
基于BP 神经网络的人口普查收入预测
2021-03-25 04:05:58马晓星
现代计算机 2021年4期
马晓星
(四川大学计算机学院,成都610065)
0 引言
BP(Back Propagation),即反向传播算法,常用于训练前馈神经网络,进行监督式学习。BP 神经网络是近年来应用最广泛的神经网络,常见的神经网络有循环神经网络、卷积神经网络、逆向图网络等。反向传播这一术语在神经网络中广为人知是于1986 年由两位科学家宣布的,之后这一技术被独立发现了很多次,且有很多研究甚至可以追溯到20 世纪60 年代,在结构上分为输入层、隐藏层和输出层。它的基本思想是梯度下降法。在拟合神经网络时,基于梯度搜索技术,通过反向传播计算损失函数及其梯度,调整网络权值使损失下降到最小。BP 算法通过链式法则计算损失函数对每个权值的梯度,从最后一层向前迭代,每次计算一层。
基本的BP 算法包括两个过程。从输入到输出的方向,计算网络误差,从输出到输入的方向,调整网络的权值和阈值。向前传播时,信号从输入端,经过非线性映射到达输出端,若输出信号与预期值的均方差没有达到期待值,则转为误差反向传播过程。反向传播时,误差从输出端开始逐层传递,经过隐含层到达输入端,各层的权值都会以误差为依据得到调整。通过网络权值和阈值的调整,使得误差沿着梯度方向下降,经过反复的训练,直到达到最大迭代次数或误差达到期待值,训练结束。此时的网络参数,即训练好的BP 神经网络模型,若将类似样本作为输入信息,网络经过自行计算,得到预测输出。
BP 神经网络应用非常广泛,于安雷等人[1]使用BP神经网络做软件模型的缺陷预测,郝海霞等人[2]使用PSO 改进的BP 神经网络做函数拟合,陈立君等人[3]使用BP 神经网络做木材纹理分类研究,傅建平等人[4]基于BP 神经网络训练出发动机磨损模式识别模型。林泉等人[5]基于BP 神经网络对心电数据进行压缩,解决了现有的心电数据压缩方法开支较大、难以在实际工程应用中发挥作用等问题。
人口普查由国家出一套统一的标准和规定,对全国现有人口挨家挨户的进行一次全面登记调查。它是当前采集人口信息的一种最基本最科学的方法,其重点是了解当地人口变化和发展、性别占比、出生占比等,是提供人口数据信息的重要来源。本文使用的人口普查数据集来自1994 年,主要调查数据包括年龄、教育程度、工作类别、国籍、性别等多项属性,基于BP神经网络分析主要特征值,预测个人收入是否超过$50K/年。
1 相关研究
1.1 BP神经网络算法原理
神经元是神经网络最基本的单元。图1 给出了神经元的一般模型。BP 神经网络中常用的激活函数有双曲正切函数、阈值函数和s 型函数。

图1 神经元模型
前向传播时,信号从输入层进入,经过隐藏层,到达输出层。神经元的输出为:

神经网络是将多个神经元按一定规则联结在一起而形成的网络,其输入神经元的个数等于输入样本的数据维度,输出神经元个数与等于需要预测的分类数。通常使用的是三层神经网络,即隐藏层的层数为一层。
若为二分类问题,BP 网络使用Sigmoid 作为传递函数,它的特点是函数导数和其本身都是连续的,Sigmoid 函数有多种定义,其单极性函数定义如下:

若为多输出神经元,通常采用Softmax 函数,它是二分类Sigmoid 函数在多分类上的扩展,Softmax 能将多分类结果以概率的方式展示出来。
采用损失函数来衡量输出值和预期值之间的误差,损失函数值越小,代表拟合程度越好,计算公式为:

BP 神经网络采用梯度下降法训练模型,调整网络参数使模型在训练过程中的损失函数值下降到最小。
本文使用一个隐含层,其节点数基于经验公式确定,公式为:
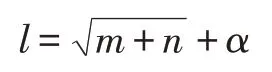
1.2 BP神经网络的缺陷及优化
如果BP 网络的初始权值设置不合适,BP 网络易陷进局部极小值。BP 网络采用梯度下降技术来调整网络的权值和阈值,这使得网络只会“下坡”而不会“爬坡”。基于梯度下降的BP 算法,其固有缺陷难以克服。BP 的梯度下降不能保证能找到误差函数的整体最小值,可能陷入误差曲面的局部极小值后难以冲出。这些参数需要不断地训练才能逐步固定,而过度的训练会造成过拟合现象,即拟合误差减少而预测误差增大。
PSO 粒子群算法是优化BP 神经网络最常见的算法之一。基于PSO 算法来调整BP 神经网络权值的过程是:使用PSO 粒子群算法替换BP 算法中的梯度下降法,优化BP 神经网络模型的权值和阈值,直到其适应度不再有意义地降低。得到初始权值后,再使用BP算法对网络参数进一步迭代优化,得到更精确的解,直到网络参数满足预期误差,即可得到精确的最优权值和阈值组合。PSO 算法与BP 算法的融合主要体现在两个方面,首先PSO 算法中粒子的位置向量对应BP算法的全部连接权值和阈值,PSO 算法通过适应度函数寻找最优位置,也就是在寻找BP 网络的最优权值和阈值。其适应度函数的定义对应于BP 算法均方误差,粒子的适应度采用BP 算法的前向传播来计算。
2 基于BP神经网络的收入预测模型实现
2.1 特征选择
人口普查数据集的数据复杂,数据维度高,为了更好地适应BP 神经网络的训练,需要对数据进行特征选择,尝试剔除数据中的噪声,选择出对于预测模型而言的重要特征。基于随机森林的特征选择能够计算单个变量的特征重要性并对特征进行重要性排序,进而实现从所有特征中选出重要性靠前的特征。
基于随机森林计算特征M 重要性步骤如下:
(1)对每一颗决策树,选取对应的袋外数据(Out Of Bag,OOB)来计算袋外数据误差。袋外数据就是对数据集进行多次抽样得到子数据集,用于训练决策树。剩余没有参与决策树训练的数据用于计算模型的错误率,对决策树进行性能评估,即袋外数据误差err1。
(2)随机改变样本数据的特征值M,即对OOB 所有样本的特征M 随机加入噪声干扰,重新计算其袋外误差err2。
(3)假设随机森林有N 颗数,则特征M 的重要性I 为:

若加入随机噪声后,计算得到OOB 准确率严重下降,则说明特征M 对分类结果影响度很高,即特征M重要程度比较高。
2.2 One-Hot编码
对类别特征,需要进行One-Hot 编码(独热编码),即利用0 和1 表示某些参数,使用N 位状态寄存器来对N 个状态进行编码。例如输出值工资,分为>=50k和<=50k,编码分别表示为[0,1]和[1,0];若特征值婚姻状况分为已婚、未婚、离婚、丧偶,则未婚状态的编码为[0,1,0,0]。独热编码能处理非连续性特征,使得特征矩阵的数据变得稀疏,在一定程度上也起到了扩充特征的作用。

表1
将处理过的数据集按照3:7 分割为测试集和训练集,首先将训练集输入BP 神经网络,经过反复迭代,调整网络权值和阈值,得到收入预测模型。然后将测试集输入预测模型中进行测试,计算网络损失和准确率,最后得到可视化结果。
3 实验结果及分析
神经网络输入神经元个数即特征值在预处理和独热编码后的个数,在本次实验中input_n=95,设输出神经元个数output_n=2,设置训练网络的学习率为0.01,数据集规模为32561 个样本。实验采用的计算机配置如表2。

表2
基于以上实验环境和参数训练BP 神经网络,得到收入预测模型的训练和测试损失如图2。每次批处理的样本规模为64,迭代次数为20,训练损失和测试损失在epoch=10 以前随着迭代次数增加急速下降,当epoch 超过30 时,损失函数开始收敛,实验证明基于BP 神经网络的个人收入预测模型具有较高的收敛速度。

图2 训练和测试损失

图3 分类准确率
神经网络的预测准确率公式如下:

训练得到分类准确率如图3。当epoch>15 时,分类准确率达到百分之百。实验证明基于BP 神经网络的个人收入预测模型具有较高的准确率。
4 结语
本文基于人口普查数据集,训练出了基于BP 神经网络的个人收入预测模型,并经过真实的实验,证明了该模型具有较高的收敛速度和准确率。近年来研究学者们探讨了很多基于BP 神经网络的优化算法,例如将BP 神经网络与遗传算法或PSO 粒子群算法结合,提高了收敛速度,避免其陷入局部极小值。
然而随着数据规模越来越大,BP 神经网络在处理大数据样本时暴露出了较明显的缺陷,例如收敛速度慢,准确率下降等。我们在接下来的工作中,也将聚焦于数据并行化训练算法,研究集成学习算法与BP 神经网络的结合方式,并且基于Hadoop 或Spark 等大数据平台,使BP 神经网络适应大数据场景,表现出更好的训练效果。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
电子制作(2019年19期)2019-11-23 08:42:00
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
自动化学报(2017年7期)2017-04-18 13:41:02
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
