
基于正交层次分析法的质检数据语音识别效率改善方法研究
2021-04-01 07:41:20杨静萍王万雷
大连民族大学学报 2021年1期
张 伊,杨静萍,王万雷
(大连民族大学 机电工程学院,辽宁 大连 116605)
1 研究背景
2017年,秦楚雄和张连海针对低资源训练数据下DNN特征建模识别性能不佳的问题,提出了一种提取新的基于DNN特征的方法,使其相对于HMM模型识别率提升了0.8%~3.4%[8]。但是仅使用DNN模型可能存在记忆断层及噪声环境下性能不稳定的问题,2018年Mohit Dua等提出一种利用差分进化(DE)算法优化MFCC、GFCC和BFCC技术中滤波器数目和间距的新方法,该方法在噪声环境下识别效率得到有效提高[9]。2019年,李婉玲和张秋菊为提高语音识别的鲁棒性,提出一种基于HMM/SVM的抗噪语音特征提取及优化组合方法,实验表明该方法的系统识别率达到95.25%,提高了系统的识别效率和分类决策力[10]。邓引引为解决浮点语音数据运算效率低的问题,对CNN模型进行优化,提出一种改进的卷积运算方法,优化后中文CNN声学模型的语音识别系统平均识别效率相对提升77.58%[11]。2020年Toktam Zoughi等又进一步降低了识别错误率,提出利用自适应窗口卷积神经网络(AWCNN)分析联合时间-光谱特征的变化和一种新的残差学习方法,在某些语音识别任务中比现有方法的绝对错误率降低了7%[12]。
在上述方法中,语言模型和声学模型优化方法能够有效提升语音识别效率。然而,由于需要建立相关模型及训练数据集,该方法的工程量大且耗时长。在工业领域中,对语音识别的准确率和安全性要求较高[13]。在确定语音识别率的情况下,质检数据语音识别效率还有改善的空间。语音识别在实际应用中主观性占比较大,存在用户发音有要求及使用流程和过程中出现输入错误怎样改正等问题。本研究提出一种基于正交层次分析法的质检数据语音识别效率改善方法,该方法不需要提高语音识别准确率及降低噪音影响,而是采用试验统计方法快速计算和完成评价,有效提升了语音识别的效率,缩减了质检人员录入电子文本的时间,提高了质检人员的工作效率。
2 正交层次分析语音识别效率评价模型
正交试验设计依据数理统计原理,科学地挑选试验条件,合理减少试验次数并获取有效的实验数据,提高了试验的效率[14]。层次分析法(Analytic Hierarchy Process,AHP)是一种定性与定量分析相结合的多准则决策方法,基本思想是在对复杂决策问题的本质、影响因素及内在关系进行深入分析后,构建一个层次结构模型,利用较少的定量信息,将人的思维过程层次化、数学化,为求解多目标、多准则或无结构特性的复杂决策问题提供一种简便的决策方法[15]。
根据郭穗勋、黄榕波提出的正交试验数据分析的新方法——正交试验层次分析法[16],为分析输入指令方式、录入人员普通话等级和改正输入错误方式对质检数据语音识别效率的影响,并找到质检数据语音识别更高效的方法,设计了正交实验(测试环境:噪音45~60分贝,没有多余外界因素干扰),因子水平设计见表1。

表1 因子水平设计
正交实验和层次分析法相结合,其模型的逻辑结构框图如图1。第1层为试验考核指标层,第2层为因素层,第3层为水平层。

图1 模型逻辑结构框图
计算相应矩阵,进而得出影响权重,评估各因素对强度的影响程度,验证正交试验直观分析的结论[17]。试验指标是时间,越小越好,则令Mij=1/Kij(i=1,2,…,n;j=1,2,…,m),其中Kij为因子Bi的第j水平下实验数据之和,水平层对实验影响效应矩阵:
(1)
对矩阵A的每一列进行归一化,右乘矩阵S,矩阵S如式(2)。
(2)
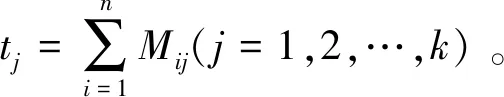
毛泽东同志曾指出:“科学研究的区分,就是根据科学对象所具有的特殊的矛盾性。因此,对于某一现象的领域所特有的某一种矛盾的研究,就构成某一门科学的对象。” 我认为同其他应用经济学科一样,中国特色贸易经济学是有自己特定研究学科对象和研究内容的,并可以与相关的经济学严格区分开来。
(3)
由式(1)、(2)和(3)可以得到各因子对语音识别效率的影响权重大小:ω=ASCT。
3 语音识别效率对比实验
效率最直观的检测方式就是时间与工作量的比值,在同一时内,完成的工作量越多效率越高;在同样的工作任务下,完成全部工作用时越短则效率越高。
3.1 语音识别效率评价模型
本试验共涉及三因子二水平,选用L8(2^3)正交表,正交实验直观分析见表2,其中T为单次输入所用时长。

表2 正交试验直观分析表
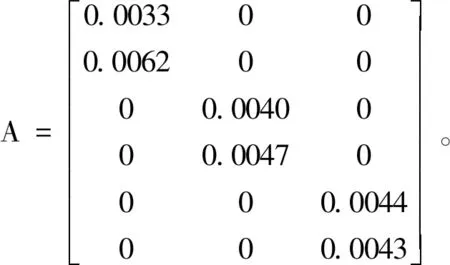
根据式(1),M11=0.0033,M21=0.0062,M12=0.0040,M22=0.0047,M13=0.0044,M23=0.0043,则
(4)
因为式(2)即1/t1=118.09,1/t2=117.27,1/t3=115.27,

(5)
又因为式(3),式中R1为139.212,R2为38.095,R3为7.715,则
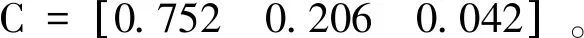
(6)
由式(4)、(5)和(6)可以得到各因子对语音输入效率的影响权重如式(7):

(7)
因子B1中对指标权重影响最大的是B12,因子B2中对指标权重影响最大的是B22,因子B3中对指标权重影响最大的是B31,故试验最优条件为B12B22B31,各因子影响排序B1>B2>B3,与直观分析法结果一致。质检数据语音识别高效的模型:录入人员普通话等级在二级乙等及以上,通过光标指示并在输入过程中及时改正错误。
3.2 语音识别对比实验
语音识别实验由语音输入检测原型系统和相关硬件设备组成。语音输入原型系统基于语音输入软件开发工具,结合语音输入流程设计Android录入系统。硬件系统包括计算机(用于数据存储、系统设定)、平板电脑或手机(用于语音输入原型系统客户端的运行)和蓝牙耳麦(语音数据采集)。语音识别实验流程如图2。

图2 语音识别实验流程图
分别进行效率改善前的语音识别实验和正交层次分析法得出的模型语音识别实验,每个实验分成5组,每组50次,5组数据对比,选择每组最优的数据进行记录。
3.3 实验结果分析
上述语音识别输入实验和语音模型识别输入实验最优数据结果见表3。
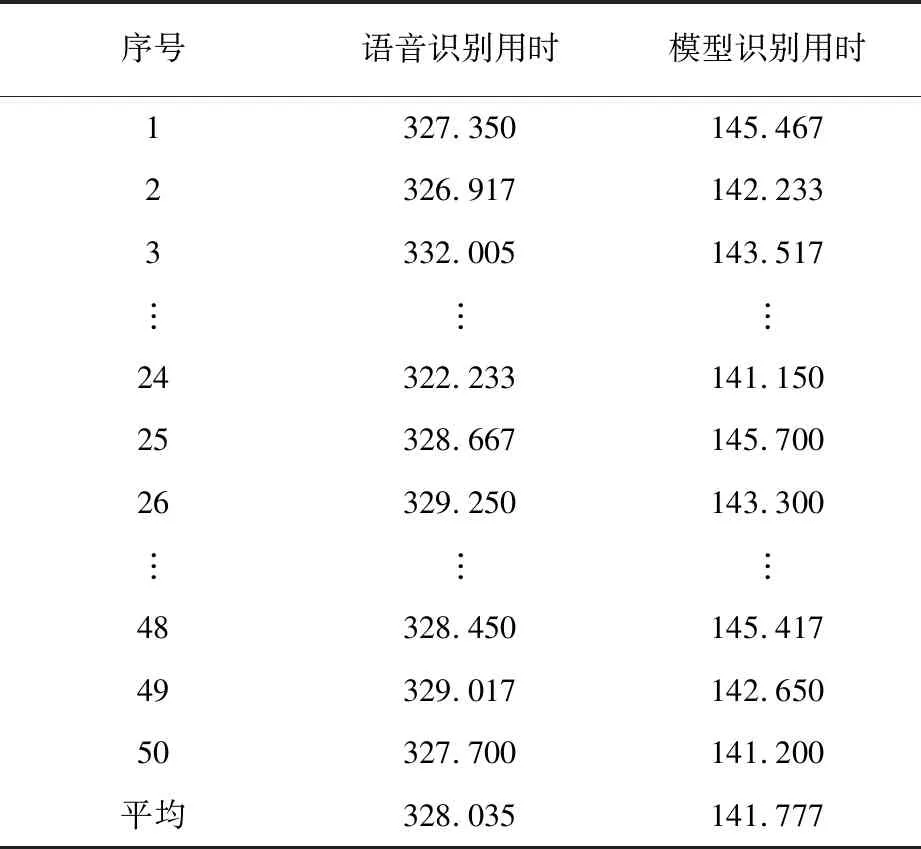
表3 实验最优数据结果 /s
将以上实验数据通过图像的形式直观展现,语音识别输入最优数据组汇总报告如图3。
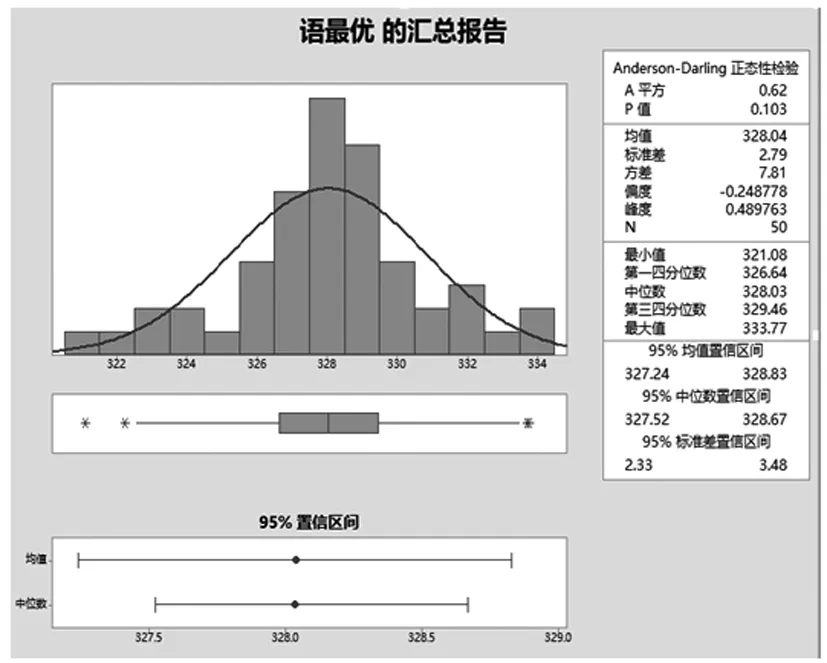
图3 语音识别输入最优数据组汇总报告
模型识别输入最优数据组汇总报告如图4。
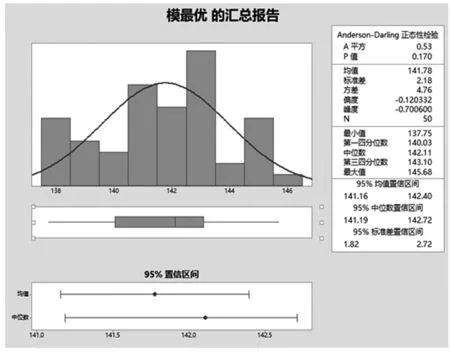
图4 模型识别输入最优数据组汇总报告
通过实验数据结果显示,语音识别输入时间均值为328.04 s,标准差2.79,最大值为333.77 s,最小值为321.08 s;模型识别输入时间均值为141.78 s,标准差为2.18,最大值为145.68 s,最小值为137.75 s。模型输入质检数据的方式用时较语音输入质检数据的方式少,且时间波动幅度也较小,使用语音模型可提升45.29%语音识别的效率。
4 结 语
本文提出一种基于正交层次分析法确定语音识别效率的评价与改善方法,首先确定输入指令方式是影响质检数据语音识别效率的主要因素,录入人员普通话等级是次要因素,而改正输入错误方式对效率也有一定影响。通过正交层次分析法对比实验最终确定录入人员普通话等级在二级乙等及以上,通过光标指示并在输入过程中及时改正错误的方式为质检数据语音识别效率最优方式。该方法在保证现有语音识别准确率的前提下对语音识别的效率提高具有一定作用,实验结果表明模型有效。
猜你喜欢
防爆电机(2022年4期)2022-08-17 05:59:06
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
传媒评论(2018年6期)2018-08-29 01:14:36
传媒评论(2018年6期)2018-08-29 01:14:36
电子测试(2018年11期)2018-06-26 05:56:14
中国交通信息化(2017年9期)2017-06-06 07:14:54
项目管理技术(2016年8期)2016-05-17 05:39:14
