
基于改进遗传算法的DBN结构自适应学习算法
2021-03-19 05:45孙美婷
计量学报 2021年1期
孙美婷, 刘 彬
(1.北京工业大学 信息学部人工智能与自动化学院,北京 100124;2.燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
1 引 言
动态贝叶斯网络(dynamic dayesian network, DBN)是在静态贝叶斯网络的基础上加上时间属性的约束而形成的具有处理时序数据能力的新的随机模型。DBN在对问题进行研究时充分考虑了时间因素的影响[1]。与静态贝叶斯网络(bayesian network, BN)相比较而言,DBN在处理时序非线性的问题中具有极强大的优势。目前动态贝叶斯网络已经被应用于生产民生等各个方面[1~6]。然而,与BN学习方法类似,DBN也存在着随着研究对象增加而导致候选结构数量呈现指数级增长的问题。因此,在无先验知识下,如何从数据中准确地学习一个与数据样本匹配程度最优的结构模型已经成为DBN结构学习亟待解决的问题之一。
Zoubin Ghahramani等是DBN结构的奠基人,通过将静态贝叶斯网络的研究方法应用到动态贝叶斯网络的学习中,为动态贝叶斯网络的应用奠定基础,但该算法运算次数是节点个数的指数次幂。当节点数量较多时,算法的效率低[7]。为解决NP难问题,研究人员提出2种方案。第1种,基于统计分析法。如冷翠平等基于变量间的基本依赖关系和依赖分析方法进行DBN结构学习,首先建立变量的关系草图,然后通过条件独立性除去多余的边,利用碰撞识别和条件相对预测能力确定边的方向,但是该算法无法动态调整结构搜索空间,而导致潜在最优解丢失[8]。第2种,基于评分搜索法,如王飞等给出网络结构编码方案,并设计相应的遗传算子,得到EGA-DBN算法,然而变异概率和交叉概率无法自适应地动态调整,使得算法易陷入局部最优[9]。贾海洋等利用免疫算法改进EGA-DBN算法,但未对搜索空间进行约束,造成运行时间长,收敛速度慢[10]。
针对上述问题,将最大互信(maximum mutual information, MMI)与遗传算(genetic aAlgorithm, GA)[11~13]相结合,提出基于改进遗传算法的DBN自适应学习算法(DBN structure adaptive learning algorithm based on improved genetic algorithm with missing data, IMGA-DBN)。该算法首先计算最大互信息和时序互信息分别构建初始先验网和转移网,限制DBN结构的搜索空间,完成结构搜索空间的初始化。同时,在GA迭代寻优过程迭代寻优中引入评分标准差构建交叉概率和变异概率的自适应调节函数,提高GA全局搜索能力。为DBN结构的建立提供了一种新思路。
2 问题定义
根据BN的基本原理,假设存在随机变量集X={X1,X2,…,Xn},Xi表示BN图中对应的节点,Pa(Xi)表示节点Xi的父节点集,Xi[t]表示t时刻的节点Xi。对于BN可定义为BN=(G,θ),其中G是变量集X上联合概率分布的有向无环图,θ表示网络参数。因此变量集X上联合概率分布定义为:
(1)
由于DBN是BN在时间序列上的展开,因此需要将BN模型的表述扩展为包含时间因素的随机过程,假设马尔科夫性和平稳性将该复杂系统简化为2部分组成,如图1所示。

图1 DBN表示图
3 IMGA-DBN算法
IMGA-DBN描述为{F,Pc,Pm,δ,λ,Pint,τ},其中F表示适应度函数,Pc,Pm分别表示交叉概率和变异概率,λ表示群体规模,Pinit表示初始群体,τ表示算法的终止条件,δ表示概率阈值。
3.1 互信息和时序互信息构建初始网络
3.1.1 互信息构建先验初始网络
首先,利用计算机程序产生Nseq个完整的二进制观测序列,第l个序列的长度为Nl,将其作为初始时刻数据,从Nseq中随机选取l个Nl序列(即N=∑lNl个转换实例)
以任意2个随机变量X和Y来说明,互信息I(X;Y)表示为:
(2)
式中:P(X,Y)为变量X和Y的联合概率;P(X)为变量X的概率。由于I(X;Y)≥0,因此分为两种情况:I(X;Y)=0和I(X;Y)>0。当I(X;Y)>0,说明变量X和Y间存在弧但不确定方向,故用无向边X-Y代替,并且I(X;Y)越大,说明变量间的依赖性越强。反之,说明变量X和Y相互独立,不存在相对应的弧[14]。
3.1.2 时间互信息构建初始转移网络
根据DBN的假设,t时刻节点的状态只与t-1时刻节点的状态有关,因此在t-1时刻时,考虑除去节点i和j外其他所有节点状态的条件下,研究Xi(t-1)与Xj(t)的条件独立性。设Yij(t-1)={Xk(t-1),k≠i,j},Xi(t-1)和Xj(t)在Yij(t-1)条件下的条件互信息为:
I(Xi(t-1),Xj(t)/Yij(t-1))=
H(Xj(t),Yij(t-1))+H(Xi(t-1),Yij(t-1))-
H(Xj(t),Xi(t-1),Yij(t-1))-H(Yij(t-1))
(3)
式中:H(X)为离散随机变量X熵[15],对于给定阈值ε>0,若I(Xi(t-1),Xj(t)/Yij(t-1))<ε时,表示节点i和j相互独立,否则称节点i和j是相关的。
3.2 GA算法构建DBN
3.2.1 适应度函数
一个DBN可分解成2个Bayesian网,那么适应度函数需分别进行判断。根据EM算法对缺失数据进行填充,此时利用BIC函数关于每个家族局部结构(一个变量和其所有父亲节点)的独立因式的特点,将BIC评分函数分为2部分,从而分别评价先验网B0和转移网B→。
BIC测度表示为BIC(S:D)=BIC0+BIC→
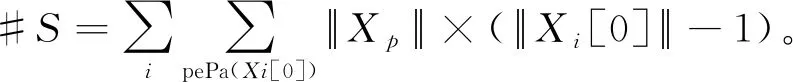
3.2.2 编码先验网和转移网
将DBN结构编码成染色体。由于DBN由2部分组成,则相应染色体可表示为C=(C0,C→)。
首先假定初始先验网初始方向由编号小的节点指向编号大的节点,得到先验网;转移网络初始方向为t-1时刻指向t时刻。通过分别对2个初始结构进行编码。利用图1 DBN表示图说明编码方式:
B0编码:由于B0相当于BN,它是一个有向无环图。设定编码规则:节点标志位为1;小节点序号在前,大序号在后;节点是标识位的父节点代码为1,反之为0。则初始网络B0的代码:
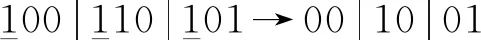
B→编码:t-1时刻的所有节点没有父节点,即只需要编码t时刻的节点。设定编码规则:节点标志位1;t时刻节点在前,t-1时刻节点在后;小节点序号在前,大序号在后;节点是标识位的父节点代码为1,反之为0。转移网络B→的代码:
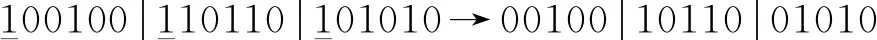
3.2.3 改进自适应遗传算法
利用加边、转边算子对先验网和转移网进行搜索。首先利用BIC(S:D)=BIC0+BIC→计算初始搜索后个体的得分后可知得分基本满足于正态分布。因此分别记录B0,B→结构最高得分Fhigh、平均得分Fav、得分标准差Fstd,将得分高于Fav的个体存放在集合M中。
(4)
(5)
式中:Pc为交叉概率;Pm为变异概率;K为常数;F1,F2为当前个体的得分;δ为设定的阈值;F为由爬山算子初步搜索得到的最佳得分;Fav,Fsed分别为平均得分和得分标准差。根据得分标准差Fstd自动选择交叉方式和变异方式。
对于交叉方式的设定:若整体结构群的评分标准差Fsed≥1.2δ时,说明结构评分离散,应增大交叉概率,所以对当前结构与最高评分结构进行两点交叉;当Fsed≤0.8δ时,说明结构评分集中,所以对当前结构与最高评分结构进行单点交叉。通过此操作可以保证个体优良性不被破坏。
对于变异方式的设定:若整体结构群的评分标准差Fsed≤0.8δ时,说明结构评分集中,应增大变异概率,所以对当前结构进行两点变异;当Fsed≥1.2δ时,对当前结构进行单点变异。图2给出了实例。

图2 交叉变异方法
通过交叉方式和变异方式的操作可以保证个体优良性不被破坏,同时增加了种群的多样性,进而更快地寻找全局最优解。
4 IMGA-DBN算法仿真实验
IMGA-DBN算法的仿真实验分为2个步骤:
第1步,在不同样本量下,4种隐藏变量在3种标准差δ下的网络平均对数损失,验证IMGA-DBN算法的本身有效性。
第2步,以标准动态Asia网络和Water网络为模型,将IMGA-DBN算法与Trabelsi提出的动态最大最小爬山算法(DMMHC)、Mez构建的贪婪算法(GS)、最大支撑树爬山算法(MWST-HC)和最大支撑树贪婪(MWST-GES)进行性能对比,验证本算法的准确度、收敛性和运行时间等性能。
为了检测IMGA-DBN算法的学习效果,分别以动态Asia网络[16],Water网络[17]为标准,构建动态贝叶斯网络。其中Asia网络中含有8个状态变量,10个观察变量,Water网中含有12个状态变量,对应的两时间片网络中共有24个顶点。图3(a)为Asia网络拓扑结构,图3(b)为Water网络转移网络的拓扑结构。
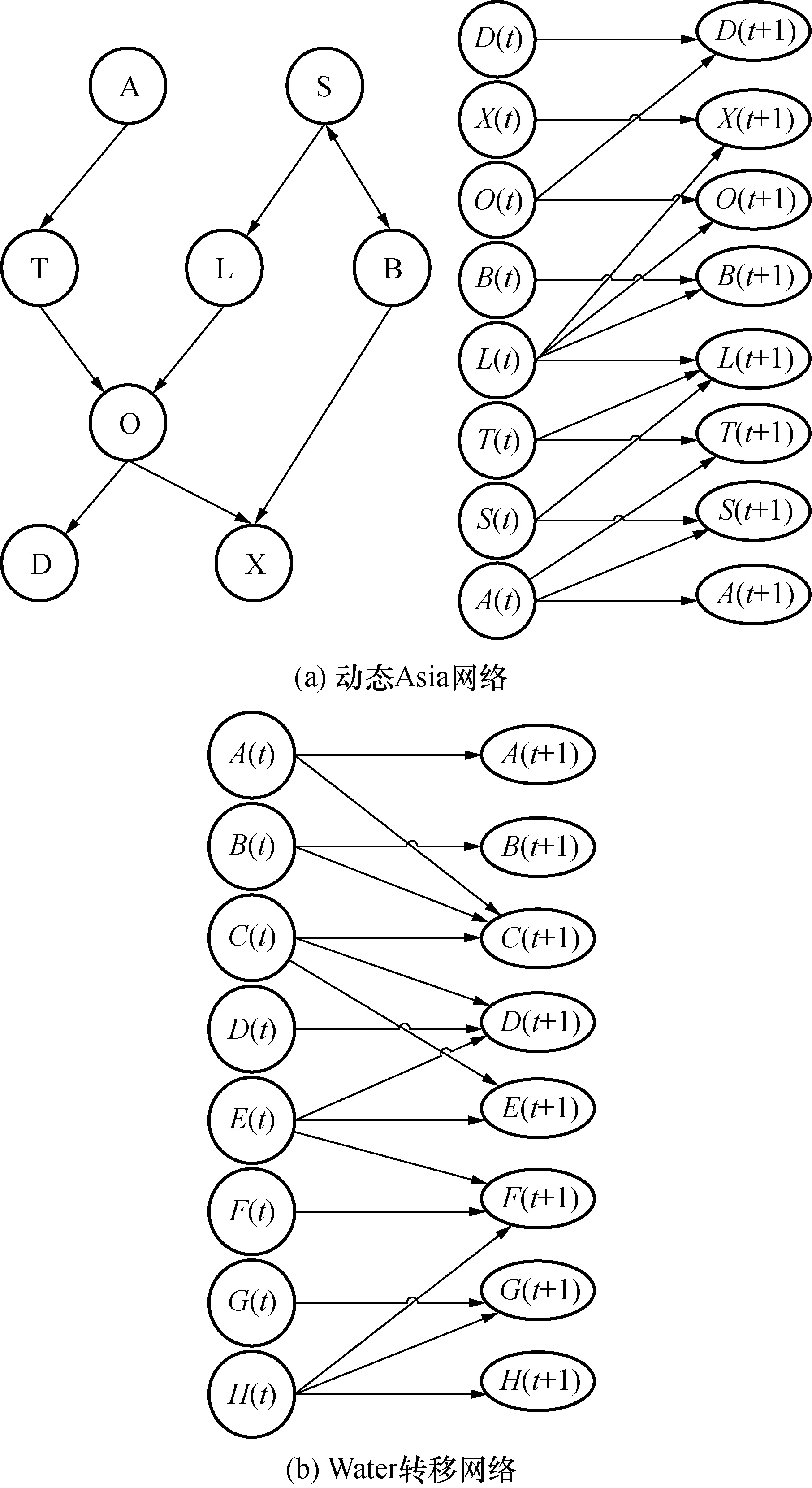
图3 2种标准DBN结构
4.1 仿真实验参数设置
1) 由于DBN中父节点集合的状态个数随着父节点数量的增加呈现指数级增长,为简化算法实现过程,在仿真实验中令每个节点的父节点个数不超过4个。
2) 由于GA的迭代寻优过程具有很强的随机性,为保证对比实验能够充分反映每种算法的性能,迭代优化算法均独立仿真运行30次完成测试。
3) IMGA-DBN参数设置如表1所示。

表1 仿真实验参数设置说明
4.2 算法性能评价指标
1) 隐藏变量个数(HD);
2) 算法获得的最终结构BIC评分(BIC0和BIC→);
3) 算法获得的最终结构与标准模型结构之间的汉明距离(SHD0,SHD→);
4) 算法运行时间(T)平均值和方差;
5) 获得最优解的迭代次数(BG)。
4.3 仿真实验与结果分析
4.3.1 仿真实验1:本算法的有效性
将评分最高的模型作为结果模型,通过计算结果模型反映测试集分布的准确度作为评价指标,验证本算法的有效性。
根据Water网络分别生成含250,500,1 000个序列作为训练数据集,训练数据集中仅包含10个观测变量。对于每一个训练数据集事先分别引入3个、4个、5个和6个隐藏变量记录状态变脸和瞬时变量,每种情形在无先验知识的条件下分别利用IMGA-DBN算法学习30次,选择30次最佳网络结构作为最终结果。此外生成含2 000个序列作为测试数据集。计算每种情形下关于测试数据集的平均对数损失log-loss,即式(6)所示。仿真结果如图4所示。
(6)
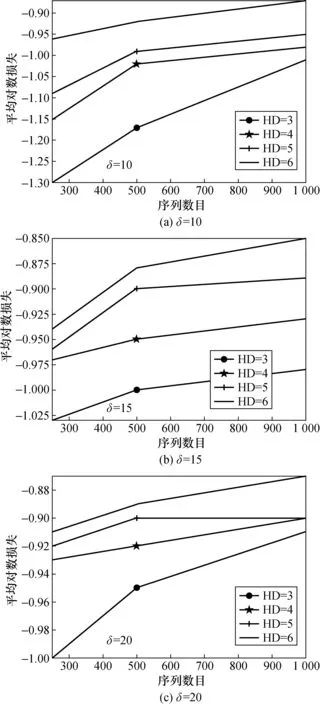
图4 不同隐藏变量(HD)数目的比较
由图4可知:当阈值δ确定时,随着训练序列数目增多,最优结构计算得出的平均对数损失逐渐减少,说明预测结果准确度越来越准确。
综上所述:该实验说明IMGA-DBN算法为解决复杂动态随机过程的学习提供了可行的方法。
4.3.2 仿真实验2:与其他算法的对比分析
利用IMGA-DBN算法与动态最大最小爬山算法(DMMHC)[18]、贪婪算法(GS)[19]、最大支撑树爬山法(MWST-HC)和最大支撑树贪婪(MWST-GES)[20,21]在不同样本数集下分别构建动态Asia网和动态Water网络,在准确度、运行时间、最高评分和收敛性等方面进行对比分析。
4.3.2.1 动态Asia模型仿真实验
以动态Asia网络为标准结构的仿真实验结果如表1所示。表1给出了Asia-1000、Asia-2500、Asia-5000、Asia-10000样本数据集,3种DBN结构算法在准确度、运行时间、最高评分的3个性能指标的平均结果,即表中每种算法的性能指标为15次重复实验的平均值,括号中为数据的标准差。
对表2仿真结果的分析如下:
1) 在15次的独立仿真实验中,IMGA-DBN算法的平均先验网络汉明距离(SHD0)为1.535,平均转移网络汉明距离(SHD→)为3.542 5,在3种算法中是最小的。由于汉明距离表示当前算法所得到的网络与真实网络之间的差异程度,则汉明距离越小表示算法得到的结构越接近标准网络,从而证明IMGA-DBN算法学习获得的结构与标准Asia网络结构的准确度最高。
2) IMGA-DBN算法平均运行时间(T)为217.25 s,比DMMHC算法(376.45 s);GS算法(770.332 5 s)的用时短,表明IMGA-DBN算法的学习效率要优于DMMHC和GS算法。
3) IMGA-DBN算法的平均BIC0为-1 338.78,平均BIC→为-2 519.7,与其他两种算法对比分值低,证明IMGA-DBN算法得到Asia网络更准确。
构建Asia网对比3种结构法在不同样本下的性能。图5表示先验网和转移网的汉明距离。图6表示运行时间。图7表示先验网和转移网的平均BIC评分。
由图5可知:随着数据量的增加,3种算法的汉明距离都呈现下降趋势。但是与DMMHC、GS算法相比,IMGA-DBN算法的汉明距离明显要小于二者,而且随着数据量增加,汉明距离的下降程度越来越大。表明IMGA-DBN算法在4种样本量的情况下,学习得到的最终结构明显优于其他算法。
由图6可知:IMGA-DBN算法的运行时间最短,GS的运行时间略长于DMMHC算法,而且IMGA-DBN的方差较小,说明该算法搜索到了最好的动态贝叶斯网络。
由图7可知:IMGA-DBN算法的先验网和转移网的平均BIC得分均小于DMMHC、GS算法。而且结合图8可知:根据IMGA-DBN的运行时间最短并且最终结构的平均BIC最高的特点,反映出IMGA-DBN的初始种群的较其他算法更优,证明通过计算互信息和时序互信息有效地提高了初始化种群的适应度,并且有效减小了算法的搜索空间。
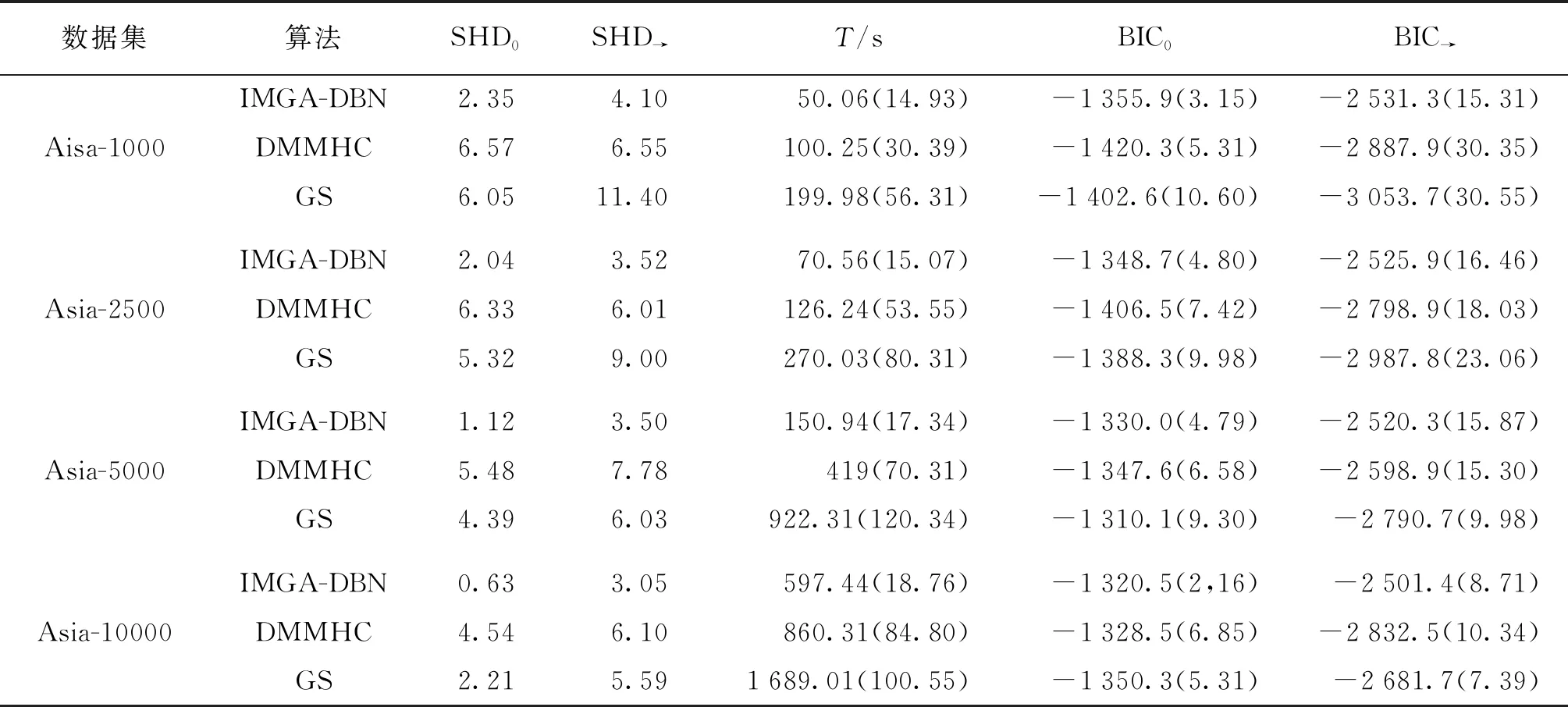
表2 Asia网络在各样本集下不同算法结果对比
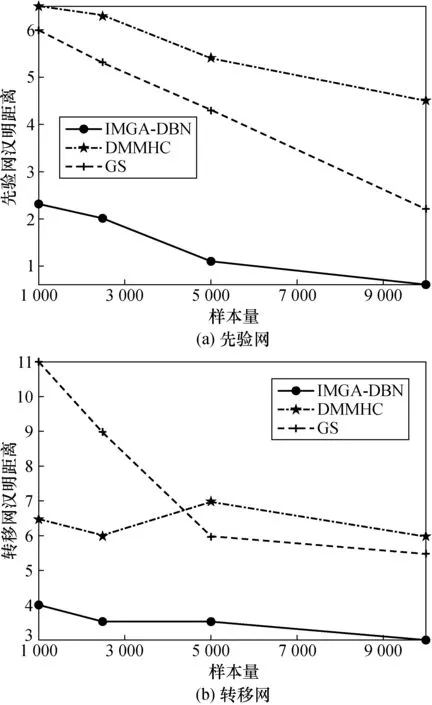
图5 3种算法汉明距离对比
4.3.2.2 动态Water模型仿真实验
以Water模型为标准结构的仿真实验结果如表3所示。表3给出了Water-2000样本数据集下,5种DBN结构学习算法在5个性能指标下的平均结果,即表中每种算法的性能指标值为30次重复实验的平均值,括号中的数据为标准差。
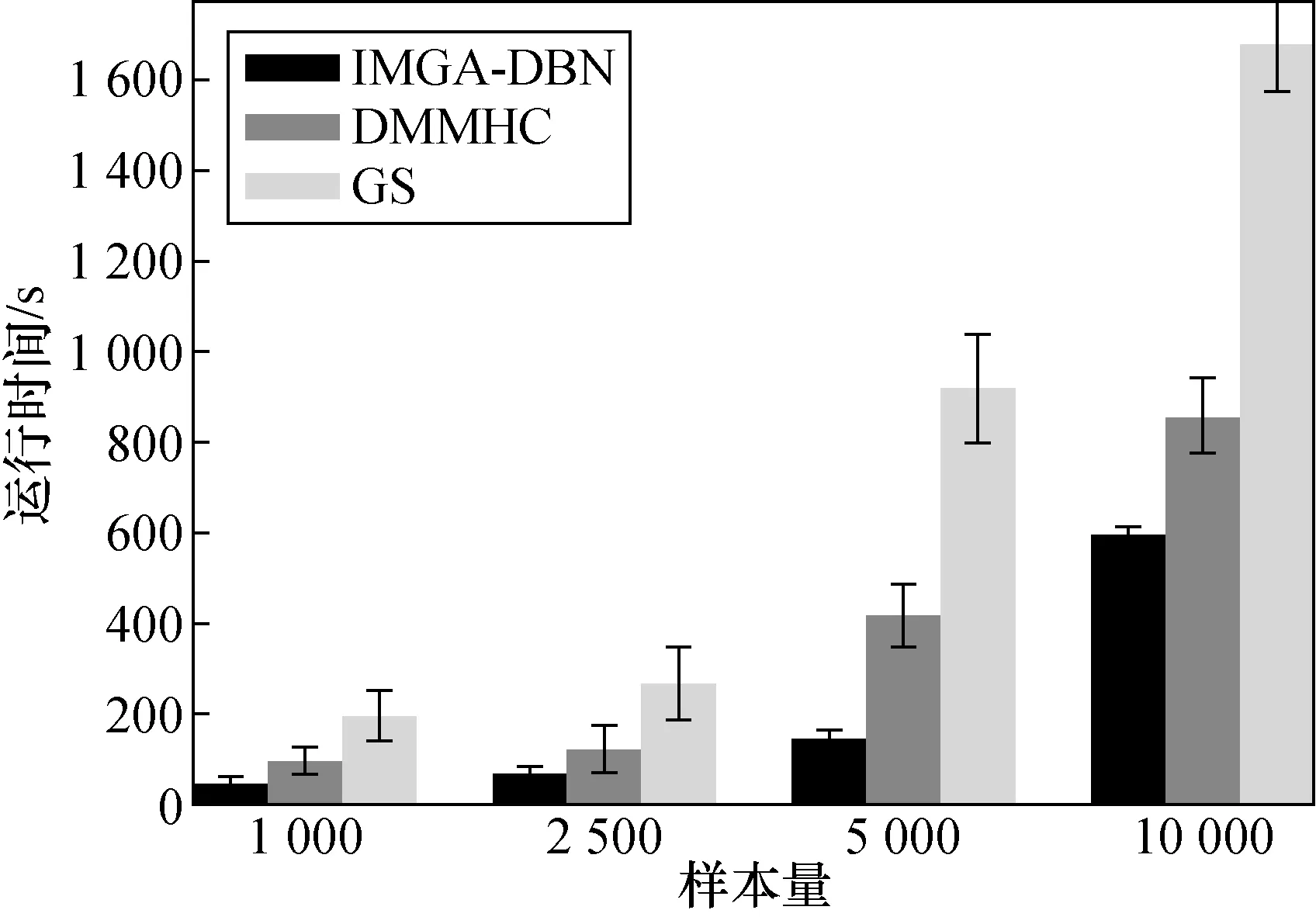
图6 3种算法运行时间对比
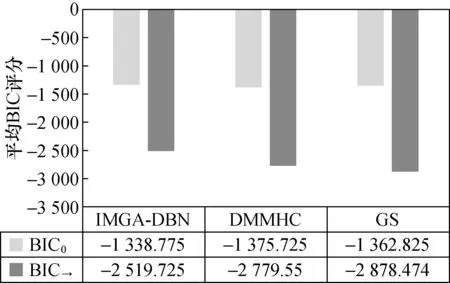
图7 3种算法平均BIC评分对比
对表3仿真结果的分析如下:
1) 在30次独立仿真实验中,IMGA-DBN算法的初始网平均汉明距离(SHD0)为2.73,转移网平均汉明距离(SHD→)为5.09,该指标在5种算法中最小,表明IMGA-DBN算法获得的结构与标准Water网络相似度最高。
2) 在相同的终止条件下,IMGA-DBN算法的平均运行时间(T)为158.48 s,比其他4种算法的用时短,表明IMGA-DBN算法的学习效率高。
为了清晰对比5种结构算法性能,图8(a)~图8(d)分别描述在Water-2000样本数据量下的B0平均汉明距离、B→平均汉明距离、算法平均运行时间及获得最优解的平均迭代次数。
如图8(a)~图8(c)所示,可以获得与动态Asia网络仿真结果所显示的相同结论。如图8(d)所示,IMGA-DBN算法能够在使用较少的迭代次数时获得最优的DBN结构,并且相较于DMMHC、GS、MWST-HC、MWST-GES算法,IMGA-DBN算法在相同终止条件下所耗费的时间短,并且该算法获得的最终结构明显优于其它算法。
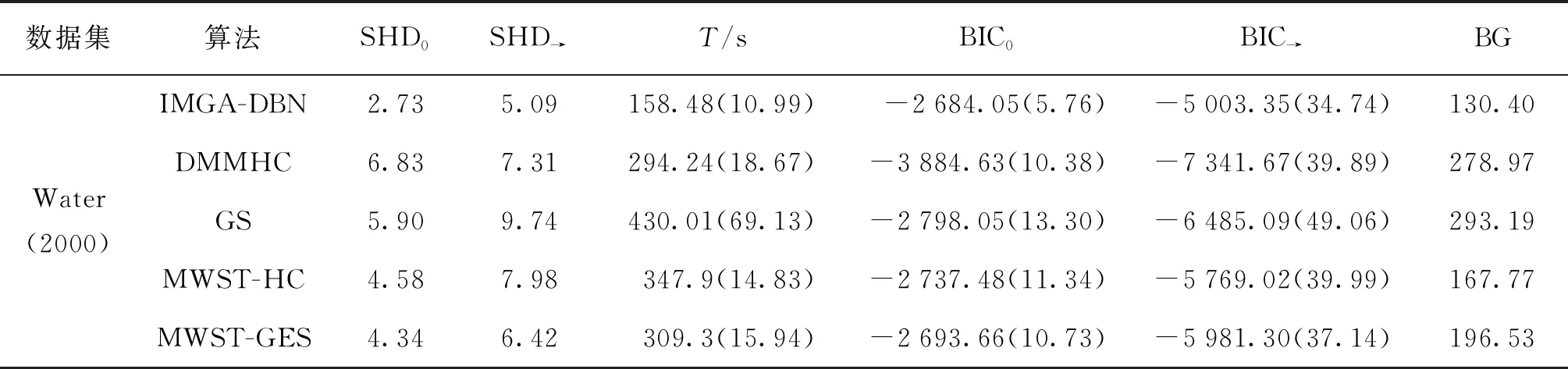
表3 Water网络在不同算法结果对比

图8 5种算法在Water-2000的3种指标对比
图9为Water-2000样本数据下分别运行30次,5种算法获得最优结构的BIC平均值碎迭代次数变化的曲线图。

图9 Water-2000最优结构BIC平均值变化曲线
由图9可知:在Water-2000样本数据下,IMGA-DBN算法初始种群的最优结构评分相较于其他算法高,直至迭代终止。在先验网的仿真中IMGA-DBN算法最终结构BIC评分与MWST-HC、MWST-GES算法的评分趋势和大小无明显差异,但是IGMA-DBN算法的收敛性要比其他算法快。在转移网的仿真中,IMGA-DBN算法得到的最终BIC评分和收敛速度皆高于其他算法。
综上所述:在无先验知识的情况下,本文提出的IMGA-DBN算法通过计算节点互信息和时序互信息并采用自适应遗传算法调节变异和交叉函数,使得结构学习的精度和迭代寻优的收敛速度得到提高。与DMMHC、GS、MWST-HC和MWST-GES相比,IMGA-DBN算法使用互信息和时序互信息构建初始网络,缩小了结构的搜索空间。在后续评分搜索阶段,IMGA-DBN算法利用节点顺序设计编码方法,使得该算法无需进行无环检验,进一步剔除了无效结构。最后,改进遗传算法自适应计算交叉和变异概率,并进行相应地交叉和变异操作,避免了算法陷入局部最优。
5 结 论
从大数据量中快速、准确地获得与数据样本匹配程度最高的结构模型是DBN结构学习亟待解决的问题之一。为此,本文基于改进自适应遗传算法提出了IMGA-DBN算法,解决了在无先验知识的情况下,仅利用数据信息动态限制搜索空间,构建DBN结构的学习问题。通过两种仿真实验得出以下结论:
(1) 本算法为解决复杂动态随机过程的学习提供了一种可行的方法。
(2) 计算互信息和时序互信息的条件下,构建初始先验网和转移网,为后期遗传算法搜索提供了BIC评分较高的初始种群,加快了收敛速度。
(3) 引入结构评分标准差自适应确定交叉、变异概率及操作,使得遗传算法的搜索空间动态且合理地变化,提高了算法的全局搜索能力,并且确保了种群个体多样性,提高了结构学习的准确度并且加快了算法迭代寻优的收敛速度。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
自动化学报(2017年5期)2017-05-14
中国铁路文艺(2016年6期)2016-05-14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
应用数学与计算数学学报(2014年4期)2014-09-26
