
中国城镇居民健康的性别差异分解模型
2021-04-06 08:49熊彦
佛山科学技术学院学报(自然科学版) 2021年2期
熊 彦
(佛山科学技术学院 数学与大数据学院,广东 佛山528300)
1 问题提出
两性平等是现代社会中一个重要的课题,以往的研究大都集中在男女收入、薪酬方面的不平等,而对两性在健康方面的差异研究相对较少。国际上关于健康性别差异的讨论表明,尽管女性有更长的预期寿命,但是相比男性有更高的发病率和更差的健康状况。一些针对发达国家的研究表明,女性在健康方面的劣势,主要是由女性的社会角色及社会经济地位弱势造成的[1]。关于中国人口健康的性别差异,Yu M 等[2]讨论了男性和女性在死亡率、发病率等医学指标方面的差距,姜秀花[3]讨论了卫生服务利用的男女不平等问题。近年国内学者已经认识到社会经济因素对人口健康影响的重要性[4],郑莉[5]通过分析收入、教育、职业等变量对健康的回报率在男女组别的不同来研究健康的性别差异。以上研究虽然都明确了社会经济因素在健康性别差异中的重要影响,但是,都不能定量回答由社会经济因素引起的健康性别差异究竟有多大,同时,由于社会经济因素是一个综合的概念,需要多个维度的度量指标进行刻画,这些指标中,哪些对健康性别差异影响大,各自对男女健康差异程度占多大影响比例,前面的文献也不能回答。要回答以上问题,需要运用统计学的方法,对男女两个组别的健康差异进行定量分解,至今国内外尚未有任何这方面的研究。
对某一变量在两个组别间的差异进行分解,始于Oaxaca[6]和Blinder[7]在1973 年各自提出的开创性工作,也就是此后广为应用的Oaxaca-Blinder 分解方法。经典的Oaxaca-Blinder 分解只是两个群组间基于线性回归模型的定量变量差异的分解,对二元定性变量的差异分解却无能为力,Neilson[8]和Fairlie[9]将传统的Oaxaca-Blinder 分解方法进行了扩展,使其适用于非线性模型的定性变量差异分解。此外,Oaxaca-Blinder 分解方法还存在指数基准问题等固有缺陷,也就是分解中,选择两个群组中(如男、女)哪一种作为基准组,会使得分解结果存在较大的区别,Reimers[10]、Cotton[11]、Oaxaca 等[12]针对指数基准问题对Oaxaca-Blinder 分解方法提出了改进。本文正是在Fairlie 适用于非线性模型的定性变量差异分解框架下,运用改进的Oaxaca-Blinder 分解方法,对我国城镇居民健康的性别差异进行了分解研究。与此前文献相比,本文有两方面的突破:一是本文关于社会经济因素变量的度量不同于已有文献直接沿用国外文献中的选择方案,而是从中国社会当前的特征出发选定度量指标;二是本文应用统计方法,对城镇居民男女组别的健康差异进行了定量分解,量化了各部分对性别健康差异的贡献率。本文的研究结论能更深入刻画我国城镇居民健康性别差异的结构,为进一步深入研究社会经济因素与健康性别差异奠定基础,同时为从社会经济因素角度来缩小健康性别差异提供了政策启示。
2 模型与方法

其中,ΔX 反映的是由于协变量不同带来的平均差异,即在两群组的回归系数一致(反事实)的情况下,由于X 的不同引起的Y 在两个群组间的差异,即可被协变量本身不同所解释的部分(在文献中称为变量效应),ΔS 是在两个群组的协变量取值相同(反事实)的情况下,由于方程结构(回归系数)不同引起的Y 在两个群组间的平均差异,即不能被协变量本身不同所解释的部分(在文献中称为结构效应)。以上为一般的Oaxaca-Blinder 分解方法。
本文中Yg表示是否健康二元定类变量,以上针对定性变量的分解方法不再适用。对二元定类变量Y,其与社会经济因素的关系通常用Logit 模型来拟合,即
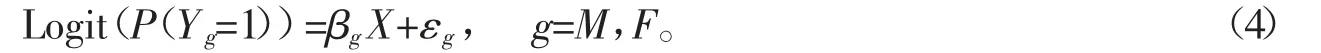
按Fairlie 的非线性模型分解框架,本文先将上面的模型等价写为

其中F 为Logistic分布函数,于是

经过数学推导,总差异Δ 可以写为如下两项,第1 项为
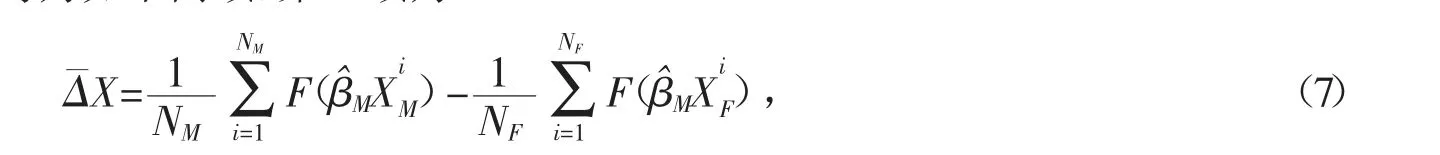
表示可被社会经济因素变量本身不同解释的差异,本文称之为变量效应。第2 项为

表示由社会经济因素影响系数不同引起的差异,本文称之为结构效应。
注意到,以上过程都是选择了M 组作为分解基准,也就是特征效应中选择了M 组βM作为系数。学者们在应用中发现,如果选择F 组作为基准,分解结果有很大的差异,Reimers 等[10-12]提出更为合理的做法,将M 和F 混合组系数β*用于特征效应的估计,本文采用这种做法,于是变量效应和结构效应分别变形为
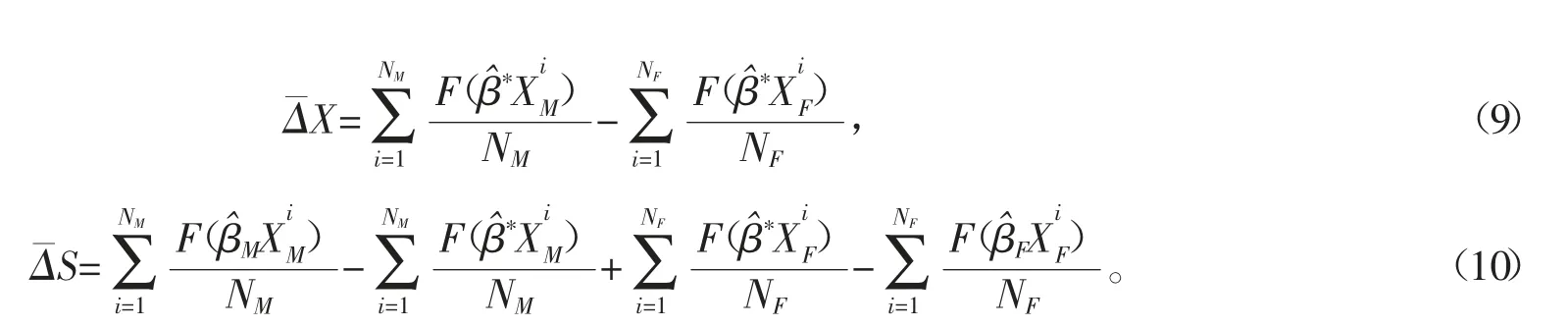
在总的变量效应ΔX 中,每一个社会经济因素变量引起的效应该如何估计,是一个比较困难的统计问题,文献中提出的方法各有优劣。Fairlie 的方法在两群组样本量一致的情况下,可以完美地解决这个问题,但对应用中两样本量不一致的情况,Fairlie 提出样本容量大的组别随机选取一个与较少组别相同容量的子集,然后按样本量一致的情况进行单个特征变量效应分解,这样的处理使得结果成为一个随机变量。Fairlie[9]证明该随机量是真实值的渐近无偏估计。国内已经有个别学者,应用上述方法框架对就业率(也是二元定性变量)城乡差异进行了分解,不过其文中并未将总变量效应继续分解到各变量项上去[13]。
依照上述分析框架,本文拟定的分解步骤为:1)先利用全体样本拟合影响健康的社会经济因素Logit 模型;2)拟合各组别的影响健康的社会经济因素Logit 模型;3)将前两步取得的系数分别代入方程(9)、(10),获得健康差异的总变量效应与结构效应;4)从较大样本组中,选取一个与较小样本中容量一致的子样本,利用该样本与较小样本组,将总变量效应分解到各变量的效应;5)多次循环4),把各次结果的均值作为各分项变量效应的点估计,并求出其置信区间。
3 实证研究
3.1 数据来源
本文选取家庭收入调查项目组2016 年发布的CHIP2013 城镇人口数据作为研究样本,CHIP2013数据主要是家庭收入方面的调查结果,也包含个人健康信息,是能公开获得的最新个体健康大型微观数据集,数据的详细说明可以参见中国收入分配研究院的网站。CHIP2013 城镇居民样本共有6 674 个家庭,19 887 个居民数据。包含个人特征、家庭收支和家庭其他特征3 类信息,家庭的收支和家庭特征问卷是由户主代表作答。由于家庭特征方面的信息大都为多分类的无序定性变量,对缺省值不便于插值补充,因此,对缺省值和错误应答条目,本文采取直接删除的处理方式,最后得到有效样本容量为4 375 个,其中男性样本3 390 个,女性样本为985 个。
3.2 指标选择
因变量方面,基于以下三方面的考虑,本文用个人健康自评得分作为个人健康状况的测度:第一,已有的研究表明,自评健康数据与其他客观健康指标高度相关;第二,相比其他客观健康指标,自评健康是一个更综合反映生理和心理、客观和主观感受的度量指标;第三,本文选择的CHIP2013 数据集样本覆盖面广、且包含了丰富的社会经济因素变量,是本文研究主题最好的数据来源,在CHIP2013 调查中,只包含个人自评健康信息而不包含任何单一的客观健康指标。CHIP2013 所提供的个人自评健康选项为五个等级:非常好、好、一般、不好和非常不好。本文在处理时,沿用已有文献的做法,将其归并为两类,其中非常好和好归为健康,一般、不好和非常不好归为不健康。
自变量方面,关于社会经济因素的度量,尚未有统一的共识,事实上影响因素变量的选择应该更密切来源于研究对象。齐良书[14-15]、黄洁萍[16]在综述了大量已有文献的基础上,指出收入、职业和教育是三个支柱性的维度,黄洁萍[16]、王甫琴[17]等学者关于社会经济因素对健康影响的机制研究也表明从收入、职业和教育三个维度选择变量是合理的。本文基于收入、职业和教育三个维度,同时立足于中国的社会经济特征来选择社会经济因素变量。中国文化是重农文化,是群本本位的沃土,重视群体价值、家庭价值,个人价值依赖于家庭与社会,个人是家庭的一份子[18]。东方文化长期受儒家文化的影响,家庭处于极其重要的位置,个人不能超越家庭发展[19]。而且,经验证据表明,在现代化进程中,家庭整体利益观,为家庭承担责任的观念未受到冲击[20]。本文选取年龄、职业身份、教育程度作为个人层面的特征;将家庭年收入、亲友是否可靠、自己家庭是否高于周围其他家庭的生活水平(简称为是否有更好的生活水平)、是否有比自己家庭生活水平更高的朋友(简称为是否有更好的朋友)作为家庭层面的特征。年龄使用分段归并为老年、中年和青年三类,职业身份归并为雇主和非雇主二类,教育程度采用教育年限变量,家庭收入为2013 年家庭可支配收入,其他家庭特征变量均归并为二元变量。各变量的描述统计见表1。
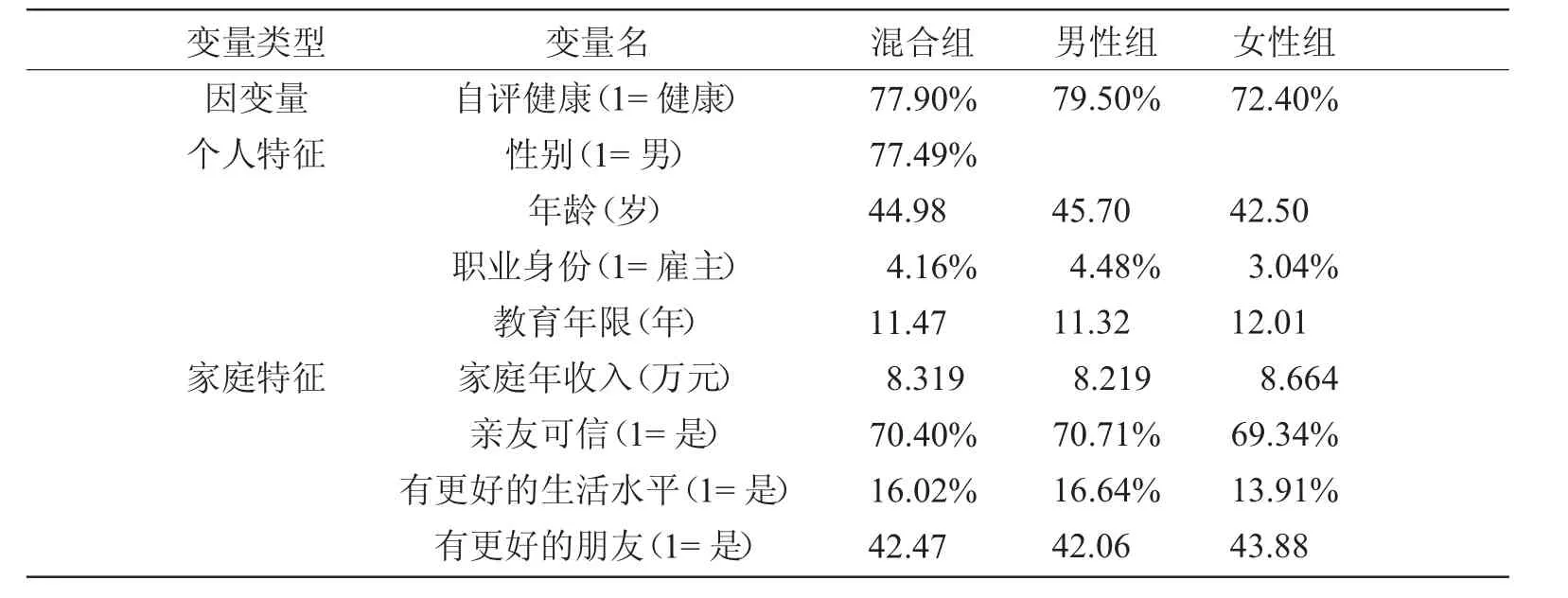
表1 各变量描述统计
从表1 可以看出,男性自评健康得分高出女性组7 个百分点。社会经济特征方面,男性组样本年龄、职业身份中的雇主比例、亲友可信比例以及自己家庭比周围家庭有更好的生活状况比例高于女性组,而教育年限、家庭年收入、拥有比自己生活水平更好的朋友的比例低于女性组。
3.3 模型拟合及分解
首先按男女组混合、男组和女组分别拟合了个人健康的社会经济特征Logit 模型,结果显示,混合组、男性组中,除了拥有更好生活水平的朋友变量外,其他各社会经济特征变量系数均高度显著,表明这些社会经济因素对居民健康有显著影响,剔除拥有更好生活水平的朋友变量后,模型结果见表2。可以看出,各社会经济特征变量对健康的影响系数在男性组与女性组有较大的差异,其中教育年限、职业身份对男性的健康的影响系数明显高于女性,这与郑莉[5]应用CHNS 数据集拟合的结果一致。
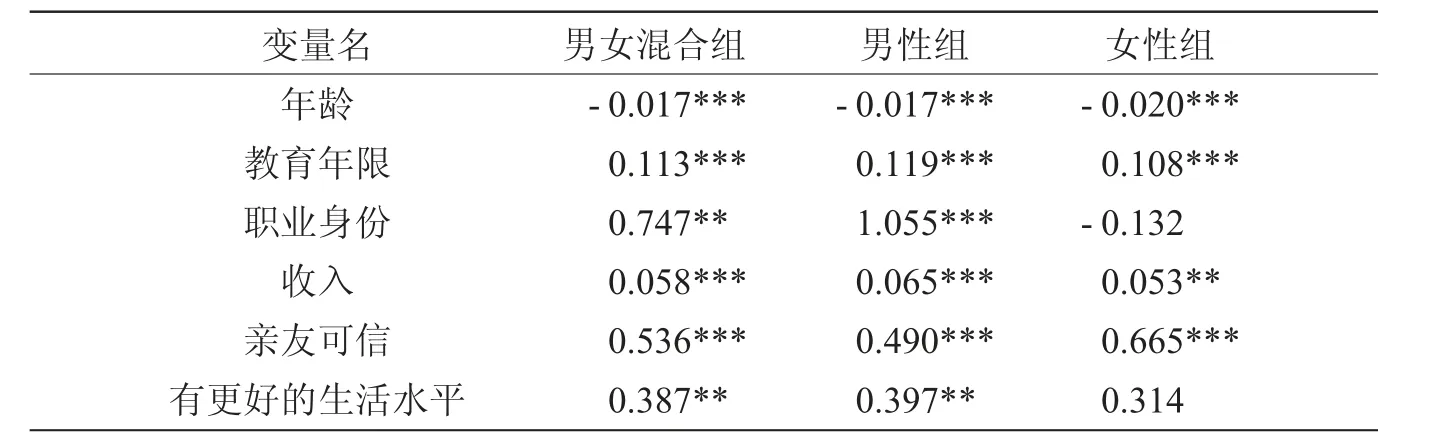
表2 个人健康Logit 模型拟合结果
按第二部分分解步骤,对男女健康差异进行分解,先将总差异分为变量效应和结构效应,然后再从男性样本中抽取与女性组容量相同的随机样本,对变量效应进行分项分解,并将此过程重复10 000 次,我们报告了10 000 次的均值结果和其置信度为0.95 的置信区间,见表3。注意到由于分项分解是在男性子样与女性样本之间进行,所以各变量分项效应之和不完全等于总的变量效应。本分解的结果显示,由于男女性别间社会经济因素本身不同,导致的健康差异占23.8%,而由于不同社会经济因素对健康的影响不同导致的差异占77.2%。根据10 000 次重复抽样计算结果,各特征分项效应的95%置信区间的波动幅度大都在10%以内,各变量的效应总和与总的变量效应的差异在5%以内。从贡献份额来看,职业身份的效应贡献了最大份额,占30%以上,而女性在教育、年龄、家庭收入变量方面更占优势,所以这些变量抑制了男女健康差异的扩大。

表3 男女健康差异分解结果
4 结论与讨论
本文从个人和家庭两个层面入手,选取了城镇居民的社会经济特征指标,用Logit 模型拟合了我国城镇居民自评健康得分与各社会经济特征因素之间的关系,然后,在Fairlie 非线性Oaxaca-Blinder 分解的框架下,对男女组间健康差异进行了定量分解。本文的研究有如下发现:
(一)本文模型结果是基于2013 年的数据得出的,在此前后我国居民医疗保障制度进行了重大调整,而本文结果表明,个人层面和家庭层面的社会经济特征都对个人健康有显著的影响,这是扩展了已有文献中基于早期数据的结论,丰富了刻画社会经济因素变量和指标的选择。
(二)从Logit 回归结果来看,年龄对人口健康有负向影响,教育年限增加,家庭收入增加,较高职业身份,可信的亲友,在生活水平更好的家庭,对人口健康都有正向影响。但是各社会经济因素对男性和女性的健康影响不同,甚至对男性健康有高度显著影响的因素如职业身份和有更好的家庭生活等,对女性组的健康并无显著影响,这种影响机制的性别差异在郑莉[5]的研究中有所探讨,也是本文分解结果中,社会经济因素对健康的影响不同造成的健康性别差异超过3/4 的原因。
(三)定量分解显示,我国城镇居民中,男女组别健康差异主要由社会经济特征对健康影响不同的差异引起的,其产生的结构效应达77.2%,而由于社会经济因素本身的不同导致的健康差异只有23.8%。各单一社会经济因素指标中,职业身份的差异,对男女健康差异的扩大有很强的效果,而其他对健康有正向影响的社会经济特征中,有些男性组占优势,有些女性组占优势,所以各分项特征的效应互相抵消了一部分。
从以上第二点和第三点可以看出,我国城镇居民中,男女性健康差异来源主要有两个方面:一是社会经济因素对男女健康的影响机制不同,这一方面对健康性别差异的贡献度达到77.2%;二是男女性别在职业地位上本身的差异,这方面对健康性别差异的贡献度达到33.2%。
本文的局限性在于:第一,社会经济因素变量的选择可能存在遗漏,因此本文关于社会经济因素对健康的影响(即方程(5)中的系数)存在高估,从而导致社会经济因素对健康的影响对健康性别差异的贡献率高估的可能;第二,本文的定量分解结果,是对性别健康差异来源的一个客观描述,能定量发现各部分对健康性别差异的贡献度,但是不能揭示造成这种结构的原因。本文主要价值在于:定量刻画了城镇居民健康性别差异的结构,量化了各部分来源对健康性别差异的贡献率,为进一步探讨形成这种性别健康差异结构的原因奠定了基础;同时,应该从优化社会经济因素对健康的影响机制、缩小男女职业地位差距这些贡献率大的方面入手来进行政策设计,缩小健康的性别差异。
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
小学生学习指导(高年级)(2021年4期)2021-04-29
意林(2021年2期)2021-02-08
妇女生活(2020年2期)2020-03-27
海峡姐妹(2018年1期)2018-04-12
体育时空(2016年9期)2016-11-10
考试周刊(2016年77期)2016-10-09
校园英语·下旬(2016年4期)2016-05-09
新高考·高二数学(2014年7期)2014-09-18
爆笑show(2014年8期)2014-09-04
