
基于深度学习的图像识别算法构建
2021-04-02 04:57魏彬
粘接 2021年3期
魏 彬
(陕西铁路工程职业技术学院,渭南 714000)
0 概述
图像对象的分类和检测是计算机视觉中最基本的两个问题。当前,行业内关于机器学习领域的核心是对象分类及检测,在人脸识别,安全领域的行人检测,智能化视频分析、行人跟踪、对象识别、车辆交通事故现场的交通统计、交通逆行检测、车辆牌照检测识别以及基于内容的图像分析的互联网、相册自动分类等已得到了应用。
基于深度学习的图像识别技术已经应用到人们日常生活的各个方面,而图像识别中的核心手段为分类与识别,集成深度学习等机器学习技术,提升了图像分类及识别的效率。在文献[1]中,Soheil等人提出了多模式任务驱动的字典学习图像分类算法,该算法通过以字典原子的稀疏线性组合作为输入信号,已经成功地用于重新构建和鉴别性的任务;虽然该方法大多是针对单模态场景而开发的,但最近的研究已经证明了基于多模态输入的联合稀疏表示的特征级融合的优点。R Ji[2]的研究团队提出了一种新的基于光谱空间约束的高光谱图像分类方法,主要用于处理像素谱和空间约束的关系。文献[3]中,作者对腹侧视觉流的前馈层次模型进行了研究,主要应用于功能脑图像的分类。
关于图像对象分类以及识别问题的研究主要分为三个层次:实例级、类级和语义级。①实例级:由于图像特征中的光照、拍摄角度、拍摄距离、拍摄对象本身所具备其它特征,造成在对象识别过程中产生较大的变化,视觉识别算法的执行存在较大的困难;②类级别:困难和挑战往往来自于三个方面,第一个是课堂上的差异,即同一类型对象显著特征有较大的差异,同时在实例级中提到的各种动态变化和背景干扰,但在实际的拍摄过程中,摄影对象是不可能处于静态环境,因此由于复杂的识别环境造成难以识别的问题;③语义层面:与视觉语义相关的图像,难度水平通常很难处理,尤其对于当前的计算机视觉技术,面临最大的问题是解决多重稳定性特征。因此,为了解决上述缺陷和不足,本文提出了一种新的基于图像多特征提取和改进的SVM(Support vector machine,SVM)图像识别算法,并对其进行了理论分析和数值分析[4-7]。
1 图像特征提取技术及方法
针对图像多特征的特性,单一特征只能描述图像的部分属性,因此只能片面的描述图像,缺乏足够的特征信息来区分图像。本文所提出的综合特征提取方法,第一步是对图像的基本特征进行目标分类和框架检测,包含两个办法,一种是基于兴趣点检测,另一种是集中提取。兴趣点检测实现过程是定制相关检测标准,如以具有明显特征的局部纹理像素—边、角、块等;然而近年来使用较多的对象分类领域是集中提取方法,主要从图像的固定步长、规模、大局部特征的数量等方面,大量的局部描述虽然具有更高的冗余度,但更丰富的信息相比兴趣点检测更好的性能。
业内核心的图像分类算法是综合了多种特征、提取办法和兴趣点检测相融合,这种处理方式是通过对大量冗余特征进行处理完成特征提取,提升了有用信息的利用。事实上,今年来广泛使用的图像识别方法(深度学习)的核心问题是视觉信息处理过程中综合特征集的设计,综合特征集的合并可以参考以下方程:
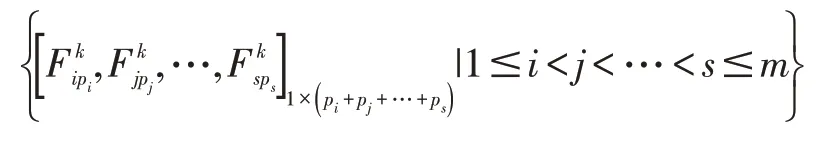
对于图像集中提取的特征中包含了大量的冗余和噪声,因此为了实现图像特征表达的鲁棒性,业界利用特征变换算法对底层进行编码设计,实现图像特征更健壮及区别性特征的表达,许多研究工作都集中在寻找更强大的特征编码方法。矢量量化编码通过一个小的特征集来描述底层的特征,局部特征在实际图像中往往具有一定的模糊性,下面的公式给出了正弦变换的过程。
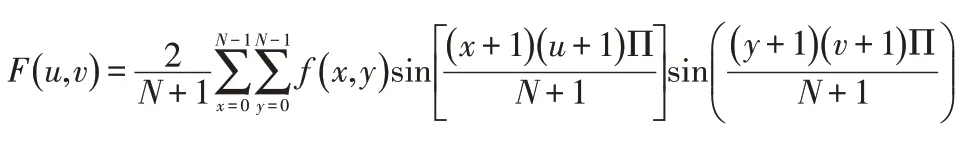
对于一个大型的特性集,相关联的对象通常只有一些功能,例如,自行车的核心特征部分,如车轮、车把和视觉特征是密切相关的。稀疏编码后的局部特征可能会以不同的视觉语言做出回应,而不连续性的转换造成编码特征的不匹配,对最终的图像识别率有较大影响。为了解决这个问题,本文结合PCNN技术来获得更高的精度,PCNN 的结构是二维的神经元,每个神经元都与图像中对应的像素相连接。在如下公式中描述了神经元与图像特征的连接表述。
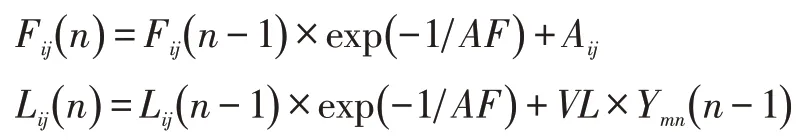
在局部流形上编码重构的基本特征,既解决了编码不连续性特征的问题,也不会保持稀疏矩阵的特点。在编码中约束的局部特性,原理上提升额字符编码过程问题的连续性,如图1所示为PCNN模型流程图。
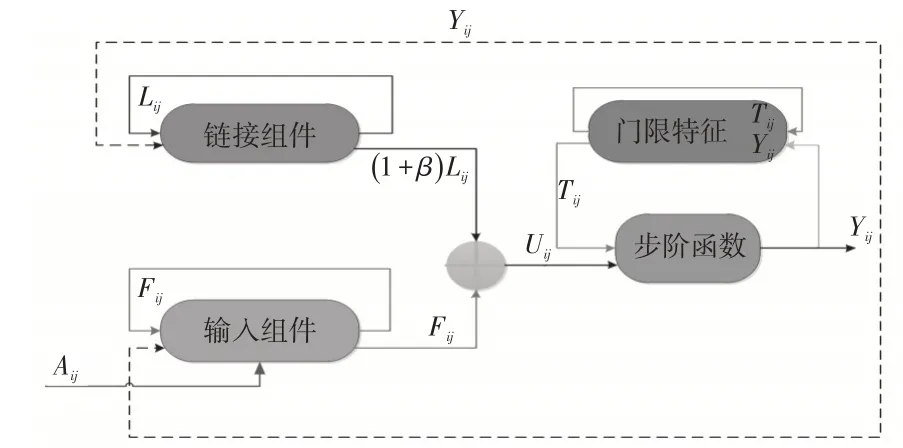
图1 PCNN的基本模型Fig.1 PCNN basic model
与传统的基于重构的特征编码方法不同,Fisher矢量编码同时结合了生产模型和判别式模型的能力,记录了局部特征和视觉词的差异及二阶之间的区别。空间特征组合在集成操作的特征集合中,通过编码的特征,可分析得出特征向量的表达式。在绝大多数收敛性能的情况下最大聚集比一般的好,也是分类中使用最广泛的。不再使用视觉词汇来描述局部特征,而是用一个加权、有效地解决视觉词歧义问题,提高物体识别精度的方法来描述。稀疏编码的最小平方重构,在一个完整的过程中通过加入稀疏约束完成稀疏性反应的实施。一般来说,利用对象分类算法按照手工特征或全局特征进行图像整体描述,然后通过分类器识别是否有某个对象,对象的检测任务比较复杂如下公式描述该特征,如图2所示为特征提取的过程描述[8-9]。
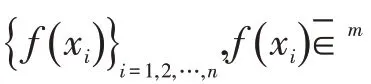
图2 特征提取过程Fig.2 Feature extraction process
2 图像识别算法
2.1 SVM和深度学习模型的概述
传统的分类算法是采用SVM 进行分类,通过图像特征提取到特征表达式形成后,形成固定维度 向量,随后是完成对图像的分类。分类器包含支持向量机(SVM)、k-邻居、神经网络、随机森林等,SVM主要在图像分类实现中使用,通过研究一个完整的稀疏特征,可以在高维特征空间中利用线性支持向量机(SVM)来提高线性分离特征。随着对象分类研究的深入,视觉词汇量的增加,图像的表达维度也在增加,这样的高维数据,与数以万计的数据样本相比,与传统的模式分类问题有很大的不同。
为了保持数据中最重要的数据,需要设置隐藏层单元数量小于数据输入的维度,实现数据维度的减少和特征编码。首先从对可见层的原始输入开始,训练一个单一的物质,然后将物质重量的第一层固定作为一个新的可视层。通过贪婪的无监督训练,可使整个DBN 模型[10-11]获得一个更好的初始值,然后通过生产或判别方法添加标签信息,对整个网络监管进行微调,进一步提高网络性能。
2.2 算法模型
相关研究证明,在以信息量作为基本变量前提下,采用多分类机器学习算法比单分类机器学习算法的泛化能力更优。虽然该算法具有较好的泛化能力,但通常包含大量冗余信息,极大得降低了泛化学习能力的效率。此外,许多特征组合将导致更高维度,而特征维度的上升将导致SVM 训练和测试被占用的时间增长。因此,在使用图像分类算法时,需要减少提取特征的维数,去掉特征中的冗余信息。
图3 所提方法的流程图Fig.3 Flow chart of the proposed method
在词包模型设计过程中,利用神经网络的卷积层设计原理,实现特征编码及运算的收敛层和词包模型的收敛性,两者的区别在于词包模型中只包含一个有效地卷积模型和收敛层,并用表达式的形式使用无监督学习特征的模型和卷积神经网络模型实现特征表达效果的提升。欧氏距离最小的表达式如下:

从模型设计角度考虑,图像对象检测的核心是采用组件模型的变量,对象分类模型主要采用实词包模型,不同模型使用特征信息是不同的,图像对象检测更多是利用自身特征信息来完成对象分类。局部信息的对象考虑更多的结构信息,使对象检测和分类精度较高,但在分类过程中鲁棒性较差;全局特征信息可考虑图像的全局信息,特别是图像的语义信息,但是信息量的增加可能导致精度的提高,也可能是由于冗余降低了分类的性能,但从统计意义上来说,它的健壮性可以得到提高,以下公式为该模型的公式化表述。
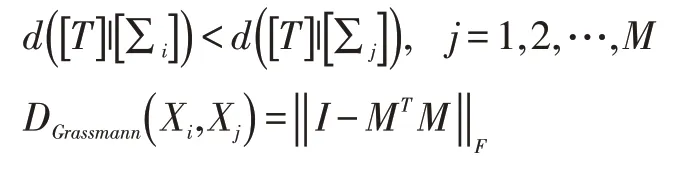
对象分类的目的是检测是否包含所需特征的图像;对象检测的目的是根据特征确定图像中对象的位置,因此对象结构更是至关重要。在大数据时代,来自复杂变异性的海量视频数据将对传统学习方法的特点带来巨大挑战;而对模型表达能力的深度学习,强烈的自然数据无疑会对大数据在视觉研究的背景下产生巨大的影响。
3 仿真实验
3.1 实验设置
为了验证本文算法的有效性,在Windows 平台上,选择了Laplacian priori Matlab 2011b 环境模型、电视先验模型和GMRF 先验模型,与算法进行了比较,实验环境设置如表1所示:

表1 实验环境设置表Tab.1 Experimental environment setting table
3.2 实验结果

图5 实验结果Fig.5 Experimental results
如图5所示为按照所设置的实验环境进行分类的结果图。针对目前的图像分类方法,未能充分利用各种单一特征图像在互补性特征与大量冗余信息的存在中提取特征之间,造成图像分类精度不高。
4 结语
图像对象的分类和检测是计算机视觉中最基本的两个问题,目前已应用了许多领域,如行为检测、人脸识别、视频图像分析、智能交通等。机器识别的研究对于对象分类及检测具有理论意义和应用价值,因此,文章讨论了对象分类与识别的相关联系,并在此基础上对两种方向的学习和结构进行了深度学习。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
意林(2018年3期)2018-03-02
