
基于改进字节对编码的汉藏机器翻译研究
2021-04-09 03:10头旦才让仁青东主尼玛扎西于永斌邓权芯
电子科技大学学报 2021年2期
头旦才让,仁青东主,尼玛扎西*,于永斌,邓权芯
(1. 青海师范大学藏文信息处理教育部重点实验室 西宁 810008;2. 西藏大学信息科学技术学院 拉萨 850000;3. 电子科技大学信息与软件工程学院 成都 610054)
机器翻译是利用计算机自动地将一种自然语言转换为相同含义的另一种自然语言的过程[1]。机器翻译在语言形态上分为语音翻译和文本翻译,其历史发展已从基于规则的机器翻译、基于统计的机器翻译发展至基于神经网络的机器翻译(即神经机器翻译)。目前,神经机器翻译已经取代统计机器翻译,成为Google、微软、百度、搜狗等商用在线机器翻译系统的核心技术[2]。
神经机器翻译最早在2013 年被提出,但是存在长距离重新排序和梯度爆炸消失等问题,翻译效果不理想[3]。2014 年,文献[4]提出了编码器和解码器框架,引入了长短时记忆模型,解决了长距离重新排序和梯度爆炸消失等问题,同时神经机器翻译的主要难题变成了固定长度向量问题。2015 年,文献[5]将注意力机制应用到机器翻译中,解决了固定长度向量问题。
注意力机制的模型将注意力放在一些相关性高的词上,编码器和解码器之间通过注意力机制连接[6],在翻译目标单词时检测其与源端语句相关的部分,解码时融合了更多的源语言端信息,可以显著提升机器翻译效果,是目前神经机器翻译的主流方法,应用广泛。2018 年,文献[7]使用自注意力机制来增强序列标注模型的全局表示能力,从序列标注任务端减少汉文分词对随后翻译对影响的方法。在此基础上,文献[8]提出了格到序列的神经机器翻译模型。通过实验,该模型在翻译性能上显著优于传统的基于注意力机制的序列到序列基线系统。同年,文献[9]提出简单循环单元的注意力机制模型。2019 年,文献[10]提出了一个稀疏注意力模型,解决了注意力权重分布问题。2020 年,文献[11]提出了一种深度注意力模型,大大提高了系统翻译的忠实度。综上,基于注意力机制的模型成为目前神经机器翻译领域的主流模型。
近几年,研究人员在基于注意力机制模型的基础上,利用不同的方法进行了汉藏藏汉神经机器翻译研究。2017 年,文献[12]基于注意力机制和迁移学习方法,将英汉神经网络机器翻译模型参数迁移到藏汉神经网络机器翻译模型中。2018 年,文献[13]将注意力机制模型应用于汉藏机器翻译任务中,实现了汉藏书面语料和口语语料的神经机器翻译。2019 年,文献[14]在transformer 模型上,运用百万句子单语数据大规模迭代式回译策略,实现了藏汉神经机器翻译模型,文献[15]也使用transformer实现了藏汉神经机器翻译模型,并将藏语单语语言模型融合到藏汉神经机器翻译中。
汉藏机器翻译中的命名实体处理一直是最难以突破的一个技术环节,为处理命名实体、同源词、外来词和形态复杂的词,本文在模型训练时,改进藏文字节对编码算法,优化了基于注意力机制的翻译模型,使得汉藏神经机器翻译效果更加准确。
1 基于注意力机制和改进字节对编码模型
藏文是拼音文字,音节之间用分隔符隔开,词与词之间没有明确的分隔符,再者藏文有格助词、助动词等汉语文法不具有的语法单元,所以对应的翻译句子长度比汉语长。
1.1 注意力机制模型
为了解决长句的翻译问题,本文系统(阳光汉藏机器翻译系统V2)采用了基于注意力机制的神经机器翻译模型。

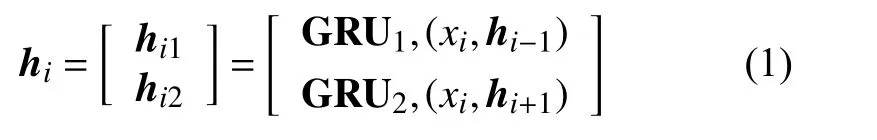
式中,GRU1和GRU2是两个门控循环单元,从两个方向循环地对x 编码,然后拼接每个词的输出状态,即h={h1,h2,···,hls}。
解码器依次生成藏文词 yj:

通过最大化藏文词汇的似然来优化整个翻译模型:
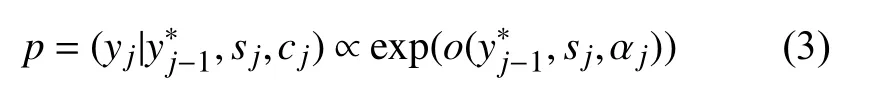

式中,GRU 是非线性函数; αj是每次解码动态更新的汉文上下文表示,依赖于汉文编码序列h={h1,h2,···,hi}即每个汉文词语状态的加权和:
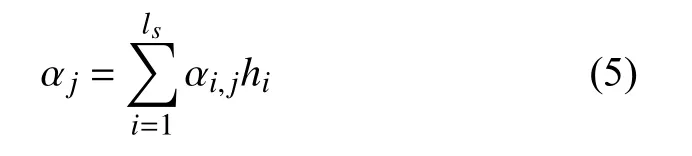
式中, αi,j是第i 个汉文词语与第j 个藏文词语之间的对齐概率:

式中, ei,j是对齐模型,通过前馈神经网络,计算出i 时刻生成的藏文词与第j 个汉文词的匹配程度。图1 为基于注意力机制的神经网络翻译模型,其中, yj表示模型在第j 步所预测词语的概率分布,极大似然估计(MLE)表示计算损失的方法[16]。
1.2 改进的藏文字节对编码算法
本文为了提高模型的稳定性和翻译的准确率,训练时使用了一种带字数阈值的的藏文字节对编码算法,优化了翻译模型。首先简单描述一下原始字节对编码算法。
1.2.1 字节对编码
字节对编码(byte pair encoding, BPE)指通过自动发现稀疏词,建立基于稀疏词的神经网络翻译模型[17],即通过构造高频的字符片段,将稀疏词拆分为合适的子词,使得这些子词在语料中的出现次数足够高,从而进行训练,得到最优的翻译模型,BPE 算法流程图如图2 所示。

图1 基于注意力机制的神经网络翻译模型

图2 原始BPE 算法流程图
1.2.2 改进的藏文字节对编码算法
BPE 算法不需要对语料中的词汇进行任何处理,由于藏文的词与词之间没有空格,所以形式上不存在单词边界的问题,所以改进的BPE 算法中不需要词头词尾标记符号“</w>”。另外,通过分析藏文和汉文使用原始BPE 算法之后生成的子词长度分布情况,发现藏文和汉文对应最大子词长度分别为39 和21,在长度峰值上,藏文子词明显大于汉文子词。基于此,在分词粒度较大的藏文部分,本文提出了一种改进的BPE 算法,使用长度阈值控制藏文子词,合并出现频率略低但长度更适合的子词。其算法流程如图3 所示。

图3 改进的BPE 算法流程图
通过对比图2 和图3 的流程,相对于原始的BPE 算法,改进的藏文BPE 算法设置子词字数阈值,不提取字数超过该阈值的子词。实验表明,当设置的字数阈值为23 时,效果提升最为明显。
2 实验结果对比与分析
2.1 数据集
本文使用西藏大学和青海师范大学建设的107 万汉藏句对,经纠正错峰句对、检查拼写错误、校对断句错字和过滤重复句子,最终将100 万句对作为训练语料,其中80 万句对为新闻和法律题材,20 万句对为其他领域语料;测试集和验证集各1 000 句对。此外,为了提高翻译效果,建立了15 万词条的汉藏地名词典和5 万条的汉藏人名词典作为辅助工具。
2.2 参数设置
模型训练中,通过反复调整参数,最终获得最优的模型参数,具体描述如下。
所有的模型参数都使用随机梯度下降算法进行优化[18],学习率使用Adadelta 算法[19]进行自动调节;训练语料汉文端和藏文端保留的最大句长为50 词;汉文和藏文词向量维度为512;编码器和解码器中循环神经单元的隐状态和输出状态均设为512;模型最终输出层采用dropout 策略,dropout设置为0.5。
测试时本文使用束搜索算法进行解码[20],搜索过程中束大小设置为10。汉文端和目藏文端的词表大小设置为15 万,覆盖率100%。语料训练的轮数最大为50 轮。模型的超参数需要根据训练数据量来设置,通常数据量越大,模型的超参数如enc_hid_size、dec_hid_size 可以适当放大。
2.3 结果与分析
本文实现了基于PyTorch 框架的注意力机制汉藏神经网络机器翻译系统,循环单元采用门控循环单元,评测指标使用了BLEU4,采用基于字的评测方法。
汉藏双语语料库进行分词时,汉文分词使用了感知机、Hanlp 和BPE。藏文分词使用了西藏大学开发的基于Perceptron+CRF 模型的藏文分词系统[21]和改进的藏文BPE 算法。
本文在测试集、验证集一致的前提下,做了6 组实验。训练模型时,除实验1 未使用BPE 算法外,其他实验的译文和原文都使用了BPE 算法和改进的藏文BPE 算法。6 组实验的验证集和测试集情况如下表1 所示。

表1 实验数据集
为了体现命名实体的翻译效果,验证集和测试集的每个句子中至少包含了一个地名或人名,因此通过该测试集得到的结果应当具有一定的通用性且能够说明模型具有的泛化能力。
实验数据、方法、结果如表2 所示。
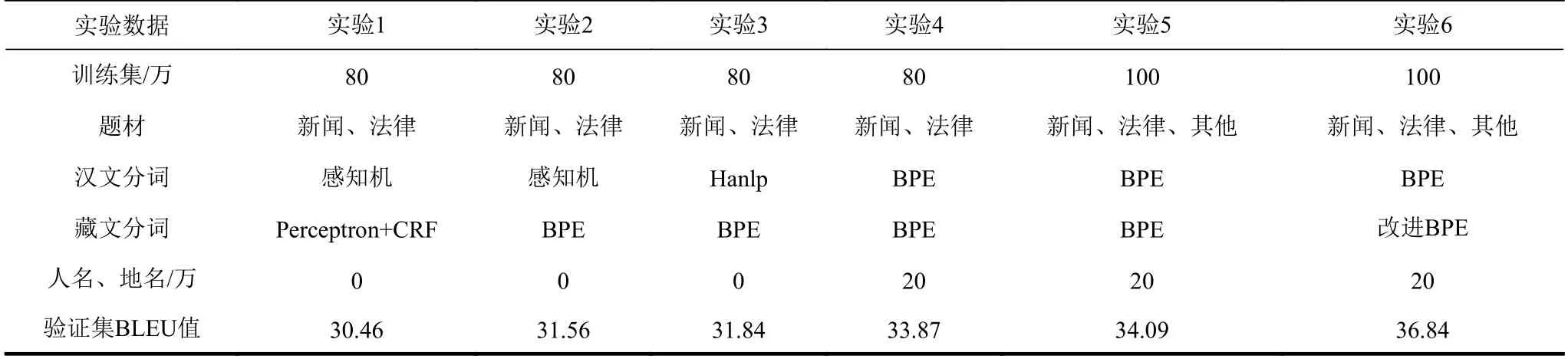
表2 实验数据、方法、结果
在实验中,第一组实验使用了基于平均感知机的汉文分词方法[22],目标端没有使用BPE 操作,BLEU 值最低,只有30.46。由于该汉文分词器的分词粒度较大,而藏文分词器的分词粒度较小,分词粒度的差异导致翻译效果不够好,另外由于汉文分词器的算法问题,导致前端的查询速度很慢。
第二组实验的汉文分词方法和第一组实验方法一样,但是对藏文端使用了BPE 算法。虽然分词粒度的差异导致翻译效果不够好,但是解决了一些稀疏词和低频词翻译问题,BLEU 值提高了1.10。
为了解决汉藏分词粒度的耦合性,第三组实验使用了Hanlp 汉文分词器[23],因为其分词粒度较小,也提供了更友好的Python 访问接口;同时还提供了词性标注等更高级的功能,为后续对模型的优化提供了更好的扩展性,另外查询速度也得到提升。使用BPE 操作,提供了更细的分词粒度,致使汉文分词和藏文分词粒度契合,BLEU 值达到了31.84。
为了进一步提高翻译效果,第四组实验的汉文分词使用了BPE 算法,并增加了20 万条的人名地名词典作为训练辅助工具,解决了命名实体翻译问题,BLEU 值提高了2.03,达到了33.87。
第五组实验在第四组实验的基础上,增加了20 万条的人物传记、小说和口语等双语语料,由于语料题材的多样性,BLEU 值仅提高了0.22,达到34.09。
上述五组实验结果得知,如果仅仅使用原始BPE 算法,BLEU 值提高1.06,如果增加命名实体词典,BLEU 值也仅仅提高2.03。为了体现改进的藏文BPE 算法的性能,第六组实验在第五组实验的基础上,在藏文端使用了本文提出的BPE 改进算法,这时BLEU 值提高了2.75,达到了36.84。
本文根据模型在验证集上的BLEU 值分数,当BLEU 值出现震荡或者模型过拟合,BLEU 值开始出现明显下降时,停止训练。
2.4 与已商用化的汉藏翻译对比
在已有的汉藏神经机器翻译研究[13-15]中,每个模型采用的训练语料和测试集不同,且目前汉藏机器翻译领域尚未存在公开的数据集,因此各模型的BLEU 值无法进行对比。
本系统在翻译任务上的效果较好,BLEU 值达到了36.84。原因如下:一方面,对训练语料进行了较为全面的校对,语料质量较高;另一方面,神经机器翻译中命名实体翻译一直是一个难题[24-25],通过改进BPE 算法和人名地名双语词典提升了命名实体翻译现象,如由于词典覆盖率不够,导致译文中出现了unk,而本文方法能够把原文的所有词语完整地翻译出来,不会出现unk。目前,国内一些高校和研究机构研发了在线汉藏机器翻译系统,其中,厦门大学开发的“云译”[26]和中国民族语文翻译局开发的在线智能翻译系统[27]等的影响较大。现将本文翻译系统与腾讯民汉翻译、小牛翻译[28]等已商用化的汉藏机器翻译系统进行对比,其翻译实例及结果如表3 所示。

表3 本系统与已商用化的汉藏翻译系统翻译实例结果对比
翻译实例1 和2 中包含了地名和人名,虽然1个汉文地名或人名的翻译结果有5 个对应的藏文地名和人名,但是汉藏地名人名翻译没有统一的标准可依,均可音译,所以5 个译文都没有错误,结果相当。
翻译实例3 中包含了藏区地名,汉文中的藏区地名翻译结果是统一的,所以本文翻译系统的译文完整地翻译了实例中的地名“夏河”和“合作”,其他译文的翻译都有错。
从以上翻译结果对比可以看出,各种汉藏神经机器翻译虽然翻译效果不错,但各自也都存在一些不足。就本文翻译系统而言,新闻和法律领域的翻译结果较为流畅,但是其他领域的翻译有待改进,如同样的句子加上和去掉标点符号得到的结果不同等现象。
3 汉藏神经机器翻译系统化
3.1 汉藏神经机器翻译模型总体流程
汉藏神经机器翻译模型由数据处理模块、模型选取模块、模型训练模块、翻译评测模块和系统化模块5 个部分组成,如图4 所示。
3.2 本文汉藏机器翻译系统架构
本文汉藏机器翻译系统V2 架构由电子科技大学数字信息系统实验室与西藏大学藏文信息技术人工智能自治区重点实验室搭建。系统架构主要由算法、后端和前端组成,算法就是模型的实验,后端设计主要由Flask 框架实现,首先将分词器和神经翻译模型的初始化工作放在Flask 后端初始化之前,并将其保存在内存中。每次请求到来时,只需调用已初始化完成的模型即可,这样减少了大量响应时间。经简单测试,加载神经翻译模型和分词器只需要50 ms。通过后端设计,还实现了Android前端和网页前端。汉藏神经机器翻译系统化总体架构如图5 所示。

图4 汉藏神经机器翻译模型总体流程

图5 汉藏神经机器翻译系统总体架构
4 结 束 语
本文利用100 万汉藏句对和20 万汉藏人名地名词条,进行了基于注意力机制的神经机器翻译实验,并提出了一种改进的BPE 算法,用以协调原始BPE 得到的藏文粒度大于汉文粒度的情况,将BLEU 提升了2.75%,减少了过度翻译、翻译不充分的问题,提升了命名实体翻译效果。设计实现了基于注意力机制和改进字节对编码的汉藏神经机器翻译模型,部署在阳光汉藏机器翻译网站,实现了该汉藏神经机器翻译系统的应用推广。本文汉藏机器翻译系统的模型具有语言无关性,完全可以应用到藏汉神经机器翻译研究中。
由于汉藏神经机器翻译目前缺乏大规模双语数据,而藏语单语语料比较充足,所以下一步将利用格到序列、半监督和无监督方法提升翻译效果。
共享和开放是计算语言学(自然语言处理)研究的发展趋势,该工作在汉英机器翻译技术领域获得了很好的进展,免费开放了一些汉英英汉双语平行语料,使得汉英机器翻译技术具有可比性和竞争性。汉藏机器翻译研究语言资源较少,没有公开的语料,而且资源问题一直是困扰神经机器翻译研究和产业化的首要问题[29]。为此,我们开放了部分实验数据和藏文地名词典(获取地址:https://github.com/toudancairang/Tibetan-Computationallinguistics/tree/master),希望吸引更多的人参与其中,建立藏文资源开放平台,推动藏语计算语言学(藏语自然语言处理)研究,促进中文信息处理技术的整体发展。
致谢:该模型的构建得到了中科院计算所自然语言处理实验室同仁的大力支持。
猜你喜欢
中国藏学(2022年1期)2022-06-10
辽金历史与考古(2021年0期)2021-07-29
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
学校教育研究(2020年3期)2020-02-18
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中国文化遗产(2016年5期)2016-12-14
西江月(2016年10期)2016-11-26
