
基于DTW 和CNN的仿真驾驶手势识别及交互
2021-03-22 04:26杨尊俭张淑军
重庆理工大学学报(自然科学) 2021年2期
杨尊俭,张淑军
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
手势是非语言交流的重要方式,也是非接触式的人机交互中的重点研究课题。其在各个领域取得了广泛的应用,如汽车自动驾驶过程中需要能够识别交警手势并做出正确响应,基于手势交互的车辆控制[1]、智能教学[2],基于手势的机器人控制[3-4]、3D模型控制等[5]。其中手势的识别速度和精准度是研究和应用的关键。
非接触式交互设备的出现,如Kinect、Leap Motion、HTC VIVE等,推动了基于手势的交互技术的进一步发展。Shotton等[6]从Kinect提供的深度数据中评估出3D关节点的位置,为人体动作识别提供了重要的数据基础。传统的手势识别主要通过数字图像处理的方式对手势进行跟踪、分割等处理,对图像进行分类。以骨架研究分为两大类[7]:一种是将骨架用点来表示,对点的信息进行分析处理;另一种则是将部分骨架表示为刚体片段进行分析[8]。曹国强等[9]使用动态时间规整(dynamic time warping,DTW)与朴素贝叶斯分类(naive bayes classification,NBC)相结合进行模板训练与匹配的方法,对手势进行分类。石祥滨等[10]通过K-均值聚类算法提取视频序列中关键帧的关节点位置和人体刚体部分之间的骨架角度来对动作序列分类。Ju等[11]结合RGB-D颜色空间的最大期望对Kinect捕获的手势进行分割。王鑫等[12]用LE(laplacian eigenmaps)流形学习对Kinect设备获取的人体关节点信息进行降维运算,提取特征。
随着卷积神经网络(convolutional neural networks,CNN)的提出,基于深度学习的识别方法得到了迅速发展。Sanchez-Riera等[13]使用Kinect进行数据采集,利用深度学习方法对手势的运行轨迹进行姿势和方向上的评估。Dardas等[14]对图像进行尺度不变性特征变换特征提取,使用多分类支持向量机(SVM)进行手势识别。
本文以仿真驾驶为背景,提出了一种结合DTW 与深度学习的手势识别技术,使用Kinect进行数据采集,以无人车在城市中行驶为背景,利用Unity进行场景搭建及定义交互事件,构建无人车驾驶仿真交互系统。
1 方法概述
在无人车行驶中,车辆的行进方向与行进速度是研究的关键。车辆需要对交警手势、用户自定义手势等做出及时的反馈,以保证智能化行进。本文提出改进的DTW 算法与卷积神经网络相结合的识别方法应用于无人车驾驶,并通过虚拟现实技术对其进行模拟仿真。系统流程如图1所示。
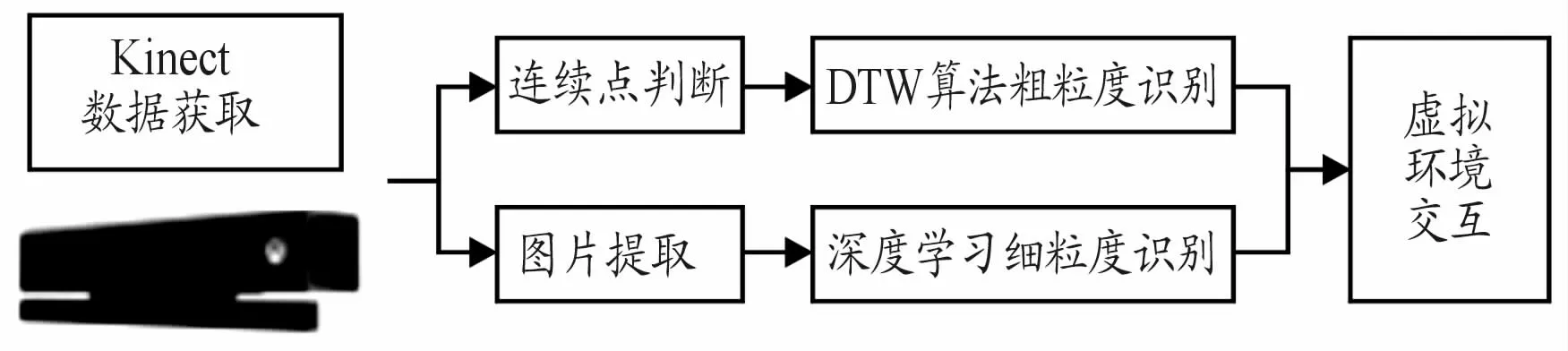
图1 系统流程框图
通常的手势交互以上肢动作为主,识别需要做到实时才具有可用性。同一个人多次做相同手势和不同的人做相同的手势,手势的速度和细节都存在差异,因此,适合使用DTW 算法进行识别。又考虑到在识别过程中,不同关节点贡献率不同,所以本文提出了一种加权的DTW 算法,对手势进行粗粒度识别。由于背景光照、颜色、遮挡等各种客观因素影响,部分手势在RGB图像中比较模糊,使用传统方法稳定性和鲁棒性较差。为此,本文使用基于卷积神经网络的手势识别方法与DTW算法相结合,充分利用Kinect提取的关节点信息对手进行局部聚焦,同时识别上肢粗粒度手势及手部细粒度语义,提高识别的速度与准确率。
本文通过Kinect获取用户的实时图像并进行人体识别获取关节点信息,改进的DTW 算法利用关节点信息进行特征向量的提取和匹配,对手势进行粗粒度识别。基于深度学习的方法使用CNN网络对手势图像进行细粒度识别。在仿真驾驶系统中,粗粒度识别结果决定汽车的行驶方向,细粒度识别结果对行驶速度等进行控制,2种方式同时作用,实现虚拟环境与用户的实时无缝虚实交互。
2 基于K inect的人体关节点提取
Kinect由RGB摄像头获取彩色图像,由红外线发射器和红外摄像机配合获取深度图像。红外线发射器作为光源将结构光打在物体上,形成激光散斑,而红外摄像机作为接收器,对这些激光散斑进行标定,计算得到深度数据,最后使用插值算法得到场景的三维数据。
Kinect获取人体关节点的过程包括3个步骤:前景提取、人体骨骼分类和关节点定位。前景提取通过深度图像上的深度信息,设置相应的阈值提取目标主体和形状。人体骨骼分类用机器学习的算法对提取的形状信息进行训练,训练出决策树分类器依据形状信息来匹配人体的各个部位。最后通过计算来匹配关节点在人体中的位置。
Kinect传感器数据采集标准:Kinect设备水平放置于桌面上,目标面对Kinect传感器,距离为0.8~2.5 m。获取的彩色图像与深度图像分辨率均为640*480,帧频为30 fps。传感器使用的三维坐标为:以Kinect为原点,通过右手定则建立空间坐标系,x轴的正方向为水平向左,y轴的正方向垂直向上,z轴方向为摄像头拍摄方向。三维空间坐标使用(x,y,z)表示,如图2所示。
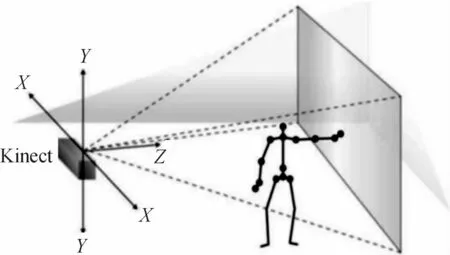
图2 Kinect空间坐标系
通过Shotton等[6]提出的方法从深度图像中提取人体25个关节点,如图3所示。
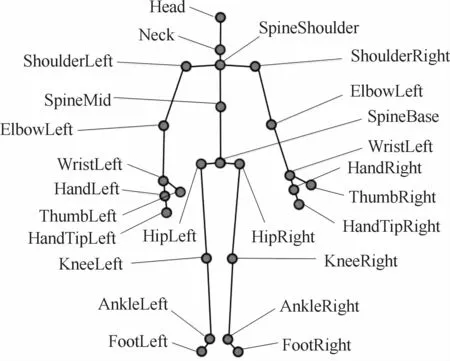
图3 Kinect25个关节点示意图
从图3中可以看出,左右双臂和双手各有不同的关节点,这为后续识别左侧或右侧手势提供了有利的数据支持。
3 基于加权的DTW 算法识别粗粒度手势
3.1 动态时间规整(DTW)
DTW 方法是Sakoe等[15]提出用于判断时间序列相似性的方法。DTW 可以很好地匹配2个不同时间轴上的时序序列之间的匹配代价[16]。
基于DTW 的手势识别主要分为3个步骤:建立样本库、训练样本、识别样本。在识别时首先截取部分手势帧作为测试样本,然后与样本库中的样本进行对比,找出与之最匹配的样本。手势样本库中的样本表示为R={R(1),R(2),…,R(m),…,R(M)},测试样本为T={T(1),T(2),…,T(n),…,T(N)},其中m和n为样本帧的序号,R(m)为第m帧的动作特征矢量,T(n)为第n帧的动作特征矢量,M、N为模板中所包含的动作总帧数。构建一个M×N的矩阵,样本库样本R为横轴,测试样本T为竖轴。将测试动作矢量T(n)映射到样本库动作矢量R(m),这种映射关系表示为(Rm,Tn),计算二者映射后对应的欧几里得距离,对R和T中所有对应项求和:

式中:K表示该帧特征向量的维数;Rmk表示样本库样本的第m帧的第k个特征值;Tnk表示测试样本的第n帧的第k个特征值。D越小说明测试样本T与样本库样本R相似度越大,D越大则相似度越小。
3.2 加权的DTW 方法
动态时间规整默认每个手势的关节点在轨迹上的贡献度是相同的,对样本中的所有关节点使用相同处理标准,而在实际手势中不同关节点的位移变化对手势识别所起的作用并不相同,某些关节点起到决定性作用,因此,本文提出一种改进的DTW 算法,通过对关节点进行加权来进行更优的动态规划,更精准地识别手势。充分考虑各关节在上肢手势中所起的作用,选取颈椎中部(1)、左肩(4)、左肘(5)、左手腕(6)、右肩(8)、右肘(9)、右手腕(10)、颈下脊椎(20)等8个关节(括号中的数字对应图3中的关节点编号)用于连续手势识别,可有效减少运算的复杂度。每一个关节由一个三维坐标表示,因此,一帧骨骼数据可以表示为由8个关节点坐标组成的24维的动作矢量:
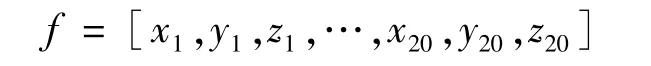
人与摄像头之间的位置以及骨架的大小等都会造成关节坐标的改变,因此需要对关节坐标进行预处理。以人体颈椎关节为原点,将坐标系平移到人体,并以脊柱的距离作为标准,分别对各关节坐标进行标准化,以消除干扰因素的影响,获得较为标准的关节数据。根据中国成年人人体尺寸(GB/T 10000—1988),以双臂平伸站立姿态,左肘(5)、左手腕(6)、右肘(9)、右手腕(10)关节点到颈椎中部(1)、左肩(4)、右肩(8)、颈下脊椎(20)4点中心的距离作为权重标准,如左肘的权重为:
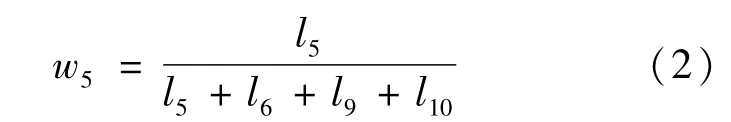
l为关节点到中心的距离,整体匹配代价如式(3)所示:
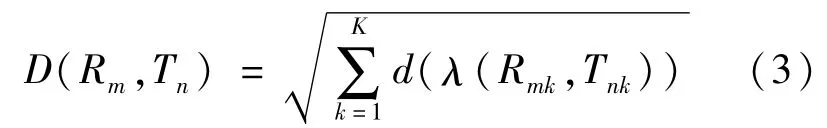
其中λ={wi},通过加权后的手势序列匹配,对大幅度手势动作得到识别结果。
4 基于深度学习方法识别细粒度手势
DTW 算法能够完成2个手势序列的整体匹配,但对于手部的细节动作识别不够准确,为此,本文采用基于深度学习的方法对动态手势中的手部语义进行细粒度识别。深度学习方法已成功应用于图像识别领域,并且具有较好的稳定性和鲁棒性。
4.1 卷积神经网络(CNN)
卷积神经网络(convolutional neural network,CNN)由输入层、卷积层、池化层、全连接层以及输出层组成。一般有若干卷积层与池化层交替设置,卷积层的每个节点通过卷积核与上一层局部信息相连,卷积的结果经过激活函数得到该层特征图;池化层中的每个特征面与上一层的一个特征面对应,对特征信息稀疏处理,获取具有空间不变行的特征;在全连接层中,每个节点与上一层的节点全连接,整合卷积层和池化层中具有区分性的信息;在输出层,通过Softmax分类器处理后的数据按概率返回分类结果。
4.2 手部ROI的计算
要想通过手部动作表达不同的语义,必须要对手部进行准确的定位和识别。传统方法对复杂背景中的手分割和识别效果较差,本文通过Kinect提取的手部关节点来定位手部ROI,使用7层的CNN对手部图像进行识别。
在Kinect获取的25个关节点中,手部的关节点位一共有8个,左右手各4个,分别为腕、手、拇指和指尖,根据这4个关节点与手整体位置之间的关系,4个点的质心即可作为手部ROI的中心点,而ROI的边长设定为人体前臂的长度,以保证手部区域的完整性。人体前臂的长度L可通过手肘到手腕的距离来计算:
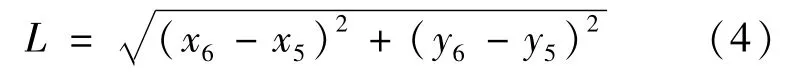
式中,(x5,y5)与(x6,y6)分别表示图3中编号为5的关节点ElbowL以及编号为6的关节点WristL当前帧的坐标值。不同手势情况下手部ROI的部分计算结果如图4所示。

图4 手部ROI的计算结果
4.3 基于CNN对手部ROI进行训练和识别
本文使用的CNN模型分为输入层、卷积层、池化层、全连接层和输出层。对提取的ROI手部图像进行归一化处理,得到90×90大小的图片,将其输入到CNN网络中。归一化尺寸的选取是根据实验中多次采集到图像的统计结果确定的。7层卷积神经网络对输入图像进行特征提取和采样,再送入全连接层,最后通过Softmax函数得到分类结果,如图5所示。
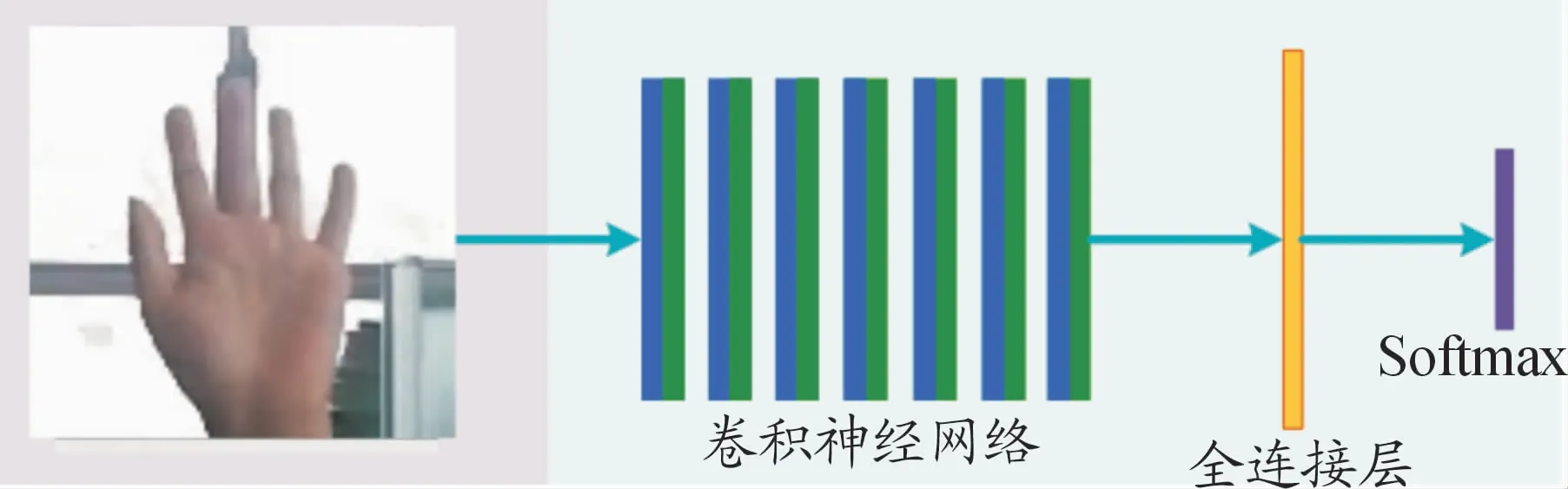
图5 基于CNN进行手势识别的分类结果
5 实验结果与分析
实验环境:采用Unity3.6.1f1建立仿真驾驶环境,使用Kinect采集用户信息,通过手势识别与虚拟环境进行自然交互。软硬件配置如表1所示。
5.1 系统建模与界面
本文使用3DMax创建虚拟环境中的模型,导出为FBX场景文件,并在Unity中导入到Scene中,调整好度量单位、灯光、动画、嵌入媒体以及骨骼几何体等,保证导出的场景中包含所有模型的元素,在Unity-Scene中对模型进行合理布局。
所有的贴图文件在Assets-Material文件夹中保存,FBX等模型文件在Models中保存,在导入好的模型的Inspector视图中通过“Add Component”查找“MeshCollider”,加入网格碰撞功能。
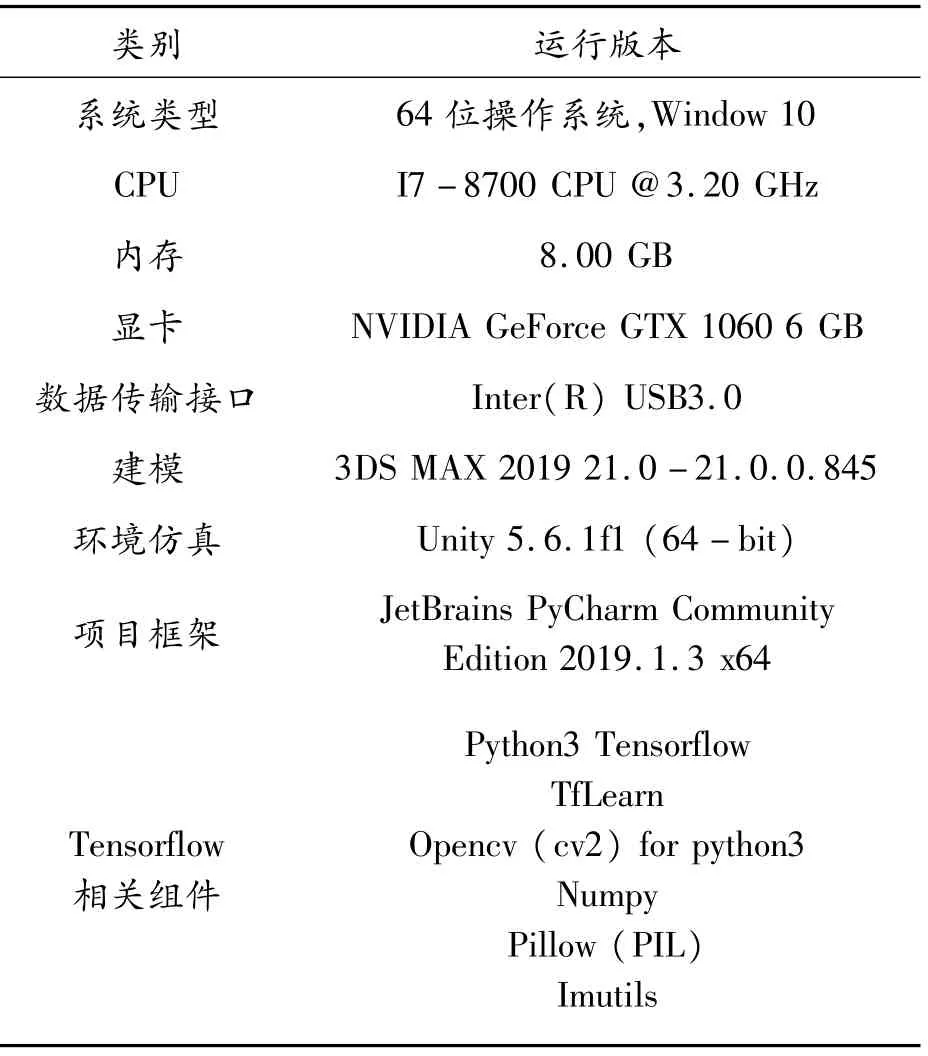
表1 软硬件配置
Unity中车辆与场景模型通过坐标等修改使得轮胎与道路路面接触,设置好车辆动力学特性、重力场、触发器和碰撞器的检测等各项技术参数,让车辆模型能够与场景的物体进行实时检测。
构建了一个包含道路、车辆、交通信号灯、建筑物、树木等在内的虚拟城市场景,系统交互界面如图6所示。
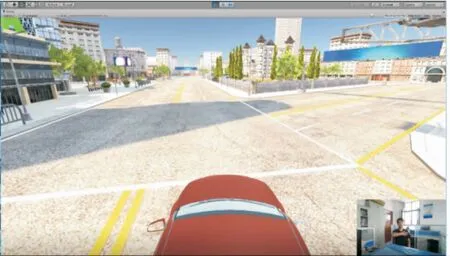
图6 系统交互界面
5.2 手势及交互效果定义
为了在虚拟环境中更好地展现无人车对手势指令的反馈效果,定义5种动态手势,分别控制无人车前进、停止、左转弯、右转弯、后退,同时为了交互控制汽车行驶速度,定义4种模式的手部动作,可以叠加在上述5种手势过程中,构成复合手势,使无人车同时在行驶方向和速度上有相应的反馈。手势名称及动作语义如表2所示。

表2 手势名称及动作语义
表2中,手势1—5由DTW 算法识别,手势6—9由深度学习方法识别,二者组合,得到完整的手势识别结果。手势6—7中,每次识别之后速度按1个标准单位变化。
5.3 关节点数据分析
记录实验数据,以备后续数据分析。手势数据按照关节点X、Y、Z轴分别存储,以便于数据分析。表3给出了TurnRight手势的右手腕关节点(编号为10)的坐标序列值。

表3 TurnRight的右手腕(10)点坐标
由此可见,在TurnRight中,X轴数值逐渐上升,Y、Z轴无明显变化。对于TurnRight,右手腕(10)关节点的X轴坐标影响较大,以此作为赋予权重依据。
5.4 基于深度学习的识别
该识别方法分为离线训练与实时识别2个阶段。离线训练阶段分为2个步骤:
1)数据集
数据集使用马德里自治大学视频处理与理解实验室的HGDs数据集[17],选取其中的4种:手掌张开、手握拳、剪刀手和食指伸出。每种手势200幅图像。每类手势按9∶1的比例分为训练集与测试集,如图7所示。

图7 手势数据集
2)训练网络模型
本网络由7个带有relu层的卷积层与一个全连接层组成,使用softmax作为分类器。加载在ImageNet上预训练的网络模型,在上述手势数据集上进行训练,batch_size=64,迭代次数为2 000次。在测试集上的最终识别准确率为96.6%。存储该训练参数模型用于实时识别阶段。
5.5 手势识别及虚实交互结果
对粗粒度和细粒度手势识别的结果及虚拟车辆的交互反馈效果如图8所示。
图8(a)~(e)分别展示了举起左手配剪刀手动作——汽车减速前进、举起右手配拳头动作——汽车加速后退、手左挥配手掌动作——汽车匀速左转、手右挥配手掌动作——汽车匀速右转、食指动作——后视镜开关变化的交互效果。图中左上角红字为手势识别结果,分别为DTW 算法识别结果(运动行进方向)、当前行驶速度、深度学习方法识别结果(速度或后视镜变化)。

图8 手势识别及交互结果
为了进一步验证本文方法的可行性,对每种手势在仿真系统中测试其识别的精度,每种手势分别测试100次,识别准确率如表4所示。
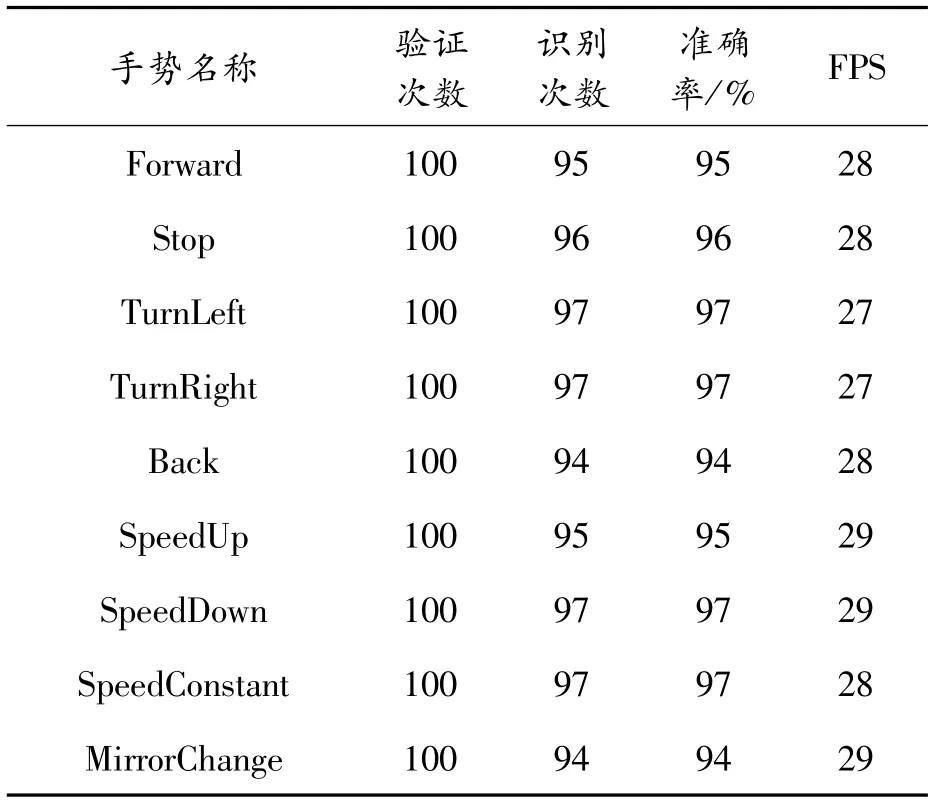
表4 实验结果
实验结果分析:从表4中可以看出SpeedUp和SpeedDown识别较为稳定,手部的左右移动识别较好,手部细粒度识别整体较好,行进方向控制的平均准确率为95.8%,平均FPS为27.6 Hz,行进速度控制平均准确率为95.75%,平均FPS为28.75 Hz,实验表明本文提出的方法在无人车仿真中的有效性。
6 结论
随着社会的进步,智慧城市的发展,汽车智能化与网联化即将到来,无人车自动驾驶是重点研究项目。本文主要面向仿真驾驶场景,将改进的DTW 算法与卷积神经网络方法相结合,对用户的动态与静态复合手势进行实时识别,虚拟车辆根据识别结果进行交互反馈。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
军营文化天地(2017年6期)2017-06-28
小学阅读指南·低年级版(2017年6期)2017-06-12
智能系统学报(2017年1期)2017-06-01
童话世界(2017年11期)2017-05-17
中华皮肤科杂志(2014年4期)2014-12-19
