
基于贝叶斯分类算法的用户评论数据挖掘系统设计
2021-03-25 04:06:04孙含笑
现代计算机 2021年4期
孙含笑
(汕尾职业技术学院信息工程系,汕尾516600)
0 引言
20 世纪是一个信息爆炸的时代,相比于从前的车马慢的生活,快节奏是这个时代的标志,为了满足时代的发展,电商应用而生。相比于传统的购物方式,网购用户可以足不出户在家“逛商店”,订货不受时间、地点的限制;并且获得大量的商品细节信息,买到当地缺乏的商品等,极大地突破了购物的时间和空间限制。同时,商品销量也因网购获得极大的提升。此外电商平台存储了海量的商品交易信息、用户评价等,从这些海量的数据中采用数据挖掘的方式搜索隐藏于其中信息[1],从而做出相应的调整。例如数据挖掘经典的应用案例,“尿布和啤酒的故事”。朴素贝叶斯作为数据挖掘的十大经典算法,广泛地应用在文本分类面。“朴素”一词的由来在于假设特征之间是相互独立的,即一个特征或者单词出现的可能性与它和其他单词相邻没有关系[2]。简单的理解,给出一段文字,“研表究明,汉字的序顺并不定一能影阅响读,比如你当完看段话后,才发现这里的字全是乱的。”,朴素贝叶斯分类器就是基于这样的原理,将复杂的问题进一步简化,进而对文本分类,并且达到比较好的效果。贝叶斯分类器的实现还依赖于贝叶斯定理[3]:

其中P(H|X)表示给定观测样本X,假设H 成立时的概率;
P(H|X)是后验概率;
P(H)是H 的先验概率;
P(X)是X 的先验概率。
当假设样本具有n 个特征,且假设各个特征相互独立时,式子表述为:

基于贝叶斯分类算法,可以对用户的评论做出文本分类,从不同的分类中可以挖掘出客户对商品的主要关注点,客户对商品的满意度,以及商品的改进点等。相比于传统的客户满意度调查,采用数据挖掘的方式,更容易发现数据的潜在规律,而且节省了人力、物力。
1 研究目的与框架
1.1 研究目的
近年来,随着电子商务的不断发展,电商的竞争力越来越大,为了提升商品的竞争力,商家可谓是百花齐放。挖掘客户的潜在需求,聆听客户的声音显得至关重要。用户的评论当中,蕴含了大量的信息。此次研究以当下最火的化妆品行业为例,近年来女性对于化妆品的期望越来越高,越来越多的女性渴望拥有白净的皮肤,由此市面上各种化妆品层出不穷,对于商家来说竞争也越来越大。本文采用Python 爬取某知名化妆品的用户评论,绘制词云,根据词汇出现的频次,从而找到关于该商品的敏感词汇。利用贝叶斯分类器对用户评论进行类别训练,类别有好评、差评、中评三个类别。对于不同类别的评论分类找到敏感词汇,找到该商品的改善点以及优点,从而提升商品的竞争力。
1.2 研究框架
(1)研究设计的创新点
采用绘制词云的方式,可以方便非专业人士读取有效的信息。将评论内容进行分类,从不同类别的评论里找到敏感词汇,从而精准地找到商品的核心竞争力以及改善点。
(2)研究和试验设计的框架

图1 研究和试验设计框架示意图
2 研究的设计与实现
2.1 爬取数据及数据清洗
登录天猫网站,进行爬取某知名化妆品的现有评论数据。将得到的数据存储在数据库当中。对评论数据进行数据清洗,例如有些用户没有做出评价,系统会默认给出好评,这些评论数据对研究意义不大,因此需要进行清洗。
2.2 提取词频及绘制词云图
对清洗之后的数据,不能直接使用CountVectorizer进行词频统计,因为中文的分词较英文分词有很大的不同,英文里面每个单词都是用空格隔开,使用Count-Vectorizer 进行词频统计有很好的效果,但是处理中文效果却很不理想。因此先利用jieba 分词进行分词处理,但使用jieba 分词在处理过程中发现有一些词汇,例如:“不油腻”、“不暗沉”等词汇,在分词之后是“不”,“油腻”以及“不”,“暗沉”,这样的分词结果显然不是想要的结果,因此在使用jieba 分词进行分词时,自定义字典添加新词汇,从而避免jieba 分词处理过程中的弊端。分词之后利用CountVectorizer 进行词频统计,在特征词汇中发现一些无用词汇,例如:“一下”,“一下子”等,因此需要去除停用词,并利用WordCloud 绘制词云图。程序中的关键代码如下:


绘制的词云图如图2。

图2 词云图
由图2 词云图可以得到一些有效的信息,字体的大小和词汇出现的频次成正比。大部分用户对该商品体验不错,感到很满意。客户关注该商品的重点是,吸收效果、保湿效果、味道、滋润度、包装、活动优惠力度、美白效果、清爽度。
2.3 建立贝叶斯分类模型
通过绘制词云,可以看到客户对商品的整体评价以及客户对商品的关注点。对于该电商来说,不仅仅需要上述信息,还需要从客户的评价中找到商品的宣传点、核心竞争力以及商品所存在的问题。贝叶斯分类器对于文本分类问题具有较好的分类效果,因此构建贝叶斯分类器模型,将商品评论分为好评、差评、以及中评,现有的评论分类比例为:好评:差评:中评=177:1.2:1,因此大部分客户对该商品比较满意,并从现有的分类结果对模型进行训练以及评估,训练集和测试集的比例为:3:1,模型训练的结果为:训练集的得分0.999611046285492,测试集的分值为测试集的得分1.0,具有较好的分类结果。
利用贝叶斯分类器测试集的评分如表1 所示,由表1 的结果可知,差评和中评的准确率和召回率都为1,因此我们所构建的模型能够准确地对评论进行正确分类。通过构建贝叶斯分类器,可以快速将评论数据进行分类,进而能够准确地在不同类别中寻找敏感词汇。

表1 模型分类评价表
2.4 提取各个类别的敏感词汇
提取评论中好评、差评、中评中的高频词汇,如表2所示。

表2 高频词汇分类表
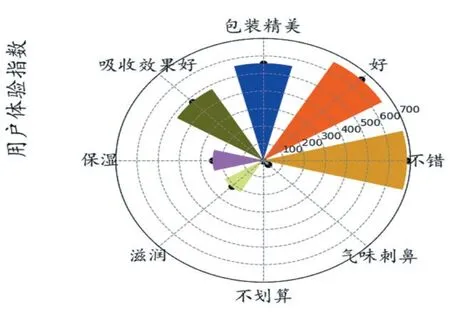
图3 高频词汇雷达图
通过表2 可以获得高频词汇雷达图(如图3 所示)。从不同类别中提取高频词汇可以看到,商品的特点有:保湿效果好、质地不错、滋润度好、清爽不油腻,包装精美、味道好闻,具有美白效果好,受到90%以上的用户喜爱。从差评中提取的高频词汇可知,首先是客户对商品是否是正品存在质疑以及味道刺鼻等问题,另外商品在双十一活动中存在一些问题,客服态度以及赠送的小样没有达到部分顾客的满意度。从中评中提取的高频词汇可知,商品整体评价不错,但是没有赠品问题以及价格不划算拉低了用户体验。
接下来我们来分析主要的消费群体,如表3 所示。

表3 消费群体分类表
除了大部分女性消费群体,一些男士也会买给自己的女朋友和老婆。因此可以将一些年轻的男士也作为重点推广客户。
接下来我们来分析消费群体的肤质特征,如表4所示。

表4 消费群体肤质分类表
由上述结果可知,该护肤品适合所有的肤质,不同肤质的用户体验都不错。对于敏感肌和痘肌的用户也有不错的体验。
从上述分析来看,大部分客户对商品的满意度高。从少部分的客户评价来看,商品本身可能存在气味刺鼻的问题,但是这个问题也存在质疑,因为从大部分客户的评价来看,商品气味没有问题,气味有淡淡的清香。因此商家可以通过样本测试或者市场调研来解决这个问题。此外,从获取的评论数据中可知,商家的赠品比较少,打折力度不够,也是拉低用户体验的原因,因此商家可以在一些大型的电商促销活动中,例如双十一和双十二等节日中加大打折力度或者赠送样品来回馈顾客。
3 结语
本文基于通过Python 爬取某知名化妆品的用户评论,通过对数据清洗、词频统计以及绘制词云图,分析得到客户对商品的用户体验,以及客户对该商品的主要关注点。接下来为了更好地得到用户评价潜在的信息,对评论数据进行分类,分成中评、差评、好评,并构建贝叶斯分类器模型,进行模型训练及评估。由结果可知,训练集和测试集的准确率都基本达到100%,各个类别的查准率和查全率也达到100%,因此能够准确地识别出差评以及中评,表明构建的模型有很好的效果。接着对各个类别分别提取敏感词汇,找到商品的核心竞争力和商品存在的问题。研究实验表明,该研究易读性强,成本低,具有潜在的商业应用价值。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
数理化解题研究(2017年4期)2017-05-04 04:07:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
铁道通信信号(2016年6期)2016-06-01 12:10:20
新校长(2016年8期)2016-01-10 06:43:59
电子器件(2015年5期)2015-12-29 08:43:15
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
