
行人属性识别研究
2021-03-25 04:06:12马路宽
现代计算机 2021年4期
马路宽
(四川大学计算机学院,成都610065)
0 引言
行人属性识别(Pedestrian Attribute Recognition,PAR),其目的是在给定的行人物图像中挖掘目标人物的属性。与LBP[1]、HOG[2]等低级别像素特征不同,行人属性是更高级的语义特征,是符合人们日常描述一个人外貌特征认知思维的词语。相较于计算机视觉中的其他任务,行人属性识别中数据集包含许多不同层次的标签。例如,头发的长短、上下衣服的颜色、衣服的款式、是否戴帽子、是否戴眼镜等被看作是特定的细颗粒度属性,这些属性的关键位置都在图像的不同的局部区域,而有些属性是全局的概念,如行人的性别、年龄等,并不对应于特定的局部区域,需要综合的特征分析,这些属性被认为高级属性。
随着行人属性识别在计算机视觉领域越来越多的被学者研究,越来越多的数据集被公开出来,表1 列举了目前认可度较高的数据集,其中常用的数据集有PETA[3]、Market-1501[4]和Duke-MTMC[4]。
行人属性识别常用的评价标准主要采用平均准确度(mean Accuracy,mA)[3]评价属性识别算法。对于行人每一个表情属性,mA 分别计算正样本和负样本的分类准确率,然后取其均值作为该属性的识别结果。最后,计算所有属性的平均值得到识别率。公式如下:
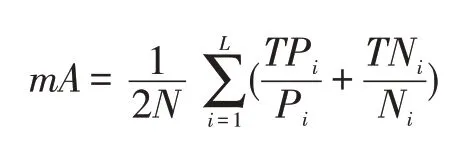
其中L为属性的数量。TPi和TNi分别为预测正确的正例数和负例数,Ti和Ni分别为正例数和负例数。
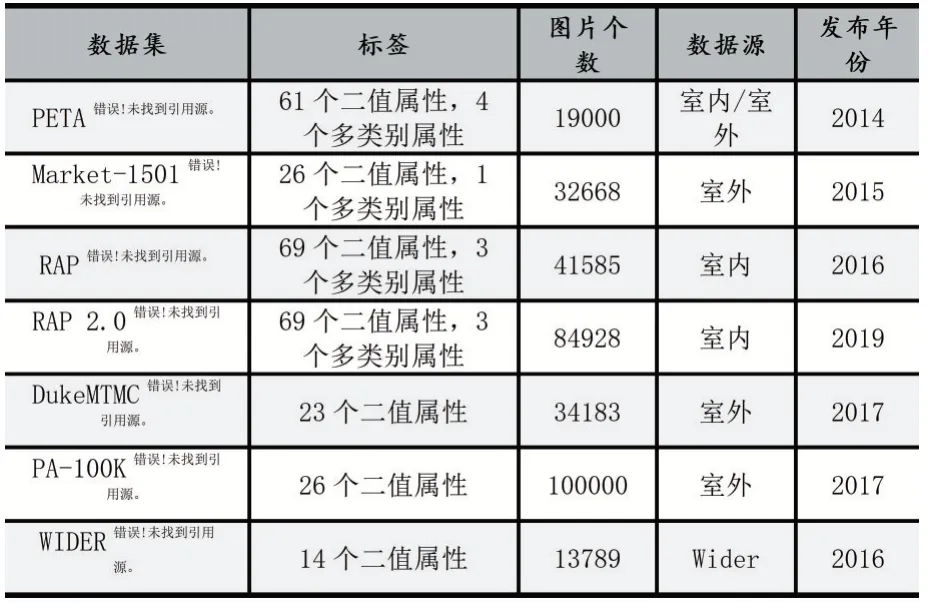
表1 行人属性识别数据集
1 算法
1.1 传统算法
传统的行人属性识别方法通常采用手工提取特征,依赖于强大的分类器最终的目的是得到某一图像的特征表示。常用的分类模型包括HOG[2]、SIFT[9]、条件随机场模型[10],Layne 等人[12]首先使用支持向量模型(SVM)解决属性识别问题。Deng 等人[3]利用SVM 和马尔可夫随机场进行属性识别,构建了行人属性数据集PETA。然而,这些解决思路对特征的提取都是使用传统手工的方法,不能有效地表示图像,忽略了对属性识别任务重要的属性之间的关系。伴随着问题规模的扩大,和场景复杂度的提高,这些算法很难胜任一些苛刻的要求,无法满足实际应用的要求。而且传统的算法并没有很好的利用属性之间的关联性。
行人属性识别可以视为一个多标签分类问题,如果不考虑标签之间的关联性可以简单的视为多个单独的二值分类问题进行处理[13],但是行人的属性在一定程度上存在关联性,例如穿着红色衣服并且长头发其性别属性在很大程度上倾向于女性,标定后的标签排序算法[14],该算法考虑了成对标签之间的相关性,将多标签学习转化为标签排序问题。
随机k-Labelsets 算法[15],它将多标签分类问题转化为多个分类问题的集合,每个集合中的分类任务是一个多分类器。多类分类器需要学习的类别是所有标签的子集。
多标签行人属性识别的常规流程如图1 所示。为了提高输入图像的质量,矫正变形,减少噪声干扰,增强图像特征,提高训练模型的鲁棒性通常都需要对图像进行预处理操作,常用的预处理方法有归一化、随机裁剪、灰化等。首先将预处理之后的行人图像输入,提取其特征表示(如HOG、SIFT),然后根据提取的特征训练一个分类器来预测相应的属性。
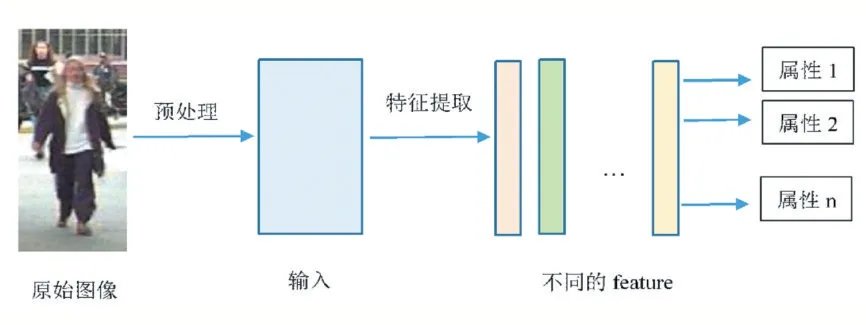
图1 多标签行人属性识别的常规流程
1.2 基于深度学习的方法
(1)基于全局的方法
全局的方法是考虑图片的所有信息,将整张图片输入给神经网络处理。
Sudow 等人[16]提出一种针对所有属性联合训练CNN 识别模型的方法,针对所有能够利用这些依赖关系的属性,只考虑图像作为输入,而不考虑行人的姿态、局部信息或环境信息。并提出了一个真实的户外视频序列的数据集PARSE-27k,这是一个更大的、排列良好的属性数据集,并使用它来评估检查模型的性能相关因素。其中包含27000 个行人,每个行人标注10个属性。有创意的是由于遮挡、图像边界原因而无法确定属性的被标记为N/A。
Li 等人[17]提出两个基于深度学习的模型来识别属性。首先,将每个属性视为互相独立的,提出了基于深度学习的单属性识别模型DeepSAR,单独地对每个属性进行识别,为了有效地利用属性间的相关性,提出了统一的多属性联合学习框架DeepMAR 来同时识别多属性。在DeepMAR 中,一个属性可以用于表示其他属性。
Abdulnabi 等人[18]提出分类器之间共享统计信息的方法,采样不足的分类器可以利用来自其他分类器的共享信息来提高其性能。具体的做法是,通过一个多任务CNN 模型来学习二元语义属性,每一个CNN 预测一个二值属性。多任务学习允许CNN 模型在不同属性类别之间同时共享视觉知识。每个CNN 都会生成属性特有的特征表示,然后对特征进行多任务学习来预测它们的属性。
基于整体的行人属性识别算法都是将整个图像作为输入,进行多任务学习,尝试学习最健壮的特性表征,并且属性之间的信息可以共享。共享使用特性,端到端的学习,算法的优点是较为直观、复杂度低、效率高,但由于缺乏对局部细粒度属性识别的考虑,这些学习模型的性能仍然有待提高。
(2)基于局部特征的方法
局部特征更符合人们判断他人衣着、外表属性的思维模式。
为确定图片中行人的属性常常需要检测一些不显眼的对象和特性,Diba 等人[19]提出一种新的卷积神经网络——Deep Pattern CNN 模型来解决这一问题,该模型可以挖掘中层图像小块区域,能够有效地利用细微的局部信息。该模型既利用图片的上下文信息,又通过迭代学习和局部区域聚类挖掘中层图像的纹理来进行人的属性识别。
Li 等人[20]提出PGDM 模型,PGDM 首先估计人的关键点,同时生成局部区域,然后把这些基于区域的特征表示综合起来,用于姿态引导下的行人属性识别。由于在现有的行人属性数据集中没有姿态标注,对现有的行人属性数据集进行人体姿态的标注是一件十分耗时和困难的工作。该模型将位姿知识应用和局部区域信息关联起来,一起应用在属性识别中,具体的做法是将人体关键点作为先验,在这些关键点附近找到匹配的局部区域,然后将所有的关键点相关区域综合起来进行行人属性识别。
Huang 等人[21]提出在自由环境下识别人的属性的方法。选用一个卷积神经网络(CNN)从所有小波子检测中选择最能描述属性的人体部分,以行人为中心的上下文通过在CNN 中共同学习到的全局场景分类评分来重新为以人为中心的预测打分,从而产生最终的场景感知预测。使用语义组织的上下文从相关的人体局部和整个图像的上下文。为了防止全局场景上下文在一些不那么相关的物体对属性识别的干扰,只将全局场景特征作为互补信号,并将它们映射到CNN 的场景分类分数中。
Liu 等人[22]提出一种新的定位引导网络,可以预先提取的建议和属性位置之间的关联性,为局部特征分配特定属性的权重。该模型可以自动学习每个属性的局部特征,并通过与全局特征的交互来强调局部特征。在两个行人属性基准PA-100K 和RAP 数据集上的实验结果证明该模型的识别效果较好。
本小节算法都结合了全局和细粒度局部特征。相较于只考虑全局信息的算法,局部信息的使用显著提高了算法的识别性能。也更符合人类的判断方法。但基于局部信息的算法同时也存在着一些缺陷,例如,最终的识别结果很大程度上受局部定位准确度的影响,错误的局部特征检测会导致错误的属性分类等。另外由于考虑到人体部位的信息必然需要更多的训练时间和代价,在数据集上,一些现有的数据集并没有局部信息的标注,需要额外标注局部特征属性标签,这无疑进一步增加了人力成本。
(3)基于注意力机制的方法
Liu、Zhao 等人[23]提出一种新的基于注意力的深度神经网络,称为HydraPlus-Net,它可以多方向地将多层次注意力映射输入到不同的特征层。该模型能够从低层次到语义层次捕获多个关注,探索了关注特征的多尺度选择性,丰富了行人的最终特征表示。对行人细粒度属性,提出了一种基于多方向性注意模块的多头联立网络(HydraPlus Network,HP-Net)。在此基础上,并且提出了一种新的大规模行人属性数据集(PA100K dataset),包括最大数量的行人图像和实例。
Sarfraz 等人[24]提出端到端感知视图属性预测模型,在端到端学习框架中确定了属性依赖的关系,除了依赖于身体部位、图像中的属性空间上下文或一般场景上下文的流行观点之外,粗糙的身体姿态信息可以是另一个简单但高度相关的可靠属性推断线索,并提出姿态视图敏感属性推理能够更好地学习属性预测。
Sarafianos[25]提出了一种有效的方法来提取和聚合不同尺度的视觉注意力遮罩。通过引入了一个损失函数来处理类和实例级别上的类不平衡,并进一步证明带有高预测方差的惩罚注意掩模是导致注意机制的监管不力的原因。算法在PETA 和更大属性数据集中使用简单的注意机制,无需附加上下文或附加信息,就能获得很好的识别率。
Guo 等人[26]提出使用类激活图网络(CAM)来识别人的属性,并通过细化注意力热图来进一步改进识别,注意力热图是CAM 的中间结果,反映了每个属性的相关图像区域。该方法不需要身体部位的检测以及身体部位与属性之间的先验对应关系。定义一个新的指数损失函数来度量注意力热图的适宜性,根据原有的分类损失函数和新的指数损失函数对属性分类器进行进一步的训练。该方法是在带有CAM 的端到端CNN 网络上开发的,通过添加一个新的组件来细化注意力热图。
2 问题与挑战
虽然有众多学者研究行人属性识别领域,并提出很多解决的算法,但是由于问题场景的复杂性,行人属性识别仍然存在这很大的挑战,在实际的监控场景中,由于摄像机的拍摄角度不同会造成同一个人的观察视角不同,对识别效果产生的影响较大,使人的属性识别变得更为复杂。另外由于户外的场景不定性很强,行人轨迹可以看作是随机的,另外其他车辆、广告牌等物体可能出现在行人之前,从而遮挡行人,造成行人身体一部分的信息缺失,这显然增加了属性识别的难度甚至会导致错误的分类结果。由于行人和监控摄像头的距离都比较远,所以造成图像的分辨率较低,给一些细粒度属性的识别增加了难度,这也是很难采用人脸识别的原因之一。另外,室外光线的强度、数据分布不均等因素也给行人属性识别增加了挑战。
目前主要的研究还是基于行人图片的属性识别,而现实场景主要是视频帧,考虑单张图片有遮挡、角度问题,可以考虑视频帧之间的连续性,例如遮挡问题,可以进行视频多帧之间的弥补,视频作为图像的高维信息,如何准确、高效地利用这些高维度信息来识别行人的属性是一个值得研究的问题。
3 结语
本文介绍了行人属性识别的概念背景以及评估的方法,另外介绍了部分现有工作,主要阐述了早期基于传统的识别算法以及深度学习的方法在行人属性识别领域的应用,包括基于全局的算法和基于局部细粒度属性的算法并介绍了基于注意力机制的算法,并介绍了行人属性识别存在的问题难点,对未来的工作做出了展望。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
扬子江(2019年1期)2019-03-08 02:52:34
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2018年1期)2018-04-18 11:52:35
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
