
基于两种U型网络的钢铁图像缺陷检测方法对比
2021-04-09 05:11师伟婕黄静静王茂发
北京信息科技大学学报(自然科学版) 2021年1期
师伟婕,黄静静,王茂发
(1.北京信息科技大学 理学院,北京 100192;2.桂林电子科技大学 计算机与信息安全学院,桂林 541004)
0 引言
随着信息技术的发展,“冶金行业+互联网”已成为必然发展趋势。为实现钢铁缺陷的精确检测,现如今,多采用基于机器学习、深度学习[1-2]的图像分割算法替代传统的人工缺陷检测方法。但目前在钢铁图像缺陷检测的过程中,仍普遍存在缺陷位置定位不准确、缺陷类别识别不清、成本高、效率低等问题。
对钢铁缺陷检测的研究须建立在一定量的图像数据之上,但目前大规模、高质量、用于工业级分割的钢铁图像数据较少。应用比较广泛的钢铁缺陷数据集有NEU(美国东北大学)的表面缺陷数据集[3]和UCI(加利福尼亚大学欧文分校)的钢板缺陷数据集[4]。这些钢铁数据集数据量较小且图像注释标签不完整,深度学习则往往依赖较大的样本数据量,并且对计算机硬件性能要求较高,因而在进行钢铁缺陷图像分割时,研究人员多采用传统机器学习方法,使用深度学习方法进行钢铁数据分析的研究不多[5]。
在深度学习方法应用于图像分割方面,U型神经网络U-Net[6]、Res-UNet表现出较好的性能。张倩雯等[7]运用3D Res-UNet网络对CT影像数据进行肺结节图像分割,将二维Res-UNet扩展为三维Res-UNet,使用较少的数据集就可以达到一个较为优秀的结果。钢铁图像与医学图像都存在数据边界较模糊、数据集不平衡、图像分割存在细小处等特征,利用U型网络对医学图像的研究为本文提供了借鉴。
在相关研究的启发下,本文选取两种U型神经网络模型U-Net、Res-UNet对钢铁图像进行缺陷检测。对比两种模型的图像分割性能,进行缺陷种类识别和缺陷区域分割,从而探索实现钢铁缺陷精确检测的方法。
1 模型选择
1.1 U-Net网络模型
U-Net卷积神经网络首次由Olaf Ronneberger等[8]提出。U-Net是类似“编码器-解码器”的U型神经网络模型,模型结构如图1所示。U型左侧是模型深化的过程,由上到下图像特征从具体到抽象,图像分辨率降低。U型右侧是分辨率恢复的过程,使用反卷积和同维度的特征拼接实现分辨率的提升。最终将深层抽象特征与浅层具体特征相融合。U-Net可以用深层特征进行定位,用浅层特征进行精确分割,对于数据边界模糊、需要较高分辨率的图像具有较好的图像分割效果。

图1 U-Net 网络结构
1.2 Res-UNet网络模型
Res-UNet是U-Net模型的变体,在U-Net基础上结合了Resnet残差网络。Resnet残差网络首次由何凯明等[9]提出,它通过设置冗余网络层残差F(x)=0来代替快捷路径的h(x)=x,实现参数的恒等映射,从而有效解决网络层数过深导致的网络退化和梯度消失问题。
Res-UNet模型结构如图2所示。在U-Net模型的U型基础上,使用残差网络对每个单元模块进行调整,将U-Net中原有的卷积层、卷积层、池化层调整为Res-UNet中的BN(batch-normalization)批量标准化、Relu激活层、卷积层、BN批量标准化、Relu激活层、卷积层和addition附加层。在右侧分辨率提升部分通过concatenate特征拼接层将编码部分与解码部分进行特征连接,实现同维度的特征拼接。
Res-Unet模型不仅有U-Net模型在深层抽象特征与浅层具体特征相融合的优势,而且具有Resnet残差网络的优势,即可以有效解决网络退化和梯度消失问题。

图2 Res-UNet网络结构
2 钢铁图像缺陷分割
2.1 数据集
本实验采用的数据集来自kaggle2019的“Severstal:Steel Defect Detection”竞赛。数据包含3个主要文件:test_images测试集钢铁图像、train_images训练集钢铁图像、train.csv。测试集钢铁图像和训练集钢铁图像两个文件夹用于存储jpg格式的钢铁图像数据。train.csv是csv格式的训练数据集,文件大小为16.96 MB,有50 247条数据,12 568张钢铁图像。通过train训练集的缺陷类别和位置信息来训练网络,通过test测试集中的钢铁图像来识别缺陷类别和定位缺陷位置,从而实现钢铁缺陷的定位。
2.2 数据统计和分析
对训练集图像数据进行初步可视化,并且使用python对train.csv文件进行每类缺陷占比、缺陷数量、缺陷面积的数据统计与分析。
实验环境为Windows 10平台下的Jupyter notebook,CPU环境,python版本3.5,所用的框架是tensorflow(1.4.0)为后端的Keras(2.0.8)。
2.2.1 数据分析
使用训练集csv格式文件进行数据分析。对钢铁图像数据的缺陷类别进行合并汇总,转换数据统计格式。最终通过pandas创建列名为“ImageId”(钢铁图像数据id编号)和“ClassId_EncodedPixels”(缺陷像素游程编码)的表格型数据结构,部分数据如图3所示。ClassId_EncodedPixels格式为[(缺陷类别编号,像素游程编码)]。

图3 表格型数据结构
2.2.2 掩膜合成与数据可视化
依据自定义函数将4类缺陷掩膜覆盖在训练集钢铁图像上,缺陷类别“一二三四”分别对应掩膜颜色“红蓝绿紫”。合成后的钢铁图像数据进行数据可视化,结果如图4所示,可以清晰地呈现出训练集中缺陷种类和缺陷位置。

图4 钢铁缺陷可视化
2.2.3 数据统计
使用Plotly的离线操作,在Jupyter notebook页面内进行数据统计及可视化。
1)针对训练数据集中有无标签进行划分,如图5所示,有标签的图像个数为6 666个、无标签的图像个数为5 902个。
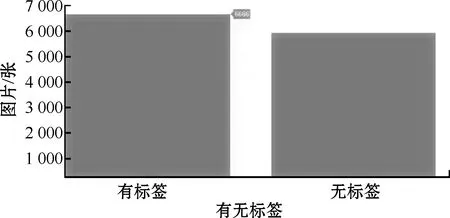
图5 有无标签的条形图划分
2)针对每张图像所含缺陷类别的个数进行统计划分,如图6所示,无缺陷的图像有5 902张,有1种缺陷类别的图像个数是6 239张,有2种缺陷类别的图像个数是425张,有3种缺陷类别的图像个数是2张,没有含全部4种缺陷类别的图像存在。

图6 单图中所含缺陷个数的条形图划分
3)针对每个缺陷类别所占图像张数进行划分,如图7所示,类别3为72.6%,5 150张;类别1为12.6%,897张;类别4为11.3%,801张;类别2为3.48%,247张。数据集的类别分布非常不平衡,说明训练集图片中所含掩膜缺陷类别3的张数较多,所含掩膜缺陷类别2的张数最少。
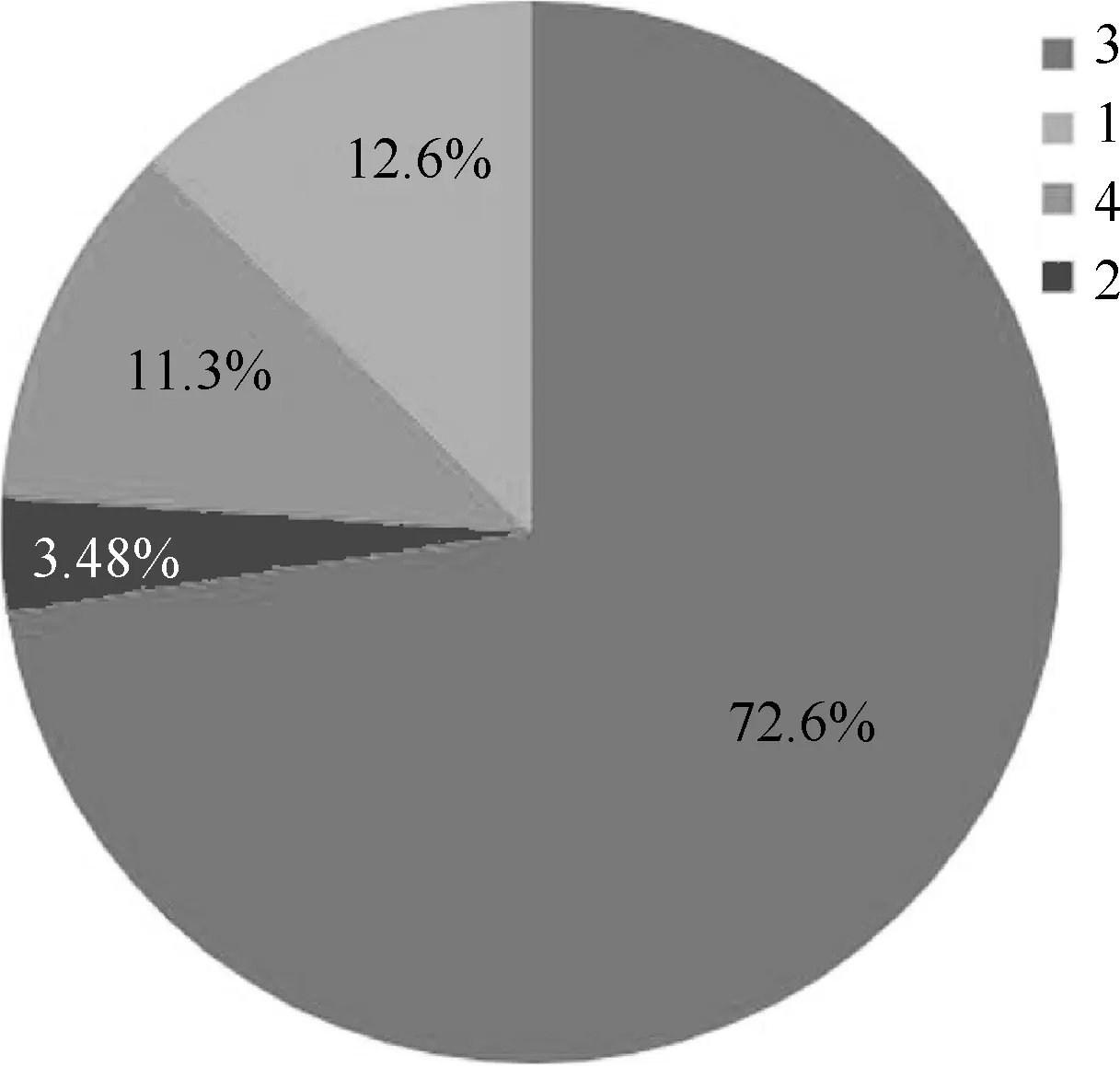
图7 每个缺陷类别所占图像张数的饼状图划分
4)针对每个缺陷类别像素值覆盖范围进行划分,如图8所示,由图可知,类别3掩膜的像素值覆盖范围最广,而类别2掩膜的像素值覆盖范围最小。
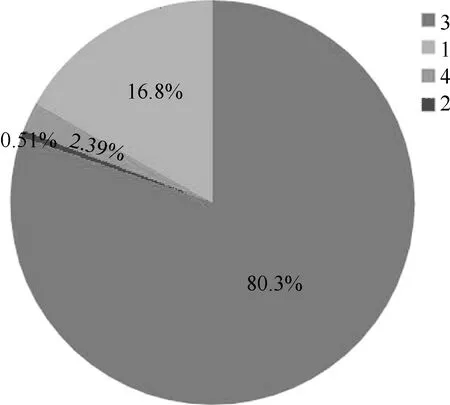
图8 每个缺陷类别像素值覆盖范围的饼状图划分
2.2.4 数据生成器
Keras数据生成器继承keras.utils.Sequence,结合fit_generator实现节约内存训练。原始数据掩膜像素大小为1 600×256,像素转换后为定义的掩膜宽度self.img_w和掩膜高度self.img_h。python生成器以每批次32个样本数据,图像宽×高为512×256的图像数据,不断循环目标文件夹内的图像并且不停迭代生成批量数据。
在数据统计和分析阶段,得出结论:所选取的钢铁数据集具有数据集不平衡、图像缺陷存在细小处的图像特征,且缺陷类别3占比最大,其余3类缺陷占比较小。
2.3 网络训练
使用U-Net和Res-UNet两个U型神经网络模型训练相同的钢铁数据集,在相同损失函数情况下,对比训练结果,对模型进行评估,实现钢铁缺陷的图像分割。原始图像像素1 600×256,重置图像大小为800×256,共迭代25次。图像数据12 568个,validation验证集与train训练集的比例为2∶8,即2 514∶10 054。
实验环境:kaggle平台的在线编辑器,GPU环境。
U-Net网络模型共包含9个单元模块。解码器部分为模块1至模块4,每个模块包含两个3×3卷积层和1个2×2最大池化层。桥梁部分为模块5,模块包含两个3×3卷积层和1个2×2上采样层。编码器部分为模块6至模块9,每个模块包含1个特征拼接层、2个3×3卷积层和1个2×2上采样层。输入模型的参数为256×800×1,输出模型的参数为256×800×4。
Res-UNet网络模型共包含10个单元模块。编码器部分为模块1至模块5,每个模块包含2个BN批量归一化层、2个激活层、2个3×3卷积层和1个addition层。桥梁部分为模块6,包含2个BN批量归一化层、2个激活层、2个3×3卷积层和1个上采样层。解码器部分为模块7至模块10,每个模块包含1个特征拼接层、2个BN批量归一化层、2个激活层、2个3×3卷积层、1个addition层和1个上采样层。输入模型的参数为256×800×1,输出模型的参数为256×800×4。
由上述数据统计和分析可知:钢铁数据集为数据不平衡数据集,并且存在缺陷面积细碎的特点。Tversky损失函数在处理数据集不平衡的问题时,具有较准确的实验效果,在召回率和精度之间可以达到较好的平衡。
基于Tversky的广义损失函数如式(1)所示。
(1)
式中:|A-B|代表FP假阳性;|B-A|代表FN假阴性;α和β为控制假阴性和假阳性之间权衡的系数。较大的α强调假阴性,使召回的准确性高于精确度,从而达到召回率和精度之间的平衡。因此,α选值0.7,β选值0.3。优化器为Adam,学习率或步长因子为0.05,epsilon为0.1。由于T(A,B)中所有项都为正,因此T(A,B)的取值范围为[0,1],当结果越接近1,则模型性能越佳。
2.4 结果与分析
本文通过U-Net和Res-UNet两种U型网络模型分别对钢铁图像数据进行数据训练,通过模型的Tversky系数和损失率对模型进行评估。
U-Net模型训练结果如图9所示。在25训练批次下,U-Net模型训练集Tversky系数最高为0.076,损失率最低为94.23%;验证集Tversky系数最高为0.083,损失率最低为93.75%。

图9 U-Net模型Tversky系数与损失率
Res-UNet模型训练结果如图10所示。在25训练批次下,Res-UNet模型训练集Tversky系数最高为0.74,损失率最低为35%;验证集Tversky系数最高为0.57,损失率最低为50%。
从图9和图10可以看出,Res-UNet训练集Tversky系数远远大于U-Net训练集Tversky系数,更接近于1;Res-UNet验证集Tversky系数虽有降低,但仍大于U-Net验证集Tversky系数。Res-UNet在训练集和验证集的损失率都小于U-Net。结果表明,Res-UNet模型在对钢铁数据集的缺陷分割中,模型性能更佳。以Res-UNet网络模型为例,将模型预测的缺陷结果进行可视化,如图11所示。由数据统计和分析可知缺陷类别1和缺陷类别2占比过小,对此类细碎缺陷的识别难度较大,预测结果仅可以成功预测出缺陷类别3和缺陷类别4。

图10 Res-UNet模型Tversky系数与损失率

图11 缺陷预测结果可视化
3 结束语
对于钢铁图像的缺陷检测问题,本文在前期有关U型深度学习网络模型的基础上,使用2种U型神经网络模型U-Net和Res-UNet训练有缺陷的钢铁图像数据。在数据统计和分析阶段进行掩膜图像数据合成、数据统计和数据预处理。在网络训练阶段,将U-Net和Res-UNet分别训练相同的钢铁图像数据,在相同Tversky损失函数下和相同的训练批次下,对比Tversky系数和损失率,从而对两种模型进行评估,实现预测缺陷的可视化。
实验证明,在相同的25训练批次下,Res-UNet模型训练集Tversky系数最高为0.74,而U-Net模型训练集Tversky系数最高仅为0.076。Res-UNet在损失率上与U-Net相比,有很大程度的降低。Res-UNet模型训练效果远远强于U-Net模型,在缺陷分割效果上,Res-UNet相比U-Net具有更好的性能,对于钢铁图像的缺陷位置和缺陷类别的识别更清晰和准确。但是,由于钢铁数据集数据高度不平衡,缺陷类别1和2占比非常小,缺陷面积存在细碎处,因此对于此类缺陷的识别难度较高。在后续的工作中,将继续改进网络模型,找到细碎缺陷的进一步解决办法,从而达到更好的训练效果。
猜你喜欢
学与玩(2022年8期)2022-10-31
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
少儿画王(3-6岁)(2020年4期)2020-09-13
小学生作文(低年级适用)(2019年5期)2019-07-26
东方教育(2018年20期)2018-08-22
军事文摘·科学少年(2016年8期)2016-11-02
学苑创造·A版(2016年4期)2016-04-16
