
基于距离度量学习的SAR图像识别方法
2021-03-31 10:28:42高飞赵洁琼林翀陈浩然
北京理工大学学报 2021年3期
高飞, 赵洁琼, 林翀, 陈浩然
(北京理工大学 信息与电子学院,北京 100081)
合成孔径雷达(synthetic aperture radar,SAR)是一种能构建接近光学成像传感器高分辨率图像的相干成像雷达,已广泛应用于国防军事、遥感探测等多个领域.军事领域中,经常利用SAR图像对特定军事目标进行探测和识别[1].由于SAR图像在成像原理、辐射特征、几何特征等方面不同于一般光学图像,在其成像过程中会受到地物回波信号的随机影响,产生的相干斑噪声直接降低图像质量,且由于雷达波反射的不均匀造成图像分辨率下降、目标边缘模糊[2]等问题.与此同时,在SAR图像识别领域,由于目标探测手段上的困难,通常难以获取足够数量的SAR图像样本,进而给图像识别带来挑战.基于上述特点,对SAR图像目标识别的研究主要包括特征提取和分类设计[3-4].传统目标识别方法中一般根据图像纹理特征,使用支持向量机(support vector machines,SVM)的方法对图像进行分类[5],或使用改进的决策树进行SAR图像分类[6]等.Gupta等[7]使用随机森林法融合了SAR图像的纹理特征、SAR观测特征、统计特征和颜色特征进行土地覆盖分类.以上方法依赖于人为设计图像特征,该过程易受图像噪声、方位角等多种因素影响,且在处理不同类别间图像相似度高的任务中,传统识别方法无法准确识别各类图像.基于KNN的合成孔径雷达目标识别中[8]将非参数分类的KNN算法应用于SAR目标识别,此类方法在样本不平衡时易将容量小的样本归类到容量大的样本中.深度学习方法[9]可实现特征的自动提取,通过网络结构的非线性变换实现复杂函数的逼近,在图像识别领域显示出其优越的性能.目前基于卷积神经网络(convolutional neural network,CNN)的SAR目标识别[10]通过搭建包含若干卷积层与池化层的网络,以及使用反向传播优化网络参数,完成特征的自动提取,最后输出分类结果.然而深度学习的训练需要大量的样本数据,由于 SAR图像样本数量的不足,使用神经网络容易出现过拟合和陷入局部最优的情况,降低识别准确率.而近年来小样本学习的提出[11]在一定程度上改善了深度学习面临的问题,其目的是在只有少量样本的情况下,对已有样本进行特定训练,从而进行快速学习,提高泛化性能,但该领域的发展还不够成熟.
针对上述问题,本文从以下两点出发,提出基于距离度量学习的SAR图像识别方法:(1)为区分相似度高的类间图像,利用CNN网络初步提取图像特征,同时使用LSTM网络保留样本间的相似特征,将各类样本进行关联,使用距离度量函数计算图像之间的匹配度,并引入注意力机制以提取出与测试图像特征更具相似性的训练图像;(2)在SAR图像数据样本有限的情况下,结合小样本学习中数据训练方式,对训练集按比例划分,采取预训练的策略进行模型训练.
1 基于度量学习的算法原理
1.1 分类模型
训练集S中包含N个类别、每类k张图像,记为
S={(xi,yi),(x2,y2),…,(xN×k,yN×k)} (1)
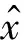
(2)
其中c∈Y,Y为标签空间。模型计算过程公式表示为
(3)
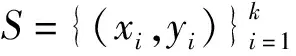
(4)
1.2 距离度量函数
注意力机制通过距离度量函数来计算向量之间的匹配程度.度量学习依赖给定的度量方式,计算样本之间的相似度,相似度越大则目标之间属于同类的可能性越大.一般而言,一个距离函数d(x,y)需要满足以下性质:
1)d(x,y)=0有且仅有x=y时;
2)d(x,y)≥0;
3)d(x,x)=d(y,x);
4)d(x,k)+d(k,y)≥d(x,y).
根据数据的不同特性,不同问题采用不同的度量方法,如空间问题采用欧氏距离,路径问题采用曼哈顿距离,编码差别采用汉明距离,向量差距采用夹角余弦等.由于计算图像样本间的距离属于高维度向量问题,距离度量函数采用余弦距离.通过欧几里得点积公式:
a·b=‖a‖‖b‖cosθ
(5)
得到向量A和向量B余弦夹角:
(6)
d(A,B)=θ=arccosθ
(7)
通过余弦距离θ的大小来计算样本之间的距离,θ越小,cosθ越大,样本间越相似,反之亦然.
1.3 特征编码
利用LSTM网络特性,将CNN网络提取的特征向量嵌入到编码空间,使各样本之间产生关联,记住特定信息.对于训练集,其编码函数表示为g(x).结合双向LSTM网络[12](Bi-directional long short-term memory,Bi-LSTM)对样本进行编码,输入序列为训练集中的各个样本,对样本xi的编码为
(8)
(9)
(10)
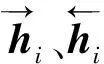

(11)
(12)
(13)
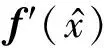
2 网络设计
2.1 网络结构
2.1.1数据预处理
针对本文实验数据集的特定属性,对其进行数据预处理操作.首先对原始数据图像进行格式解析,将原始只读形式文件解析为图像形式文件.由于解析后的图像像素不一,包括128×128,158×158,192×193等大小的图像,需统一对图像尺寸进行调整,将其裁剪为128×128像素大小.此外,为方便图像进行分类,统一对图像标签进行one-hot编码.
2.1.2网络算法
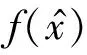
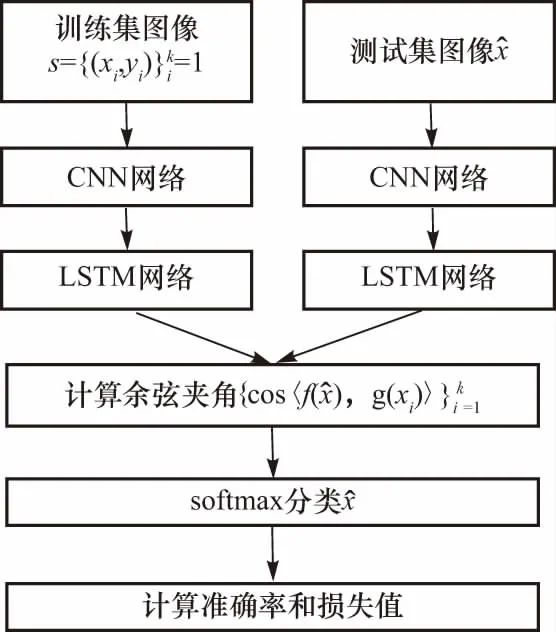
图1 图像识别网络结构
CNN网络由输入层、隐含层、输出层组成.其中隐含层包括卷积层、池化层和全连接层,卷积层的目的是提取输入图像的不同特征,在各层内部包含多个卷积核,该卷积核中权重参数w和一个偏置b由反向传播算法得到;池化层则是对卷积层输出的特征图进行特征选择,降低数据维度;全连接层对提取出的特征进行非线性组合,从而输出特征向量.本文方法由于只需利用CNN网络对图像进行初步特征提取,无需将特征映射输出,因而移除输出层,使图像经过全连接层后,直接输入到下一个网络中.

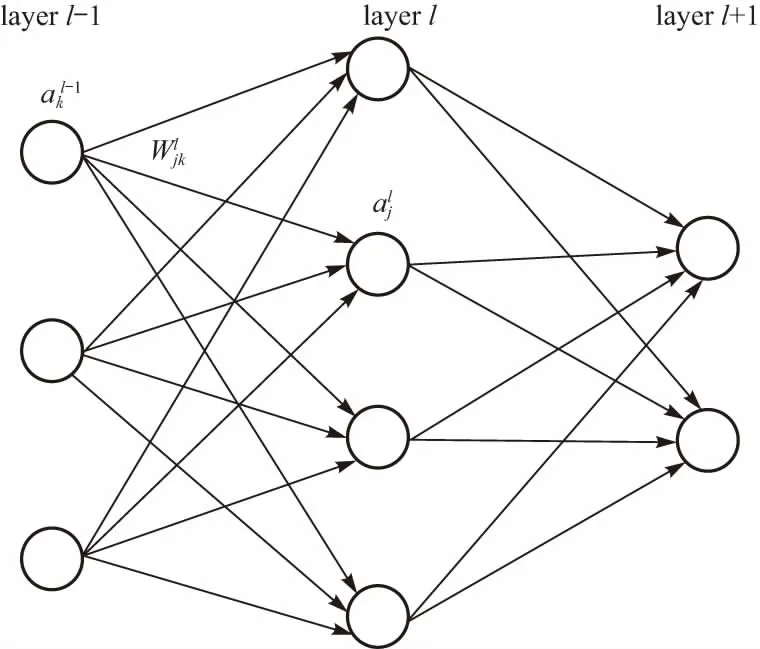
图2 CNN前向传播示意图
(14)
改写为矩阵形式:
al=σ(wlal-1+bl)
(15)
(16)
δL=((wl+1)Tδl+1)⊙σ′(zl)
(17)
(18)
(19)
CNN网络受神经元个数、学习率、迭代次数等超参数的影响,此类超参数依据经验值进行设置.本文所构建的CNN网络框架中包含4层卷积层和1层全连接层,在卷积层后添加批量标准化(batch normalization,BN),使用ReLU非线性激活函数,并添加max pooling池化层,经过全连接层后得到特征分布,作为LSTM网络的输入,具体结构如图3所示.
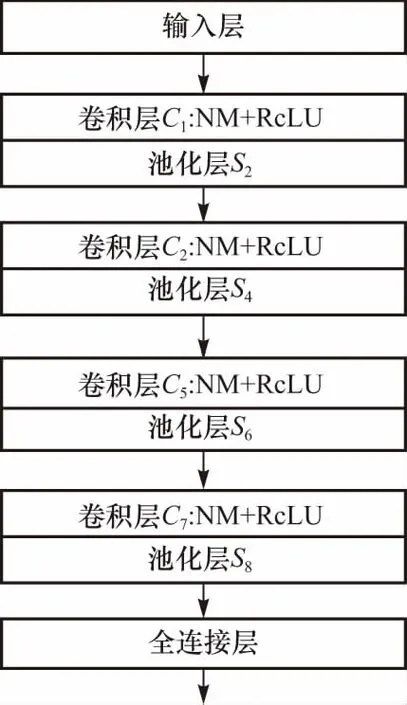
图3 CNN网络结构
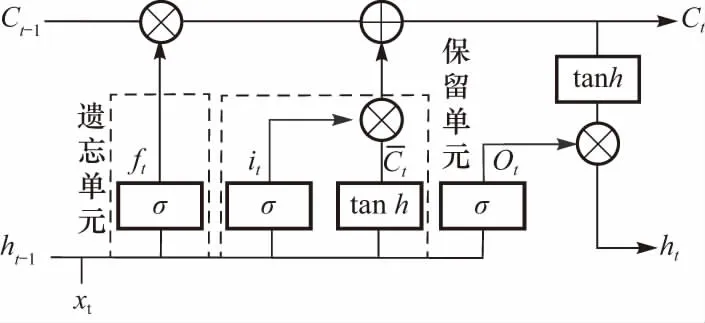
图4 LSTM单元框架
at=σ(Wo[ht-1,xt]+bo)
(20)
使用Bi-LSTM网络进行特征编码,该网络不仅将前一刻的样本与当前样本进行关联,并且使后一刻的样本也与当前样本得到关联,进一步增强样本间的关联度,区分同类样本和异类样本.Bi-LSTM网络由前向LSTM和后向LSTM组成.前向LSTM层和后向LSTM层共同连接着输出层,每个单元包含6个共享权值W1~W6,整体框架如图5所示.在前向层和后向层的传播中,分别计算前向和后向各时刻隐含层的结果并保存,最后在每个时刻结合前向层和后向层对应时刻的结果得到最终输出(左右箭头分别代表后向、前向传播).该过程对应表达式如(21)~(23),式中函数F与函数G为t时刻的输出函数.
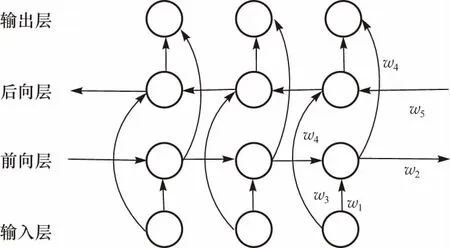
图5 双向LSTM框架图
(21)
(22)
(23)
余弦相似函数计算测试样本与训练样本图像之间的余弦距离,对输入的训练样本向量和测试样本向量使用Batch Matrix Multiply方法进行点积运算,通过计算两向量的平方根倒数,将二者结果相乘输出余弦相似值,并输入注意力机制中,最后得到预测结果.网络通过交叉熵代价函数计算损失值,根据结果进行梯度下降并反向传播.
2.2 训练策略
在小样本学习任务中,数据集的组织原则与训练方式不同于常规深度学习数据集,记常规数据集为Dr,小样本数据集为Df.在常规深度学习数据集中,有
Dr=Trainset+Testset.
在小样本学习数据集中,Df由若干Dr构成,Dr中包含N个类别K个样本的若干小规模的常规数据集,每个Dr定义为一个Task,即
Df={Dr}={Trainset+Testset}.
通过对每个Task进行模型训练,在只有少量样本的情况下,泛化已知的类别.
基于此,本文针对SAR图像训练样本数据有限的情况,结合小样本学习中数据训练方式,采取对训练集上的图像预测试的策略进行模型训练,即划分出训练集中的部分图像先进行测试.具体操作如下:将训练集S按照20∶1的比例划分为Sa和Sb两部分,Sa集用来进行图像训练,Sb集用来进行预测试.模型训练过程分批次进行计算,每一批次从Sa集各类图像中随机选取10张图像,从Sb集中随机选取一类,并从该类中随机选取5张图像进行预测试,每批次计算结束后返回准确值和损失值.
3 实验与分析
3.1 实验数据
实验数据集采用来自美国国防高等研究计划署支持的MSTAR计划公布的MSTAR数据集,采集数据所用雷达工作在X波段,采用HH极化方式,分辨率为0.3 m×0.3 m.该数据集的采集条件分为标准工作条件(standard operating condition,SOC)和扩展工作条件(extended operating condition,EOC),数据集中的目标是雷达工作在多个俯仰角时各军事目标在该方向上的SAR成像图片.本次实验采用官方公开提供的SOC条件下的数据集,共包括10类静止地面目标图像,分别为自行榴弹2S1、装甲侦察车BRDM2、步兵战车BMP2、装甲运兵车BTR60、装甲运兵车BTR70、推土机D7、坦克T62、坦克T72、军用卡车ZIL131、自行防空高炮ZSU234.
3.2 网络参数设置
网络在Ubuntu 16.04环境下基于Python 3.6编程实现,算法部分实验基于Pytorch框架实现.实验优化后,选取参数设置如下:学习率lr设为1×10-3,学习衰减系数lr_decay设为1×10-6,迭代次数Epoch设为50,每批训练样本数batch_size设为105,weight_decay设为1×10-4,优化器选用Adam.
3.3 结果与分析
网络在训练时共进行50次迭代,图6显示了50次迭代中交叉熵代价函数变化情况.由图可知,随着迭代次数的增加,网络不断进行参数优化调整,损失值在部分迭代更新中出现反增情况,但整体来说呈下降趋势.实验中每次迭代后进行一次测试集上的测试,与之对应的准确率情况如图7所示,在迭代过程中准确率略有波动,当epoch值达到26左右时,交叉熵损失值稳定在1.55左右,分类准确率已超过99%.
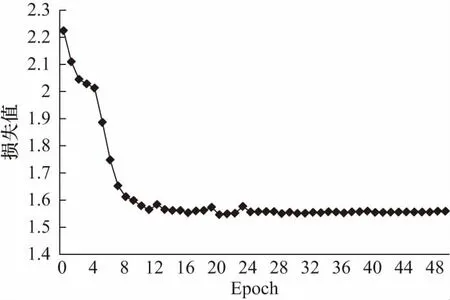
图6 测试集交叉熵损失值变化曲线
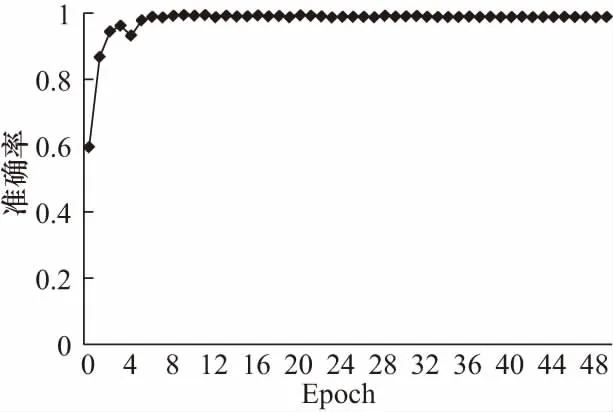
图7 测试集准确率变化曲线
将本文方法与K近邻算法(KNN)、支持向量机(SVM)、随机森林法和卷积神经网络(CNN)进行比较,如表1所示.KNN算法中K值过小会发生过拟合,且模型复杂度高,K值过大则导致分类模糊,学习误差增大,采用交叉验证法后选取K=10;由于样本量不大且样本特征较少,SVM算法中选取高斯核函数,不仅能将原数据映射到高维空间实现线性划分,而且能减少计算量;随机森林法中子树数量设置太小容易欠拟合,太大不能显著地提升模型性能,采取多次重复实验的方法将该值设为1 000;CNN网络中选取卷积核与池化核更小、卷积层更多的VGG-16模型,其结构简洁,泛化性能较好.从表中看出,本文方法的准确率最高,达到99.3%,较SVM算法提升2.5%.神经网络在该数据集上的识别效果不高,主要因为MSTAR数据集样本数量较少,网络易出现过拟合情况.

表1 本文方法与其他方法的结果比较
通过实验发现,对于装甲侦察车BRDM2的识别,传统方法易将该类混淆为BMP2、BTR70等类别.SVM方法与本文方法在BRDM2类别上的平均识别准确率分别为87.1%和95.1%,在该类别上本文方法的准确率相比提高了8.0%,从该类中随机选取8张图像输出两种方法预测结果,如表2和表3所示.分析结果得到,在易混淆的图像识别任务上,本文方法识别效果优于传统方法.
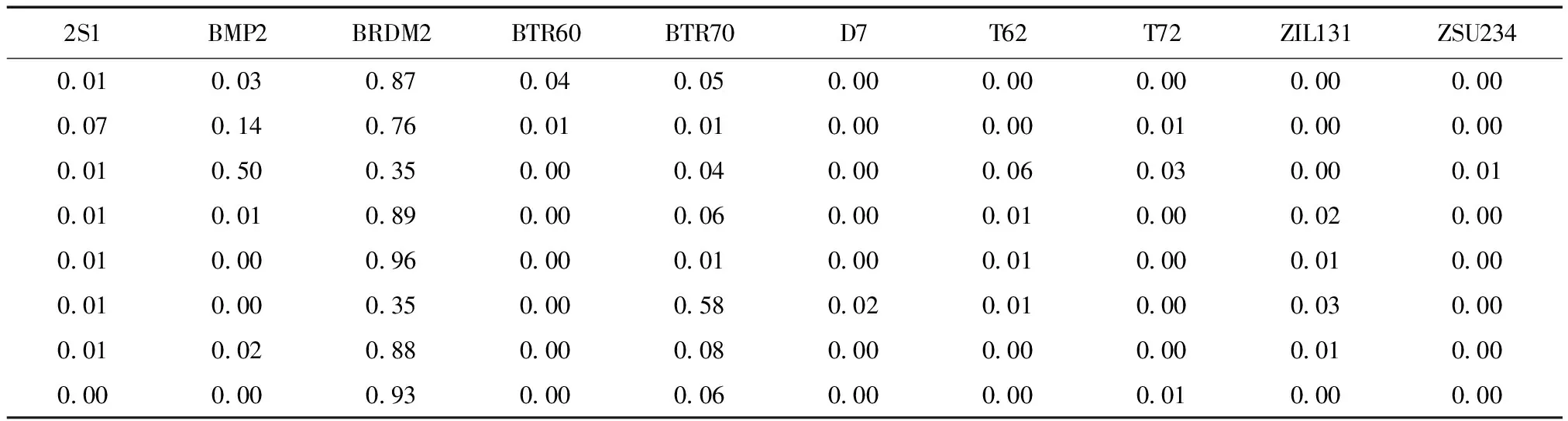
表2 SVM方法在BRDM2上预测结果:准确率
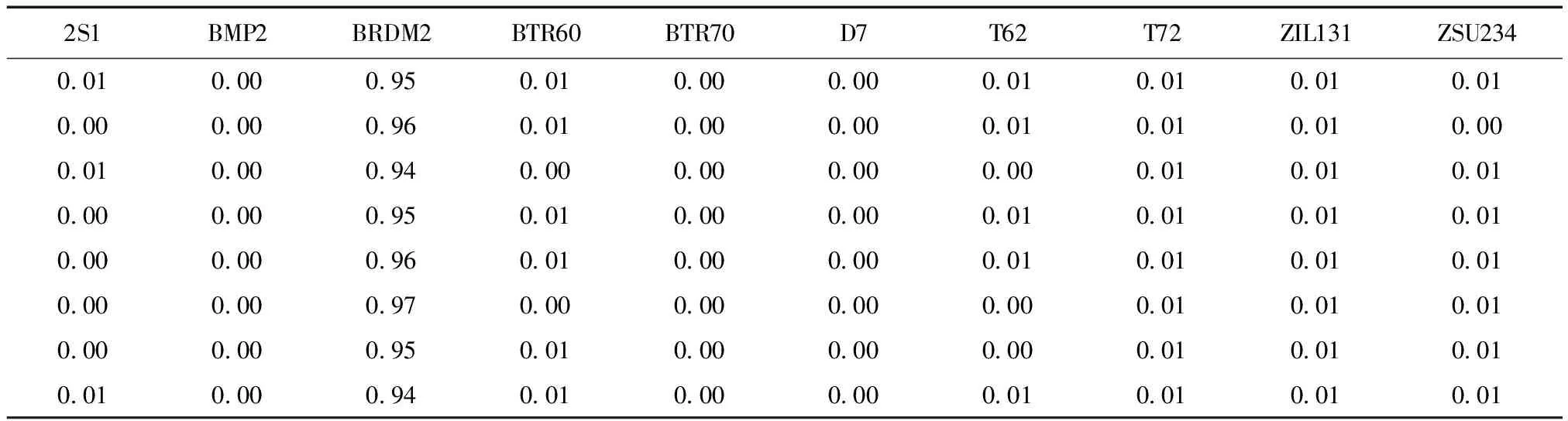
表3 本文方法在BRDM2上预测结果:准确率
4 结 论
本文基于图像相似度的匹配范式提出一种SAR图像识别分类方法,使用CNN网络提取图像中的特征,对此特征进行LSTM编码,加强图像间的关联性,利用余弦相似度量函数计算测试样本与训练样本之间的距离,通过注意力机制后进行图像分类.同时,在样本有限的情况下,结合小样本学习中数据训练方式,对训练集按照比例进行划分,采取预训练的策略进行实验.实验表明,在MSTAR数据集的10类军事目标准确率达到99.3%,本文提出的方法在SAR图像识别上具有一定的应用前景.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
电子制作(2019年11期)2019-07-04 00:34:38
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学学习与研究(2017年3期)2017-03-09 18:12:42
