
基于随机森林分类的端子缺陷检测研究
2021-04-07 00:26:14张捍东吴玉秀
蚌埠学院学报 2021年2期
陈 晨,张捍东,吴玉秀
(安徽工业大学 电气与信息工程学院, 安徽 马鞍山 243002)
接线端子现如今被广泛应用于各个领域,在传递电信号方面起到连接作用,一个合格的接线端子产品能给生产和使用带来诸多便利,避免许多麻烦。端子产品缺陷检测的目的就是检测出带有缺陷的接线端子,避免缺陷端子被应用到生产和生活中。缺陷端子有很多种类,例如压着端子变形、端子深压、端子浅打、端子氧化等。不同种类的缺陷端子在被应用后容易造成严重程度不同的恶劣后果。为杜绝缺陷端子流出,提升端子缺陷检测的效率,本文将随机森林模型应用于端子缺陷检测领域中,对端子缺陷信息数据进行随机森林模型的训练和建立[1],模型建立完成后使用测试数据集对模型进行性能评估,获得随机森林模型的应用评价。
1 随机森林算法
随机森林算法是以多个决策树为基学习器组成的,随机森林算法的结果让所有基学习器的决策结果进行投票,最终取得最高票数的就是结果[2]。随机森林算法具有容易实现,处理速度快,抗过拟合能力强等优点,已被广泛应用于医学、工业生产、林业等领域,且在各种应用任务中均表现出了良好的性能[3]。
1.1 算法介绍
随机森林(Random Forest,RF)[4]是引导聚类算法的一种拓展算法,RF以决策树作为基学习器搭建Bagging集成的基础,且在决策树的训练过程中进行随机属性选择。随机森林以决策树为基础,故决策树的理论也必须要了解。决策树有很多不同的变种,但是变种的核心主函数都是类似的,主要不同点是最优特征标准的选择。根据最优划分属性(特征)选择的不同,决策树算法又分为ID3决策树学习算法、C4.5决策树算法和CART决策树算法等几大类,下面介绍这几种决策树算法。
ID3决策树学习算法是以样本信息的信息增益(information gain)进行最优划分属性的选择,信息增益来自于信息熵(information entropy), 信息熵是最常用来度量样本集合纯度的指标。其式如下所示:
(1)
式中D为样本集合,pk(k=1,2,…,|y|)为第k类样本所占的比例,且Ent(D)的值越小,代表样本D的纯度越高。假定由属性a对样本集D进行划分并产生V个分支节点,记其中第v个分支节点为Dv,则属性a对样本集D划分所获得的信息增益为:
(2)
由式(2)可看出,信息增益越大,则说明属性a划分集合D所获得的纯度提升越大。故可选用信息增益作为划分属性选择,这就是著名的ID3决策树学习算法[5]。
C4.5决策树算法是以信息增益率(gain ratio)选择最优划分属性[6]。由于ID3算法对连续型变量属性的处理效果非常差,并且更偏好属性分类较多的属性,为了减少这种偏好的不利影响,Quinlan提出使用信息增益率选择最优划分属性,这就是C4.5决策树算法。增益率符号与公式(2)相同,定义公式如下:
(3)
其中
(4)
CART决策树是以基尼指数(Gini index)选择最优划分属性,采用符号与公式(2)相同,则数据集D中属性a的基尼指数计算公式为:
(5)
Gini(D)(基尼值)表示数据集的纯度,即从数据集中随机抽取样本类别不一致的概率,基尼值越小,表示所抽取的数据集纯度越高,Gini(D)计算公式如下:
(6)
使用决策树算法可获得决策树,而随机森林算法则是以单决策树为基学习器集成的分类器,这种集成分类器克服了单分类器的很多缺点,具备极好的准确率。RF的思路就是通过对各个单决策树的分类结果进行投票,将票数最高的结果作为RF的分类结果。随机森林的两次随机抽样非常关键,首先就是用bootstrap的有放回随机采样,每个基学习器只使用约63.2%的初始训练集的数据,剩下约36.8%的数据则可用于对RF模型进行改进优化[7]。其次是选择特征时的随机抽样,保证生成决策树时选择的特征不完全一样,再将所有已构建的决策树相连,即构成了随机森林。RF的运行过程是利用自助采样法(bootstrap sampling)对训练集处理,获得多个训练子集,再通过处理训练子集产生众多决策树,最后在对这些决策树的结果进行投票获得RF的分类结果。
1.2 随机森林模型性能指标
用随机森林模型对测试集样本数据进行分类,根据测试集样本真实类别和学习器预测类别将分类结果划分为真正例(truepositive)、假正例(falsepositive)、真反例(truenegative)和假反例(falsenegative)四种情形,获得分类结果的混淆矩阵[8],如表1所示。

表1 分类结果混淆矩阵
准确率Accuracy、查全率Sensitivity、查准率Precision、特异度Specificity和F1的相关定义[9]如下:
(7)
(8)
(9)
(10)
(11)
其中准确率Acc是通过算法分类正确的样本数所占的比例,查准率Pre可视为精确性的度量,查全率Sen和特异度Spe体现了算法分类的真正例率和真负例率,F1则是基于查准率和查全率的调和平均定义的,这是一种更为常用的性能指标。
2 模型构建
将随机森林应用于端子缺陷检测中,首先需要训练一个可用于分类的随机森林模型。因随机森林由众多决策树组成,训练随机森林模型的过程实质上就是训练众多分类决策树的过程。
2.1 随机森林模型训练
随机森林算法应用于端子缺陷检测中的算法步骤如下:
(1)电压数据预处理[10]。对电压数据进行滤波处理,消除电压采集过程中出现的抖动和高频噪声。再对电压数据进行处理,获得包含100组特征数据的训练集D,训练集D中含有6种分类属性。
(2)使用自助采样法(bootstrap)对训练集D进行抽样,每次抽取样本数量为63个,获得新的训练子集。
(3)从6种分类属性中随机抽取t(t≤6)种属性,使用CART决策树算法选择最优划分属性(CART算法相对ID3和C4.5算法不会对特征属性数量有偏好),选择最优叶子节点,在子样本集中获得所有的叶子节点。
(4)重复进行步骤(3),在所有的决策树生长完成后,随机森林模型就完成训练。
随机森林算法训练流程如图1所示。
2.2 随机森林模型分类
随机森林分类图如图2所示,使用RF模型分类步骤如下:
(1)对任一已训练完成的分类树,只要有样本变量输入,相对应的节点变量从决策树的根节点达到末节点,末节点的结果即作为这棵决策树的输出结果[11]。
(2)对随机森林中所有的决策树都重复步骤(1),这样RF中每棵决策树都可以输出对变量的分类结果,将这些结果进行投票就可以获得RF的分类结果。
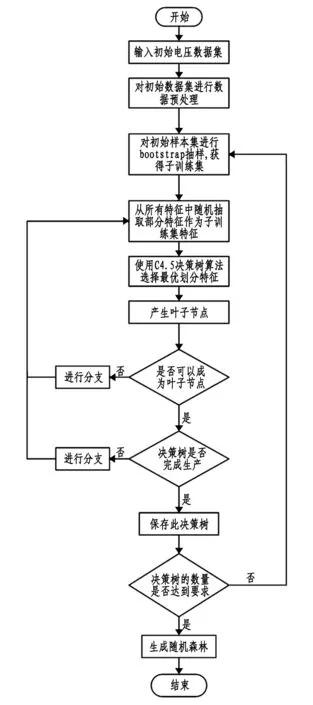
图1 随机森林模型训练流程图

图2 随机森林分类流程图
2.3 使用加权方法进行决策结果投票
传统的随机森林将所有的决策树对决策结果的影响看成是相等的,即通过等权重投票获得决策结果[12]。本文则对投票的过程进行了改进,计算RF中所有决策树在分类过程中的分类精度,以分类精度度量决策树的性能及其对RF的影响,而后再根据各个决策树的分类精度进行加权投票从而获得RF的分类结果,以此提高了RF的准确性。又因RF在获得子训练集时是使用bootstrap方法,所有的基学习器只使用了初始训练集约63.2%的数据,剩下约36.8%的袋外数据可对已训练完成的决策树进行评估,则可以获得n棵决策树的精度向量。
VAcc=[Acc1,Acc2,Acc3,…,Accn]
(12)
将袋外数据用于决策树的分类精度评估,直到获得全部n棵决策树的精度向量VAcc。将获得的精度向量赋予权重,即wn=Accn,可得到所有决策树在决策结果投票时应有的权重向量WA。
WA=[w1,w2,w3,…,wn]
(13)
其中Accn为RF中各个决策树的分类精度,wn则为各个决策树在投票时所占的权重[13]。根据单棵决策树计算所得的权重确定该决策树在整个随机森林结果分类中所占的权重比例,在最终结果投票时分类结果与权重向量相乘获得最终分类结果。
3 结果和分析
为测试随机森林算法应用于端子缺陷检测时的性能效果,也为了与其它分类器算法作对比,实验还将BP神经网络分类算法和SVM分类算法与RF算法作比较。使用三种分类方法对同一组端子缺陷信息数据集做分类处理,使用Acc、Sen、Pre、Spe和F1作为评估算法性能的指标。
3.1 实验数据
为训练随机森林模型,对所有的电压数据集进行预处理,得到所有的压力曲线信息,每一条压力曲线信息对应接线端子生产时所受的压力变化,提取电压数据特征值成为训练随机森林模型的初始数据集,而后对模型进行测试评估并获得实验结果。端子缺陷数据表如表2所示。

表2 端子缺陷数据表
3.2 模型决策树最优个数
随机森林模型中决策树的数量影响分类结果的准确性,为了保证RF分类结果的准确性较高,必须要获得RF模型中决策树的最优数量。使决策树的数目在0-500范围内变化,每次增加50棵决策树,以不同决策树数量训练随机森林算法模型,并对不同数量决策树训练的随机森林模型通过模型准确率Acc进行评价,从而找出随机森林模型准确率和决策树数量之间的关系。 获得的决策树个数与RF模型性能指标的准确率Acc的变化关系如图3所示,从图3中可以看出,当决策树的数量较少时,准确率Acc也较低,随着决策树数目的增加,RF模型的准确率Acc也在增加,且增加的幅度越来越小。出现这种变化趋势的主要原因是由于训练样本和节点变量都是随机选取的[14],在决策树数量较少时,会因为随机性导致RF模型的准确率偏低;当决策树的数量逐渐增多时,这种随机性也在不断降低,各个变量都能全面地对分类结果造成影响,所以训练模型的准确率也在逐渐增加;当决策树增加到一定数量时,随机性对RF模型准确率造成的影响已经最小,即便是继续增加决策树的数量,准确率也不会提高[15]。由图3能看出,当随机森林内部决策树的数量达到400时,模型准确率不再继续提升,因此选择决策树数量400作为最佳数量。

图3 RF模型查准率与决策树数量关系图
3.3 模型分类结果和分析
在分类树数量为400时,使用随机森林模型对测试集数据进行分类,统计分类结果并获得模型准确率Acc、查准率Pre、查全率Sen、特异度Spe和F1的值,如图4所示。
从模型性能图可以看出,RF模型的准确率Acc达到了0.94,即随机森林模型在理想情况下对端子缺陷信息识别准确达到0.94,这已经远远高于传统人工检测的准确率;且模型的Pre达到了0.95,Sen达到了0.86,Spe达到了0.87,模型的F1指标也达到了0.9以上,这些都说明了将随机森林模型应用于端子缺陷信息检测中的可行性。使用机器学习方法检测端子缺陷还能大幅度缩减人工成本,降低检测时间,极大地提升了端子缺陷检测的效率,是未来端子缺陷检测的趋势。

图4 RF模型性能评估图
3.4 RF模型与其它算法比较
为了测试随机森林算法应用于端子缺陷检测时性能是否优于其它分类算法,同时也为了与其它算法性能做对比,本实验采用随机森林、BP神经网络和支持向量机对同一组缺陷信息数据集做分类处理[16],BP神经网络采用非线性激活函数:Sigmoid函数;支持向量机以高斯函数作为其核函数。以准确率Acc、查准率Pre、查全率Sen、特异度Spe和F1值作为度量这三种分类算法的指标,实验获得的算法性能如表3所示。

表3 各算法性能表 %
根据表3中随机森林、BP神经网络和支持向量机模型的性能指标,RF模型的准确率为0.94,比BP神经网络模型高4%,比SVM模型高6%,其查准率为0.95,比BP神经网络模型高6%,比SVM模型高9%,其F1值为0.902,比BP神经网络模型高4.8%,比SVM模型高6.2%,由此可知RF模型的这三个性能指标都明显高于BP神经网络模型和支持向量机模型,在分类精度上有更好的表现,故可以将随机森林模型应用于端子缺陷检测中。
4 结论
使用随机森林算法对端子缺陷进行检测,分类效果要远高于传统的分类方法,其分类时间也远小于人工分类所需要的时间,极大地提升了端子缺陷检测效率。利用训练随机森林模型使用的袋外数据对RF做进一步的提升,以此提升随机森林模型的准确率。和另外两种分类算法相比较,随机森林模型在分类性能上确实具备更好的表现。之后的研究方向可以放在检测出端子缺陷种类上,即通过分类算法检测出端子缺陷的类型,进行多分类,可直接分出端子缺陷的类型,在算法中会体现出复杂性,也是对此算法的提升。
猜你喜欢
建筑与预算(2023年9期)2023-10-21 10:14:34
建筑与预算(2023年2期)2023-03-10 13:13:40
建筑与预算(2022年2期)2022-03-08 08:41:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
