
基于云架构的地质测绘管理系统构建
2021-04-02 04:57董晋
粘接 2021年3期
董 晋
(中晋环境科技有限公司,太原 030000)
随着地质测绘工作的开展和深入,对于如何提升测绘工作中的检索效率和对产生的大量数据进行管理,是测绘工作中需要解决的问题。我国常用依托关系型数据库对测绘工作中产生的数据进行管理,再对数据检索系统和管理模块进行构建,进而提高数据的存储。在地质测绘工作中,包括了关系型数据和各类异构数据。对此,传统的测绘数据管理方法在如今的测绘界已不适用。在云计算技术兴起的当下,Hadoop框架不仅能够存储大量数据,也能储存种类不同的数据,因此成为了当前的应用热点。例如潘云(2020)和王永才(2020)会将Hadoop 框架运用与系统构建以及数据挖掘工作中,以此来提升挖掘数据的效率和系统的运行效率。不难看出,Hadoop 技术逐渐受到了人们的关注,因此本文以Hadoop 为前提,提出了基于大数据对地质测绘产生大量数据的存储及管理方案,在该方案的基础上对该系统进行了设计。
1 Hadoop框架
由于地质条件的差异性,造成了地质测绘数据的多样性、异构性、随机性、非线性、相关性等特点。因为地质测绘的数据具有多样性,例如地质元素、构造和地质形成等。因此,从以上分析来看,地质测绘管理系统应当兼具多维度、结构化与非结构化并用等特性。HDFS文件管理系统采用分布式架构设计,能够顺序访问机构化、非结构化数据,对于硬件条件的要求较低;HBase数据库对于硬件条件的要求较高,能够快速随机访问数据。显然,将HDFS 系统与HBase数据库进行结合,则能够更好地实现海量地质测绘数据的存储、访问及管理。对此,本文利用HDFS系统来存储地质测绘数据。其中,当地质数据量过多时可直接存储到HDFS系统,体量较小的地质数据直接经过文件合并再存储到HDFS 系统。利用HBase 数据库来存储地质数据条目的索引信息,从而实现两类文件管理系统的结合。当一个HDFS文件发生变化,与之相对应的HBase索引数据也会同步更新,从而提升数据检索效率。具体架构示意图如图1所示。
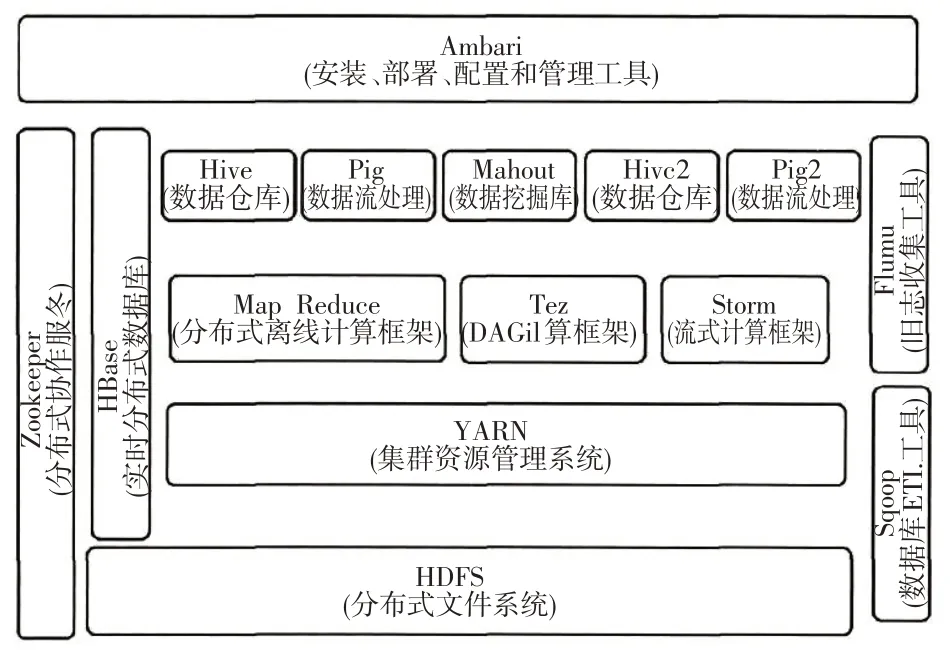
图1 Hadoop系统架构Fig.1 Hadoop system architecture
Hadoop架构的特点有以下3点:
1)分布式文件管理系统HDFS:该系统可部署在普通PC 服务器集群中,内置流式访问接口,嵌入“一次写入、多次读取”的文件访问模型,不仅能够实现可靠的数据存储功能,而且其数据访问速率优于集中式文件管理系统。此外,HDFS 系统的容错能力强,且支持跨平台移植。
2)分布式处理模型MapReduce:该模型集中了Map与Reduce机制,能够将复杂问题简化分解为多个彼此独立的子任务,然后引用计算处理节点对各子任务进行高效处理,整体上保证了对于海量数据的处理功能。此外,MapReduce模型利用数据/代码互定位技术切断了各节点间的联系,从而为单项任务的处理创造了条件;MapReduce模型还为系统开发中的系统层设计提供了技术支持。
3)非关系型数据库HBase:作为一种新型的分布式数据库,HBase可用于存储半结构化、非结构化的松散数据,并且通过主键range实现了快速检索功能,在应用中表现出性能优越、实时读写等优势特征。
2 地质云计算平台技术框架
针对Hadoop 特点和测绘管理系统的业务进行分析,把系统整体架构分成存储层、物理层和数据层等,架构示意图如图2所示。

图2 本系统的Hadoop架构Fig.2 Hadoop architecture of the system
1)物理层。物理层是系统架构的底层硬件资源,除了实现通信、数据传输等功能外,还为上层提供存储、运算资源。
2)存储层及数据层。基于HDFS系统和HBase数据库的数据存储层负责地质测绘数据的存储管理、查询检索,在系统架构下实现了数据输入、云存储、日志记录、数据迁移、安全管理、索引等服务。
3)逻辑层。基于MapReduce模型的逻辑层是Ha-doop系统框架的核心层,在系统框架内充当着数据预处理器、接口分析机、查询引擎等角色,对于系统运行发挥着重要作用。
4)网络及接口层。网络及接口层利用路由选择算法对子网之间的通信进行控制,包括信息传输、数据维护、连接切断等,在系统架构内实现了查询检索、算法接口、空间分析等功能。
5)应用层。应用层位于Hadoop架构的顶端,它直接面向用户,为用户提供数据挖掘、数据分析、数据操作、资源调控等服务,并且对各项服务进行统筹协调,在系统架构内实现了网络、应用程序与用户之间的联结功能。
3 系统设计与实现
3.1 地质数据云存储设计与实现
因为地质测绘数据具有体量大、种类多的特点,本文采用HDFS文件管理系统对数据进行存储。与集中式数据库Oracle作对比,本文选用的HDFS系统将地质数据分散存储于Hadoop集群中,这种独特的存储管理方式有效保障了地质测绘数据的高效处理和安全存储。由于地质测绘文件是由许多个子文件构成的,每一个子文件的体量并不大,若是将这些子文件进行单独存储,必然会大幅度降低数据处理效率,因而需要利用其它方法对小文件进行预处理。对此,本文设计了小文件合并算法,首先对多个小文件进行合并,然后再存储于HDFS中,在MapReduce模型的配合下,能够实现高效的数据处理功能。具体实现如下图所示。
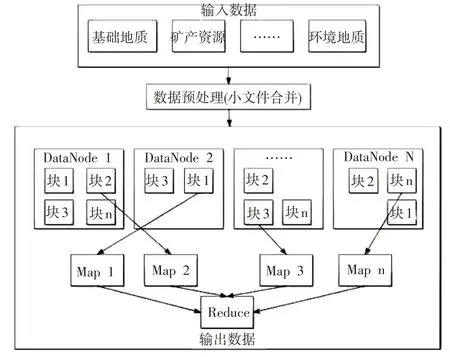
图3 基于HDFS的地质数据云存储Fig.3 Cloud storage of geological data based on HDFS
根据HDFS 的存储特征,结合地质测绘数据的特点,需要对地质测绘小文件进行合并处理,从而更加安全、高效地存储于HDFS 中。HDFS 采用数据块(Block)管理方式,一个Block的体量介于64~128MB之间。如若不对小文件进行合并处理,则一个小文件就会占用一个Block,导致Block数量激增,继而使得Name Node在运算过程中占用大量内存,并且严重拉低Hadoop处理速率。对此,在清理冗余小文件的同时,还需对小文件进行合并处理,从而保持Hadoop集群的高效运行。
3.2 地质数据MapReduce的计算模型设计与实现
MapReduce 并行编程模型按照Key 对海量地质测绘数据进行排序,并从中提取出有价信息,在此基础上对原始数据进行打包处理,并以打包后的SequenceFile 作为基础单位进行并行运算,整体上提升了系统运算效率。具体实现流程如图4所示。
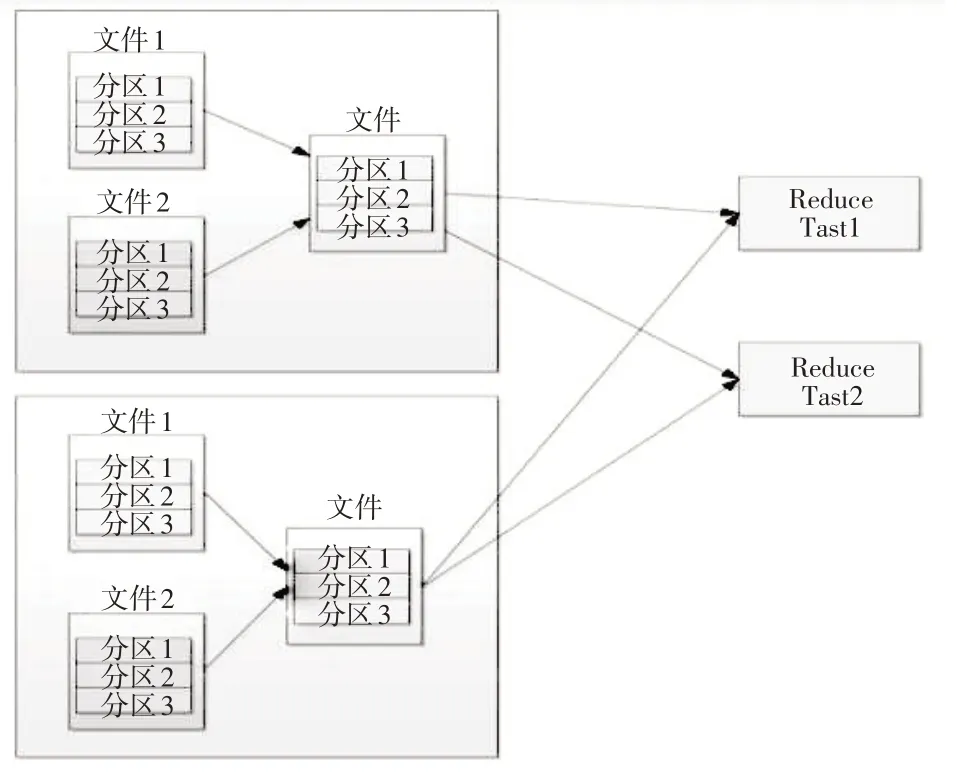
图4 MapReduce模型的工作流程Fig.4 Workflow of MapReduce model
3.3 系统负载平衡设计与实现
在Hadoop集群的运行过程中,总是会持续不断地进行着新建、检索、读取、分析、清除等操作,这使得集群内部不同DataNode上的磁盘空间使用率存在显著差别。在Hadoop集群内部DataNode上的磁盘空间已趋近于饱和的情况下,若是管理员继续增加一批DataNode,这一操作不会影响原有DataNode磁盘使用率,但却会出现新增DataNode 磁盘使用率偏低的问题,从而破坏DataNode吞吐量的负载平衡,并且影响数据I/O的并发运算。因此,有必要引用某种机制来维持集群中DataNode数据的均衡态,避免出现少数DataNode密集承载数据请求的情况,这不仅能够提高用户响应速率,而且能够防范因某一DataNode失效而造成系统宕机的风险,从而有效改善了Hadoop集群性能。
对此,在Hadoop系统中内置了一套基于数据均衡算法的平衡(Balancer)机制,其命令符是Hadoop balanc-er [-threshold<threshold>],据此对各个DataNode进行评估,并且维持DataNode数据处于均衡状态。在以上命令符中,“threshold”指的是平衡阈值,其取值范围是0~100%。在执行Balancer机制时,若设定的threshold值过小,则需要投用更多资源和时间来实现DataNode数据的均衡分布。Balancer机制的实现步骤为:
1) Rebalancing Server 调 用 NameNode 对DataNode数据的分布情况进行评估,并根据评估结果计算出Hadoop 集群的整体空间利用率以及各个DataNode节点上的磁盘利用率。
2)Rebalancing Server 确定待迁移的DataNode 数据,结合threshold值对DataNode进行分类,规划出最佳的Block迁移路线。
3)在遍历各DataNode 结点以后,找寻到适宜进行Block迁移的目标结点,然后开启Block迁移过程。
4)Proxy Source Data Node 复制一块待迁移的Block,然后粘贴至目标DataNode节点。
5)将原始Block清除,避免数据库冗余。
6)目标DataNode节点向Proxy Source Data Node发出迁移任务完结信号。
7)Proxy Source Data Node向Rebalancing Server发出迁移任务完结信号。在完成一轮DataNode数据迁移过程以后,若Hadoop集群仍未达到负载均衡标准,则需要再次执行Balancer机制。根据经验,在进行5轮迭代以后,Hadoop集群通常即可实现负载均衡。
在评价各DataNode节点的负载时,本文选用了带宽利用率NUi、内存利用率MUi、CPU利用率CUi等三个参量,并根据主观经验赋予各项参量以特定的权值,在此基础上求解出Hadoop集群的总负载:X1×CUi+X2×MUi+X3×NUi。需要说明的是,根据主观经验对参量NUi、MUi、CUi进行赋权,这一方法虽然简易但不够严谨,由此所得评估结果也难免与实际情况存在偏差。
针对于此,本文利用信息熵算法来确定各DataNode节点的负载值,该算法以实际负载值作为基础,通过衡量一个随机变量出现的期望值,同时兼顾指标的变异性,最终客观确定权重大小,以上过程摆脱了主观经验的干扰。依据信息熵算法,指标值的变异程度越小,指标信息熵越大,则该指标的作用越小,其所对应的权重越小;反则反之。
设定DataNode 节点i 的虚拟机数量为ni,那么,该节点所对应的三项分量依次是
套用信息熵算法,执行以下运算过程:
1)假定存在n个属性X1、X2……、Xn,构建由它们的属性值构成的决策矩阵P。
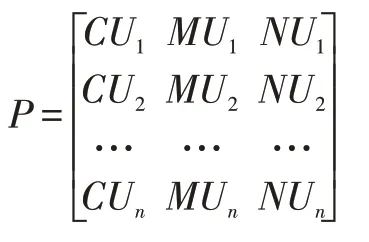
4) 如果(r1j,…rmj)=(1/m,…1/m),那 么Ej=1 ;如果(r1j,…rmj)=( 0,…0,1,0,…),那么Ej=0;
5) 求解出属性Xj对于方案的区分度:Fj=1-Ej,并利用式,j=1,2,3,...,n求解出属性Xj的权值。
6)最后计算节点i的负载:

通过以上流程计算出各个节点的负载值,将负载值最大的节点设定为迁移虚拟机。
4 系统测试
4.1 虚拟机的安装设置
根据VMware 虚拟机的运行要求,用户需要在Windows 10 及以上版本的操作系统中进行安装,然后启用虚拟机workstation,嵌入VMware ESXi,最后在ESXi中部署Linux操作系统虚拟机。根据Hadoop架构的配置要求,Linux 操作系统的版本及配置条件是: Red Hat Linux 2.6.32- 573.el6.x86- 64, Ja-va1.7.0-91,Hadoop2.7.2。
4.2 地质测绘系统测试
为对系统性能进行测试,在eclipse 中编写代码,并对平台上传和下载对应函数的执行时间进行计算。通过前端页面对事件进行上传、下载和记录操作时的起止时间。由此,得到表1 的结果。根据结果看出,当文件大小100M 时,上传速度达到毫秒级;当文件大于500M 时,上传速度在10s 之内;当文件大于1G时,上传时间约60s。当文件大小>2G 时,上传的速度会更慢。由此看出,当文件大小不断增大时,上传文件的速度也会增加。
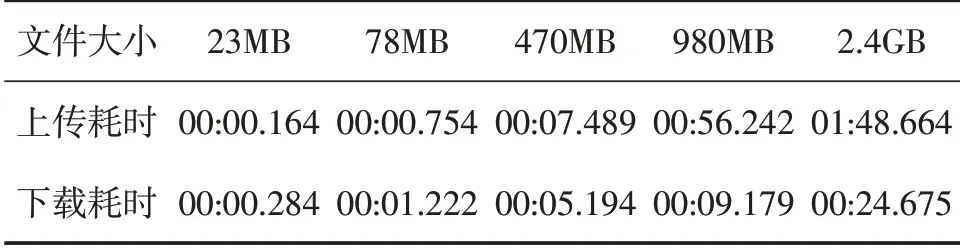
表1 上传与下载文件的耗时Tab.1 Time consumption of uploading and downloading files
在文件下载方面,当文件大小为30M时,下载所需时间为284μs;在文件大小为2.4GB时,下载所需时间为24s659μs。从该测试结果来看,即便是大于2GB的数据,下载所需时间仍可控制在秒级。因此,单个文件的下载所需时间能够满足地质测绘数据下载要求。
5 结语
通过以上研究看出,在Hadoop 集群下,能大量存储海量的地质测绘数据。同时通过Balancer 机制实现了集群负载的平衡,很好的实现了地质测绘系统服务器的均衡。而测试结果也表明,在本服务集群下,本系统下载文件的耗时时间明显较短,由此验证了本系统构建的可行性。而通过以上构建,也为地质测绘数据的存储等提供了新的方式。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
承德医学院学报(2022年2期)2022-05-23
汽车工程(2021年12期)2021-03-08
军事运筹与系统工程(2019年4期)2019-09-11
中国交通信息化(2018年8期)2018-11-09
电子制作(2018年11期)2018-08-04
计算机测量与控制(2017年6期)2017-07-01
中国交通信息化(2017年3期)2017-06-08
中国船检(2017年3期)2017-05-18
知识就是力量(2017年2期)2017-01-21
