卷积神经网络提取特征,输入到支持向量机中训练。该网络训练速度慢、占用磁盘空间大。在此基础上Girshick[9]提出了快速区域网络(fast RCNN),该网络在最后一层之后加入ROI Pooling层,生成固定尺寸的特征图,相较于RCNN训练速度有所提升。Ren等[10]提出了超快速区域卷积神经网络(faster RCNN)首次使用RPN(region proposal network)[11]代替原来的Selective Search[12]方法生成建议窗口,从最初的2 000个减少为300个,提取到的特征更多,训练速度更快、准确高。在准确率的基础上,为了提高检测速率,Redmom等[13]提出了一种更为轻量级的Yolo网络,该网络的核心思想是将整张图作为网络的输入,直接在输出层分类和回归,这样保留了检测目标全部的特征,训练效果更好,在coco数据集[14]能跑45 fps。接着Redmom又提出了Yolo v2[15]和Yolo v3[16]网络,其中Yolo v3速度更快,检测准确率更高。实现了在coco数据集上51 ms时间内map达到57.9的效果。由此可见,Yolo v3网络在兼顾准确率的同时,也能有很好的检测速率。
1 Yolo V3原理
在CVPR2016上,Yolo v3是由Redmom等人提出的一种端到端的网络。它放弃了之前Faster RCNN网络中使用Two Stage方法,在图片上直接生成区域建议的步骤,而是直接将整张图片作为卷积神经网络的输入,在输出层直接回归目标的位置及目标所属的类别,极大地提高了目标检测的准确率。
1.1 Darknet-53网络
Yolo v3使用一个全新的、更深层次的卷积神经网络Darknet-53,这个网络是由多个残差单元叠加组成的。相比较在Yolo V2中使用的Darknet_19网络,该网络主要是由连续的1×1和3×3的卷积层组成的,包含有53个卷积层和5个池化层,每个卷积层后面都会有一个批量归一化层(batch normalization)[17]。为了解决过拟合的问题,加入了去droput处理。引入多尺度融合的思想,能够更好地检测小目标,网络结构图如图1所示。

图1 Darkent-53网络部分结构图
1.2 多尺度特征融合
Yolo网络使用的端到端的思想,就是将整张图片作为神经网络的输入,提取特征、检测速度比较快。但是在检测小目标的时候效果较差,这是因为神经网络中低层中的特征语义信息相对较少,但是目标位置信息准确。高层的特征语义信息比较丰富,感受野大,但是位置信息就相对较少。为了解决这个问题,Yolo网络借鉴了FPN[18]思想,采用上采样融合的方式,融合3个尺度(13×13,26×26,52×52),在多个尺度的特征图(feature map)上单独检测、预测目标的位置以及类别,最终对小目标的检测效果有比较明显的提升。
1.3 信息预测
Yolo v3继续使用在Yolo v2中K-means[19]聚类方式做Anchor Box[20]的初始化,这种通过加入先验知识的方式,不需要提前对目标的位置坐标进行训练,而是为每种下采样尺度设定3种先验框,总共聚类9种,具有最大感受野的目标,应用较大的先验框,比较适合检测较大的对象。具有最小感受野的目标,应用较小的先验框,比较适合检测较小的目标。
在预测目标的类别时候,抛弃以往使用的softmax分类器,改为使用logistic分类器的输出进行预测。这是因为softmax只支持单一的类别预测,而logistic能够支持多标签多类别的对象。
2 改进的方法
Yolo v3网络在目标检测领域取得了较好的效果,原文献中的网络是基于COCO数据集进行训练的,该数据集包含90种类别的目标,目标之间尺度变化大、特征明显。而本文中主要是使用Yolo v3网络对送料口进行检测与跟踪,送料口不属于数据集中的一类,且属于小目标,需要对Yolo v3网络进行适当的改进,以便适用于送料口数据集的检测。基于数据集的聚类方法改进如下。
在Yolo v3网络中借鉴Faster RCNN网络提出的anchor boxes方法作为先验框,对目标进行预测。而在Faster RCNN网络中需要提前手工设定先验框,然后在之后的训练中调整anchor boxes的尺寸,这是按照研究者的经验而定,人工主观性比较强。如果能以某种方式,自动地选择一个合适的先验框,这样卷积神经网络将会更容易的学习,做出更准确的检测。为了解决这个问题,Yolo v3网络中采用维度聚类的方法,使用K-means方法计算出anchor boxes的个数和尺寸,对数据集的目标预测框大小进行聚类。
K-means方法中通常使用曼哈顿距离、欧式距离等计算方式来判断两点间的距离,然后当检测目标较小,先验框的尺寸较大的时候,使用这种方式得到的误差也更大。当使用欧式距离作为计算公式的时候,大的候选框比小的候选框会产生更多的错误,从而影响检测结果。为了让预测框与groundtruth的交并比(IOU)更大,并且IOU是与anchor boxes的尺寸无关的,且能够适用于本文中的送料口数据集,本文使用一种新的距离公式,有:
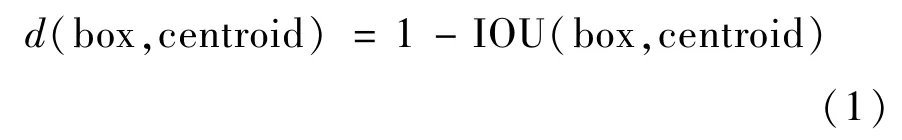
式中:centroid表示簇的中心;box表示检测目标的边框信息;IOU表示簇中心框的值与聚类得到的框的交并比。其中IOU交并比公式为:
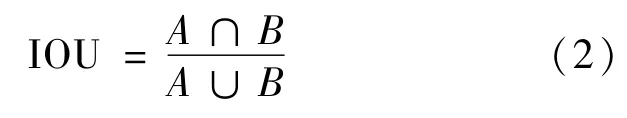
式中:A表示真实框;B表示预测框。IOU交并比越大,表示预测的值越准确。
本文使用送料口数据集进行聚类分析研究,选取K=1,2,3,4,5,6,7,8,9,得到的结果中心个数K与距离之间的关系,如图2所示。
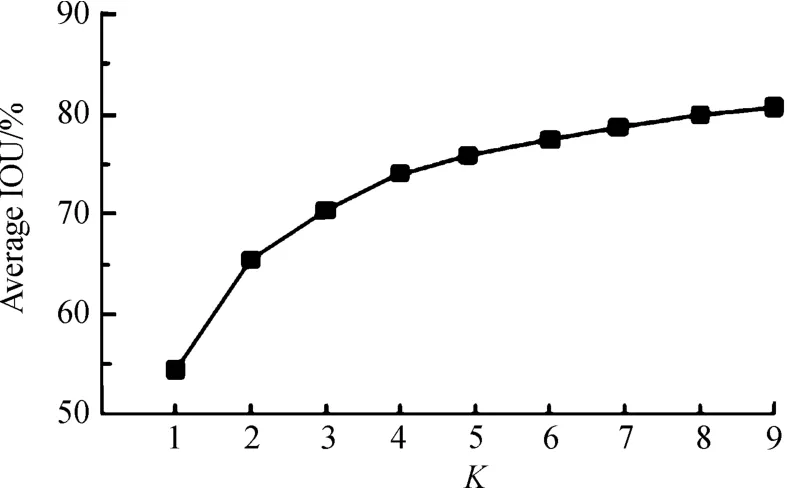
图2 K-means聚类图
由图2可以看出,当K=4的时候,折线开始变得平缓。因此针对本文中送料口数据集,选择anchor boxes的数量为4,在预测框上设定4个聚类中心框,可以得到比较好IOU的值,在本文的训练集上使用K-means方法得到的4种尺寸大小为(15,43),(16,25),(22,38),(40,75)。
由图1可知,Yolo v3网络在COCO数据集上分别对52×52,26×26,13×13大小的分辨率图像进行预测,而本文只检测送料口,且属于小目标,通过K-means方法聚类得到的最大anchor boxes尺寸大小为(40,75),如果使用52×52尺度上预测,会导致误检的现象,因此本文针对送料口数据集的情况,仅使用26×26和13×13尺度下预测,每种尺度有2种anchor boxes。
3 实验结果
3.1 自建数据样本
本文实验室环境下,让视频流中匀速转动的钟料罐不断采集每一帧的图片,自建大量有烟雾干扰的图片样本,总共1 100张。然后将整理得到的照片统一裁剪416×416像素,以适应Yolo v3网络训练集大小。为了扩充数据集的数量,增加样本的多样性,对图片进行数据增强,比如随机裁剪、旋转、翻转等,将数据集增加到2 500张。通过数据增强的方法不会丢失图片的特征,可以增加数据集的多样性。图3表示使用LabelImg工具制作数据集的过程。得到矩形框的位置信息(Xmin,Ymin,Xmax,Ymax)和目标类别的信息。然后制作成VOC数据集的格式,并按照训练集∶测试集∶验证集=7∶2∶1的比例进行分配数据集。
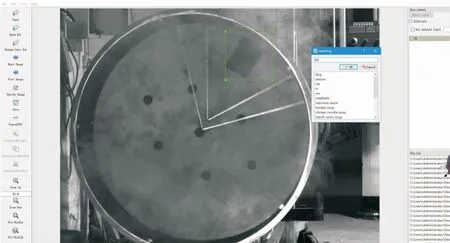
图3 数据集制作图
3.2 实验结果
为了验证Yolo v3网络在本文中对送料口的检测效果,实验平台采用的是Inter(R)Xeon(R)cpu E5-2630 v4,GPU采用的是英伟达K80显卡,操作系统为win7 64位,深度学习框架:darknet-53。
针对送料口数据集,需要对Yolo V3的网络训练过程进行适当的改变。载入权重模型,epoch训练50次,训练的batch_size为6,学习率为0.001。大概训练12 h后Loss值趋于稳定,基本收敛,得到最终的检测模型。
不同阈值检测效果对比。在深度学习检测过程中,可以为目标设定一个阈值,低于该值的预测框都会被抛弃,不显示出来。在原文中,作者使用的阈值score=0.35,为了在本文的数据集中得到最佳的阈值,对比6组不同阈值大小进行试验(见图4),不同阈值下的数据如表1所示。

表1 不同阈值下的数据
图4为6组不同阈值大小的实验结果,当阈值过高或过低的时候,漏检或误检率较高。当阈值score=0.5的时候检测效果较好。
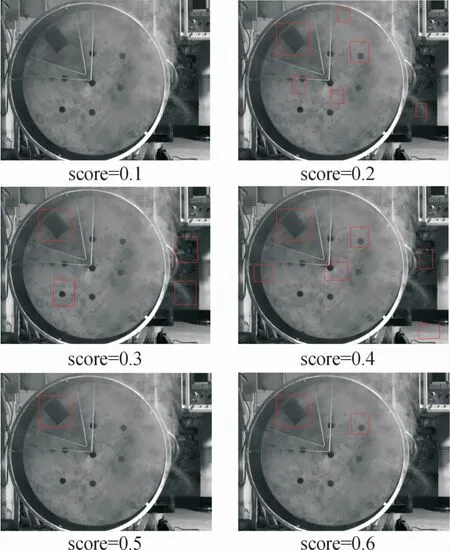
图4 不同阈值对比图
表1中预测框的个数表示为在当前阈值下,生成的预测框平均个数。由表1可知,在阈值score=0.5的时候,误检率最低.因此本文中使用改进的后的Yolo v3网络进行检测,采用阈值为0.5,能得到较好的检测结果。
为了验证改进后的Yolo v3网络的性能,在本文实验中使用送料口测试集对训练完成的模型进行检测,分别计算准确率和召回率以及检测速率,其中准确率计算公式为:

式(3)中:Tp表示正确检测出来的送料口数量;Fp表示被误检的送料口数量。
由表2可知,与Yolo v3方法以及传统的目标检测HOG+SVM进行对比,本文方法准确率达到了97.20%,改变聚类方法及多尺度特征融合的方式,能够准确地检测目标,而原文中Yolo v3网络使用6种anchor boxes方式以及阈值设置的不正确,会导致目标的漏检以及误检的情况。而传统的目标检测方法需要经过一系列人为的手工设定特征,进行多步骤图像预处理,且在受炼炉高温产生烟雾的影响下,检测准确率以及检测速度都不及深度学习方法。

表2 实验数据
而在工业生产中,非匀速转动送料口,位置及形状都发生变化,再加上烟雾及周围环境的干扰,使得传统的目标检测方法很难检测出来。本文中改进后的Yolo v3网络具有极强的泛化性和鲁棒性,检测速度达到30帧/s,基本上能满足工业上的需求。图5表示多帧效果。

图5 多帧效果图
4 结论
针对在实验场景下送料口的检测与跟踪问题,本文提出了基于Yolo v3改进的目标检测方法。根据本文中数据集中的尺度,对网络结构做出改进,使用K-means聚类的方法,得到最适合本数据集的尺寸大小。经实验表明,本文改进的网络在检测准确率以及检测速度上,基本能满足工业控制生产的要求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
