
CRM系统运用下的商业银行数据分析研究
2021-03-25 10:18
环渤海经济瞭望 2021年1期
想要实现商业银行的可持续发展,需要面对并解决市场中可能出现的任何经济关系,而这也就需要商业银行对本行资金存储数目清楚了解,对银行和存在商业关系的客户关系挖掘整理,并对整个国内市场经济具体发展情况进行分析,从而制定商业银行经营管理战略[1]。在大数据时代背景下,客户数据信息量呈爆炸式增长,想要为客户提供更加个性化多样化服务,目前也作为商业银行主要实现的目标,文中将运用CRM系统分析商业银行数据,通过分析客户数据了解客户所需,并分配不同资源,实现客户营销效率最优、最大化,对推进商业银行改革发展意义重大。
一、商业银行客户分群指标及模型建立
(一)客户分群
对商业银行的客户价值分群主要包括两方面,一是负债业务价值,二是资产业务价值。以个人客户为分群目标完成的客户分群,一方面是个人客户的当前价值,包括负债、资产两种业务价值;另一方面是个人客户的潜在价值,表现在未来成熟时机下客户的发展潜力。需要以客户具备的客观特征为依据确定客户的潜在价值,本文主要以客户具体的发展潜力与合作潜力,用于对客户潜在价值有效肯定(见表1)[2]。

表1 商业银行客户发展潜力指标规划
商业银行客户所具备的个人合作潜力,表示了个人客户对其他银行产品与服务购买的可能性综合评价,具体可以由客户已购买、未购买的产品数量和发展潜力完成评定。如今商业银行对于客户个人的合作潜力维度指标,包括了存款类、贷款类、国债、银行保险、第三方存管、黄金、外汇、转账、POS消费、代缴费、存款证明、贷款证明等,合作潜力计算公式=未购买产品数×1。
(二)商业银行个人客户分析模型
1.分析方法选择
处于大数据背景下仅仅使用普通分析软件,是无法实现对整个市场客户信息数据有效分析的,相比之下MapReduce可以作为对大数据处理的并行编程模型,具备较强的大数据处理能力,主要包括了Map、Reduce两部分[3],首先由程序操作者对Map函数确定后,统一转换最初一对键值形成新键值,之后Reduce函数即可对新键值重新接收,处理另外值后在HDFS中存储结果。K-Means算法作为最经典的跨分算法,操作算法流程图(见图1),因此本文选择MapReduce架构采用K-Means聚类算法分类客户信息数据,

图1 K-Means 算法操作流程
首先,构建思维交叉向量空间,包括了资产和负债两个业务价值、发展和合作两个潜力,每一个空间对象点可以代表一个客户数据,选取K中心点后在周围聚集对象点客户群,并在文件存储节点内保存结果。
其次,对中心点进行调整获得K个客户群,对中心点在调整过程中始终作为一个循环过程,对初始K个客户群获取后,计算每一个对象点距离中心点结果,最后选择中心点距离最近的对象点作为新客户群重复循环以上操作,直至最终达到一定对象点精度和结果不再改变。
二、建立商业银行客户分群模型
(一)操作步骤
本次运用CRM系统完成的个人客户分群步骤包括如下:
首先,以个人客户分类指标为依据,处理商业银行的数据总仓库数据,并构建统一的CRM数据集,采用元数据成功寻找客户个人分类指标所需数据,抽取后计算分类指标构建CRM数据集;其次,建立商业银行各分行数据集,同样基于CRM系统向客户通过调查填补关键分类客户数据,直接将所得指标客户数据运用于CRM系统中,保证可以全面方便的调用、查询;再者,命名每一个客户序号为Key,共计包括4个得分项分别为客户资产、客户负债、客户发展潜力、客户合作潜力,完成每一个数据集的K-Means聚类分析,可以获得每一个输出数据的Key及全部客户群聚类所获中心客户号Value[4];最后,对个人客户分类距离处理后,以银行的各项管理决策及数据分析意见,调整所得结果最终可获银行个人客户分类,从而提供关键的银行决策及资源分配建议。
(二)准备商业银行客户数据
(见图2)作为本次建立商业银行的客户个人分类数据集流程,主要完成工作有两项,一项是对商业银行的总数据仓库其中主要的数据构成进行分析,抽取分类所需数据后整合并重新加载至分行分类数据集;第二项是分析个人客户的分类指标模型,填补关键分类数据建立面向个人客户分类所需的分行数据集[5-6]。

图2 个人客户分类数据集建立流程
1.总行数据集设计
以客户的差异化业务需求为依据,建立商业银行的业务数据集,这对于个人客户分类所需数据,通过总行个人CRM数据集建立能够提供极大帮助。建立的个人CRM数据集,能够涵盖诸多个人客户的分类指标,包括了基础信息、产品信息等[7]。
2.问卷调查数据设计
文中对银行客户的信息采集主要通过问卷调查实现,调查内容主要包括了客户的基础信息,性别、年龄、文化程度、个人年收入、客户所需购买银行产品等。
三、商业银行个人客户聚类分群
选取某商业银行的5000个客户信息作为本次CRM系统下的大数据分析试验数据,主要分析步骤包括以下几部分:
(一)准备样本数据
(见表2)作为本次准备的商业银行客户个人信息样本,以上文所述的客户个人分类指标模型,(见表3)作为完成4个样本数据的价值指标抽取作为大数据分析输入值。
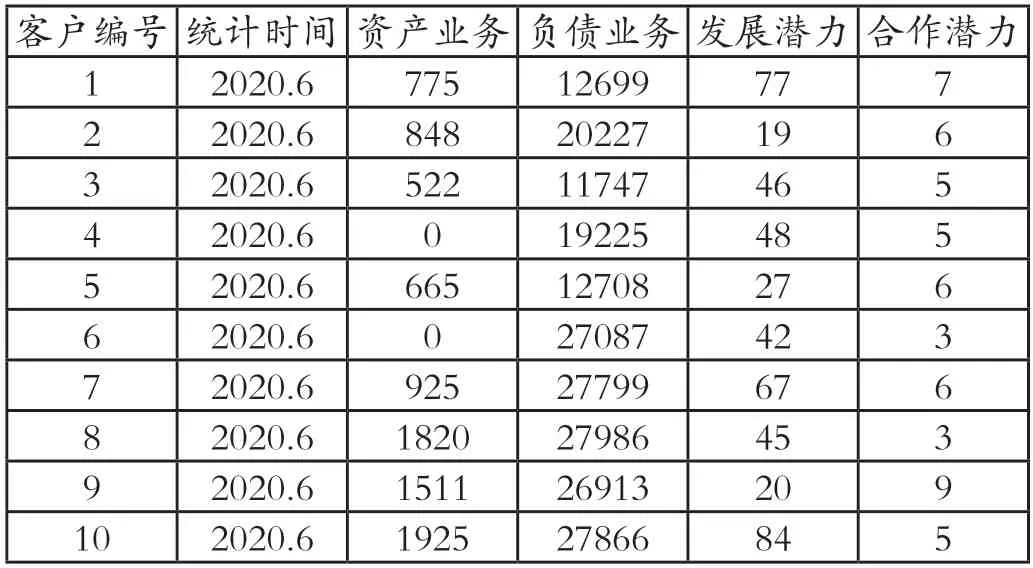
表2 数据样本表

表3 样本数据描述
(二)K-Means聚类
通过划分个人客户群共计6类(k=6),通过HDFS成功获取客户信息数据后,即可所获共计6个客户中心号,完成每一个客户中心号至中心点距离后。以4组隔热客户分类数据分析,n取值4,将每一个客户号与客户自身间隔距离最短中心点,视为该簇成员后,共计所获6个初步簇并对每一个簇中心点计算,所得不同纬度均值,之后将6个簇的中心点求解得出后,完成最近对象点和中心点距离计算,输出结果类似:
【客户编号】@1
【客户编号】@2
【客户编号】@3
【客户编号】@4
……
(三)调整参数优化结果
循环以上步骤直至确定最后MapReduce工作表后,对部分客户特征对比,并查看不同类别对应属性,查看客户所处分类是否对应,并对分类准确度与价值型加以判断。假若最终判断所得结果未能符合预期,则可以经过对分类类数修改,或对不同权重改变所获分类结果。(见表4)为所得试验的结果。
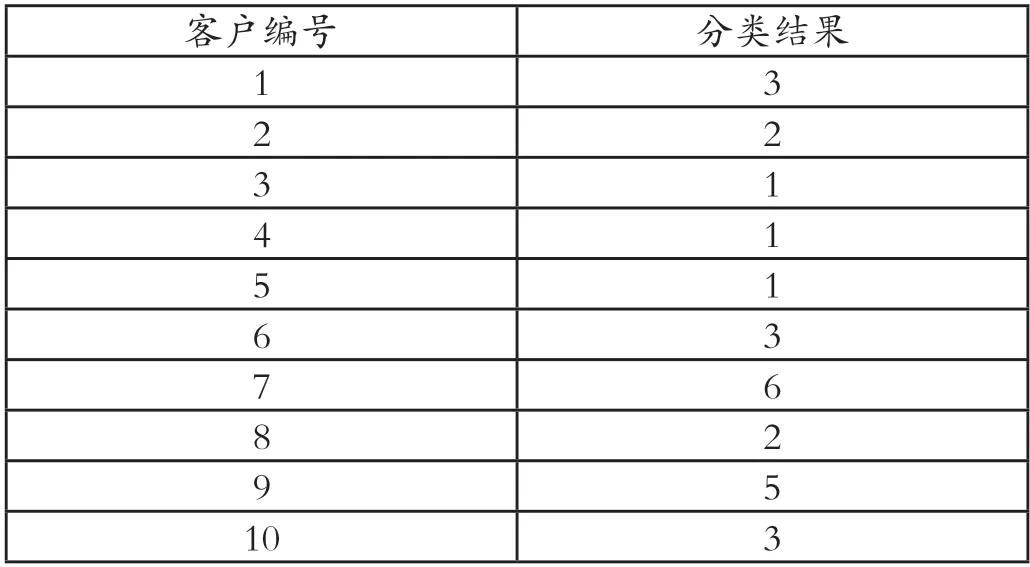
表4 部分客户分类结果
根据该结果即可清楚看到不同客户相应的特征分类,从而实现不同客户制定针对性的营销策略,给予客户差异化的商业银行服务体验,这样也就实现了运用CRM系统分析商业银行数据,可以实现最大化银行利益同时充分节约资源,保证投入最小化回报最大化。
四、结语
综上所述,通过运用CRM系统能够以客户的个人分类,建立客户分类清单实现针对性营销,对比分析预测营销结果和实际营销结果,可以获得商业银行个人客户及产品业务分析,根据数据分析结果制定针对性的营销计划,及时改善营销策略能够提供科学有效的产品服务依据。
猜你喜欢
计算机技术与发展(2020年8期)2020-08-12
大众投资指南(2020年10期)2020-07-24
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
消费导刊(2017年20期)2018-01-03
大众摄影(2015年9期)2015-09-06
科技与创新(2015年9期)2015-06-02
当代经济(2015年4期)2015-04-16
现代企业(2015年6期)2015-02-28
中国经济信息(2014年7期)2014-08-09
