
问答系统中问句分类方法研究综述
2021-03-23 03:44韩东方吐尔地托合提艾斯卡尔艾木都拉
计算机工程与应用 2021年6期
韩东方,吐尔地·托合提,艾斯卡尔·艾木都拉
新疆大学 信息科学与工程学院,乌鲁木齐 830046
用自然语言与用户进行互动的计算机系统称之为问答系统。问答系统(QA)由问句分析、信息检索、答案抽取三部分组成[1],问句分类作为QA的初始环节,其能否正确地对问句进行分类会直接影响到后续的答案抽取环节。另外,问句分类能够对系统提供较为重要的数据信息,这些信息对于帮助用户找到想要的答案至关重要。问句分类对问答系统的重要作用主要表现在两个方面:
(1)根据期望的答案类型来为问句分配相应的标签,这是问句分类的基础,从而缩小候选答案的范围。例如,问句“第一个登上月球的人是谁?”,用户真正想要知道的答案是“阿姆斯特朗”,而不是去检索过多包含“第一”或是“世界”相关内容的资料。在进行问句分类操作后,能够得知这是一个询问人名的问句,答案应与问句的类型相一致,故在答案抽取阶段会把人名以外的候选语句筛除掉,只需要把焦点放在一些和人名有关的答案即可,而无需将过多注意力放在和人名无关的候选答案语句上面。
(2)对于不相同的问句类型,问答系统在后续的操作中也会相应地制定不同的策略,例如,问句“河南的简称是什么?”,问句的答案是和简写类有关,答案抽取的侧重点也应该放在选取针对简写类的策略上。
问句分类能够较为明显地提高问答系统的整体性能,Moldovan等[2]的实验结果表明答案出错是由问句分类不够精准引起的。综上所述,问句分类对于问答系统而言,有着指导性的重要作用,问句分类的准确性会对问答系统造成较为直接的影响。此外,目前对于问句分类进行研究的主要方法通常会借鉴和引用文本分类的某些思想[3],二者的区别之处在于,例如“什么”“是”等常用词在文本分类中常常容易被忽略,但是这些可能作为停用词的字词往往在问句分类中是非常重要的,这也是问句分类的特点之一;二者的共同之处在于都是通过对文本中所含信息进行分析,再结合问句分类的自身特点,从而将问句归纳到所属类别。问答系统的体系结构如图1所示。
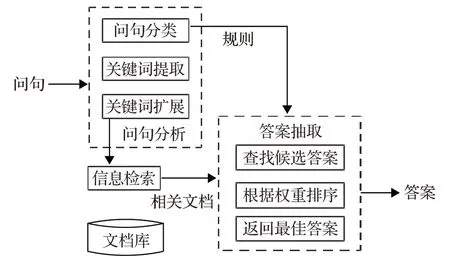
图1 问答系统的体系结构
机器学习在相关领域的成功应用极大地促进了问句分类的发展,基于机器学习的问句分类方法变得更加丰富。在该方法下,研究者会将焦点放在分类模型选择上,以及问句特征的提取上面。随着自然语言处理、机器学习,以及信息检索等相关领域在国际会议和期刊上关于问句分类的相关研究文献的增多[4],研究人员和机构以及专家学者们提出了许多在传统机器学习方法基础上的深度学习方法和模型,许多新的深度学习方法也会在问句分类任务上测试和验证,这很好地说明了问句分类研究对于QA研究人员的重要性,也体现了传统机器学习方法和当下流行的深度学习方法在问句分类任务中的重要应用。
此外,近几年随着QA 相关竞赛的兴起和发展,使得QA 研究领域受到了广泛关注并成为新的热点研究领域。与此同时,有众多新的深度学习的预训练模型提出并不断刷新问答竞赛纪录(如斯坦福问答竞赛等,其主要用到的数据集为SQuAD1.1和SQuAD 2.0),例如,Peters 等[5]在 2018 年提出的 ELMO(Embeddings from Language Models)词向量模型,静态词向量部分替换成了ELMO,并且以双向长短期记忆网络(Long Short Term Memory,LSTM)作为基本的模型组件,将通用的语义作为特征,通过预训练得到后并被迁移到下游NLP(自然语言处理)任务中,再使用现有的SOTA(State-Of-The-Art,当前最佳)模型,使模型性能得到了极大提升,在SQuAD 数据集上的精度达到了 85.8%;Devlin 等[6]在2018年提出了BERT预训练模型,其核心是Transformer模块[7]。Transformer属于seq2seq模型的一种,主要是由encoder 和decoder 两部分构成。此外,还引入了selfattention(自注意力机制),一条问句能够同时关注多个聚焦点,而不必受到序列串行处理的约束,其打破了传统深度学习模型不能够并行计算这一限制条件,同时计算文本序列中两个位置之间的关联所需的操作次数不随文本中距离的增加而增加,BERT 模型还具有更强的可解释性,在多个NLP任务中创下当年的最佳成绩[8],同时在SQuAD 问答集上也刷新了当年的各项径录;Yang等[9]在2019 年提出了XLnet 预训练模型,他们将原有的自回归语言模型(AutoRegressive LM,AR[10])换成了自编码语言模型(AutoEncoder LM,AE[11]),解决了之前遮蔽语言模型(Masked Language Model,MLM)[12]所带来的负面影响和局限性,并且还加入了双流注意力机制和Transformer-XL(在Transformer模型中引入了循环机制和相对位置编码[13]),XLnet 在多个NLP 任务上都优于BERT的表现,并在SQuA2.0上取得了SOTA结果。
1 研究背景及现状
1.1 问句分类体系
问句分类的第一步是要了解问句存在哪些类别,而问句的类别也由所采用的问句分类体系所决定,问句分类的先决条件可以说就是问句分类体系。当前的问句分类体系尚未制定一个统一的标准,大多数研究者采用的是以答案类型为导向的分类体系,该种分类体系具有较易构建、分类粒度较为细致、类别覆盖范围广泛等特点。
如表1[14]所示,国外主要采用UIUC的英文问句分类体系标准。在该分类体系中,问句分为6大类以及50个小类,问句类别由答案所属类型而决定。

表1 UIUC问句分类体系
国内目前仍没有建立一个统一的中文问句分类体系,哈工大的文勖等[15]在国外已有的问句分类标准体系的基础上,以及鉴于汉语较为复杂等特性,制定了一套中文的问句分类体系标准。该问句分类体系共有7 个大的类别,分别是:描述类(DESC)、人物类(HUM)、地点类(LOC)、数字类(NUM)、时间类(TIME)、实体类(OBJ)、未知(UNK),以及60个小类。每个大类都包含了若干个小的类别,如表2所示。
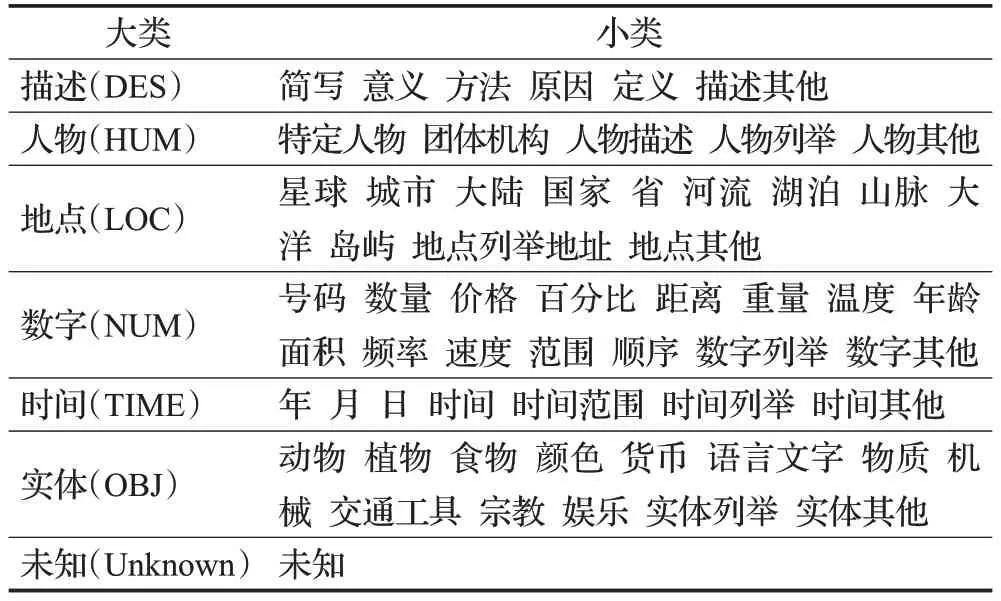
表2 中文问句分类体系
1.2 数据集介绍
在深度学习的研究中数据集是其中尤为重要且不可轻视的环节,QA领域中常用到的数据集如下:
(1)TREC。TREC 英文问句集[16]遵循UIUC 问句分类体系,属于事实类问句。该数据集有TREC-6 和TREC-50 两个版本,分别由6 个大类(ABBR、DESC、ENTY、HU-M、LOC、NUM)和50个小类所组成,训练和测试数据集分别包含了5 452条和500条问句。
(2)SQuAD。SQuAD 问答数据集[17]源于维基百科中用户提出的各种问题,每个问题的答案都来自相应的一段阅读段落,答案和段落中的一句话或者一段文本相对应,SQuAD 有 SQuAD 1.1 和 SQuAD 2.0 两个版本,SQuAD 1.1 包含536 篇文章中的107 785 个问答对,SQuAD 2.0 在前者的基础上添加了50 000 条由人类众包者提供的较难回答的问题。
(3)YahooAns。YahooAns 问答数据集[18]来自于雅虎问答社区上用户所提出的问题,并包含答案信息,共有10 个类别,每个类别的训练和测试样本分别为140 000条和5 000条。
(4)MS MARCO。MS MARCO微软问答数据集[19]的1 010 916个问题由抽取Bing搜索引擎中用户的查询信息所组成,并包含182 669 条人工智能和人为重写的生成式答案,一条问题通常有若干条生成式的答案,因此适用于开发生成式问答系统。该数据集无论是质量还是数量都是当前同类问答数据集中最全面的。
1.3 问句特征抽取
在进行问句分类任务前,先要对数据进行预处理,分别要做“分词”“去除停用词”等工作,然后把句子输出为对应的特征向量,进而通过特征提取方法将问句特征抽取出来。常见的问句提取方法有三种,分别是:词法特征抽取、句法特征抽取、语义特征抽取。
1.3.1 词法特征抽取
词法特征抽取往往只考虑一条问句中出现的单个词,也就是问句中的上下文词汇,不考虑词法、句法、语义等其他因素。
词袋特征(又称为“一元模型”)是较为常用的词法特征,它将问句看作是每个词相互独立的集合[20]。例如,Zhang 等[21]利用词袋模型并结合支持向量机(SVM)对英文问句进行分类,但是由于分类特征较为单一等原因,在TREC10英文问句集上的分类效果一般。一元模型是N元模型(n-gram)的特例,问句中任意连续的N个单词被提取为一个特征称为n-gram特征。
另外一种是基于词的形态特征的词法特征,也就是词形特征。Huang 等[22]将词形特征概括为5 大类:全数字、大写、小写、混合和其他。大多数机器学习方法都使用词法特征进行分类,词法特征易于提取,但分类的性能通常较差。
由于相较于句法和语义两种特征,词法特征更易于提取的特性,词性特征是大部分机器学习方法中会用来进行分类的特征,但是词性特征通常在作为单一特征进行分类的精度并不高,它在与其他不同的类型结合时分类精度会有所提高。
1.3.2 句法特征抽取
句法特征相较于词法和语义两种特征,具有更为丰富且常用疑问代词、中心语块、语法树[23]、问句结构依赖提取特征等特性,句法特征最常用到的两种特征分别是:词性(Part of Speech,POS)和中心词(Headwords,H)。
词性标注依托于句法结构,它是一种从句法结构中抽取的问句句法特征,问句中任一单词都有其词性。句法特征中常见的问句分类特征还有中心词特征,即问句中含有最为关键的信息的词语,问句的目标信息往往也在其中。
中心词的识别准确率会直接影响到分类精度,如Li 等[24]采用浅句法分析和启发式规则提取中心词;此外,Silva 等[14]对该规则进行了调整,使其更适用于提取问句的中心词。但是中心词提取的方法在某些问句中无法凑效,未能有效提取中心词,鉴于此,Silva 等对已有规则进行了补充,称作非平凡规则(non-trivial rules),这些补充规则在通用语法规则前使用,很好地弥补了前面提到的缺陷,中心词提取准确率达到了96.9%。
通过抽取问句的语法结构得到单词的依赖特征,这种句法特征能够较为明显地提高问句分类的精度,但是抽取句法特征往往需要较大的计算代价。
1.3.3 语义特征抽取
在问句分类过程中,有些时候只用词法或是句法特征进行分类效果欠佳,语法特征可以更好地增强问句分类的性能。问句的语义特征通常是通过问句中的词义抽取的,Metzler等[25]采用问句的单词词义作为语义特征进行问句分类。多数语义特征抽取方法通过第三方数据源来提取语义特征,如Sarkani 等[26]使用维基百科(Wikipedia)抽取问句所属类别的语义特征。此外,在语义特征抽取中,WordNet 也是较为常用的工具,基于WordNet词典的语义特征主要有三种,分别是:上位词、关联词、命名实体。上位词因为能够对某类特定单词抽象概括,故能够变成有效的问句分类特征。
为确保所选的上位词对分类有效,Huang 等[27]和Blunsom等[28]选择问句中的中心词用作候选单词来进行扩充上位词。Li等[16]采用单词的上位语义作为问句分类特征,对单词进行词义的抽取;Skowron等[29]将问句中出现的每个名词作为用于上位词扩充的候选单词;Loni等[30]对只使用中心词和使用所有单词的两种上位词特征向量的分类精度进行了对比,实验结果表明,后者由于在特征中引入了过多的噪声导致分类效果较差。
总的来说,上位词提取是一项繁杂的工作,在WordNet当中的多数单词都拥有多个层级结构和上位词,怎样确保在WordNet 中抽取的单词词义和问句中所抽取的单词词义是一致的,这些都是利用上位词进行语义特征提取所面临的问题。
1.4 传统问句分类方法
在过去数十年中,运用机器学习的方法是问句分类研究的主流方法,问句特征提取的好坏是其分类性能的决定性因素[31]。朴素贝叶斯分类算法是由贝叶斯决策理论发展演化而来,它是一种概率分类模型,通常假设特征之间互相独立,在此基础上使用贝叶斯定理,同时假设所要分类的特征项也相互独立。就问句分类而言,问句中的各个单词都是互相独立的。支持向量机(SVM)是二分类模型,通常采用组合若干个这种二分类模型的方法来处理多分类问题。Metzler 等[25]采用径向基核函数和多种特征融合的方法对英文问句进行分类,观察SVM分类模型中不同的核函数对于分类精度的影响[32],还有线性核函数以及不同特征提取情况下的问句分类效率等。和SVM模型相比较,K近邻模型通过构建kd树(K-dimensional tree)来实现其优化算法,但优化以后的效率仍然不是很理想,而且随着数据集的增大其时间复杂度也会变得很大。最大熵(Maximum Entropy model,MaxEnt)是一种基于对数线性的分类模型,与SVM的相比,最大熵模型(ME)可以计算样本属于每个类别的概率,而SVM 只能通过分类超平面将样本分到某一类别。此外,相关研究报告表明,基于最大熵模型的问句分类也可以得到很高的准确率[28]。
上述分类算法在问句分类领域的应用主要是根据问句分类的数据集、人工提取问题的特征,亦或是组合某些特征来对问题进行表示,因此具有较强的主观性,而且具有较为多样性的语言表述,这也就意味着具有较为高昂的手工制定准确的特征提取方法代价。
1.5 基于深度学习的问句分类方法
深度学习技术无疑是机器学习所属分支的一个研究新热点,它在当下成为推动机器学习快速发展的强大力量。其灵感主要来源于人类大脑的一种工作处理方式,通过各种神经网络来处理特征表达的学习过程[33]。深度学习技术的发展大力推动问句分类的相关研究,对于未来问答系统的发展也起到了导向作用。
基于深度学习的问句分类方法有较强的自适应深度学习能力,同时容错率相对较高,对于海量数据处理中的一些较大噪声和复杂的变形也有较高的抵抗能力,此外,较快的数据处理能力也是其主要的优势之一,在问句分类研究中,通常采用深度学习中主动分析和学习隐含在整个问句分类中的词语句法和语义结构特征。近年来,在多个研究领域深度学习技术都受到了广泛的应用,同时取得诸多瞩目的成就。在自然处理领域,也有越来越多的学者和研究人员利用深度学习的方法解决问题,Kim等[34]通过将问句变成词向量并用卷积神经网络(Convolutional Neural Network,CNN)对英文问句进行分类;Kalchbrenner 等[35]构建了一种动态卷积神经网络(Dynamic Convolutional Neural Network,DCNN),在该网络中使用了一种全局kmax池化操作来解决问句长度不一致的问题,并用DCNN网络对问句语义信息进行模拟,取得了较好的问句分类效果;Le 等[36]针对循环神经网络(Recurrent Neural Network,RNN)在问句分类时可能会出现句法成分修改不正确和句法树转换有误等问题,将句法森林作为CNN 网络的输入,并且任意的分支都能够增减,即森林卷积神经网络(Forest Convolutional Network,FCN),对于问句分类任务有着较好的效果;Komninos等[37]研究了词嵌入(Word Emb-edding)对于深层神经网络的影响和作用,研究结果表明基于上下文的词嵌入在问句分类任务中能够取得更佳的分类效果。徐健等[38]采用长短期记忆神经网络(Long Short-Term Memory,LSTM)就中文和英文两种语料构造出了一种双通道的LSTM问句分类模型,通过文本翻译得到更为广泛和深层次的特征,从而增进问句分类的精准度。
1.6 问句分类评价指标
问句分类通常采用准确率、召回率、精确度、均方根误差等评价指标来衡量在特定数据集上分类模型的分类效果。
(1)准确率(Accuracy,Acc),计算公式:

其中,AccNum表示正确分类的问句样本数目,Numtotal表示全部的测试集问句数量。将分类器在分类中预测的类别和实际所属类别一致的样本数量和测试集总的问句数量的比值作为重要的衡量标准。
(2)召回率(Recall),计算公式:
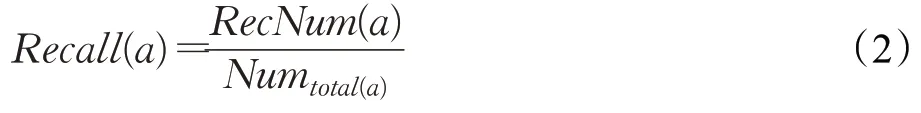
其中,Recall(a)代表a类别的召回率,RecNum(a)表示测试集中样本预测为a类且实际也为a类的样本数量,Numtotal(a)表示测试集中a类数据集的真实数量。a类的召回率是a类别中被正确分类的数据集和a类数据集真实数量的比值,旨在检测该类别的查全率。
(3)精确度(Precision),计算公式:
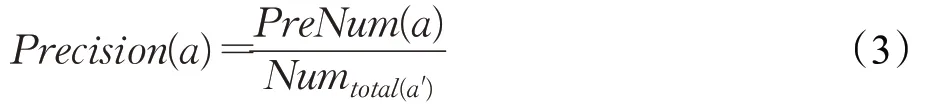
其中,Precision(a)代表a类别的精确度,PreNum(a)代表测试集中样本预测为a类且实际也为a类的样本数量,Numtotal(a′)表示测试集中分类预测为a类的数据集数量。a类的精确度是测试集中样本预测类别与实际类别一致的样本数目和所有预测为a类的样本数目的比值。
(4)均方根差(Root Mean Squared Error,RMSE),计算公式:
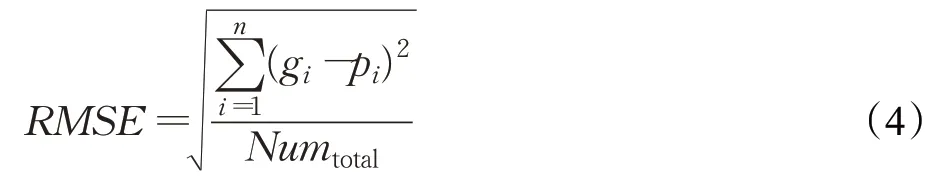
其中,gi是预测类别,pi是真实类别,Numtotal表示全部的测试集问句数目,RMSE 旨在消除gi和pi两者之间的差异。
2 机器学习分类模型
2.1 基于统计的机器学习
基于机器学习的问句分类方法主要分为两大类:基于经验规则的分类方法、基于统计的机器学习分类方法[39]。前一种方法在早期较常见,它主要根据事先设定好的经验规则和模板来判别问句的类别[40]。基于统计的机器学习方法近些年相对比较常用,其具有通用性强、易于移植和扩展等优点。这种方法首先需要提取一些特征向量,问句的类别就由这些特征向量来表示,然后再对已经精确标注过的真实测试问句通过统计和分析学习,从而自动建立分类器,最后用分类器来标注问句所属的类别。基于统计的机器学习分类方法的核心是提取问句的特征向量,分类器的分类精度通常会受到特征向量质量的影响。
当前在问句分类中常用到的基于统计方法的机器学习模型有:贝叶斯模型(Bayes Model)、支持向量机模型(SVM)、K-近邻模型(KNN)、最大熵模型(ME)等。
2.2 贝叶斯模型
在问句分类领域,贝叶斯分类器较为常见,它是一种基于概率学的分类器。贝叶斯分类的基本原理可概述为:计算一个类别的先验概率和问句中单词的概率分布,再对一个类别的先验条件参数概率和词进行分析计算,从而可以得到一个问句的词所属的先验类别条件概率,问句被划分为某类别的概率为后验概率最大的那一类。由于运行速度快、调参少、贝叶斯模型往往用于高纬度的数据集。此外,问句分类能够从贝叶斯模型中获取到快速粗糙的基本方案[41],在实际应用中效果较为不错。
对于问句分类任务,Zhang 等[42]提出的贝叶斯改进模型较为常用,其利用词袋和TFIDF加权的方法对原来的模型进行改进再对问句进行分类。句子和词之间被假设成是互相独立的,即句与词之间词袋关系模型,数学定义的表示方法为:

其中,qc表示问句类型的变量,Q1,Q2,…,Qn代表对问句做分词、去除停用词后的词项数目。对上式做简化,因为分母不变,故只需处理分子:

根据词袋模型,可以把问句简化为:
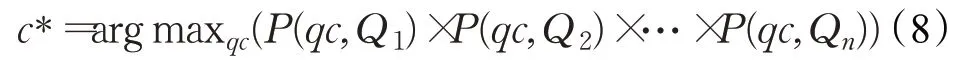
其中
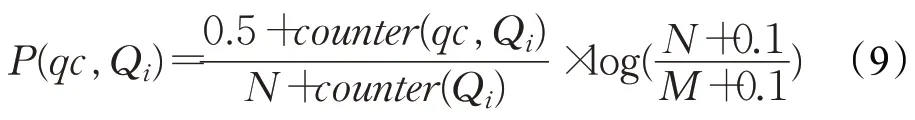
counter(qc,Qi)表示特征Qi在qc这种问句类别中出现的次数;N表示问句类型的总数目,如在TREC问句集中取N=50(小类);counter(Qi)表示特征Qi在训练集中出现的总次数;M表示特征Qi在M种问题类型中出现。由于counter(qc,Qi)有可能等于0,为了避免这种情况,在分子上加入一个常数0.5(调零因子),加入0.1 的理由同上。另外,针对语料库分布不太均匀和汉语的特点,对一些词用TF-IDF加权进行权值处理。
将贝叶斯模型应用于问句分类任务的代表性研究有:Zhang 在文献[21]中以词袋和多元词块作为主要特征并采用贝叶斯模型,在不同规模的英文训练集上做分类,得到的大类分类精度为83.2%,小类分类精度为67.8%;Kocik在文献[43]中提取了问句句首的两个焦点单词并结合问句长度作为特征,通过贝叶斯模型进行分类,大类的分类精度达到了88.6%,小类的分类精度为73.4%;Yadav等[44]分别使用一元、二元、三元单词和多元词性作为特征,采用贝叶斯模型对英文问句做分类,分类效果也较为不错;Arun 等在文献[45]中,通过给定问题中常见的术语一定的权重来计算出特征向量,用朴素贝叶斯对英文问句进行分类,准确率最高达到了92%。对于中文文句分类,Zhang 等在文献[42]中通过改进贝叶斯模型进行问句分类,但是由于只注重单一的词频特征,从而使分类精度不能够得到保障,在有些单一问句类别当中进行分类效果不佳,此外,他们还通过大量使用句法分析的方法,分析和提取问题的基本主干和主要疑问词及其主要附属词的成分来用作贝叶斯模型分类的基本特征,大类准确率为86.62%,小类准确率为71.92%;袁晓洁等在文献[46]中利用分析问题中的疑问词、依存关系、主要的一些动词、中心部分的名词和概念上外延更广的名词作为分类特征,分类精度达到了83.7%;Tian等在文献[47]中用自动学习分类的方法,构造了中心疑问句的词类别和中心词+疑问词类别的两种规则,并用改进贝叶斯模型对中文问句进行分类,分类精度达到了84%;许莉等在文献[48]中利用主干依存句法分析法找出给定问句的各个主干,从语义信息等方面通过分析给出问句中的主干从而准确提取问句特征,最终的分类效果较为理想。
2.3 支持向量机模型
支持向量机(Support Vector Machine,SVM)是二分类模型,它的基本原理是:事先设置好非线性核函数,输入向量映射到高维特征空间上,在该空间中构建一个最优的分类超平面,从而正确地划分开两类样本(训练错误率为0),将两类样本(标记为Y∈{-1,1})的分类空隙变为最大,从而将非线性问题变成一个高维空间中线性可分的问题[49]。鉴于SVM 模型二类分类的特性,通常采用多个二分类器相结合的方法来处理问句分类任务中的多分类问题,较为常见的方法有两种:分别是一对一和一对多,一对多模式效果往往不如一对一组合的模式。SVM决策函数的求解分类器为:
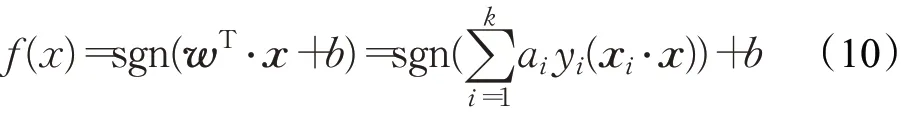
其中ai(i=1,2,…,n)是二次优化问题的全局最优解,如下式所示:
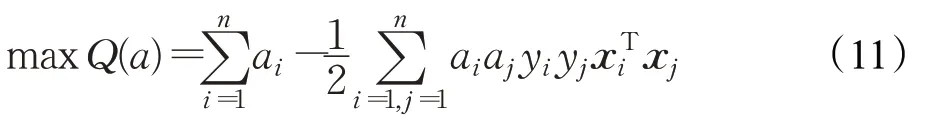
其中

将非线性的问题变为一个在高维空间中线性可分的问题,从而解决线性不可分的这种情况,最后对最优的分类面进行求解,也就是将上面的公式(11)中的xTi xj用一个核函数映射代替从而进行线性变换,在这种映射前往往并不知晓具体的映射函数,而是通过映射一个核函数反过来确定映射函数,这称之为映射核函数的技巧(kernel trick)。
用SVM 模型进行问句分类的代表性研究主要有:Zhang 等在文献[21]中采用树核函数进行特征抽取,将句法结构的分类特征加到里面,在UIUC英文问句集上的分类精度达到了80.2%;Li 等[50]提出了基于错误驱动语言规则分类方法(TBL)并采用了来自WordNet 的英语同义词集、来自名词的上位词概念、来自Minipar的依存关系等语言基础知识作为问句分类方法的特征,在所采用的英文公开问句集上达到了91.4%的分类精度。Silva等在文献[14]中只采用单一的词袋作为分类特征,对UIUC英文问句集做分类,大类准确率为88.8%,小类准确率为80.6%;Duan 等在文献[51]中提出一种可以融合多种语义特征的问题词汇分类的方法,用SVM 模型对中文问句进行了分类,在所用的公开问句集上大类和小类的分类精度分别达到了92.82%和84.45%;Gao 等在文献[52]中通过基本的词汇语法特征问题类别线索词特征以及其绑定特征等,用SVM 模型对中文问句进行分类,大类准确率为94.08%,小类准确率为86.77%。
2.4 K-近邻模型
KNN(K-Nearest Neighbor,KNN)是一种基于实例的分类模型,其基本思想是:将训练集中的每个样本特征化为一个向量,对于测试样本,先通过向量计算分析得出训练向量的夹角余弦值,再用训练集中的样本与该测试样本逐一做相似度计算,通过分析计算两个样本的相似度后就可以确定该测试集中至少有k个相似的样本,相似样本数量最多的类别最终决定测试样本的类别[53]。对于加权KNN 问句分类算法,一个明显改进是对k个最相似的样本的贡献加权,根据其与问句之间的距离,将较大的权值赋给较近的,最后选取权值最大的类别作为测试样本的类别。数学形式可表示为:
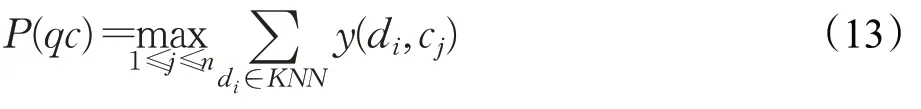
其中,qc为测试类别问句,n为总的问句个数,y(di,cj)为每个测试问句类别中所有属性的取值函数,最近邻的K个问句为di,若cj包含di类,取值即为1,反之为0。
将KNN 模型应用于问句分类的代表性研究主要有:Lee等在文献[21]中以词袋和词块(包括问句中所有连续的单词序列)为主要特征,在UIUC10 英文问句集上进行分类,大类准确率为75.6%,小类准确率为68.6%;Sundblad 在文献[54]中将词袋作为分类特征在TREC10英文问句集做分类,大类分类精度为67.2%,小类分类精度为60.0%;Jia等在文献[55]中利用知网(HowNet)义原树的方法计算中文问句间的语义相似度,再通过计算得到的语义相似值作问句间的距离矢量,结合KNN 模型进行分类,在TREC2004基础上改编的英文问句集上达到89.8%的分类精度。
2.5 最大熵模型
最大熵(Maximum Entropy,ME)模型是较为成熟的统计模型,已经成功地应用于文本分类、词性标注、组块识别等多个NLP领域的任务上。其基本思想是:承认已知事物并对未知事物不做任何假设,即训练数据中的部分已知条件被模型所掌握时,它所估计的概率分布应该尽可能地接近均匀分布,即具有最大的熵[56]。
对于问句样本集合T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi(0 <i<n+1)表示一个问句的词、语义等特征信息,yi(0 <i<n+1)表示问句所对应的类别。在给定问句样本和与之相对应的约束条件后,存在一个唯一的概率模型P(y|x),它的熵取值是最大的,数学形式可表示为:

其中,fi通常认为是一个函数模型中的特征函数,被取出的值一般为0或1。λi通常为一个特征模型中的特征参数,它代表fi对于模型的影响程度,x如果已经给定,Z(x)则表示为泛化常数。式(14)、式(15)中参数值λi的求解通常采用Darroch和Ratcliff这两种估计方法,二者皆为通用迭代算法(Generalized Iterative Scaling,GIS)[57]。
将最大熵模型应用于问句分类的代表性研究主要有:Kocik 在文献[43]中将统计学分析方法中较为常用的最大熵模型引入到问句分类任务中,对英文问句中的长度、焦点、命名实体、词块等特征进行抽取,大类准确率为89.8%,小类准确率为85.4%;Nguyen在文献[23]中将频繁子树挖掘(ESPM)的方法应用于问句分类任务中,对英文问句中构建的子树进行分解,分解后的子树信息被提取作为分类的主要特征,再用最大熵模型在TREC 英文问句集上就50 种小的类别做分类,达到了83.6%的分类精度;Thint 等在文献[22]中分别提出以句子的上位词和中心词作为特征,在UIUC英文问句集上分类,大类准确率为93.6%,小类准确率为89.0%;孙景广等在文献[58]中提出了以问句中的词汇、句法结构、意向词以及HowNet 中的首义原等作为特征,使用最大熵模型对中文问句进行分类,大类准确率为92.18%,小类准确率为83.86%;李茹等在文献[59]中进行特征模型构建,将一系列基于汉语框架的语义原作为主要分类特征,并用这些语义原来表示每个问句的基本语义结构信息,最后用最大熵模型做分类,大类分类精度达到了91.38%,小类分类精度达到了83.20%。
2.6 机器学习分类模型对比
上面对机器学习问句分类模型的基本思想和相关的代表性研究工作做了介绍和分析,表3就模型、机制、时间、精度、优点、缺点等5个方面进行对比和分析。
3 深度学习分类模型
3.1 基于深度学习的问句分类模型
做为机器学习技术研究新的发展热点,深度学习技术主要是利用模仿人类大脑的机制对解决问题的可能性和各种方法进行了分析和学习[60]。近年来,在多个科学研究领域,深度学习的方法都已经能够被成功地应用[61]。研究人员通过深度学习的方法可以更有效地分析和处理不同类型的任务,深度学习方法也极大地提高了问句分类的准确性[62]。
深度学习的基本原理可概述为:通过神经网络的架构对数据进行低维到高维的映射操作,抽取特征并得到数据相应的特征表示。对于问句分类任务来说,可以通过借鉴深度学习的核心思想主动分析和学习隐含在问句中的句法和其语义的特征,较深层次分析了问句的语义特征结构并结合优化算法,对问句分类任务中进行特征提取,再对其错误进行纠正从而能够使问句分类更为准确。
3.2 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是一种典型的具有深度数据结构的前馈神经网络,它是一种较为成熟的能够分布式训练的深度学习模型,原始数据通过卷积运算等操作得到较为抽象和更加高层次的表达,简言之其本质就是卷积计算。Kim[34]在2014 年的EMNLP 上发表的论文提出了TextCNN 的方法,在多个数据集上取得了很好的效果。TextCNN旨在将CNN在图像领域中所表现的不俗成绩复制到自然语言处理的下游任务中[63],其在问句分类任务领域也得到了广泛使用。
CNN 由输入层、卷积层、池化层、全连接层以及Softmax层等5层构成。首先,问句输入到输入层,对这些问句进行分词等操作,并通过word2vec 得到每个词相应的词向量,再利用多个滤波器来分析和捕捉每一个句子的语义信息,这些信息是局部性的,接着使用最大池化,保留捕捉到的最重要的特征的最大值,最后在全连接层将所有提取的特征全部连接在一起,并通过Softmax函数输出问句所属类别的概率[64]。卷积神经网络的层级结构如图2所示。

图2 卷积神经网络结构
其中,在卷积层中,若干个卷积核与词向量矩阵进行卷积运算,卷积核的宽度往往与词向量维度一致,高度可调节。卷积操作和词向量序列方向一致,卷积层的一般形式可表示为:

表3 机器学习分类模型对比

其中,⊗表示卷积操作,yj为第j个特征经过的卷积层,g(⋅)表示Sigmoid、Tanh、Relu等常用的激活函数,xi表示i个输入的数据,这i个数据属于输入的问句集合Q,kij为卷积层中第i个输入特征的卷积核权值,它和第j个输出特征的卷积核权值相对应,bj为偏置项。
将CNN 应用于问句分类的相关研究工作主要有:Kim 在文献[34]中提出了卷积神经网络文本分类模型,在TREC英文问句集上对大类进行分类,准确率最高达到了93.6%;Ma等在文献[65]中提出了一种新型的组稀疏卷积神经网络,通过将组稀疏自动编码引入传统的CNN模型中来自然地学习问句从而进行分类,在TREC英文问句集上的大类分类精度达到了94.2%;籍祥在文献[66]中采用分段池化操作并将问句的结构等信息引入,在不同的分段池化层上提取问句中的主要特征并结合dropout,防止模型过拟合并提高其泛化能力,在TREC 英文问句集上进行分类,大类分类精度达到了89.2%;Yang等在文献[67]中提出了双通道卷积方法,一个通道传入字级别的词向量,另外一个通道传入词级别的词向量,并对卷积核进行不同尺寸的设置,最终得到问句中更为深层次的抽象特征,在所采用的中文问句集上的分类效果较为理想。
3.3 长短期记忆网络
长短期记忆网络(Long Short-Term Memory,LSTM)[68]是对循环神经网络(Recurrent Neural Network,RNN)进行改进的更加高级的神经网络。传统RNN在使用后向传播算法进行训练的时候可能会分别面临梯度爆炸和梯度消失等问题,从而在较长的神经元和问句当中只能直接学习到距离当前较近的信息,远距离的当前较近信息难以在问句中捕获得到,而LSTM很好地弥补了这一模型的缺陷[69]。其基本的思想和特点就是:通过在每个神经元上面的信息中添加一个门(gate)的这种方式可以用来有效控制每个神经元中信息的读取和写入。由于每个神经元上的门信息打开时刻和速度可以不同,因此LSTM 既能更有效地在问句中捕获到较远距离的信息和依赖,也能捕获到较近距离的信息和依赖,这种有效的方式还可以更有效地在问句中过滤和去掉较长的问句中一些不重要的信息,去噪的同时还能够大幅度地提高问句的分类精度。LSTM 模型中有三种门控分别是:输入门、遗忘门、输出门,其结构如图3所示[70]。
LSTM 中信息的存储和更新由这些类似全连接层的门控来实现。门控的一般形式可表示为:


图3 长短期记忆网络结构
其中,式(18)为Sigmoid函数,是较为常用的非线性激活函数,它可以把一个实值映射在0~1 的区间内,进而表示出有哪些问句信息通过:当门的输出值为0,表示没有问句信息通过,当输出值为1则表示所有问句信息都可以通过。
将LSTM应用于问句分类的相关研究主要有:Zhou等在文献[71]中,用LSTM模型在TREC数据集上对英文问句进行分类,大类分类准确精度达到了93.2%;Yang等在文献[72]中提出了基于深度长短期记忆网络(DLSTM)的问句分类模型,它是非线性不连续的特征映射,在TREC英文问题集上进行分类,大类的分类精度达到了93.6%;Li 等在文献[60]中用LSTM 模型学习到的词序语义特征在融合了NLPCC2015QA评测问句集、哈工大问句集、复旦大学问句集的中文数据集上进行分类,大类和小类分类精度分别达到91.05%和80.7%;徐健等在文献[41]中对中文和英文两种语料进行翻译得到扩充后的数据集,并用问句和翻译后的文本来当作双语语料中的样本数据,将中文和英文的语料样本分别用问题文本和翻译文本来表示,最后通过双通道LSTM模型用上述特征做分类,中文问句分类精度为86.9%,英文问句分类精度为76.0%。
3.4 注意力机制
注意力机制(Attention Mechanism,简称Attention)是由TREISMAN 和GELADE 在1980 年所提出的一种用于模拟人脑的注意力机制的模型[73],其基本原理可概述为:将Attention 看做是一种可组合函数,并计算出注意力的概率分布,进而突出某个关键输入对输出的影响,也就是一个查询(Query)对一个键值对集合(set of Key-Value pairs)的映射[74]。在问句分类中使用Attention 来关注问句本身,进而从问句中捕捉有效信息,抓住语义等重点信息,它通常仅关注自身,而不使用其他额外信息。Attention的基本形式可表示为:

其中,Q表示输入问句的词向量所组成的矩阵,Q∈Rdn,d代表词向量的维度,n是句子的长度,w是一个训练的参数向量,wn是一个转置,维度w,α,r与d,n,d分别对应,q是用于分类的问句最终的表示形式。模型结构如图4所示[75]。
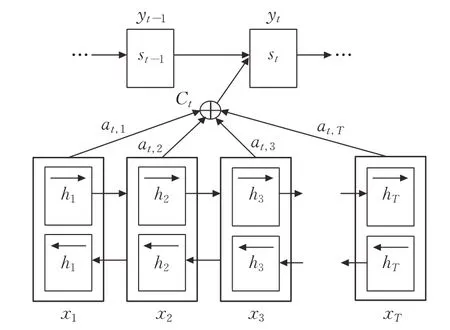
图4 注意力机制结构
将Attention 应用于问句分类的相关研究主要有:Shaw等在文献[76]中提出了一种注意力机制通用框架,对Attention进行建模,在计算每个特征时都用到Attention并结合一个或多个位置mask,将输入向量放在前向和后向Attention中,并将前向Attention和后向Attention得到的结果进行拼接,使用多维度的Self-Attention进行输出,用该模型在TREC 英文问句集上进行分类,大类准确率达到了94.2%;Shi 等在文献[77]中引入Attention机制来提取问句特征,充分利用问句的答案信息来增强问句表示,更加有效地抽取问句中的有效信息并把握语义重点。实验结果表明,引入注意力机制的问句分类方法相较于文中未引入的模型,在YahooAns问句集和CQA问句集上分别提高了4个百分点和7个百分点。
3.5 深度学习问句分类模型对比
上面对深度学习问句分类模型的基本思想和相关的代表性研究工作做了介绍和分析,表4 就模型机制、时间效率、优点、缺点等4个方面进行对比和分析。
4 面临的挑战与未来研究方向
4.1 面临的挑战
对于问句分类而言,面临的最大挑战就是能够有效提取并选择各种问句特征,这对于分类结果的质量具有极大的影响[78]。虽然目前问答系统领域已经有大量对于问句分类的研究,但是大多数的方法都未能很好地处理语义问题,浅层的信息不能充分表达出问句中蕴含的丰富信息,怎样就已有和补充后的信息来理解问句,进而找出问句中最有效的信息是问句分类任务函待解决的问题。鉴于此,如何有效降低数据噪声并拓展、科学地分配权值、加入语法语义规则以及如何高效地获取所需特征都是难点和挑战所在。
4.2 未来的研究方向
问句分类领域涉及到的领域较广,如语料库的建立、数理统计、自然语言处理、机器学习和深度学习等,故仍有较多亟待解决的问题[79],未来研究方向可能如下:
(1)问句集的完善。相较于丰富的英文问句集,中文问句集数量仍有待提高,中文自身的复杂性以及质量和规模都是制约分类精度不如英文问句分类精度高的原因,如Gao 等[80]从论坛或是社区问答中提取问答对,因此,可以通过从一些开放的社区问答搜索或是论坛中,如360问答、百度知道、搜狗问答、豆瓣、猫扑论坛等搜集数据,从而扩充语料。
(2)分类模型的结合。当前对于问句分类的研究中用到的模型大多还比较单一,未来通过结合不同的网络模型并优化,从而更好地提取问句特征并特高分类精度将是主要趋势。
(3)跨领域的应用。正如CNN 一开始是在数字图像处理领域取得了巨大的成功,后来研究人员将CNN引入到文本处理领域,从而让TextCNN在问句分类的发展上起到突出的贡献。未来类似CNN、GCN[81]等不同领域成功应用的深度学习模型方法的借鉴和迁移将会是一种趋势。
(4)统一的分类体系。当下缺乏一种统一的分类体系标准,许多研究中都是根据各自的应用领域来自行定义类别,这极大地阻碍了训练数据的共享。故未来需要制定一个折衷的问句分类体系,从而促进该领域的研究和发展。
(5)预训练模型。近几年,BERT 等预训练模型在NLP各项任务上取得了瞩目成绩,成为了新的研究热点之一[82]。但是,研究人员对于当下这些热门的预训练模型的相关理论和经验性质仍然知之甚少。因此,今后对于预训练模型在问答系统研究领域和问句分类任务中进一步的应用和基础理论的研究和发展将成为未来的一大趋势。
5 结束语
问句分类是问答系统的首要环节,对于后续的答案抽取等工作起到至关重要的作用,问句分类准确性也直接影响到问答系统的性能。本文从问句分类研究背景和现状、问句分类体系、数据集、问句特征抽取、问句的分类模型、模型的优缺点以及相关问题的研究几个主要方面进行阐述,综述了近年来国内外对于问句分类研究的发展情况和进展,并分析了问句分类当前存在的难点以及今后的研究和发展方向,期望能对未来进一步的研究和发展奠定夯实基础。

表4 机器学习分类模型对比
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
新校长(2016年8期)2016-01-10
大连民族大学学报(2015年2期)2015-02-27
商事法论集(2014年1期)2014-06-27
电视技术(2014年19期)2014-03-11
中国中医药现代远程教育(2014年16期)2014-03-01
