
基于CNN 和SVM 的人脸识别系统的设计与实现∗
2021-03-22 09:12冯友兵陆轶秋仲伟波
计算机与数字工程 2021年2期
冯友兵 陆轶秋 仲伟波
(江苏科技大学电子信息学院 镇江 212003)
1 引言
人脸识别[1]作为一种生物特征识别技术,是近年来模式识别、图像处理、机器视觉、神经网络以及认知科学等领域研究的热点课题之一。同时人脸识别作为一种稳定性高、精度高、难以复制、易于被人接受的生物特征识别技术,在身份认证、安防监控、人机交互等领域具有广泛的应用前景。随着信息技术的日益革新,人脸识别技术对图像的处理也越来越复杂,在样本充足、背景单一、环境光照稳定的情况下,大部分算法都能取得较高的识别率。
在实际应用中,如何解决环境因素和人脸表情,姿态变换的影响,成为目前检验各类算法的难题。基于特征脸的人脸识别算法通过降维的方式提取人脸特征,虽然降低了计算复杂度,但在降维的同时也会丢失某些有效特征[1]。基于3D 模型的人脸识别算法[2]将采集的人脸还原成三维模型,再与数据库中已知身份人脸的三维数据进行匹配识别,但该算法对图像要求较高、应用性较低。基于稀疏的人脸识别方法[3]通过将所有训练人脸图像映射到一个子空间,然后在子空间中找到测试人脸图像的稀疏表示,该算法在噪声干扰的情况下仍具有较好的性能,但在人脸样本不充足的情况下效果较差。近年来卷积神经网络[4~7]已成为语音分析和图像识别领域的研究热点,尤其在人脸识别领域取得了不俗的成果。卷积神经网络通过结合人脸图像的局部感知区域、共享权重、在空间上来充分利用数据本身包含的局部性等特征,该特征对光照变化、姿态、遮挡具有一定鲁棒性。
本文采用了卷积神经网络构建人脸识别系统,首先使用基于卷积神经网络的facenet 模型[8]提取人脸特征,然后使用SVM 分类器[9]进行分类,并在实际环境中进行测试。
2 卷积神经网络(Convolutional Neural Networks,CNN)
2.1 卷积神经网络结构
CNN 是一个处理输入为二维数据的多层非全连接的神经网络,网络每层有多个二维平面,每个二维平面有多个独立的神经元。神经元之间的连接只存在于相邻层。该网络的底层主要提取图像的纹理、边缘等。底层提取的信息通过神经元连接传递到下一层,逐渐传递到高层进而提取到图像最本质的结构信息。通常情况下网络层数越多网络性能越好。卷积神经网络与一般神经网络区别在于局部连接和权值共享,减少了需要训练的权值数目,从而大大降低了网络模型的学习复杂度。卷积神经网络的基本结构有卷积层,池化层,全连接层。如图1所示。

图1 卷积神经网络结构
1)卷积层
图1 中的C1、C2 为卷积层,卷积层通过一个可以学习的卷积核(图1中conv1,conv2),首先从上一层的特征矩阵中提取出与卷积核相同大小的区域,再将区域中特征值按照顺序与卷积核对应位置的权值相乘之后加上偏置为该片区域的卷积结果,最后按照卷积核的移动步长依次计算其他区域的卷积结果。当卷积完成时,这些结果产生一个新的特征矩阵。

其中*为离散卷积运算符,f(⋅)为激活函数,通常是Sigmoid,如式(2)所示:
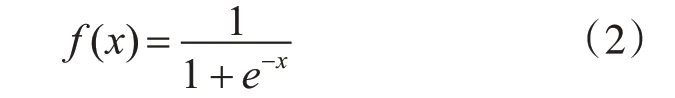
其中x 为输入,f(x)为输出。
2)池化层
图1 中S1、S2 为池化层,池化层通过采样将初级视觉特征筛选并结合成抽象、高级视觉特征。本文池化层采用最大值采样方法,采样大小为2×2,首先将前一层提取的特征矩阵平均分为2×2 大小的矩阵块,再对每个矩阵块取最大值,最后输出一个大小为原来的特征矩阵。采样后有减小计算量和图像移位的影响,整个过程如式(3)所示:
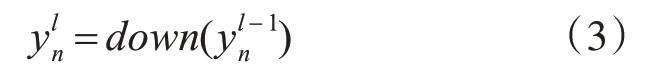
3)全连接层
图1中F1为全连接层,全连接层可增强网络非线性的映射能力,将前一层网络的所有神经元与当前网络的所有神经元互相连接,同层之间的神经元不连接。如式(4)所示:
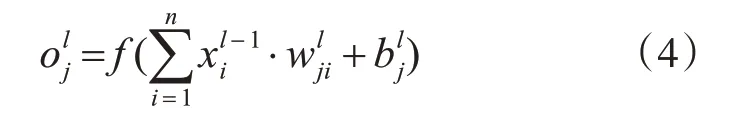
其中l 表示当前网络层数,n 表示为第l-1 层网络的神经元个数,表示为第l-1 层网络第i 个神经元输入值,表示第l 层网络神经元j 与第l-1层网络神经元i 之间的连接权值,表示为第l 层网络神经元j 的偏置,f(⋅)表示为激活函数。
2.2 facenet模型
近年来基于深学习的人脸识别方法普遍使用Softmax[10]损失函数训练网络,从网络中抽取某一层作为输出特征,再使用输出特征向量训练分类器。这种方法的缺点是低效和不直接,输出特征的维度非常大。facenet 是由Google 公司提出的一种新的基于卷积神经网络的人脸识别模型,facenet直接学习到一个从图像到欧式空间的映射,欧式空间的距离关联着人脸相似度。

图2 facenet模型图
facenet 模型图如图2 所示,其中deep architec⁃ture 为卷积神经网络结构,经L2 归一化后,得到特征表示。
3 支持向量机(Support Vector Ma⁃chine,SVM)
SVM 由Cortes 和Vpanik 于1995 年首先提 出,它建立在统计学习理论和结构风险最小原理的基础上,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,来获得最好的泛化能力。
SVM最初是用来对二分类问题进行分类的,在线性可分的情况下,对于训练集(xi,yi),其中xi∈RN,yi∈{-1,1},i=1,2,3,…,n ,目标是找到一个超平面能够将两类样本完全分开且两类间的间隔最大。不妨设超平面的方程为w ⋅x+b=0 ,将w ⋅x+b >0 的归于1 类,而w ⋅x+b <0 的则归于-1类。两类间隔的最大化等价于最小化如式(5)所示:

约束条件:

引入Lagrange乘子a,得到式(7)中的Wolfe对偶形式为
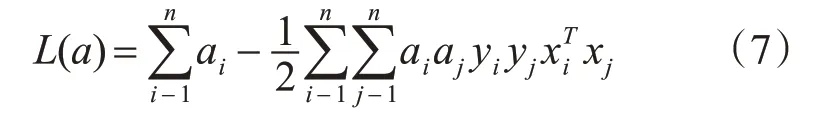
求解得到a 之后,平面参数w 和b 便可以由对偶问题的解a 来确定。由此可以得到SVM 的最优分类函数:

对于非线性问题,SVM分类器则通过非线性变换将低维空间中的非线性分类的样本映射成高维空间中的线性可分样本,然后在映射后的高维空间线性样本中构建最优的分类超平面。其非线性变换是由选择适当的内积函数得到,内积函数称为SVM核函数,即

其中φ:Rn→Rd,表示通过非线性变换从n 维的低维线性空间到d 维的高维线性空间,这样将低维空间的非线性样本转化为高维空间的线性样本,并且把高维空间中的内积运算简化为通过核函数K(xi,xj)来计算。通常使用的核函数有以下几种:
1)线性核函数

2)多项式核函数

3)高斯(RBF)核函数
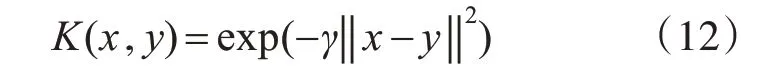
对于多类样本的分类,采用的分类策略是一对一的投票方式,构建SVM 多类分类器。假设训练样本的类别数为n,则在SVM 多类分类器训练阶段创建n(n-1)/2 个分类器。这样把每个类别与其他类别进行对比,求取最优分类平面,然后保存每个SVM二分类器的训练参数即为训练结果。
4 人脸识别系统设计
本文设计的人脸识别系统主要由以下部分组成:人脸识别服务器、客户端、图像采集设备。如图3所示。
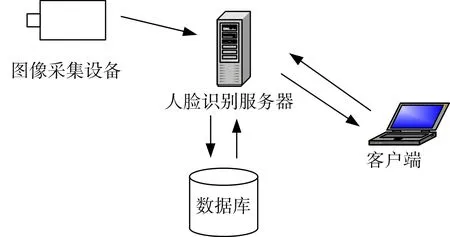
图3 人脸识别系统结构图
人脸识别服务器包含人脸检测模块、人脸识别模块、预训练facenet 模型、数据库等模块。人脸检测模块使用的是opencv[12]图像处理库中人脸检测api 通过提取haar[13]特征检测人脸。人脸识别模块则使用的是开源深度学习框架tensorflow[11]该框架使用图来表示计算任务,这种形式可以高效地构建深层神经网络,且可以在cpu 和gpu 上运行。预训练的facenet 模型则是davidsandberg 基于CA⁃SIA-WebFace[14]数据库训练的,该数据集有9982张图片,预训练的facenet 模型具有很好的泛化性能,在LFW 数据集的准确率为0.98。数据库模块使用mysql 负责存储训练好的SVM 分类器参数以及人脸标签。由于服务器环境搭建需要一定时间,所以本系统在人脸识别服务器开启状态下便加载ten⁃sorflow 框架,gpu 配置以及预训练的facenet 模型到环境中。人脸识别服务器的作用是通过接收图像采集设备发送过来的图片然后根据客户端的请求调用相应模块计算结果返回给客户端。其中核心模块是基于CNN 和SVM 的人脸识别算法,算法描述如下:
步骤1:加载基于CASIA-WebFace数据库训练的facenet 模型,将训练集中所有图片裁剪成160*160的图像块x,并初始化标签向量y。
步骤2:按式(1)、(2)、(3)将图像块x 作为输入到网络中,结合facenet 模型中提取的卷积核、权值、偏置,经过计算得到特征向量为x(1),此时特征提取过程结束。
步骤3:将x(1)输入到SVM 分类器中,SVM 分类器使用线性核函数结合式(7)SVM分类器优化函数如式(13)所示:

其中N 为样本数,ai,aj为引入的Lagrange乘子。
步骤4:使用SMO[15]算法先固定ai,aj求解剩余参数,然后再通过剩余参数求解ai,aj,迭代更新直到函数收敛,所得结果记为平面参数w 和b 便可以由对偶问题的解a*来确定。最后保存SVM 分类器训练结果参数w和b。
步骤5:输入测试图像裁剪成160*160 的图像块,同样通过步骤2提取特征向量。
步骤6:加载步骤4 中保存的SVM 分类器参数w 和b,按式(9)计算最优分类结果。
算法流程如图4所示。
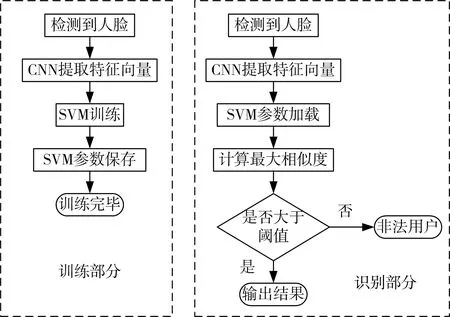
图4 人脸识别系统算法流程图
5 系统测试
在实际应用中,人脸识别系统最大的挑战是存在姿态变化和遮挡时,识别效果不理想。因此本文采集了多类实际应用中的人脸图像作为实验样本。正常人脸样本是在面部基本对齐或小角度倾斜、无遮挡、表情单一,如图5(a)所示。姿态变化的人脸样本有多种表情和侧脸如图5(b)所示。有遮挡人脸样本如图5(c)所示。系统测试中采集4 个人每人40张人脸图片,其中正常人脸样本20张、存在姿态变化人脸10 张、有遮挡人脸10 张。样本尺寸为160×160 像素。系统测试分为以下三种情况:T1 为正常人脸样本训练和测试,T2 为正常人脸样本训练和姿态变化人脸样本测试,T3 为正常人脸样本训练和有遮挡的人脸样本测试。每种情况取不同的训练样本数,测试结果取10次平均值如表1所示。

图5 各种情况的人脸样本
由表1 数据可知,当训练样本只有两张时,各类识别率普遍较低,随着训练样本数量增多,各类识别率都有显著提高。其中识别率上升速度依次是T1、T2、T3,说明遮挡对特征提取影响较大,其次是姿态变化。当训练样本数取到10 时,各类识别率均达到100%,达到预期效果。

表1 不同训练数目在各类情况下的识别率(%)
图6 为系统在实际场景中录取一个下午13:00到14:00 视频的一帧截图,对所有进入图像采集设备区域的人脸进行识别。其中人脸出现次数为125次,所有人脸均能正确识别,识别率为100%,每个人脸的测试平均时间为217ms,完全可以满足一般情况下的人脸识别要求。

图6 视频人脸识别测试图
6 结语
研究并采用了基于facenet 卷积神经网络的特征提取算法以及svm 分类算法,在此基础上设计并实现了人脸识别系统。系统首先在视频流中截取每帧图像进行人脸检测,然后便将检测到的人脸进行识别。实际测试结果表明,系统在训练样本充分的情况下对于人脸姿态、表情、遮挡变化都具有较高的识别率。在人数较少的场所如小型办公室、家庭等,本文所设计的人脸识别系统能满足需求。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
奥秘(2021年5期)2021-06-15
计算机系统应用(2021年2期)2021-02-23
软件导刊(2017年4期)2017-06-20
米娜·女性大世界(2016年8期)2016-08-17
