
一种基于深度学习的图像盲去运动模糊算法
2021-03-25 04:06:06朱龙闯
现代计算机 2021年4期
朱龙闯
(四川大学视觉合成图形图像技术国防重点学科实验室,成都610065)
0 引言
图像运动去模糊,即从带有运动性质模糊的原始图像中恢复出包含重要细节的清晰图像,一直是计算机视觉领域一项具有挑战的工作。随着网络媒体的发展,生活中产生了大量与人脸相关的图片和短视频等媒体信息。尽管近年来,数字成像技术已经取得了巨大的进步,但在捕获内容的同时,由于在成像传感器曝光的期间,场景中物体或者相机的相对运动所引起的运动模糊也成为了一个普遍存在的现象。由此带来了显著的视觉质量的下降、图像细节的丢失等诸多问题,在文献[1]中表明因模糊而退化的低质图像可能造成许多计算机视觉任务(例如人脸识别)的性能下降。因此,一种专门设计的,人性化的去运动模糊算法对于处理以人像为中心的视觉数据是十分必要且有益的。
深度学习的兴起和发展,给计算机视觉领域的研究带来了前所未有的成就。尤其是文献[2]提出的生成式对抗网络(GAN)以及其变形因为能够更好地建模数据分布,保留图像的纹理细节,来生成更加清晰锐利令人信服的图像,目前已经运用于生成高质图像、图像翻译与风格迁移、图像还原与修复等任务中。受图像超分辨率、图像修复等工作的启发,本文的工作正是以GAN 作为框架,通过端对端的学习方式估计运动对象的模糊内核,结合对于生成器以及判别器网络的修改,来更好地适应高分辨率图像任务,同时增加了人脸先验的损失函数设计可以有效约束引导网络学习。
总而言之,工作的主要贡献是:提出了一种高效的盲去运动模糊的框架,可以提高高分辨率运动模糊图像的处理能力。结合人脸先验信息,能够更好地定位人脸,高效获取特定位置和场景下的图像语义信息。
1 相关研究
1.1 图像去运动模糊
在传统研究中,可以将单张图像去模糊分为盲去模糊与非盲去模糊。前者将以估计模糊核的形式进行处理,通过反卷积的方式生成清晰图像;后者则是通过大量的图像先验信息和已知的模糊核进行图像恢复,是一种更加“理想化”的去模糊方法。然而无论是函数简单拟合模糊核还是手工选取的图像先验,都难以估计真实图像中的模糊变化。
随着深度学习的兴起,推动了计算机视觉任务的突破性发展。Sun 等人[12]首次利用卷积神经网络(CNN)来估计模糊核。Chakrabarti[13]注重局部信息,独立对各图像局部进行推理恢复。此外,Nah[14]直接使用端对端的方式,跳过了模糊核估计这一步骤,直接从模糊图像恢复中恢复清晰图像,效果令人印象深刻。
GAN 在图像领域作出了重大贡献。文献[15,17]借鉴了图像翻译的思路[16]去解决图像模糊问题。特别文献[6]结合Wasserstein GAN[17]、PatchGAN[16]的思想,更加适应高分辨率图像任务的处理。Lu 等人[18]将内容和模糊进行拆分解缠,利用两个编码器分别对内容和模糊进行特征提取和模糊信息捕获。
1.2 生成式对抗网络
生成式对抗网络[2]由Goodfellow 于2014 年提出,其包含两个部分:生成器和判别器。生成器负责根据输入的信息,通过不断训练学习,生成能够欺骗判别器的人工合成样本数据,而判别器负责对输入的数据进行验伪,同时也不断学习提高自身鉴别能力。两者本质上构成了最大-最小化的博弈游戏。其目标函数表示如下:

众所周知,GAN 目标函数的优化也一直是一个难题。文献[17]证明了传统的GAN 存在着两大问题:梯度消失/爆炸和模式崩溃,为此提出了以Wasserstein 距离代替JS 散度的方法来帮助优化。Mao[20]、Berthelot[21]、Qi[22]等均在损失函数设计上作出了贡献。
除了在目标函数上通过非正则化或正则化的基础改进,为满足实际任务的需求,GAN 的模型结构上也做出了诸多调整。cGAN[18]指导了如何通过指定标签生成数据;InfoGAN[11]通过从噪声z 中拆分出结构化的隐含编码的方法,使得生成过程具有一定程度的可控性、可解释性;DCGAN[10]引入CNN 概念,极大增强了GAN 的数据生成质量。
2 算法实现
整个算法流程图如图1 所示。
生成器网络以带有运动模糊的图像做为输入,估计并处理恢复出相应的图像。同时,判别器网络将生成器网络生成的图像与原始清晰图像做为图像对,判断并输出反馈两者之间的差别。
2.1 生成器结构
本工作的生成器借鉴了“U-Net”[24]类似的编码-解码的网络结构,通过跃层连接形式,将不同层次之间的信息共享。在本文的场景中,人脸的图像结构相对固定。对于人脸盲去运动模糊,其中一项任务就是对人脸结构以及背景信息的精准分割。跃层连接通过融合不同尺度的特征信息,可以起到补充信息的作用:在高层补充了语义信息,在底层细化了分割的轮廓,使网络能够更好地适用于高分辨率图像的学习过程,生成更加清晰的图像。此外文献[3]研究指出这种跳级连接能够促使网络的最小化过程更平坦,从而对新的数据敏感度更低,泛化能力更强。同时,为了提升网络的鲁棒性,减轻网络梯度消失的问题,更有效地利用网络特征,加强了特征之间的传递与共享,减少参数量和计算量,同时保证网络效果,本文引入Dense Block[8]的设计,在同层网络之间进行稠密连接。生成器网络结构如图2 所示。

图1 算法流程图
生成器包含4 个跃层结构。每一层网络都会经过两次3×3 的卷机操作,卷积后利用Instance Norm 进行归一化,并利用Dense 思想通过Concat 操作进行结合,同时为了快速获取底层信息和恢复图像,引入了最大池化和相应的上采样过程。
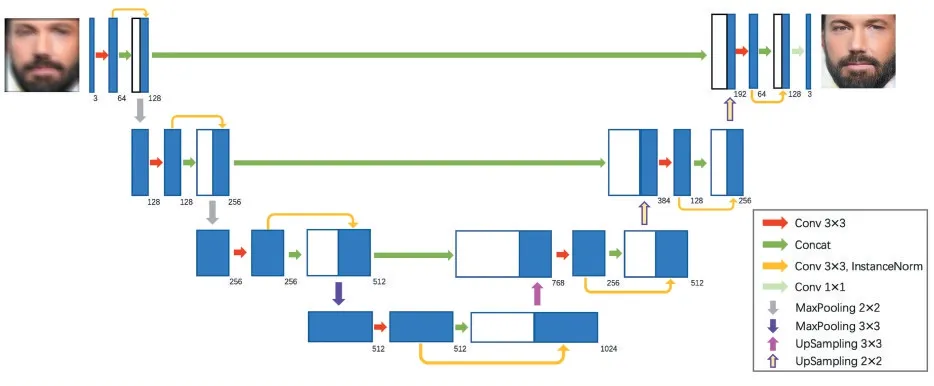
图2 生成器网络结构图
2.2 判别器结构
在对抗博弈思想中,判别器的作用就是区分输入的图像是由生成器生成还是原图。在不断学习强化自身判别能力的同时,给予生产器相应的反馈,帮助生成器生成更加逼真,接近原始状态的图像。原始GAN 的判别器最终得到的是一个判断为整体图像真假概率的二分向量。但是在图像间,尤其是高分辨率图像的转换任务中,为了得到更好的效果,仅使用整体图像真假概率这一信息显然是不够的。因此在本文的工作中,改进了原始GAN 的判别器结构。本文通过引入PatchGAN[16]中对于判别器的改进,将我们工作中的判别器输出调整为一个N×N 的向量矩阵,采用矩阵中的每一个向量可以表示图像局部的信息来代替整体图像的真假概率信息。L1 损失可以使模型学到低频的特征,PatchGAN 的结构可以使模型学到高频的特征,可以更好地恢复人脸的纹理、风格等信息。
2.3 损失函数
在本文工作中,将损失函数表示为对抗损失、内容损失与人脸先验差别的组合:

其中,在本文实验中的λ值设定为100,μ的值设定为1000。本文工作选择了WGAN-GP 做为评价函数,因为其被证实在生成器的结构上更具有鲁棒性。损失函数计算如下:
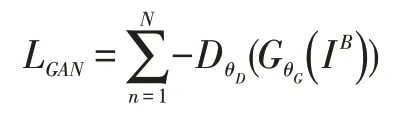
在内容损失上,由于L1 或者MSE 损失函数会造成生成图像出现模糊的假象[23]。本文工作为更好适应清晰化图像的场景,选择了感知损失[9],基于生成图像与目标图像之间的特征图差别。它的定义如下:
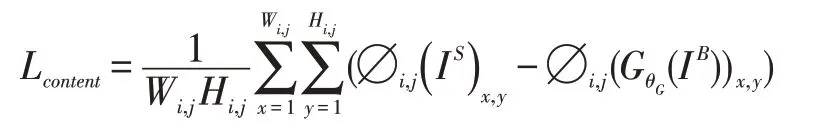
其中∅i,j表示图像特征图,IS,IB表示原始清晰图像和模糊图像。
在人脸先验上,通过利用dlib[4],来计算生成器图像与原始图像人脸之间的特征点差别,并使用欧氏距离绝对值作为衡量。公式如下:

对抗损失侧重于恢复一般内容,内容损失能够更好地恢复纹理信息,加上人脸先验可以更好地定位人脸,适应人脸去运动模糊的场景。
3 网络训练与结果对比
3.1 数据集的处理
相较于其他例如超分辨率和风格迁移的图像到图像转换任务,去运动模糊问题很难得到大量有效的清晰-模糊的图像对用于训练。由于人脸场景运动模糊的公开数据集过少,我们的数据集主要利用开源数据集CelebA[5]筛选出的清晰人脸图像,借鉴文献[6]中的做法,利用Boracchi 和Foi[7]提出的通过马尔科夫随机过程生成随机生运动轨迹的方法,然后对轨迹进行子像素插值法生成模糊核模拟二维空间上的运动。处理后的数据集效果如图3。

图3 原图与运动模糊处理后图像对(a)原始图像;(b)运动模糊处理后的图像
3.2 训练细节
我们使用CPU:Intel Core i7-9897,GPU:NVIDIA RTX2080,内存16G 的硬件平台进行实验。实验训练数据集由5077 对清晰-模糊的图像对组成,另外847张模糊图像作为训练过程中的验证数据集。所有图像的分辨率为300×300。实验选取Adam 优化器,学习率10-4等超参设置下进行100 轮训练。训练共计用时110 小时。
3.3 实验结果
为了更好地评价算法的有效性,我们使用了峰值信噪这一客观评价指标。峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)经常用于对图像重建质量的评价,可以通过均方误差MSE 进行变形定义。

图4 实验结果图(a)原始图像;(b)运动模糊处理后的图像;(c)通过算法恢复的图像
原图与模糊图像之间的峰值信噪比均值仅17.69,经过本文算法处理后生成的图像在峰值信噪比评价指标上得到了26.79 的平均值,说明算法对于恢复图像质量上效果显著。
4 结语
本文提出了不用预先估计模糊核,利用GAN 对运动模糊图像进行盲去运动模糊的方法。通过加入人脸先验信息,感知损失,修改网络结构等方法得到了拥有盲去运动模糊能力的生成式对抗网络模型。将随机运动模糊的图像作为网络的输入,经网络模型处理可以恢复出清晰的图像。本文通过图像在客观图像质量评价指标下的数值验证了网络的有效性。但是网络仍然存在一些问题:例如网络参数量过大,训练速度缓慢,生成的图像存在明显的规则的色素块等,这些将是接下来需要解决的问题。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
今日农业(2019年15期)2019-01-03 12:11:33
动漫星空(2018年9期)2018-10-26 01:17:14
自动化学报(2017年5期)2017-05-14 06:20:44
探测与控制学报(2015年4期)2015-12-15 15:00:56
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
东南法学(2015年2期)2015-06-05 12:21:36
