
检测型的联盟区块链共识算法d-PBFT
2021-03-18 13:45:22*
计算机应用 2021年3期
*
(1.广西大学计算机与电子信息学院,南宁 530004;2.广西多媒体通信与网络技术重点实验室(广西大学),南宁 530004;3.华南理工大学电子与信息学院,广州 510641)
0 引言
在用户的信息安全方面,为了保证用户数据的完整性和隐私性,本文将区块链技术应用到其中。区块链是一个去中心化的分布式账本数据库[1],其中去中心化是指区块链中的任何决策都是经过所有人投票决定的,需要一个达成共识的过程;而分布式账本表示每一个区块链节点会有一份数据账本用于存储达成共识的结果,这是能保证用户信息不会被篡改的关键所在。区块链作为一个去中心化的技术,意味着区块链中的分布式成员节点没有一个中心化、统一化的首领来发号施令,成员节点只能彼此之间相互讨论才能达成一致的结果,而这个讨论的方法和过程就是由共识层中的共识算法来决定的[2],这是分布式的区块链保持信息中心和用户的信息一致所要用到的关键技术。
目前,主流的区块链应用平台采用到了包括工作量证明(Proof of Work,PoW)、权益证明(Proof of Stack,PoS)、股份授权证明(Delegated Proof of Stake,DPoS)、Raft 共识和实用拜占庭(Practical Byzantine Fault Tolerance,PBFT)等共识算法。不同的共识算法具有不同的特点,大致上可以分为两种类型:一种是BFT(Byzantine Fault Tolerance)类[3]共识算法,这类算法能容忍网络中一定比例的拜占庭节点并达成共识,虽然网络会更加安全但共识耗费的时间相对更长。例如文献[4]使用了PoW 算法来作为比特币网络的共识算法,该算法要求区块链节点计算随机哈希散列数值来证明自己的工作量,并且该结果必须得到至少51%的全网节点认同才能达成最终的共识。文献[5]提出了一种可扩展的拜占庭容错(Scalable Byzantine Fault Tolerance,SBFT)算法,该算法能容忍小于1/3节点总数的拜占庭节点存在于网络当中,并且选定了一个Leader 节点来统计区块链节点对共识提案的通过票数,该机制可以减少区块链节点间的通信开销,因此可以进一步扩展节点的规模。另一类算法是崩溃容错(Crash Fault Tolerance,CFT)算法[6],这类共识算法能容忍网络中的故障崩溃节点并达成共识,它虽然能帮助网络快速达成共识但是需要运行在有身份认证机制的网络中,且要保证节点都是诚实节点。文献[7]提出了一种能容忍节点故障崩溃的经典共识算法,在没有作恶节点的系统中这种算法能够容忍不超过50%的节点宕机故障,提升了系统的可用性。文献[8]提出了一种部分去中心化的共识算法,该算法中区块链节点的地位并不是完全平等的,算法会在开始共识之前选举出一个领导者,通过领导者来分发共识请求并收集投票从而大大地提升通信效率,但前提是推举出来的领导者是可信任的。
综上所述,共识算法中有的更注重共识安全,有的更侧重于共识效率,本文选择兼顾安全和效率的实用拜占庭容错(Practical Byzantine Fault Tolerance,PBFT)算法加以改进,引入了节点监控和恶意节点隔离的能力,剔除了残留在网络中的拜占庭节点,消除了联盟网络中的隐患并持续维护网络安全。
1 实用拜占庭容错共识算法
1.1 实用拜占庭共识算法概述
拜占庭将军问题(Byzantine Generals Problem),是Lamport 等[9]在1982 年提出用来解释一致性问题的一个虚构模型。在现实的联盟链系统中,从信息中心的节点中选举出Leader 节点。通过先期的联盟链会员资格审查,能保证加入到联盟中的节点绝大部分都是诚实可靠的,但也不能完全确定其中就一定没有“叛徒”,这些“叛徒”节点称之为拜占庭节点,一旦它们被选举成主节点就有可能会丢弃或更改用户的隐私数据。
实用拜占庭容错(PBFT)共识算法于1999 年由Castro等[10]提出,该算法可以容忍不超过1/3节点总数的拜占庭节点存在网络之中,是一种解决拜占庭问题的实用方法,它的出现将BFT 指数级的复杂度降低到了多项式级别,让人们得以在实际生产中使用它。
在PBFT共识算法模型中,节点分为主节点和备份节点两种,主节点是轮流当选的,主节点的编号p由视图编号对节点总数取模得到:

当主节点是诚实节点时,主节点协同备份节点完成预准备(pre-prepare)—准备(prepare)—提交(commit)的三阶段协议;当主节点完成一次完整共识或是出现拜占庭错误的情况,则会引发备份节点发动视图切换(view-change)协议重新推举出新的主节点。
1.2 实用拜占庭算法的不足
相较于Raft共识只能容忍节点的故障崩溃,PBFT 共识算法可以很好地容忍拜占庭节点错误,能够在很大程度上为联盟网络的隐私提供保护,但即便如此PBFT算法仍然有需要改进完善的地方。
首先,PBFT 共识算法本身是可以容忍不超过1/3 节点总数的恶意拜占庭节点[11],但由于主节点的选取是轮询得到,而算法本身缺乏对于节点状态的判断,因此很有可能会将拜占庭节点选为主节点。一旦拜占庭节点当选为主节点进行作恶,它可能会丢弃、篡改客户端的提案,导致提案无法达成全网共识,直到被其他备份节点发现后执行视图切换协议,这个过程需要重新选举主节点并重新执行提案请求,会产生十分昂贵的开销。
其次,PBFT共识可以容纳一定数量的拜占庭节点在系统中而不影响剩余的诚实节点达成共识,但却不会处理这些恶意节点,更不会惩罚这些作恶节点,这些拜占庭节点可以不停作恶而不用付出任何代价,如果放任不管的话这些拜占庭节点可能会形成一定的规模,一旦轮询到它们担任主节点就会大大地降低共识效率,因此PBFT 共识算法亟须一种惩罚手段。针对这些可改进的内容,本文提出了一种能够监控节点状态的检测型实用拜占庭容错(detection-Practical Byzantine Fault Tolerance,d-PBFT)算法,并详细阐述了算法的共识流程。
2 改进PBFT共识算法
2.1 方案对比
针对PBFT实用拜占庭共识算法,已经有专家和学者对该算法进行了改进和完善,如文献[12]提出了基于候补集合投票的改进PBFT 算法(Improved Practical Byzantine Fault Tolerance,IPBFT),算法优化了共识过程,减少了节点间的通信次数,但仍然会将拜占庭节点纳入到候补集合中作为下一轮选举的竞选者,一旦网络中潜藏的拜占庭节点形成了一定规模甚至会导致主节点频繁切换。文献[13]在PBFT 共识三阶段之前引入了可验证随机函数(Verifiable Random Function,VRF)来进一步保证主节点选举的随机性,但随着节点规模的增大VRF会导致系统性能下降得很快。
上述改进算法虽然巧妙,但仍会残留拜占庭节点于网络中。本文提出的d-PBFT 检测型实用拜占庭共识算法会在共识开始前校验主节点的节点状态,避免拜占庭节点担任主节点,减少无效的通信,同时会将这些恶意节点纳入隔离区,追查来源并将其踢出网络。
2.2 d-PBFT拜占庭容错能力
在有严格会员准入机制的联盟区块链网络中,不能排除仍然有第三方敌手将拜占庭节点伪装成正常节点混入到联盟网络中,假设存在f个拜占庭节点,需要容忍这f个节点的恶意行为并且还要保证它们的行为不会对共识结果产生影响,这就需要给定一个恰当的节点总数n,使得恶意节点f不会成为网络中的多数派。在确定节点总数n之前,首先需要明确这些恶意节点可能会产生的恶意行为,其中一个行为是不应答,即收到共识请求后不返回执行结果;另一个行为是错误应答,即返回一个错误的共识结果来欺骗网络中的其他节点。
在此前提条件下,当一个客户端提出共识请求后,若网络节点正常则本应该收到n条消息,但由于拜占庭节点不应答的原因,因此只收到了n-f条应答消息,为了让应答的消息占据大多数就必须有n-f>f成立,所以节点总数n必须大于2f。另一方面,即便有f个节点没有应答客户端,但也可能是其他诚实节点暂时掉线了,即在应答的n-f条消息中可能存在着错误应答的拜占庭节点,为了确保系统的安全性需要考虑到最坏的因素即当前不应答的节点全是由诚实节点意外掉线导致的,因此最坏情况下n-f条消息中还包含着f条来自拜占庭节点的错误消息。为了保证诚实节点的消息数为大多数,n-f条应答消息还需要细分为n-f-f条诚实应答消息和f条错误应答消息,所以可以得出n-f-f>f即n>3f。所以为了容忍f个拜占庭节点,网络中的节点总数n至少为n=3f+1。
综上所述,只要联盟网络中的拜占庭节点数f≤这些拜占庭节点就无法左右系统达成一致的共识结果。然而随着时间的增长,假设每经过一段Δt时间后,系统内就会新增一个拜占庭节点,如果这些拜占庭节点没有得到及时的处理,不仅会降低系统的性能,还有可能造成f>进而威胁联盟网络安全,因此本文提出了节点状态监测和隔离惩罚的机制,可以在经过m轮共识后及时汇报节点的状态,以便剔除网络中的拜占庭节点。改进后的效果如图1所示。
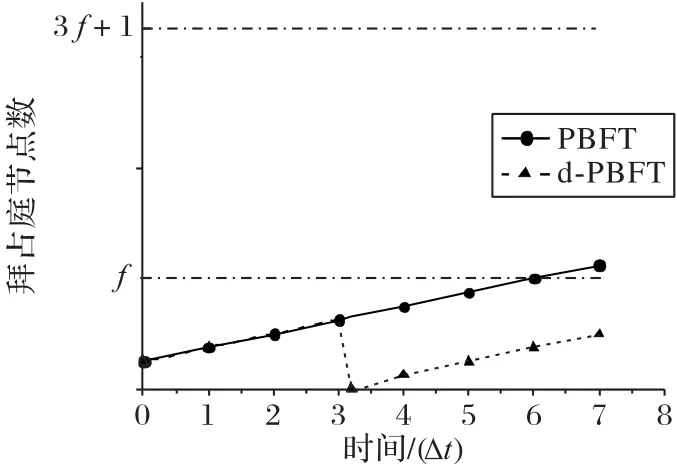
图1 d-PBFT算法的拜占庭容错能力Fig.1 Byzantine fault tolerance performance of d-PBFT algorithm
2.3 新增节点状态监测
与公有区块链中节点匿名加入网络不同,联盟区块链有严格的会员准入机制,无论是企业还是个人加入联盟链都会受到身份资格的审查,并且从可信度、安全和性能三个方面考虑,联盟链中参与共识的节点都是由组建联盟的信息中心和企业提供,个人用户的节点只参与健康提案的发起和结果校验。因此,本文考虑为这些参与共识的节点新增节点状态的属性,与此同时每一个参与共识的节点都需要维护一份节点状态信息表如表1所示。
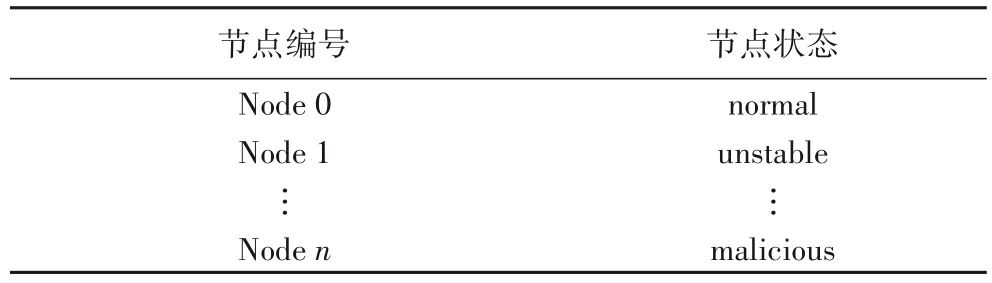
表1 节点状态Tab.1 Node states
在本文的联盟区块链中,用户节点可能有很多,但真正参与共识的节点都是来自联盟中的信息中心和企业,并且由于原PBFT算法本身通信开销和性能的因素,参与共识的节点数目通常不会超过100 个,因而维护这样一张表不会给每个节点造成额外的负担。
在系统首次运行时,每个共识节点的表中都不会记录任何节点及其状态。在执行三阶段共识协议之前,先检查主节点在节点状态表中的状态,如果没有在表中找到该主节点,就先验证该节点的签名,签名通过则添加该节点到表中。开始执行共识协议后,每完成(或终止)一轮共识,参与共识的备份节点才会为当前视图的主节点打上标记如图2所示。
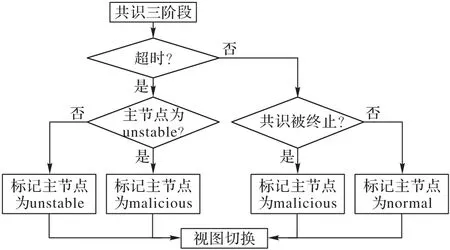
图2 节点标记过程Fig.2 Process of node marking
如果一轮共识是按照三阶段协议的预准备-准备-提交的流程正常运转,那么在结束的时候其他备份节点就应当为主节点打上normal 标记。如果在执行共识期间,主节点长时间没有响应直到超出预分配时间还未完成共识,由于无法判断该主节点是意外掉线还是故意不分发共识提案,此时其他备份节点应当标记主节点状态为unstable,之后发起视图切换view-change 协议推举新的主节点重新完成共识。带有unstable标记的节点如果连续两次担任主节点都超时,就会被其他节点标记为malicious 节点;但unstable 节点如果在下一次担任主节点时顺利完成共识,那么仍然可以恢复成normal节点。在一轮共识中,有备份节点发现了主节点有任意作恶行为,如伪造签名、分配错误的提案序号、篡改提案信息等,应当即刻发起视图切换view-change 协议,如果view-change 被全网一致通过则标记主节点为malicious节点。
2.4 追查惩罚机制
假设联盟中共有n个节点参与共识,那么在n轮共识过后,所有的节点都轮询担任过主节点,每一个参与共识的节点都会维护一张完整的节点状态表,如果联盟中的节点十分诚实,那么大部分节点的评级都应该是normal,可能会有少部分节点为unstable,这表明联盟的网络状态十分健康。现实中的区块链网络可能会存在拜占庭节点,由于联盟系统有严格的身份准入机制,这些拜占庭节点的数量很难超过共识节点总数的1/3,因此它们作为备份节点出现时对共识过程的影响不大,它们产生的恶意结果会在共识过程中被舍弃掉[14],如果这些拜占庭节点作为主节点出现在共识系统中即便无法篡改用户数据,但仍然会带来较大的性能和恶意超时的影响。因此,在这些拜占庭节点担任过一次主节点后,它的作恶行为会让它在其他诚实节点的节点状态表中被打上malicious 标记,当这些拜占庭节点再一次竞选主节点时,可以通过malicious 标记直接把这些拜占庭节点排除掉,不给它们作恶机会,同时避免浪费不必要的共识纠错时间。
同时本文还为unstable 节点和malicious 节点设立了一个“隔离区”,隔离区隶属于共识模块,如果节点曾经被标记过unstable状态,则会被隔离区记录unstable次数,次数累计较多的节点会被视作故障老化的节点最终被移除网络。如果节点被打上malicious 标记,则会立即被收纳到隔离区中,每经历m轮共识后(m视联盟的实际需求而定)系统就发起一次针对隔离区的系统共识,系统管理员就可以通过隔离区中记录的节点信息追查和处理这些拜占庭节点的所属组织。
2.5 d-PBFT算法共识流程
d-PBFT共识算法敌手模型为n=3f+1,其中n代表参与共识的总节点数,f为拜占庭节点数且f≤整个共识网络中的节点都统称为replica复制节点,因为原PBFT算法就是基于状态机复制原理的算法[15]。replica 节点又可以细分为一个Primary 主节点和众多的Backup 备份节点,主节点是根据replica 节点的编号依次轮询到的,主节点和备份节点都会运行在一个称之为视图view 的地方,每个主节点都会对应一个视图,如果主节点被更换了那就需要运行视图切换协议,图3 展示的是一个主节点在一个任期内运行d-PBFT 共识算法达成共识的流程。
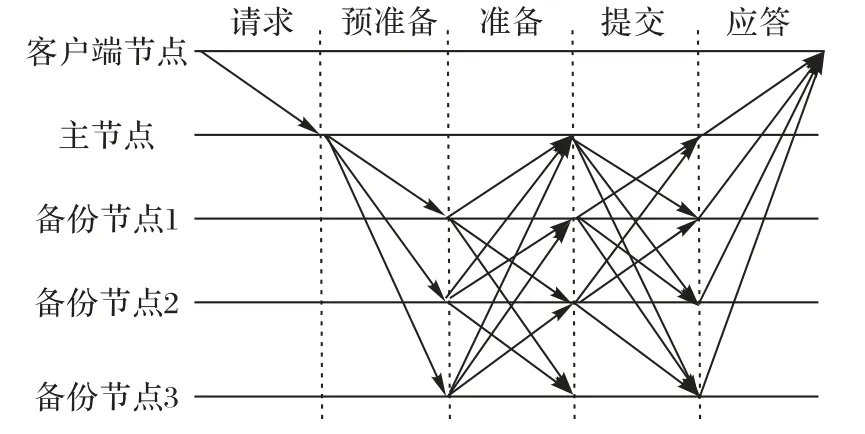
图3 d-PBFT三阶段协议Fig.3 d-PBFT three-stage agreement
d-PBFT 算法沿用了PBFT 共识算法的三阶段协议,而d-PBFT算法新增的检测主节点状态、标识主节点状态和隔离拜占庭节点的过程都夹杂在pre-prepare、prepare 和commit 过程之中,当主节点有任何超时和作弊的行为都会被其他备份节点标记下来。图3 反映的是成功达成共识需要经历的5 个步骤:
1)请求(request)步骤。首先,用户通过网络客户端client向联盟中的主节点Primary 发送提案请求其中提案内容表示为m,发送方表示为c用来表明客户端身份,该提案的时间戳表示为t。这个阶段就是用户向联盟提交需要共识的提案信息,该消息会被客户端签名,然后再进入共识的核心流程。
2)预准备(pre-prepare)步骤。在视图view 上,主节点会校验发送方的身份,然后将提案内容m编上序号并为它生成摘要,然后将它们一并打包分发给网络中的备份节点,消息内容为其中:v记录的是运行共识所在视图的编号,n表示主节点为提案m设定的序号,d则是提案生成的哈希摘要,p表示为主节点的节点编号。
如果主节点直到超时还未将预准备消息发送出去,其他的备份节点会将该编号的主节点标记为unstable 状态,若已经是unstable 状态的节点连续两次担任主节点都发生了超时,该节点就会被拉黑为malicious节点,之后其他节点就不会再选取该节点作为主节点了;但如果标记为unstable 的节点在下一次担任主节点时恢复正常,那么它的节点状态仍然可以恢复为normal状态。
3)准备(prepare)步骤。当所有的备份节点Backup接收到主节点发来的消息后,选取其中一个备份节点b1来进行说明,首先b1通过主节点的编号p在自己记录的节点状态表中查询主节点的状态,如果主节点是malicious 状态的,那么备份节点b1就直接发起视图切换协议请求更换新的主节点;如果主节点是normal 状态或unstable 状态,则准备广播消息给除b1以外的其他节点,其中i代表的是备份节点b1的编号。
4)提交(commit)步骤。其他节点接收到来自b1备份节点的prepare 消息,同理b1也会接收到其他备份节点发过来的prepare消息。首先,b1会检查消息的签名是否正确,其他节点prepare消息的视图编号是否和主节点pre-prepare消息发送的视图编号一致等。当有至少2f个来自其他备份节点的prepare 信息能和主节点的pre-prepare 信息核对一致时,此时的b1备份节点就可以广播消息给其他节点,D(m)是b1对于提案m的可验证签名。
同理,如果b1备份节点广播的prepare 消息正常的话,也会收到其他备份节点返回的commit 消息,当commit 消息达到至少2f+1条时表明全网已经达成共识。但在达成共识前,如果主节点被发现有任何作弊的行为,会引发备份节点发起视图切换协议,并把该编号的主节点记录为malicious节点,之后会把它移交到隔离区等待联盟管理员处理。
5)应答(reply)步骤。进入到reply 步骤意味着核心的共识过程已经结束,接下来就是所有的节点将消息返还给客户端,其中的r代表节点执行的结果,由于该网络只能容忍f个拜占庭节点,因此当客户端收到至少2f+1 个reply 消息即表明该返回结果确实已经达成了全网的共识认证。
2.6 视图切换流程
当备份节点感知到当前主节点p有异常行为如超时、作弊行为时,备份节点会发起视图切换协议并发送消息广播给全网,其中,v+1表示新的视图编号,n表示最近checkpoint 消息检查点的编号用于检验最新的消息log,C表示已经验证过的2f+1 个checkpoint 消息集合,P表示因超时导致未完成的pre-prepare消息和prepare消息的集合。
当网络中有至少2f+1个节点发起视图切换协议,网络就会开始重新选举节点p+1 作为主节点,所在的视图view 也会从v变更为视图v+1。之后,新的主节点p+1 将会发送消息广播给全网节点,其中,V表示备份节点发出的有效的view-change 消息集合,O表示重新发起上一轮未完成的pre-prepare 消息的集合。备份节点接收到new-view 消息后,比对其中有效的view-change消息集合,确认无误后正式加入到新节点的视图v+1 中并完成上一轮未完成的pre-prepare消息。
3 改进PBFT算法测试评估
本文提出了一种改进PBFT 的d-PBFT 共识算法,之后需要对该算法进行测试评估,并在无拜占庭节点和有拜占庭节点的情况下分别对其表现进行评估,以验证该算法在联盟网络中的实用性。
3.1 测试环境
本测试评估将会在实验室电脑上进行,本次测试使用4台实验室电脑配置如表2所示。
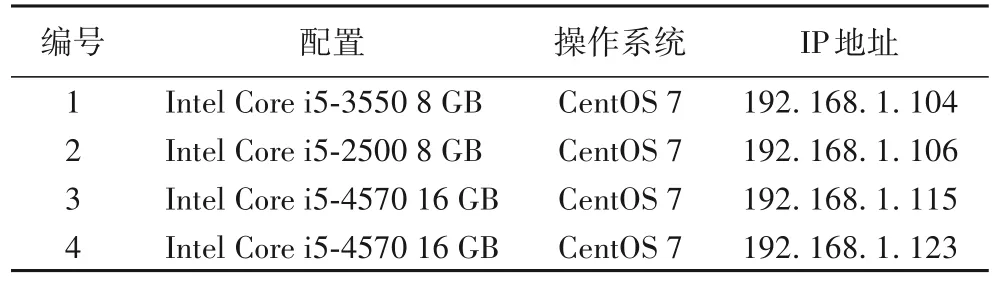
表2 网络节点配置Tab.2 Network node configuration
本文的测试将会对比PoW、Raft、PBFT 和d-PBFT 四种共识算法在无拜占庭节点情况下和有拜占庭节点情况下的吞吐量和时延,该测试不会运行在某一个特定的区块链平台,而是使用go语言实现[16]并部署在4台实验室电脑中。
在本章需要测试共识算法在同一环境下的性能,因此采用一个轻量级的开源测试框架wrk,它是一款基于HTTP 协议的测试工具,能够利用异步事件驱动框架给予系统很大的并发量。由于wrk 框架是一个轻量级框架,默认支持GET 方式发起请求,而本文的客户端节点需要提交联盟用户的信息和数据,因此需要借助lua 脚本启用POST 方式向其他节点发送请求。
3.2 测试结果
3.2.1 共识算法TPS测试
本文在无拜占庭节点和有拜占庭节点的两种情况下分别对d-PBFT 算法进行了吞吐量测试并与PoW、Raft 和PBFT 算法进行对比,测试结果如图4所示。
图4 是网络中无拜占庭节点的情况下测得的共识算法吞吐量,在区块链中吞吐量(Transactions Per Seconds,TPS)的计算方式为:

实验中,对共识算法进行了30次测试,由图4可知在无拜占庭节点的情况下部分去中心化的Raft 算法吞吐量最高,完全由Leader 节点分发客户端请求,Follower 节点只验证Leader节点信息内容,却不会在Follower 之间判断Leader 节点是否是拜占庭节点。吞吐量排在并列第二的分别是PBFT 和改进d-PBFT 算法,Backup 节点不仅会验证Primary 节点的信息内容,还会在Backup 节点间综合判断Primary 节点是否是拜占庭节点,因此为了保证联盟网络更加安全而牺牲了部分吞吐量。最后,吞吐量最差的是PoW 共识算法,这个算法是完全去中心化的算法,网络中设定的难度越难产生新的区块就越困难。

图4 无拜占庭节点下的吞吐量测试Fig.4 TPS test in non-Byzantine case
受实验室设备的限制,本文仅向网络加入了一个拜占庭节点并测试共识算法的TPS,测试结果如图5所示。
设定节点超时时间为10 s,在这一轮测试中针对部分去中心化的算法Raft、PBFT 和d-PBFT,让4 个节点轮流担任主节点,拜占庭节点也会轮值到主节点,完全去中心化的PoW算法中节点地位平等而没有主节点机制。由图5 可知,当拜占庭节点轮值到主节点时,Raft 算法完全没有任何防范能力在图像中用“×”来表示,并且拜占庭主节点不会被揪出而是一直担任着主节点,此时整个网络传递的都是拜占庭节点的消息。而在PBFT 算法中,每当拜占庭节点轮值成为主节点时,其他的备份节点会有效地识别出来,但也意味着在这一轮共识中节点都忙于检测主节点存在的问题,导致无法再传输用户信息。基于PBFT 改进的d-PBFT 共识算法在第一轮也体现了同样的特征,但不同的是在第一次发现了拜占庭节点之后,当再次遇到拜占庭节点时d-PBFT 会拒绝它轮值为主节点,使得相同时间内与PBFT 算法相比区块生成量提升了26.1%。PoW 算法则是完全去中心化的共识算法,只要不是超过51%的节点发起攻击[17],PoW算法都能够正常运行。
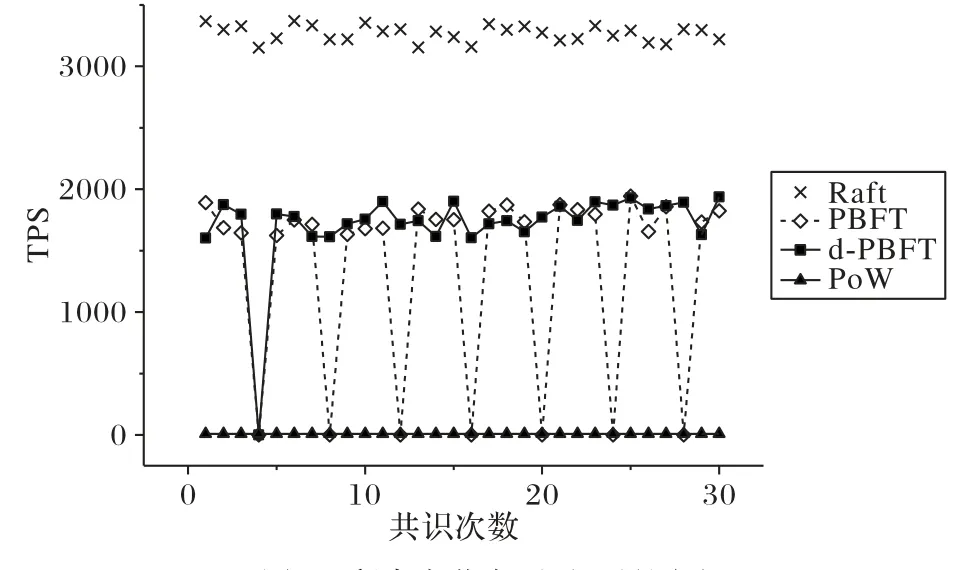
图5 拜占庭节点下吞吐量测试Fig.5 TPS test in Byzantine case
3.2.2 共识算法时延测试
在共识算法的时延测试中,同样采用无拜占庭节点和拜占庭节点两种情景进行测试,设定在共识网络中的超时时间为10 s,如果节点在10 s 后无任何响应共识会被取消。共识算法的时延计算公式为:

本文在主节点为非拜占庭节点和拜占庭节点的情境下分别测试了30 次,测试了用户数据写入区块链并达成共识的时延,对30次测试取平均值求得结果如图6所示。
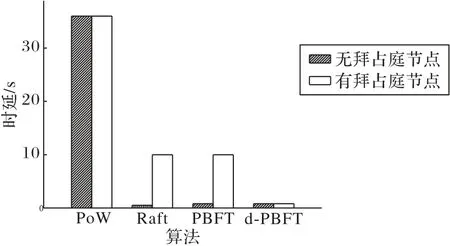
图6 非拜占庭和拜占庭情况下的共识时延Fig.6 Consensus delays in non-Byzantine and Byzantine cases
在该轮测试中,正常主节点的共识时延用斜线柱状图表示,拜占庭节点担任主节点的共识时延用空白柱状图表示。由于PoW 算法是完全分布式的共识算法,并且需要各个节点在一定难度下竞争区块,因此耗费的时间最长,平均耗时超过30 s,但是拜占庭节点只要不超过节点总数的51%就对整个网络影响有限。部分去中心化的Raft共识算法在无拜占庭节点的情景下表现优秀,能够维持在0.5 s 左右的延时,但前提条件是网络没有将拜占庭节点选为主节点,一旦主节点被拜占庭节点攻占整个网络将会处于混乱状态,共识的内容和时长将被拜占庭节点掌控直到超时。PBFT 算法和d-PBFT 算法在正常情况下达成共识的时间也非常迅速,两种算法都没有超过1 s,同时这两种算法相较Raft 算法更加安全,在PBFT 算法中当拜占庭节点担任主节点时,只要拜占庭节点数目不超过节点总数的1/3,被篡改的信息是会被其他备份节点发现并修正的,但拜占庭主节点仍然可以令共识超时,从而对用户的通信造成影响;而d-PBFT 算法在第一次拜占庭节点担任主节点时也会受到类似的影响,但在下一轮轮询中网络中的节点不会再支持拜占庭节点担任主节点,这将有效地避免拜占庭节点对网络的时延产生干扰。
3.2.3 共识安全性
上述实验分别在正常情况和拜占庭错误两种情况下进行的,除PoW算法没有主节点以外,Raft算法、PBFT算法d-PBFT算法的主节点都由拜占庭节点担任。在吞吐量测试的同时记录了共识结果,心率传感器客户端发起心率数值为65 bpm 的共识录入请求,共识算法分别在正常情况和拜占庭错误的情况下返回共识结果如表3所示。
针对共识结果的返回情况可知在主节点发生拜占庭错误的情况下,Raft算法直接返回了错误的信息,其安全性无法保障;而PBFT 算法在此情况下并没有及时地返回共识结果,它总是会进入到了自我纠错的视图切换阶段,即使最终能返回正确的共识结果,但视图切换的过程会产生额外的开销;仅有PoW 算法和d-PBFT 算法能及时返回正确的共识结果。首先PoW 算法的安全性非常高,作为完全去中心化的算法它总是能返回正确的共识结果;然后d-PBFT 算法的安全性排在第二,它被拜占庭节点“欺骗”过一次之后就会将它标记起来,之后会直接拒绝它成为主节点来降低拜占庭节点的影响,从而提高共识的安全性。
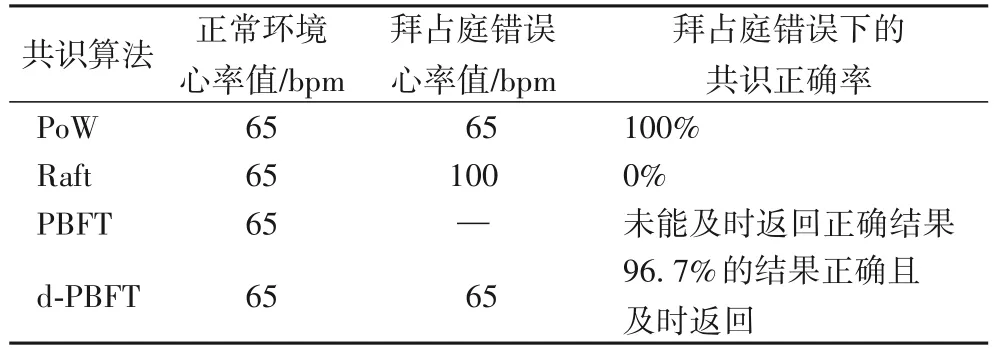
表3 共识结果对比Tab.3 Consensus result comparison
3.3 结果分析
本文对提出的改进算法d-PBFT 共识算法进行了对比测试,对比的算法包括完全去中心化的PoW 算法、部分去中心化的Raft算法和PBFT算法,测试的项目包括共识算法的吞吐量和达成共识的时延,综合分析了d-PBFT 算法相较于这些主流算法的独特优势。在吞吐量方面,虽然d-PBFT 算法不如Raft 算法但却能检测出网络中的拜占庭节点,从而更能保障联盟网络用户数据的安全性,而在有拜占庭节点的网络中d-PBFT 算法又比PBFT 算法更能排除拜占庭节点的干扰,进而在吞吐量上得到一定的提升。在共识时延方面,d-PBFT 算法遥遥领先完全去中心化的PoW 算法,并且能和另外两个部分去中心化的算法持平,而在拜占庭节点的威胁下Raft 算法束手无策,PBFT算法会在拜占庭节点担任主节点时受到不小的干扰,而d-PBFT 算法在拜占庭节点的干扰下仍具有较好的表现。所以,d-PBFT 共识算法能够兼顾信息安全、吞吐量和共识时延三方面需求,十分适合应用到联盟区块链当中[18]。
4 结语
本文在PBFT 算法的理论基础上提出了d-PBFT 共识算法,在该算法中新增了节点状态的监测和恶意节点的隔离机制,使得算法不仅能容忍拜占庭恶意节点还能捕获到拜占庭节点,隔离并禁止将它们选为主节点,以此来降低它们在联盟网络中的影响。实验结果表明,当联盟网络中存在拜占庭节点的情况下,该算法能降低拜占庭节点的干扰,提升共识结果的生成量。此外该算法仍然存在值得改进的地方,虽然该算法能标识并隔离拜占庭节点,但删除信息中心的共识节点需要重启联盟网络,下一步要优化联盟网络动态增删共识节点的能力。
猜你喜欢
恋爱婚姻家庭(2023年1期)2023-02-15 13:02:38
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03 09:09:48
中学历史教学(2018年1期)2018-04-04 05:20:24
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
古代文明(2016年1期)2016-10-21 19:35:20
凤凰生活(2016年2期)2016-02-01 12:41:05
科技视界(2015年6期)2015-08-15 00:54:11
