
结合改进密度峰值聚类和共享子空间的协同训练算法
2021-03-18 13:45
计算机应用 2021年3期
(1.重庆师范大学计算机与信息科学学院,重庆 401331;2.重庆师范大学重庆市数字农业服务工程技术研究中心,重庆 401331)
0 引言
协同训练是基于不同视图训练两个分类器来互相标记样本以扩充训练集的一个过程,属于半监督学习[1-2]的范畴。由于协同训练一方面考虑到现实世界中数据集的分布情况,充分利用数据集中大量无标记样本和少量有标记样本;另一方面考虑到多视图数据的多态性、多源性、多描述性等特点,充分利用数据集中各视图间的相关信息,使得协同训练广泛应用于图像处理[3]、工业样品检测[4]、城市管理[5]、在线问答服务[6]等领域。
协同训练的特点是在不用人工干预的情况下,通过两个独立分类器的协同作用从大量无标记样本中自动获取训练信息;然而,在协同训练迭代过程中,多分类器存在的标记不一致样本易导致分类错误累积,而如何选择更具代表性的无标记样本加入训练集也是提高分类器性能的关键。针对无标记样本的选择,付治等[7]利用基于简单约束的聚类算法和标记置信度来选择可靠的实例,以此来实现有标记样本的扩展;然而该方法严重依赖标记置信度,若样本集的簇中心选取不准确,则会造成分类连带错误。Gan等[8]用半监督模糊聚类来发现数据的内部结构,利用该数据结构选取局部判别能力强的无标记样本,但该方法未考虑到数据的全局结构信息,使得选择的无标记样本不能充分代表数据的原始空间结构。Wu等[9]提出了一种自训练半监督分类框架,利用密度峰值聚类(Density Peak Clustering,DPC)算法[10]发现数据的空间结构后将其结构融入自训练迭代过程中。DPC算法适用于任意形状的数据集聚类,但需要通过决策图来选择簇中心,从而增加了算法的冗余性,限制了算法的应用领域。马春来等[11]针对DPC 算法中对簇中心的判断问题,引入基于拐点法的簇中心选择策略来实现簇中心的自动选择,降低了通过决策图主观确定簇中心带来的误差。由于考虑到不同数据集稀疏或密集程度的差异,认为拐点位置无法为簇中心的定性划分提供理论依据,从而导致无法精确选取簇中心。龚彦鹭等[12]考虑到无标记样本隐含的空间结构信息,利用DPC 算法选取局部密度与相对距离之和较高的无标记样本来辅助训练分类器,依据数据集全局的密集或稀疏程度来划分样本的选取区间,但忽略了样本的内部结构差异,无法体现样本的局部紧密或稀疏程度,可能会造成选取的无标记样本不可靠。
在分类器的协同过程中,多个分类器标记同一个无标记样本可能会产生类标号不一致的情况。为解决该问题,Zhao等[13]设计了基于伪标记误差的安全验证方法,在候选标记中,选择比前一轮迭代过程中误差精度低的标记作为无标记样本的最终类别,然而该方法通过伪标记误差来确定候选标记时,对误差较低的界限没有明确说明。龚彦鹭等[12]采用加权K近邻算法(WeightK-Nearest Neighbor,WKNN)为分类不一致的无标记样本重新进行分类,但该算法的分类正确率在数据集分布不均衡的情况下会受到影响。Peng 等[14]提出多视图增强算法Boost.SH,通过利用多个视图的共享样本权重分布来保证视图的一致性,一定程度上解决了样本分类不一致问题,但由于多视图数据集的多态性等特点,该算法并不总是能找到满足条件的共享样本。
为了更好地选择隐含有用信息多的无标记样本和解决标记不一致样本的修订问题,提出了结合改进密度峰值聚类和共享子空间的协同训练算法(Co-Training algorithm combining Improved Density Peak Clustering and Shared Subspace,CTIDPCSS)。该算法通过定义虹吸平衡法则来实现簇中心的自动选择,以提高簇中心选择的准确度;通过引入相互邻近度[15],结合数据集全局和局部特征来划分样本的选取区间,以得到更具代表性的无标记样本;借助共享子空间(Shared Subspace,SS)[16-18],充分利用多视图间的一致性信息,得到一种新的样本修订方法。仿真实验结果表明,该算法具有更好的分类能力。
1 提出算法
在协同训练的迭代过程中,通常有两种方法选择无标记样本。一种是利用聚类算法来分析数据集的全局空间结构,根据样本所属类簇制定规则来划分样本选取区间,得到较好表现数据原始空间结构的样本,但该方法忽略了样本间的内部联系,易造成所选样本信息缺失。另一种是利用能体现样本间局部连带关系的算法,选取较好表现数据局部结构的样本,由于该方法忽略了数据的整体结构,易误将局部优选样本当作全局优选样本。若能够探讨一种将两者优势互补的方法,选择出更具代表性的无标记样本,则能提高分类器的分类性能。由此,本文考虑到DPC 算法能探索到任何簇结构数据集的全局空间结构,而相互邻近度能体现样本的局部差异,故采用一种结合DPC 和相互邻近度的方法来选择无标记样本。该方法在聚类阶段确定簇中心时,由于DPC 算法提供的理论依据不足且未实现算法批量自动化应用,则本文通过定义虹吸平衡法则来实现簇中心的自动选择,为簇中心的定性划分提供理论依据。因此,将该方法中的DPC 算法替换为基于虹吸平衡法则的密度峰值聚类算法,再根据簇中心计算样本的相互邻近度,将其作为无标记样本的选择依据。被挑选出的无标记样本能更好地体现数据的原始空间结构,则利用这些样本包含的有用信息来提高模型的分类性能。然而,在多分类器的协同过程中存在的标记不一致样本会造成分类错误累积,需及时实施样本修订策略才能有效避免标记错误样本的干扰。修订策略的目的是让多分类器最大化它们对无标记样本的一致性,从而借助无标记样本提升分类器的学习性能。因此,本文在保持原始数据的分类和决策能力的前提下找到数据一致性表征的共享子空间,以训练一个一致性分类器对多分类器标记不一致的样本重新分类。
1.1 改进的密度峰值聚类算法
1.1.1 DPC算法
DPC 算法[10]是一种基于密度的聚类方法,首先计算每个样本的局部密度和相对距离,在密度和距离的决策图上通过人工选取簇中心,最后根据密度值将非簇中心点划分至所属类簇。对于给定的数据集D=[x1,x2,…,xn]∈Rm×n,其中xi=[xi1,xi2,…,xim],n为样本总数,m为样本维度,计算每个样本xi的局部密度ρi和相对距离δi。考虑到本文存在较大规模数据集,则局部密度ρi利用式(1)中的截断核[19]方式度量:
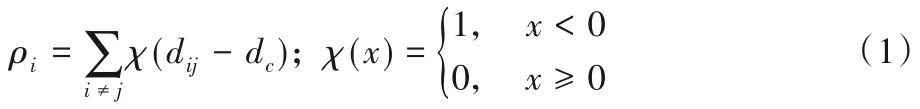
其中:局部密度ρi为以邻域截断距离dc为半径的圆形结构内的样本数,dij为样本xi到xj的欧氏距离。
相对距离δi指比样本xi密度高且与它距离最近的样本xj的距离,计算公式如下:
根据式(1)和式(2)的计算结果,以局部密度ρi为横轴,相对距离δi为纵轴作决策图,决策过程如图1所示。图1(a)是一个共含有30个样本的2维数据分布图,其类别分别以3种不同的图形来区分。图1(b)是DPC算法的可视化决策图,从图中“最上最右”的点出发,按照“向下向左”的原则,人工选择标号为3、21的点作为簇中心。但由于没有定量分析和决定性划分理论作为判断依据,人工选择簇中心存在一定主观性和误差。而作为簇中心的样本是影响DPC算法聚类效果的一个关键原因,若选取的簇中心不准确或错误,将会造成聚类效果不佳。
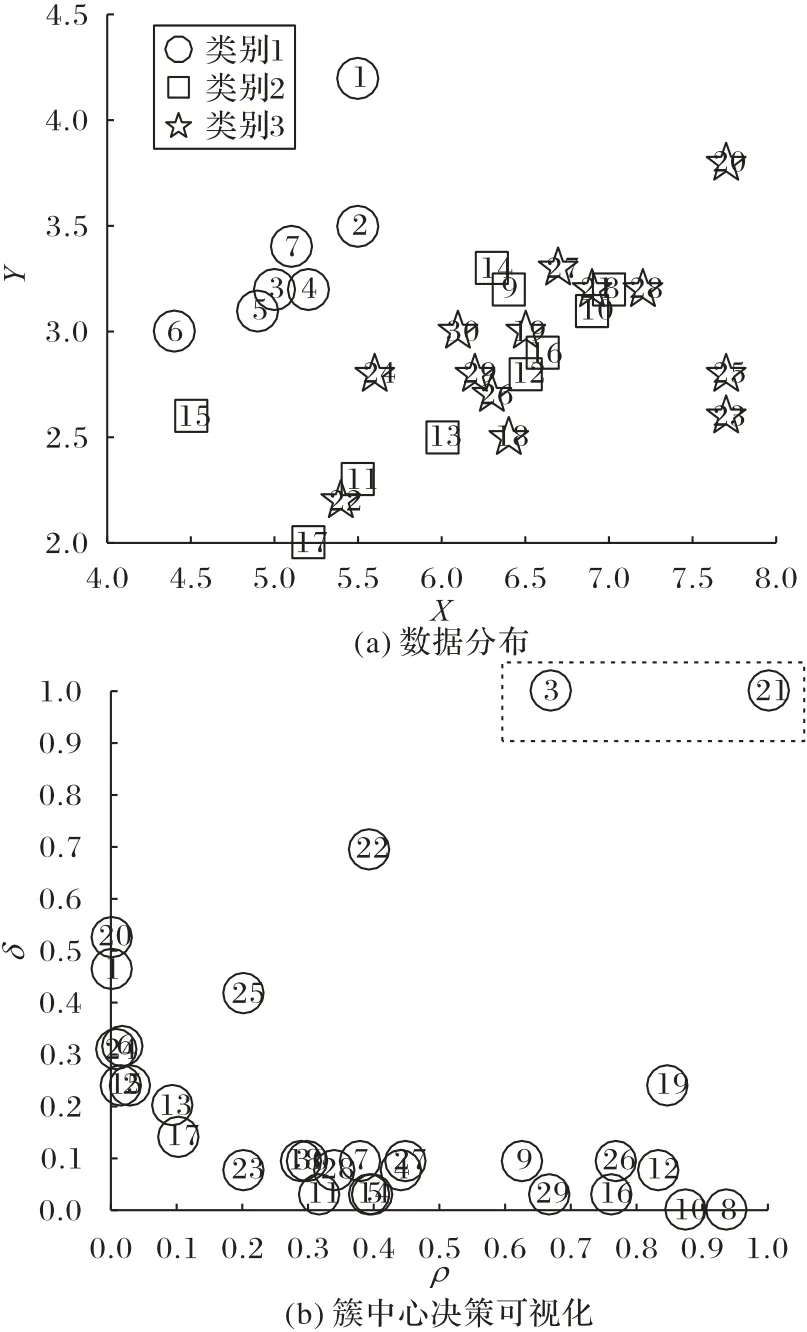
图1 DPC算法的簇中心决策图Fig.1 Cluster center decision diagram of DPC algorithm
1.1.2 基于虹吸平衡法则的DPC算法
针对DPC 算法存在的不足,马春来等[11]从量化的角度引入簇中心权值的概念,提出根据权值的偏离度变化趋势定位拐点位置的簇中心选择策略,实现了簇中心的自动选择,但未提供簇中心决定性划分的理论依据。本文基于虹吸现象[20]提出虹吸平衡法则,为簇中心的选择提供定量分析和决定性理论依据。虹吸现象的原理是:当管状结构两端存在压力差(位能差)时,水将从压力大的一侧流向压力小的一侧,当两侧的压力相等时整个装置达到平衡状态,此时容器内的水面到达相同的高度,水就会停止流动。
在虹吸平衡法则中,为公开化平衡标准,将ρi和δi进行归一化后引入簇中心权值作为平衡量:
定义1簇中心权值。

鉴于在一般情况下,数据集的簇类别数远小于样本总数,为了降低计算复杂度,将簇中心权值降序排列后取前q个点作为簇中心候选点,构造簇中心候选集Q1×q={γ1,γ2,…,γq}。为引入位差,首先确定位差分割点γc,将点γc前的候选点分配到上位区S1×c-1={γ1,γ2,…,γc-1},点γc及其之后的候选点分配到下位区X1×q-c+1={γc,γc+1,…,γq}。
定义2位差。

定义3相对平衡点。
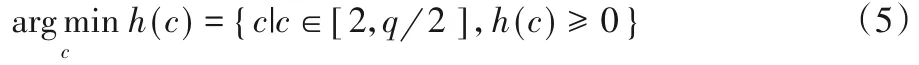
当位差分割点γc的下标取值范围为,存在数值c使得h(c)≥0 时,则认为簇中心权值达到平衡状态,此时停止簇中心权值和候选点的转移动作。从理论的角度分析,当少数簇中心候选点的簇中心权值总和与多数簇中心候选点的簇中心权值总和达到相对平衡时,认为少数高权值点能有效诠释多数低权值点,则基于权值来划分簇中心归属时多数与之差异度较大,从而可以将两者清楚地划分,以便选取到准确的簇中心。以下给出了基于虹吸平衡法则的密度峰值聚类算法的具体步骤,即改进的密度峰值聚类算法(Improved Density Peak Clustering,IDPC)。
输入:数据集D,截断距离dc,簇中心候选个数q;
输出:聚类结果。
过程:

1.2 相互邻近度
相互邻近度是由赵嘉等[15]定义的一种样本间邻近程度的度量准则,考虑到样本的内部结构差异,当两个样本的相互邻近度越高时,说明两个样本越接近,彼此的联系越紧密,从而更能反映出数据间真实的密集或稀疏关系。对于数据集D=[x1,x2,…,xn]∈Rm×n,xi=[xi1,xi2,…,xim]。当每个点的近邻数为k时,计算公式如下所示:
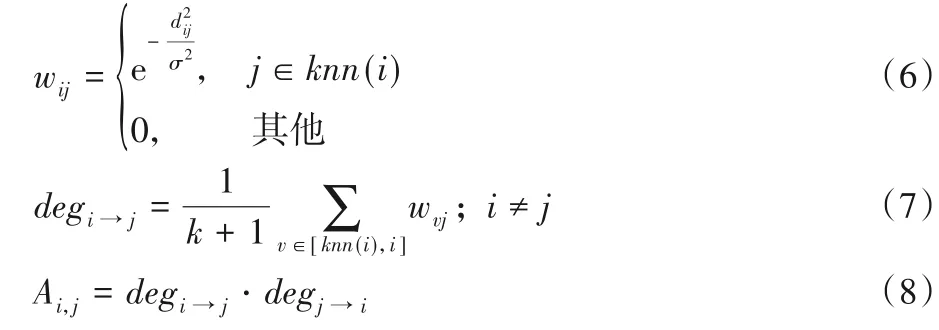
其中:σ2=,式(6)的wij为样本xi和xj的邻近度,式(7)的degi→j表示样本xi到xj的相对邻近度,式(8)的Ai,j表示样本xi和xj的相互邻近度。
1.3 共享子空间
在协同训练迭代过程中,多分类器标记同一个样本会存在标记不一致的情况,如图2的样例所示。图2以两种颜色分别代表两种类别,分类器h1和分类器h2对样本C1、C3、C4、C5的分类标记均相同,而对样本C2的标记却不同。这种情况需及时实施样本修订策略,将多分类器对样本的标记一致性最大化,才能有效避免标记错误样本的干扰。基于此,充分利用能表示多视图间一致性信息的共享子空间[16]来修订标记不一致样本。
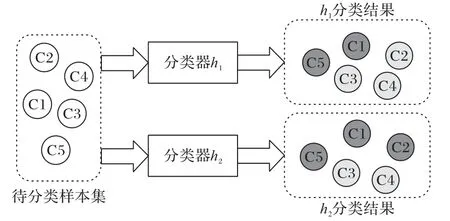
图2 多分类器标记不一致样例图Fig.2 Diagram of samples inconsistently labeled by multiple classifiers
共享子空间学习技术是指在保留原始数据的分类和决策能力的前提下,将原始多视图数据投影或因式分解得到一个共享低维子空间。非负矩阵分解(Non-negative Matrix Factorization,NMF)[21]是常用的因式分解方法,与其他矩阵分解方法的区别在于非负约束,有助于获得基于部分原始数据矩阵的表示,也增强了学习后的子空间的可解释性,但NMF只能处理单视图数据。Mekthanavanh 等[22]利用多视图非负矩阵分解(Multi-view Non-negative Matrix Factorization,Multi-NMF)方法处理多视图数据,在保留原NMF 算法优点的同时将其扩展到多视图领域。因此,本文通过在多视图有标记样本集中使用Multi-NMF 算法因式分解得到一个相同的矩阵,该矩阵即为多视图有标记样本集的共享子空间。给定N个样本的非负多视图数据集{X(1),X(2),…},每个样本有nv个视图。对于每个视图,X(v)=,U(v)表示非负基矩阵,V(v)表示非负系数矩阵,使X≈UVT。采用欧氏距离对Multi-NMF算法的目标函数进行求解,数学表达式为:
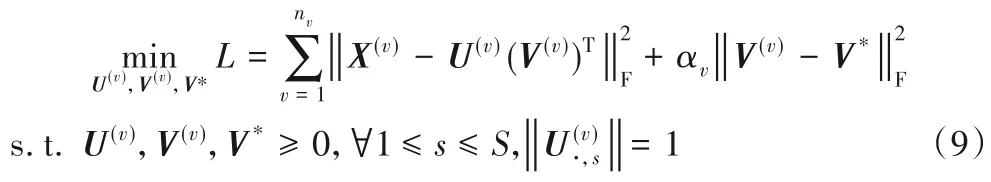
其中:V*表示多个视图的共享矩阵,S为降维系数,αv是控制不同视图重构误差项与共享子空间约束项之间的相对权重。通过利用对角矩阵Q(v)=简化U(v)上的约束条件,其中mv为第v个视图的维度。简化后的目标函数为:

由于目标函数是非凸函数,不易求全局最优解,所以在求解过程中,采用逐次迭代更新方法[23]交替更新U、V、V*,直到目标函数收敛,最终得到共享子空间矩阵V*。
1.4 本文算法
基于以上分析,提出了结合改进密度峰值聚类和共享子空间的协同训练算法。所提算法模型的整体结构见图3,算法的具体过程如下所示。
输入:有标记样本集L,无标记样本集U,截断距离dc,簇中心候选个数q,近邻数k,降维系数s,权重参数αv;
输出:分类器h1'、h2'。
过程:
步骤1 在L和U上根据算法1进行IDPC聚类,找到簇中心{c1,c2,…,cb}。
步骤2 选择以簇中心{c1,c2,…,cb}为圆心,dc为半径的圆形区域内的无标记样本,构造样本集R1。
步骤3 采用属性集合互补的方式将L和U划分为v1和v2,在L上基于v1、v2分别训练出分类器h1、h2,用分类器h1和h2对样本集R1分类。
步骤4 在L上利用Multi-NMF 算法因式分解得到v1和v2的共享子空间V*,训练一致性分类器h*。
步骤5 若h1和h2对样本的分类结果一致,则将该样本加入到L集;若分类结果不一致,则用分类器h*对其重新分类得到类标号后加入到L集。
步骤6U=U-R1,L=L+R1。
WhileU集不为空
步骤7 计算R1集中每个样本与其k个邻居的相互邻近度,选择与R1集中每个样本相互邻近度最高的无标记样本,构造样本集R2。
步骤8 采用属性集合互补的方式将L和U划分为v1'和v2',在L上基于v1'、v2'分别得到分类器h1'、h2',用分类器h1'和h2'对样本集R2分类。
步骤9 在L上利用Multi-NMF 算法因式分解得到v1'和v2'的共享子空间V*',训练一致性分类器h*'。
步骤10 若h1'和h2'对样本的分类结果一致,则将该样本加入到L集;若分类结果不一致,则用分类器h*'对其重新分类得到类标号后加入到L集。
步骤11U=U-R2,R1=R2。
步骤12R2=∅。
End
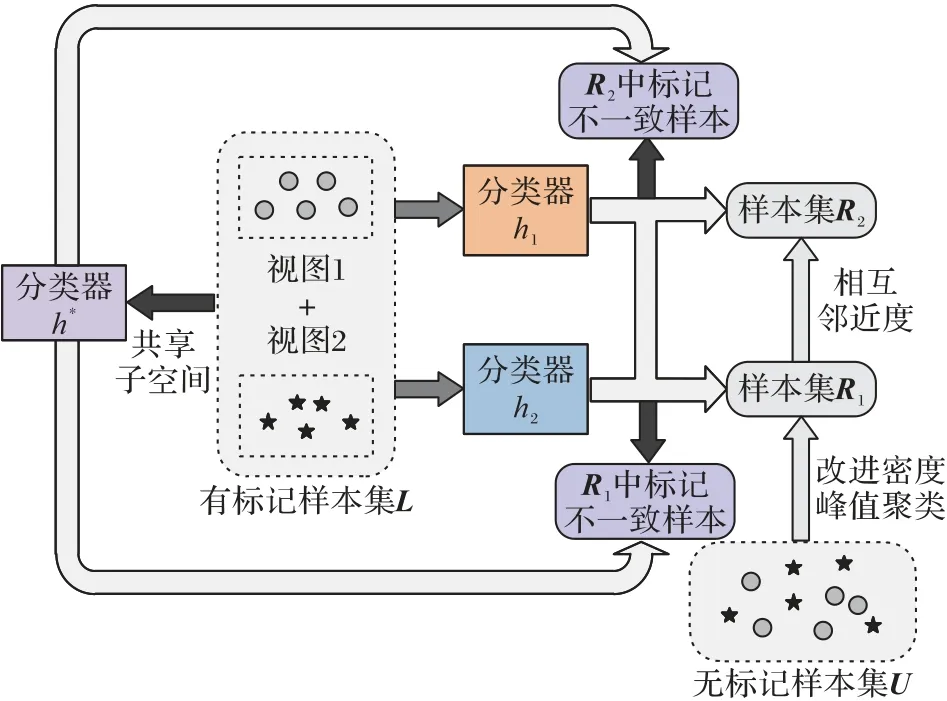
图3 本文算法结构Fig.3 Architecture of the presented algorithm
2 实验结果与分析
为了测试和评价本文算法的分类性能,将本文算法与4个对比算法在9 个数据集上进行实验,计算出每种算法两个视图的平均分类正确率,作为评价本文分类模型的有效性指标。选用的对比算法如下:
1)标准协同训练算法(Co-Training,CT)。
2)结合文献[19]和共享子空间的协同训练算法(Co-Training algorithm combining Density Peak Clustering with Shared Subspace,CTDPCSS)。
3)文献[12]提出的算法CTALDPCWKNN(Co-Training algorithm combined Active Learning and Density Peak Clustering and WeightK-Nearest Neighbor)。
4)结合文献[11]和共享子空间的协同训练算法(Co-Training algorithm combining Density Peak Clustering based on Cluster Center Automatic Selection Strategy with Shared Subspace,CTDPCCCASSSS)。
2.1 数据集描述
实验数据来源于UCI 中的9 个数据集。在实验过程中,5种算法在9 个数据集上均采用十折交叉验证方法重复实验100 次来测试算法的分类性能。每个数据集按照80%和20%的比例随机分为两部分,前者作为训练集用来构造分类模型,后者作为测试集用来测试模型的分类性能。其中,训练集依次随机选取10%、20%、30%、40%、50%的样本作为有标记样本,剩余样本去除标记作为无标记样本。表1描述了9个数据集的详细信息。
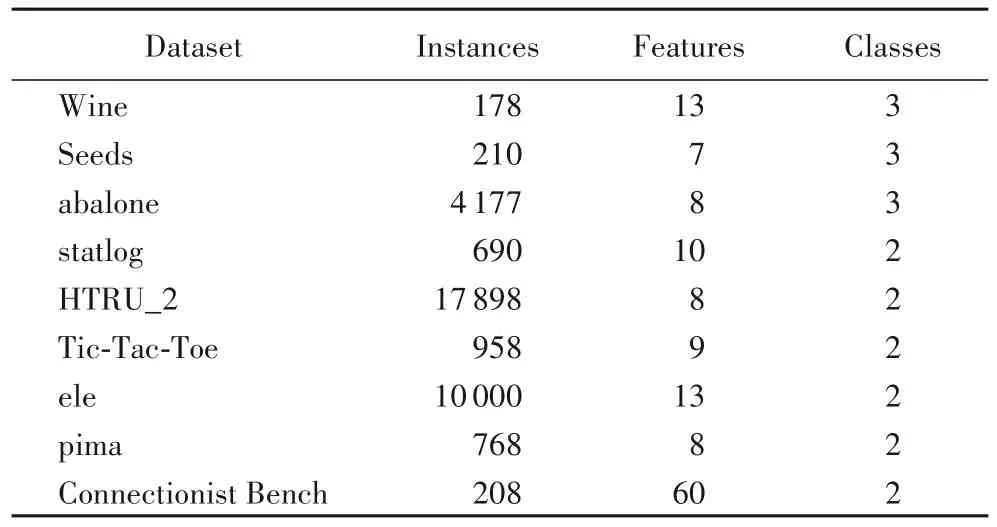
表1 数据集描述Tab.1 Description of datasets
2.2 实验参数设置
本文依据文献[19]的经验法则将对比算法CTDPCSS、CTALDPCWKNN、CTDPCCCASSSS 和本文算法需要设定的截断距离dc赋值为2。CTALDPCWKNN 算法还需设置模糊度参数ɛ,根据文献[12]设定ɛ=0.01。当上述算法利用Multi-NMF分解共享子空间矩阵时,设置权重参数αv=0.01,降维系数s=0.5dmin,其中dmin表示多个视图中特征向量最少视图的特征维度。在不同规模的数据集中,相较于大样本数据集,数量上处于劣势的小样本数据集的分布比较稀疏,导致样本的局部差异度量尺度会有所不同,从而影响算法的参数设置。为了更客观地测试所设定的参数对本文算法的普适性,选择了3 个具有代表性的数据集对簇中心候选个数q和近邻数k进行了参数调优,即分别在小、中、大样本量的数据集Wine、abalone和HTRU_2 上进行性能测试,结果如图4 所示。其中,近邻数k以1 为步长,在[5,10]内选取;簇中心候选个数q以5 为步长,在[10,30]内选取。
当有标记样本比例选取为10%时,图4 说明了在3 个不同规模的数据集上,参数值q、k对平均分类正确率的影响机制。由图4可知,当簇中心候选个数的取值范围为10≤q≤15或25≤q≤30,近邻数取值范围为5≤k≤8 时,算法的平均分类正确率相对较高且处于稳定状态。当15<q<25 时,由图4(a)和图4(b)发现,平均分类正确率有上升的波动,但随着k值的增加却逐渐降低,最终在一定范围内波动。在图4(a)中,当q=30,k=8时,存在一个明显的凸点,且该点的x轴和y轴坐标值在上述分类正确率较高的参数取值范围内。为了让本文算法的分类结果达到最优且保证算法的泛化性,在实验过程中将簇中心候选个数q和近邻数k分别统一设置为30和8。

图4 参数q、k对平均分类正确率的影响Fig.4 Influence of parameters q and k on average classification accuracy
2.3 簇中心选取策略对比
为了验证本文提出的IDPC 算法在选择簇中心时的准确性,以样本规模分别为小、中、大的数据集Wine、abalone 和HTRU_2为例,分别采用基于决策图[19]、拐点法[11]和虹吸平衡法则的簇中心选择策略来选择簇中心。为了更直观地比较各簇中心选择策略的准确度,将每种方法得到的簇中心数与各数据集的类别数进行对比。在同一个数据集中,若各方法所得簇中心数越接近数据集本身的类别数,则表明该方法选取簇中心的准确度越高。在表2中,第5列代表各数据集本身的簇类别数,而第2、3、4 列代表各簇中心选择策略分别在数据集Wine、abalone和HTRU_2下的簇中心数。
由表2 可知,基于虹吸平衡法则的簇中心选择策略的准确度均高于基于决策图和拐点法的簇中心选择方法。原因在于利用决策图选择簇中心时主观性较强,当数据集的空间结构较密集时,簇中心与一般样本的相对决策位置差异不够明显,通过人眼无法精准地识别两者的黄金分割线,从而易造成簇中心数目多选或少选。在数据集稀疏程度不同的情况下,若簇中心候选集下位区中顺位靠后的任意两个相邻点,其簇中心权值的平均变化率大于上位区顺位靠前的两个相邻点,则利用拐点法来确定偏离度变化趋势的最大值点时,会造成簇中心数目多选。而虹吸平衡法则在不同稀疏程度或任意形状的数据集下,都能通过量化分析自动确定最优的簇中心数,从而有效降低了人工辅助选择簇中心带来的主观误差。
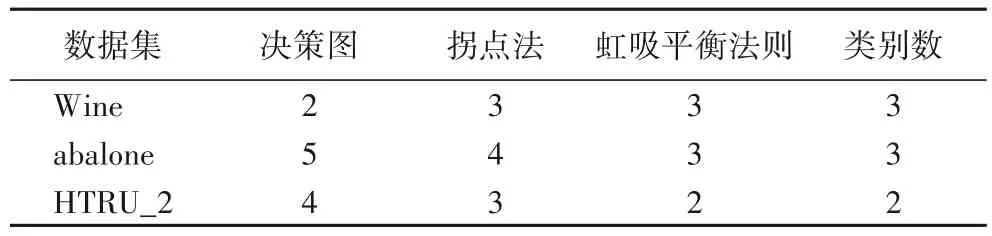
表2 不同选择策略的簇中心数与类别数对比Tab.2 Comparison of the number of cluster centers and the number of categories of different selection strategies
2.4 小样本数据集的处理
虹吸平衡法则是基于簇类别数远小于样本总数这一假设而提出,为了确定虹吸平衡法则在小样本数据集上的使用方法以及证明其在小样本数据集上的有效性,本文在Wine数据集上,分别选用其样本总数的20%、40%、60%、80%来构造新数据集。选取过程中,为了保证数据集的类别平衡,将每个类别的样本个数选取同等数量。在设定簇中心候选个数为30和将所有样本均纳入簇中心候选集这两种情况下,以平均分类正确率为评价指标,用构造的4 个新数据集和原始Wine 数据集作对比,实验结果如图5所示。
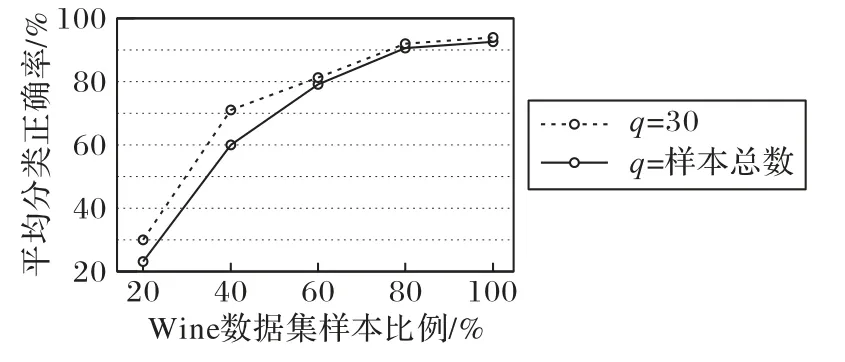
图5 小样本数据集上的平均分类正确率Fig.5 Average classification accuracy on small sample datasets
该实验过程中所得的簇中心数均为3,而由图5 可知,随着数据量的增加,算法的平均分类正确率也逐渐上升,且q=30 时的分类正确率均高于q=样本总数时的分类正确率,证明了虹吸平衡法则适用于各种规模的数据集寻找簇中心。因此,为了保持本文算法的分类稳定性,当数据集的样本总量小于30 时,将其所有样本作为簇中心候选点,否则将簇中心候选个数统一设置为30。
2.5 算法分类正确率对比
为了说明本文算法的分类有效性,表3 在有标记样本比例选取为10%时给出了5 种算法在9 个数据集上两个视图的平均分类正确率。
由表3 可知,相较于4 种对比算法,本文算法的平均分类正确率在9个数据集上最高提升了8.17个百分点。除了数据集Tic-Tac-Toe 和pima 外,本文算法在其余7 个数据集上的分类性能均优于对比算法。因为基于IDPC 算法选出的相互邻近度高的无标记样本更能代表数据集的原始空间结构,一定程度避免了边缘噪声点的影响,后续又通过共享子空间训练的一致性分类器修订样本,将多分类器对无标记样本的一致性最大化,最终得到较好分类效果的分类器。针对基于其他两种簇中心选择策略的密度峰值聚类算法,本文算法的正确率均高于基于决策图的CTDPCSS 算法。因为决策图方法定位的簇中心不够准确,可能会造成聚类过程中部分样本的类簇分配错误,从而无法获得足够的有利于改善基分类器性能的无标记样本。除数据集Tic-Tac-Toe 外,本文算法的正确率均高于基于拐点法的CTDPCCCASSSS 算法,可能因为该数据集的权值偏离度变化趋势较明显,拐点位置很大概率会成为簇中心与一般样本的分界点。相较于采用加权KNN 进行样本修订的CTALDPCWKNN 算法,本文算法在数据集pima上的分类性能略低,这可能是因为该数据集本身具有模糊度高且易分的样本,故利用主动学习去标记模糊度高的样本适用此数据集。除pima 数据集外,本文算法在其余8 个数据集上的分类正确率均高于CTALDPCWKNN 算法,证明了包含视图间一致性信息的共享子空间在重新分类标记不一致样本过程中的可行性,有效避免了由于标记不一致样本造成分类错误累积的问题。
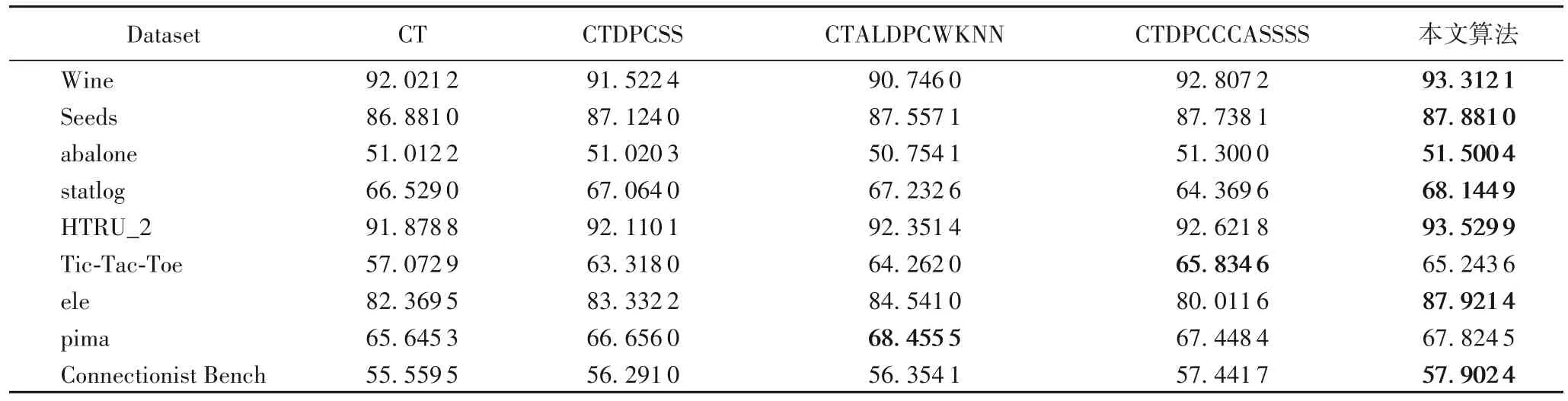
表3 五种算法在9个数据集上的平均分类正确率对比 单位:%Tab.3 Comparison of average classification accuracy of 5 algorithms on 9 datasets unit:%
2.6 时间复杂度分析
为了分析5 种算法的时间成本,本文通过划分每个算法的组成成分并计算各成分的时间复杂度,最终得到每个算法总的时间度复杂度,结果如表4 所示。其中,各算法成分括号内的信息为该部分的时间复杂度。
由表4 可知,本文算法和对比算法的时间复杂度均相同,则表明5 种算法在解决模型分类问题时所需的大致时间相同。相较于4 种对比算法,本文算法的组成成分略多,但由于各部分的时间复杂度均未超过O(n2),则总的时间复杂度保持不变。所以,本文算法在加入额外的优化步骤时,较好地控制了时间成本,保持了与对比算法同样的复杂度。
2.7 有标记样本的影响
在半监督学习中,有标记样本的比例会对模型的分类性能产生影响,为了讨论有标记样本的比例对算法的影响程度,图6 给出了9 个数据集在有标记样本比例分别为10%、20%、30%、40%、50%时的平均分类正确率曲线。
从图6 总体的关系曲线分布来看,5 种算法在除数据集HTRU_2和Tic-Tac-Toe外的其余7个数据集上,平均分类正确率随着有标记样本比例的增加而提升,这表明在半监督协同训练学习过程中,迭代初期有标记样本量越多则训练的基分类器越准确,进而利用分类器间的协同作用最终得到两个能独立完备确定样本类别的分类器。由图6(e)和图6(f)可知,在数据集HTRU_2和Tic-Tac-Toe中,有标记样本比例为10%~30%时的平均分类正确率呈上升趋势,然而当比例提高至40%~50%时,正确率下降且最终低于比例为10%时的正确率。因为随着有标记样本增加到一定比例后,有标记样本的信息对分类器的影响逐渐减弱,从而达到一种相对稳定的状态,则此时的平均分类正确率会在一定范围内波动。

表4 五种算法的时间复杂度对比Tab.4 Comparison of time complexity of 5 algorithms
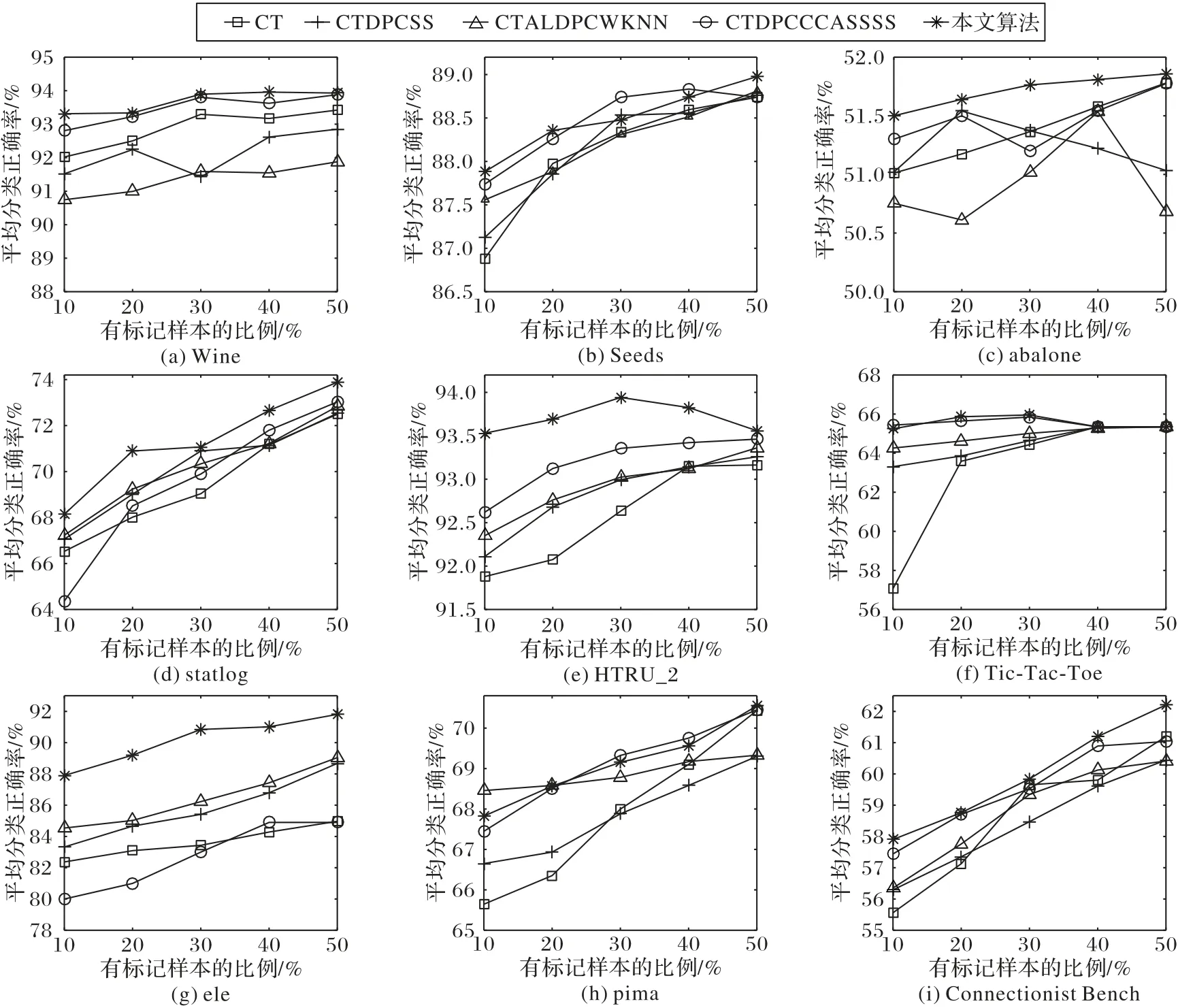
图6 有标记样本比例与平均分类正确率的关系曲线Fig.6 Relationship curve of labeled sample proportion and average classification accuracy
3 结语
本文针对协同训练迭代过程中用来改善分类器性能的无标记样本隐含有用信息不足和多分类器标记不一致样本的问题,提出了结合改进密度峰值聚类和共享子空间的协同训练算法。该算法通过定义虹吸平衡法则选择簇中心,再结合相互邻近度选择出综合数据全局和局部空间结构的无标记样本,最后利用共享子空间训练的一致性分类器重新分类标记不一致样本。基于虹吸平衡法则的改进密度峰值聚类算法为簇中心的选择提供定量分析和决定性理论依据,实现了簇中心的自动选择。通过将聚类算法与相互邻近度结合,综合考虑数据全局和局部的紧密和稀疏程度,选择更能代表数据原始空间结构的无标记样本。引入共享子空间,充分利用多视图间的一致性信息将标记不一致样本统一描述。在9 个数据集上的仿真实验证明了该算法的有效性,实验结果表明该算法具有更高的模型评价能力。在后续的工作中,将进一步讨论算法的最优参数并给出具体的调优策略,以及探索本文算法的应用拓展性,如将本文算法应用于多标签分类问题。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
医学食疗与健康(2022年3期)2022-04-23
电子产品世界(2022年4期)2022-04-21
健康体检与管理(2021年6期)2021-11-17
计算机系统应用(2021年2期)2021-02-23
软件导刊(2017年4期)2017-06-20
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
家教世界·创新阅读(2016年11期)2016-12-27
