
基于Spark内存算法的图书馆大数据文献服务方案研究
2021-03-31 08:56王海萍
微型电脑应用 2021年3期
王海萍
(西安理工大学 图书馆, 陕西 西安 710054)
0 引言
随着大数据时代背景下,图书馆馆藏所占用的信息量暴涨,其具有总量大、种类多和高价值的特点[1-2]。在海量的数据文献与有限的计算机处理能力中如何找到平衡,研究设计出可行的文献检索服务方案,具有十分重要的意义。目前,国内外关于图书馆文献检索信息化的实践研究主要体现在3个方面:首先,对于多种文献来源的收集和分类检索,大数据时代下文献资源较传统的图书资源信息量更为复杂,如何挖掘并进行有效聚合是研究热点,例如部分学者以深度聚合可视化模型为出发点,建立了基于数据资源收集、信息处理、资源整合和可视化的图书馆馆藏数据系统[3-4];其次,文献大数据的分析方法研究,支持向量机方法、多维检索排序方法和文献活跃度方法等均是在这一背景下所提出的数据分析法[5-8];最后,图书馆文献管理系统的性能和用户友好程度,这一领域的研究成果较多,结合最新的操作系统界面以及云存储等方法,Hadoop云平台、Worldcat数据库和虚拟现实技术等均有所应用[9-11]。以上3种研究方向均在图书馆文献检索方面做出了巨大贡献,但是随着大数据和5G时代的到来更加海量的文献数据对于现有的检索服务方案提出了新的挑战。
目前较为主流的大数据分析技术以内存计算为主,其中Spark平台作为内存计算的主要框架,在互联网娱乐、游戏和网络电商平台获得了十分成功的应用[12]。Spark框架内的弹性分布数据机制具有较高的容错能力,并且具备高效的机器学习库,能够对海量数据以及图形的节点进行分析研究。最为重要的是,Spark框架采用分布式集群计算法,对计算机硬件的依赖性小,能够有效降低硬件成本。因此,本文提出基于Spark框架下的图书馆文献检索服务方案,希望能够在充分利用有限计算资源的前提下,满足大数据高强度计算检索服务。
1 系统架构设计
基于Spark架构进行图书馆文献服务方案设计,本文采用3层,分别为文献服务平台设计、文献数据分析设计和文献数据聚合设计。其基本结构,如图1所示。

图1 Spark架构下图书馆文献系统设计结构
1.1 文献服务平台设计
文献服务平台通过Web形式给用户提供互联网在线服务,采用了Web显示系统技术和网络可视化技术。主要实现文献检索、文献推荐和文献可视化3个功能。例如,用户在网络搜索框输入想要检索的目标词汇,搜索引擎会触发实体或属性检索算法,根据Spark RDD线索寻找出相关性靠前的资源并自动排序。然后,可视化模块将排序的文献内容展示在Web网页上,脉络清晰,通熟易懂。
1.2 文献数据分析设计
目前的云数据模式存储的数据具有价值高、密度低的特征,对于数据分析和挖掘能力要求高[13-15]。本文采用Spark框架下的Lib和Graph函数库实现对数据的挖掘和智能化分析,该分析方式可以智能挖掘用户偏好,将用户比较感兴趣的文献排名靠前。
1.3 文献数据聚合设计
文献数据聚合是数据资源整合的基础功能,是将本体与关联数据融合并以一种相互关系进行规范化属于表达来实现[16]。在本文的聚合设计中,利用Map和Join函数对元数据进行资源整合,将馆藏数据、互联网文献库和纸质化信息进行合理整合并联。
2 基于Spark的检索算法优化
根据图书馆目前的检索使用情况,本文研究实现的算法基于读者使用习惯,包含用户-用户协同过滤、用户-图书书名推荐等混合搜索策略,每个策略分配一定权重系数,通过优化调整排序方式,最后获得近似值,在实际使用中根据用户的操作习惯动态调整权重系数的大小,最终提高了图书文献的检索效率。由于篇幅有限,因此本文仅就用户-用户协同过滤检索方法的实现原理。
分析图书馆用户的使用习惯发现,当用户a在进行检索时,一方面可以通过该用户之前借阅或者浏览过的图书信息来进行推荐;另外,还可以寻找与用户a具有类似阅读习惯的其他用户的借阅历史进行推荐。这种基于用户-用户推荐的算法能够快速让借阅者检索到自己想要的图书。这一算法包含的步骤如下:首先,分析计算出与用户a具有相似阅读习惯的用户列表;其次,将其他用户借阅过的文献信息按一定权重进行排序后推荐给用户a。具体操作,如式(1)。
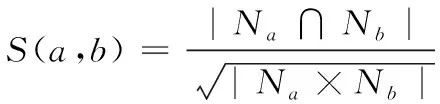
(1)
式中,S表示两个用户a和b检索相似度,无量纲常数;Na表示读者a的检索列表;Nb表示读者b的检索列表。实际运算过程中通过构建一个相似度矩阵,根据用户a的检索行为,读者b的检索行为以及另外两个用户c和d的检索行为,就可以建立一个4*4的矩阵。本文所研究的图书馆若有n个用户,那么就会建立一个n阶矩阵进行运算,如图2所示。
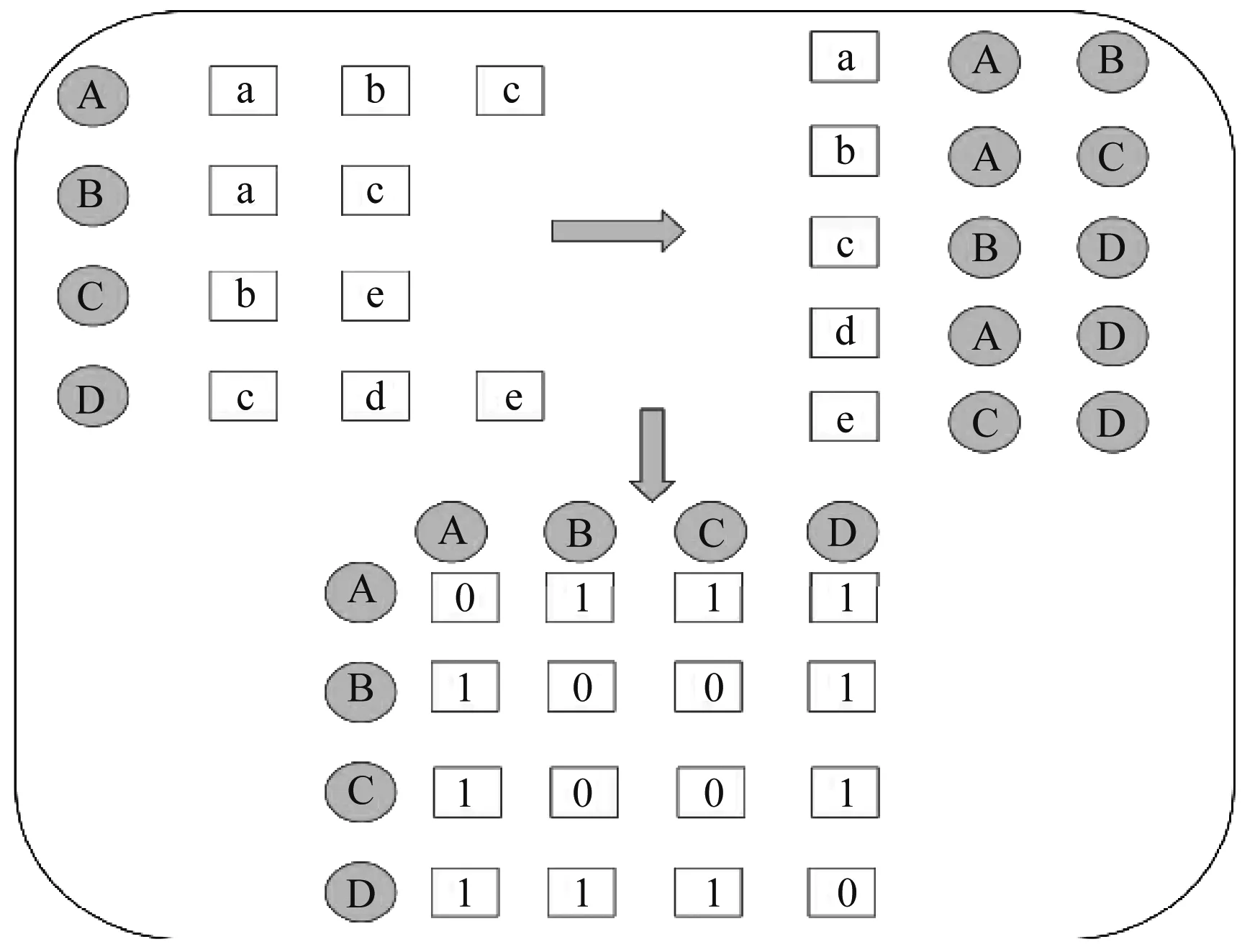
图2 基于用户-用户检索算法的矩阵排列方式
由于在实际检索过程中,若用户a和用户b均借阅过同一本大学通用的教科书,这种情况下并能体现用户对这类文献感兴趣,这是由于客观条件下大学所有学生均需要学习这本书籍。因此,本文在原有的相似度算法上增加一个惩罚系数,用于排除这类型通用的检索结果,改进的相似度计算,如式(2)。
(2)
式中,log(1+1/Ni)表示惩罚系数;Ni表示用户的检索习惯列表。借阅次数越高代表用户借阅该文献的Ni值越高,说明该文献是教科书类普适性图书的可能性越高,因此去惩罚系数越低,在检索中将其排名靠后。改进后的检索算法流程,如图3所示。

图3 改进的用户-用户协同检索算法流程图
针对加入惩罚系数后的检索和剔除过程,本文的处理方法,如图4所示。
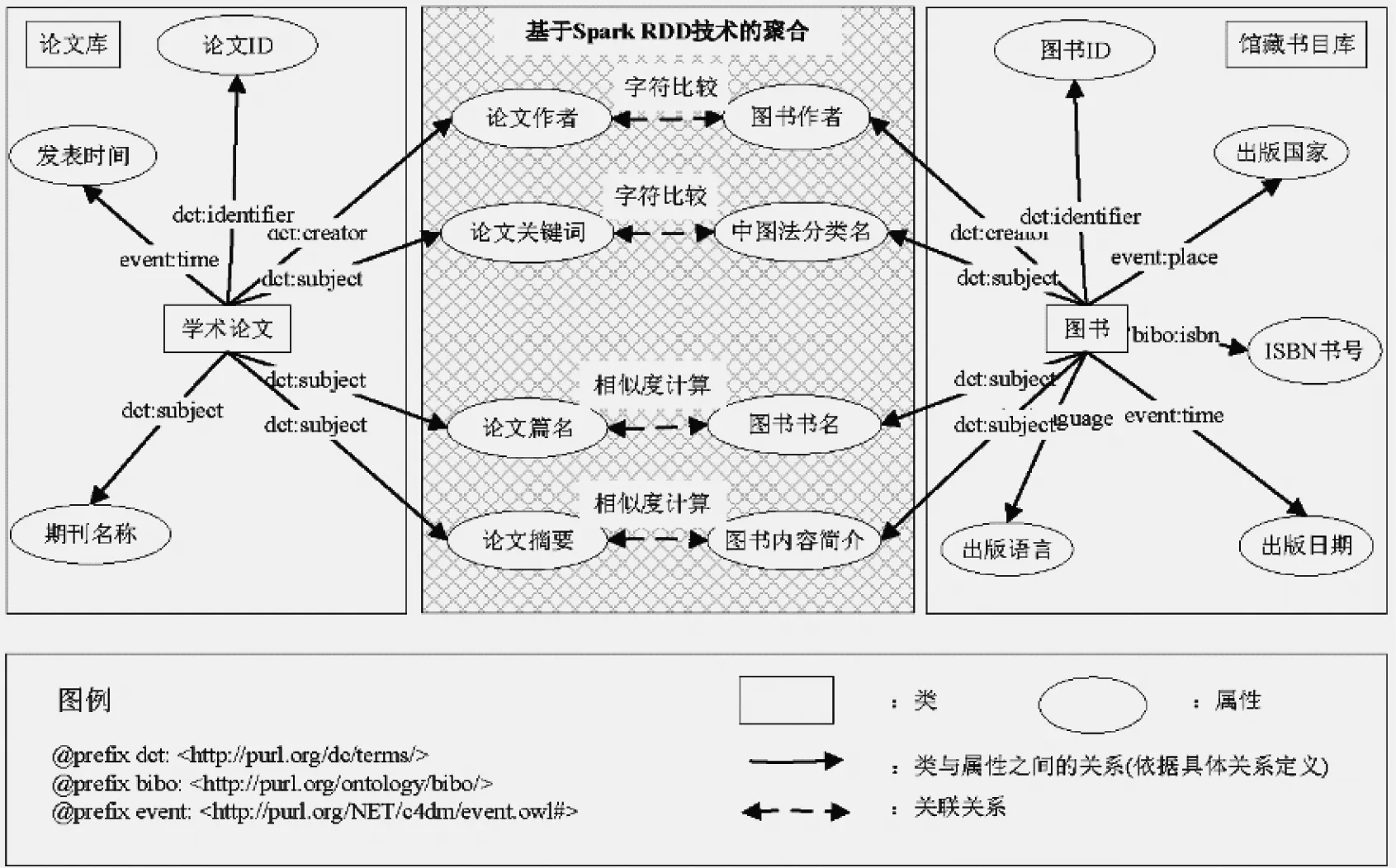
图4 检索过程中的内存信息分类和检索流程
对于如何准确从用户所生成的标签集合中提取出用户特征,本文通过将用户的当前浏览记录或者用户感兴趣的记录进行排名,作为分布式共享内存进行Spark GraphX内存计算,实现图、节点和边处理的计算优化。主要按以下过程进行实现,首先生产Graph并形成空图表,然后将文献进行聚合转为节点和边,并记录权重初始值的W值,最后按照节点的权重值进行由大到小的排序进而获取检索结果。
3 检索效果对比与分析
为了验证改进的Spark内存计算图书馆检索服务效果,本文选取图书馆从2015—2019年共5年的用户图书文献检索数据进行反演和分析。其中图书馆使用用户约为50 000人;文献数据共计285 000条;文献借阅记录约为1 304 000条。对于文献检索的标准根据准确率和召回率来判定,其中准确率计算标准为R1/(R1+R2),R1表示用户感兴趣并推荐的文献;R2表示用户不感兴趣但是被推荐的文献,回测过程中计算用户在不同文献数量下的准确率,然后选取50位作者计算器平均值;召回率计算标准为R1/(R1+R3),R3表示用户感兴趣但是没有推荐的文献,召回率的回测过程与准确率一致。
将基于内存计算方法的图书馆内存检索成果与传统的内存检索结果进行对比,如表1所示。
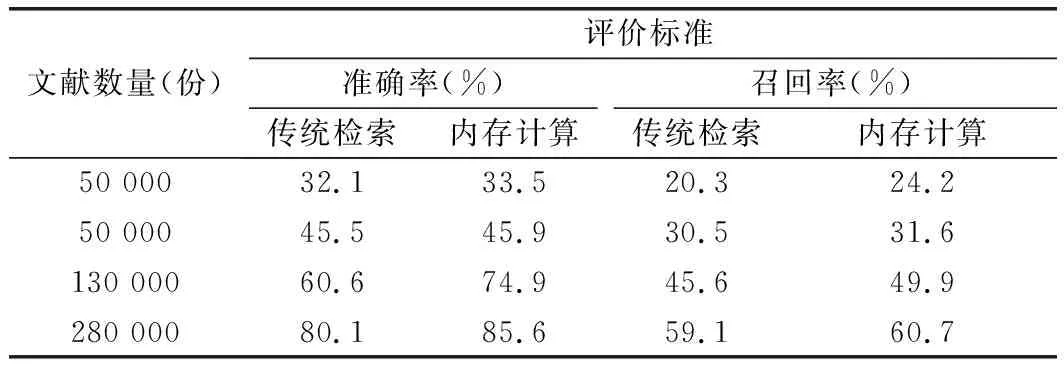
表1 基于内存计算方法的文献检索准确率与召回率成果对比
两种不同检索方式的运行时间,如图5所示。

图5 两种检索方式的运行时间对比
从表1可以看出:在文献数量为50 000份以内时,基于内存计算的检索方式与传统的图书馆文献检索系统其检索准确率和召回率分别为45.9%、31.6%和45.5%、30.5%,说明在文献数量较低的情况下,两种检索方式的精确程度相差不大,但是,在运行时间上,基于Spark内存计算方式的检索系统仅需要15 s,而传统检索需要28 s,效率提升约一倍。当回测文献数量超过50 000份之后,Spark内存计算框架系统的准确率74.9%-85.6%;召回率49.9%-60.7%;传统检索系统的准确率为60.6%-80.1%,召回率45.6%-59.1%,整体上前者较传统检索系统在准确率上提升约14.3%,召回率上提升10.5%,同时,在运行时间上,Spark内存计算检索方式仅仅需要35s,较之前缩短时间约30%。
4 总结
为进一步优化目前图书馆在处理海量文献数据检索的效率和准确率,本文提出基于Spark平台的内存计算方法,对图书馆检索方式进行了进一步优化处理,并将其与传统的检索方式进行了对比分析,结论如下。
(1) 基于内存计算框架的文献检索系统能够将运算中间结果保存在计算机内部存储器中,解决了传统检索方式中大数据反复在硬盘和内存中的交换导致效率低下问题。但是增长迅速和大数据的特征对于系统平台的应急要求较高,国内部分高校图书馆资金有限,其代价是需要过多购置昂贵的高性能服务器等计算机设备。
(2) 基于优化的用户-用户协同过滤算法,加入惩罚系数,可以有效去除用户在检索过程中最为热门的通用教材,在文献推荐方面准确率进一步提高。
(3) 文献数量在50 000份以内时,内存计算方式运算速度较传统方式能够提升一倍,但是检索准确率和召回率基本一致;当文献数量超过50 000份到280 000份时,内存计算检索方法在准确率上提升约14.3%,召回率上提升10.5%,同时在运行时间上较之前缩短约30%。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国交通信息化(2018年5期)2018-08-21
专利代理(2016年1期)2016-05-17
电脑爱好者(2015年21期)2015-09-10
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
