
基于BLT 方法的样本不平衡分类研究
2021-03-25 04:06:00白新宇
现代计算机 2021年4期
白新宇
(贵州师范大学,贵阳550000)
0 引言
随着大数据时代的来临,生活中无时无刻都在产生着数据,同时也产生了很多不平衡的数据:如癌症数据、网络诈骗数据等。数据集中各类别数量分布不均衡,将导致个别类占支配地位,我们将这种现象称为数据不平衡。不平衡数据集的分类问题在我们的现实生活种随处可见。例如:如癌症的检测,通常人们患癌症的概率是很低的,因此正常人与癌症患者的比例严重不平衡。而现实生活中,大家往往更关心的是数据集中的少数类,对少数类的误分可能造成的损失是十分严重的,如:将癌症患者判别为正常,将会耽误患者的最佳治疗时机。但在不平衡的数据集上进行分类,往往使得多数类分类精度较高,而对于少数的分类效果却很差。对于某些特定的领域而言,通常只关注样本中少数类的分类结果。因此,研究样本数量不平衡的分类方法具有十分重要的意义。
1 相关工作
样本分布不平衡在数据科学中十分常见,主要表现为不同类别间的规模差异较大[1]。Weiss GM 通过实验明确提出,相对平衡的样本分布可以取得更好的分类效果[2]。而传统的分类算法在处理不平衡样本分类问题中,效果表现较差,其主要原因为在分类模型的训练过程中,样本的不平衡分布会导致不同类别的样本被用于训练的次数不均等,往往会使分类结果倾向于多数类[3]。针对样本分布不平衡的分类问题的解决方法可概括为三类[4]:①数据层面的方法;②算法层面的方法;③数据和算法相结合的方法。
数据层面解决数据不平衡问题包括数据过采样和降采样。过采样技术是增加少数类样本的方法,SMOTE(Synthetic Minority Oversampling Technique)[5]和Borderline-SMOTE[6]是常用的两种过采样方法,这两种方法的特点是通过给予真实样本的邻居节点一个随机权重,再结合真实样本来生成新的样本。但由于需要预先确定邻居节点的数量k,因此k 值的选择对结果影响相对较大。和过采样相反,降采样是一种减少多数类来达到样本平衡的方法[7],由于该过程容易丢失重要信息因此实际应用中使用较少。
改变类分布并非是解决类不平衡问题的唯一途径,从算法层面解决数据不平衡问题也行之有效[8]。Boosting[9]是一种集成分类器,可以在每次训练后调整各类的权重,达到更好的学习效果。而后出现了一系列关于Boosting 方法的改进,如:AdaBoost[10]、SMOTEBoost[11]等都在一定程度提高了分类的精准程度。
综合以上两类方法的特点,本文提出了一种对数据进行多次划分,然后逐步分类的学习方法,为了方便描述记为“分支学习树(Branch Learning Tree,BLT)”。
2 研究方法
2.1 数据来源
癌症基因图谱(The Cancer Genome Atlas,TCGA)计划是美国国家癌症研究所和美国人类基因组研究所共同监督的一个项目,同时TCGA 也是目前最大的癌症基因信息数据库之一[12]。本实验使用数据集源于TCGA 平台,由Vesteinn Thorsson 针对TCGA 平台33 种癌症样本进行研究,结合6 种分子平台数据来计算160 种免疫特征间的相关系数[13],通过聚类分析最终得到5 个免疫表达特征,再根据这五种免疫表达特征将所有非血液肿瘤聚类为6 种免疫亚型[14](伤口愈合型、IFN-γ主导型、炎症型,淋巴细胞殆尽型、免疫静默型和TGF-β主导型)。为了方便描述将六种免疫类型记为:C1、C2、C3、C4、C5、C6,六种免疫类型的数量分布如表1 所示。

表1 六种免疫类型数量统计
2.2 BLT
分类模型在不平衡数据集上进行分类任务时,分类效果较差,其根本原因是,在少数类样本上获得的学习机会更少。Boost 算法可以重点关注分类错误的样本,以保证被错分的样本可以获得更多的学习机会。
假设可以在每次分类前将不平衡的数据划分为两个规模相近的子集,再进行多次二分类,便可以减少类别间规模差异较大造成的误分问题。基于此想法,本文设计了一种基于“多次划分”、“逐步分类”的分支学习树结构。首先依据数据集中各个样本的分布构造BLT,再对BLT 中的分类器进行训练,最终实现对所有类的准确分类。
BLT 的构建思想源于数据结构中哈夫曼树,主要构建过程如下:
(1)将每一个类别视为一棵树,将该类别的数量看作其权重。
(2)选择根节点权重最小的两棵树构造成一颗新的树,新树的权值为两个子树权值之和。
(3)将新生成的树代替被选中的两棵树。
重复步骤(2)、(3)直到只有一棵树为止,如此便构造出了BLT,与哈夫曼树不同的是BLT 中的每个分支节点是一个二分类的分类器。
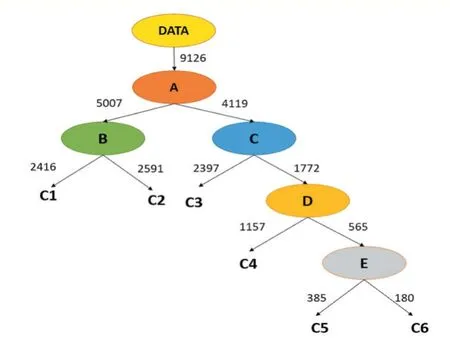
图1 肿瘤免疫亚型数据构建的分支学习树
如图1 所示为由肿瘤的免疫亚型数据所构造的BLT,C1、C2、C3、C4、C5、C6 为待分类样本的类别,A、B、C、D、E 为二分类分类器。将数据集DATA 作为BLT的输入,由BLT 对该数据集进行自顶向下逐步分类。结合表1 观察可知,这样的结构可以优先将多数类进行分类,再逐步对少数类进行分类。因此,在模型的训练过程中,可以保证待分类的两类数据规模相近,同时可以避免某一类别占主导地位情况的出现。对于图1中的分类器,本文分别使用了KNN、SVM、决策树和随机森林等四种传统分类器,详见表2。
3 分析讨论
3.1 评价指标
Micro 是一项宏观的评价指标,通过统计总体数据来计算,将所有的类的True Positive(TP)除以所有类别的TP 与False Positive(FP)的加和。因此micro 方法下的precision 和recall 都等于accuracy。
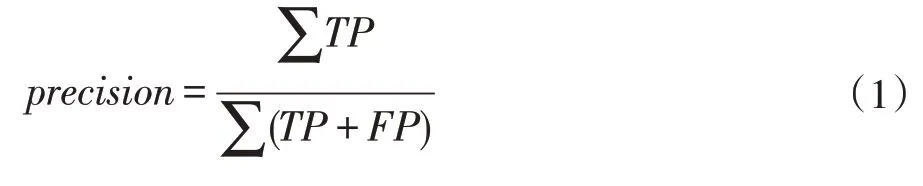
Macro 是一项微观的评价指标,通过统计各个类别数据来计算,分别求出每一个类别的precision 再求其算数平均(公式2 中ClassNum为总类别数)。

Weighted 是一项综合的评价指标,macro 算法是对各类的precision 和取算术平均,weighted 算法是对macro 算法的一种改进,weighted 算法以每个类别的占比为权重,重新计算得到加权precision。

其中,TP 表示正样本被正确的预测为正;FN 表示正样本被错误的预测为负;FP 表示负样本被错误的预测为正;TN 表示负样本被正确的预测为负。
3.2 实验结果分析
本实验所使用的数据集公开于GitHub①https://github.com/bxy123456/Sample-imbalance-Tumor-immune-subtype-data,数据集按照训练集:测试集为4:1 的比例进行划分,如下每一个指标的取值均是五次重复试验得到的平均结果。
表2 整体分为两个部分,其一为由四个传统分类(KNN、SVM、决策树、随机森林)模型的分类结果,其二为由常规分类器作为基本分类单元构成的BLT 的分类结果。对比传统分类器和BLT 的分类结果,BLT 的分类准确率高于常规分类器约1.5%左右,图2 展示了BLT 对分类性能提升的百分比,观察可知,BLT 方法在样本量较少类别性能提升可达11%-79%。分析其主要原因有以下两点:①BLT 可以减少学习过程中各类别样本数量不平衡带来的影响。②BIT 在自上向下分类的过程中,待分类的样本类别数是逐渐减少,因此受到其他类别数据的干扰更少。
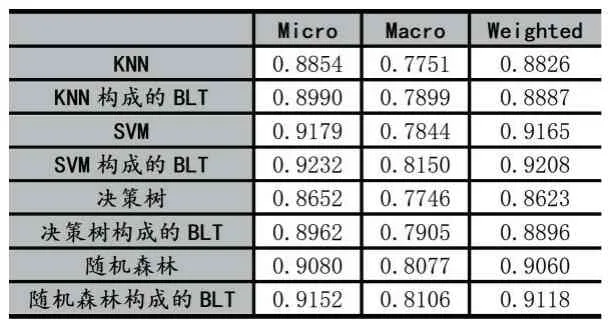
表2 传统分类器与BLT 分类结果对比
4 结语
面向样本数量不平衡的分类问题,本文提出了一种改进传统分类器的方法,并在肿瘤免疫亚型分类的数据进行验证,均使得传统分类器的分类性能有所提高。由于该方法在少数类的分类中取得提升尤为明显,因此可应用一些特殊的应用领域,来解决部分技术难题。尽管本实验取得了不错的效果,但仍有需要探究的方向,主要总结为一下两点:①本文中用于构建BLT 的分类器为同一种分类器,未探究不同分类组合的分类效果。②BLT 树虽然可以减少了样本不平带来的影响,但是不能完全消除,未来的工作可以考虑结合过采样技术来获得更好的效果。
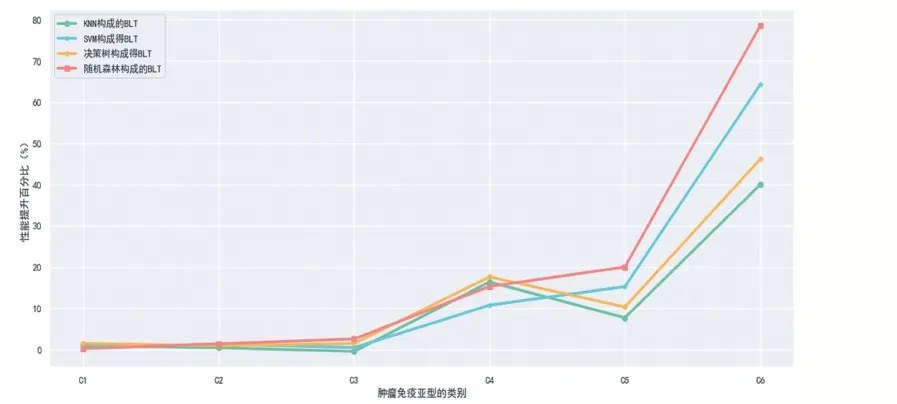
图2 多种BLT分类结果对比
猜你喜欢
家庭医学(下半月)(2020年1期)2020-05-11 02:05:32
海峡姐妹(2018年7期)2018-07-27 02:30:36
特别健康(2018年4期)2018-07-03 00:38:08
特别健康(2018年2期)2018-06-29 06:13:42
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
